- 1(Shadow Mapping) 阴影映射原理与实现_shadow mapping算法原理
- 2修改 unity“显示桌面”快捷键的方法_unity 打包怎么看到桌面
- 3微信自动化RPA机器人
- 4大型企业计算机终端安全管理现状与策略分析_终端安全现状分析
- 5【git 将当前仓库和远程仓库合并,并且远程仓库替代本地的修改】_git 合并本地和远程
- 6月之暗面:Moonshot AI接口总结_moonshot api
- 7点击button自动提交表单原因及解决方案_button 提交
- 8「深度」想当有实体的“贾维斯”,智能家居机器人还需跨越多个桎梏
- 9配置node环境、安装vue脚手架、淘宝镜像_淘宝镜像安装vue脚手架
- 10pycharm Gitee配置_pycharm配置gitee
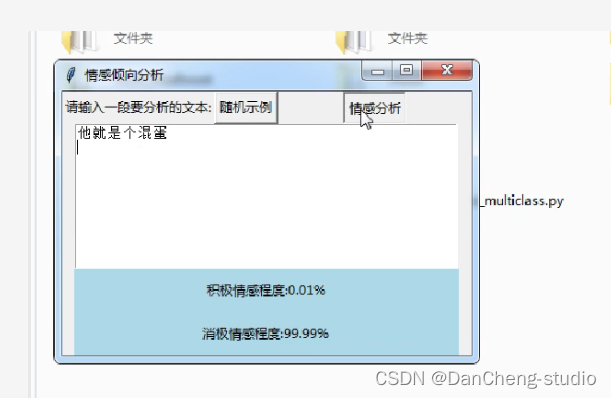
毕业设计 : 基于LSTM的文本情感分类 - 情感分类 情感分析 lstm_lstm情感分类
赞
踩
0 前言
这几天在帮助同学开发基于深度学习的情感分类项目,这里学长复现了两篇论文的实现方法,带大家实现一个基于深度学习的文本情感分类器。
**基于LSTM的文本情感分类 **
1 项目背景
文本情感分析作为NLP的常见任务,具有很高的实际应用价值。这里学长将采用LSTM模型,训练一个能够识别文本postive, neutral, negative三种情感的分类器。
本文的目的是快速熟悉LSTM做情感分析任务,所以我提到的只是一个baseline,并在最后分析了其优劣。对于真正的文本情感分析,在本文提到的模型之上,还可以做很多工作,以后有空的话,我会可以再做优化。
2 文本情感分类理论
3 RNN
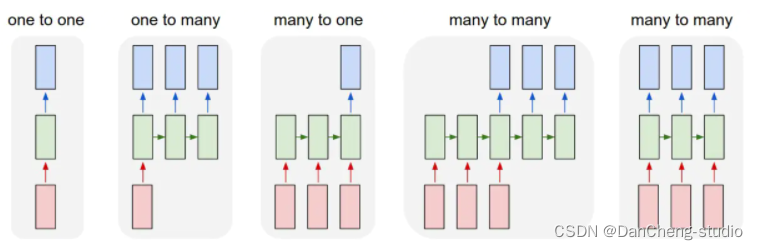
RNN相对于传统的神经网络,它允许我们对向量序列进行操作:输入序列、输出序列、或大部分的输入输出序列。如下图所示,每一个矩形是一个向量,箭头则表示函数(比如矩阵相乘)。输入向量用红色标出,输出向量用蓝色标出,绿色的矩形是RNN的状态(下面会详细介绍)。
从左到右:
- (1)没有使用RNN的Vanilla模型,从固定大小的输入得到固定大小输出(比如图像分类)。
- (2)序列输出(比如图片字幕,输入一张图片输出一段文字序列)。
- (3)序列输入(比如情感分析,输入一段文字然后将它分类成积极或者消极情感)。
- (4)序列输入和序列输出(比如机器翻译:一个RNN读取一条英文语句然后将它以法语形式输出)。
- (5)同步序列输入输出(比如视频分类,对视频中每一帧打标签)。我们注意到在每一个案例中,都没有对序列长度进行预先特定约束,因为递归变换(绿色部分)是固定的,而且我们可以多次使用。
3.1 word2vec 算法
建模环节中最重要的一步是特征提取,在自然语言处理中也不例外。
在自然语言处理中,最核心的一个问题是,如何把一个句子用数字的形式有效地表达出来?如果能够完成这一步,句子的分类就不成问题了。
显然,一个最初等的思路是:给每个词语赋予唯一的编号1,2,3,4…,然后把句子看成是编号的集合,比如假设1,2,3,4分别代表“我”、“你”、“爱”、“恨”,那么“我爱你”就是[1, 3, 2],“我恨你”就是[1, 4, 2]。这种思路看起来有效,实际上非常有问题,比如一个稳定的模型会认为3跟4是很接近的,因此[1, 3, 2]和[1, 4, 2]应当给出接近的分类结果,但是按照我们的编号,3跟4所代表的词语意思完全相反,分类结果不可能相同。因此,这种编码方式不可能给出好的结果。
同学们也许会想到,我将意思相近的词语的编号凑在一堆(给予相近的编号)不就行了?嗯,确实如果,如果有办法把相近的词语编号放在一起,那么确实会大大提高模型的准确率。可是问题来了,如果给出每个词语唯一的编号,并且将相近的词语编号设为相近,实际上是假设了语义的单一性,也就是说,语义仅仅是一维的。然而事实并非如此,语义应该是多维的。
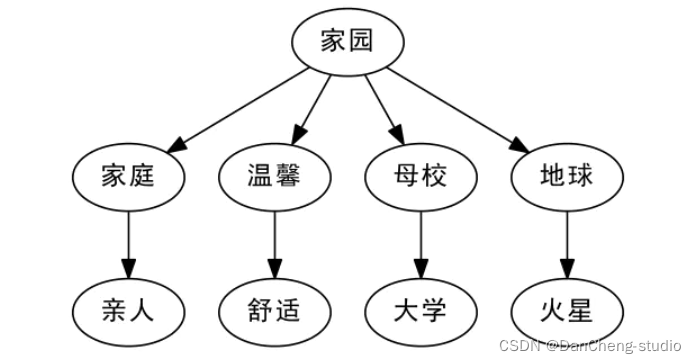
比如我们谈到“家园”,有的人会想到近义词“家庭”,从“家庭”又会想到“亲人”,这些都是有相近意思的词语;另外,从“家园”,有的人会想到“地球”,从“地球”又会想到“火星”。换句话说,“亲人”、“火星”都可以看作是“家园”的二级近似,但是“亲人”跟“火星”本身就没有什么明显的联系了。此外,从语义上来讲,“大学”、“舒适”也可以看做是“家园”的二级近似,显然,如果仅通过一个唯一的编号,是很难把这些词语放到适合的位置的。
3.2 高维 Word2Vec
从上面的讨论可以知道,很多词语的意思是各个方向发散开的,而不是单纯的一个方向,因此唯一的编号不是特别理想。那么,多个编号如何?换句话说,将词语对应一个多维向量?不错,这正是非常正确的思路。
为什么多维向量可行?首先,多维向量解决了词语的多方向发散问题,仅仅是二维向量就可以360度全方位旋转了,何况是更高维呢(实际应用中一般是几百维)。其次,还有一个比较实际的问题,就是多维向量允许我们用变化较小的数字来表征词语。怎么说?我们知道,就中文而言,词语的数量就多达数十万,如果给每个词语唯一的编号,那么编号就是从1到几十万变化,变化幅度如此之大,模型的稳定性是很难保证的。如果是高维向量,比如说20维,那么仅需要0和1就可以表达2^20=1048576220=1048576(100万)个词语了。变化较小则能够保证模型的稳定性。
扯了这么多,还没有真正谈到点子上。现在思路是有了,问题是,如何把这些词语放到正确的高维向量中?而且重点是,要在没有语言背景的情况下做到这件事情?(换句话说,如果我想处理英语语言任务,并不需要先学好英语,而是只需要大量收集英语文章,这该多么方便呀!)在这里我们不可能也不必要进行更多的原理上的展开,而是要介绍:而基于这个思路,有一个Google开源的著名的工具——Word2Vec。
简单来说,Word2Vec就是完成了上面所说的我们想要做的事情——用高维向量(词向量,Word Embedding)表示词语,并把相近意思的词语放在相近的位置,而且用的是实数向量(不局限于整数)。我们只需要有大量的某语言的语料,就可以用它来训练模型,获得词向量。词向量好处前面已经提到过一些,或者说,它就是问了解决前面所提到的问题而产生的。另外的一些好处是:词向量可以方便做聚类,用欧氏距离或余弦相似度都可以找出两个具有相近意思的词语。这就相当于解决了“一义多词”的问题(遗憾的是,似乎没什么好思路可以解决一词多义的问题。)
关于Word2Vec的数学原理,读者可以参考这系列文章。而Word2Vec的实现,Google官方提供了C语言的源代码,读者可以自行编译。而Python的Gensim库中也提供现成的Word2Vec作为子库(事实上,这个版本貌似比官方的版本更加强大)。
3.3 句向量
接下来要解决的问题是:
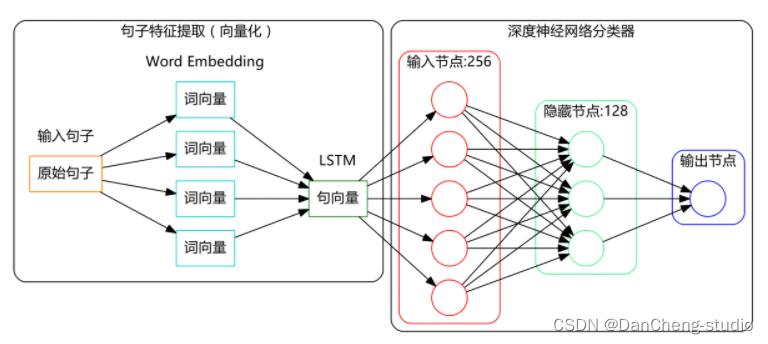
我们已经分好词,并且已经将词语转换为高维向量,那么句子就对应着词向量的集合,也就是矩阵,类似于图像处理,图像数字化后也对应一个像素矩阵;可是模型的输入一般只接受一维的特征,那怎么办呢?一个比较简单的想法是将矩阵展平,也就是将词向量一个接一个,组成一个更长的向量。这个思路是可以,但是这样就会使得我们的输入维度高达几千维甚至几万维,事实上是难以实现的。(如果说几万维对于今天的计算机来说不是问题的话,那么对于1000x1000的图像,就是高达100万维了!)
在自然语言处理中,通常用到的方法是递归神经网络或循环神经网络(都叫RNNs)。
它们的作用跟卷积神经网络是一样的,将矩阵形式的输入编码为较低维度的一维向量,而保留大多数有用信息。
4 代码实现
工程代码主要是结合参考资料2做三分类的文本情感分析;
4.1 数据预处理与词向量模型训练
处理过程,包括:
- 不同类别数据整理成输入矩阵
- jieba分词
- Word2Vec词向量模型训练
这里学长就不做重复介绍了,想要了解的,可以问我要。
三分类除了涉及到positive和negative两种情感外,还有一种neural情感,从原始数据集中可以提取到有语义转折的句子,“然而”,“但”都是关键词。从而可以得到3份不同语义的数据集。
4.2 LSTM三分类模型
代码需要注意的几点是,第一是,标签需要使用keras.utils.to_categorical来yummy,第二是LSTM二分类的参数设置跟二分有区别,选用softmax,并且loss函数也要改成categorical_crossentropy,代码如下:
def get_data(index_dict,word_vectors,combined,y): n_symbols = len(index_dict) + 1 # 所有单词的索引数,频数小于10的词语索引为0,所以加1 embedding_weights = np.zeros((n_symbols, vocab_dim)) # 初始化 索引为0的词语,词向量全为0 for word, index in index_dict.items(): # 从索引为1的词语开始,对每个词语对应其词向量 embedding_weights[index, :] = word_vectors[word] x_train, x_test, y_train, y_test = train_test_split(combined, y, test_size=0.2) y_train = keras.utils.to_categorical(y_train,num_classes=3) y_test = keras.utils.to_categorical(y_test,num_classes=3) # print x_train.shape,y_train.shape return n_symbols,embedding_weights,x_train,y_train,x_test,y_test ##定义网络结构 def train_lstm(n_symbols,embedding_weights,x_train,y_train,x_test,y_test): print 'Defining a Simple Keras Model...' model = Sequential() # or Graph or whatever model.add(Embedding(output_dim=vocab_dim, input_dim=n_symbols, mask_zero=True, weights=[embedding_weights], input_length=input_length)) # Adding Input Length model.add(LSTM(output_dim=50, activation='tanh')) model.add(Dropout(0.5)) model.add(Dense(3, activation='softmax')) # Dense=>全连接层,输出维度=3 model.add(Activation('softmax')) print 'Compiling the Model...' model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy']) print "Train..." # batch_size=32 model.fit(x_train, y_train, batch_size=batch_size, epochs=n_epoch,verbose=1) print "Evaluate..." score = model.evaluate(x_test, y_test, batch_size=batch_size) yaml_string = model.to_yaml() with open('../model/lstm.yml', 'w') as outfile: outfile.write( yaml.dump(yaml_string, default_flow_style=True) ) model.save_weights('../model/lstm.h5') print 'Test score:', score

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
4.3 测试
代码如下:
def lstm_predict(string): print 'loading model......' with open('../model/lstm.yml', 'r') as f: yaml_string = yaml.load(f) model = model_from_yaml(yaml_string) print 'loading weights......' model.load_weights('../model/lstm.h5') model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy']) data=input_transform(string) data.reshape(1,-1) #print data result=model.predict_classes(data) # print result # [[1]] if result[0]==1: print string,' positive' elif result[0]==0: print string,' neutral' else: print string,' negative'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
经过检测,发现,原先在二分类模型中的“不是太好”,“不错不错”这样子带有前后语义转换的句子,都能正确预测,实战效果提升明显,但是也有缺点,缺点是中性评价出现的概率不高,笔者分析原因是,首先从数据集数量和质量着手,中性数据集的数量要比其他两个数据集少一半多,并且通过简单规则“然而”,“但”提取出来的中性数据集质量也不是很高,所以才会出现偏差。总而言之,训练数据的质量是非常重要的,如何获取高质量高数量的训练样本,也就成了新的难题。