
- 1网易终面:4款主流分布式MQ消息队列如何技术选型,2024年最新java电商购物车面试题_rabbitmq和rocketmq对比面试
- 2MySQL介绍_mysql是一个关系型数据库管理系统,用于存储、管理和检索数据。它能够处理大量的数
- 3解密Teradata与中国市场“分手”背后的原因!国产数据库能填补空白吗?_teradata 竞对
- 4访问网站显示不安全怎么办?教您不花一分钱解决!_此站点的连接不安全
- 5十、Git
- 6Python基础库-JSON库_python json库
- 7Unity中UGUI 图片实现鼠标拖拽功能以及松开复位_unity ui 拖拽
- 8基于SSM的图书借阅系统的开发与实现_基于ssm 技术路线
- 92024年最全该死!GitHub上这些C++项目真香_tbox c++,2024年最新卑微打工人_github上c++11开源项目
- 10智能合约与身份验证:区块链技术的创新应用_怎么通过区块链来管理报名某个项目过程中的信息和身份验证
深度学习(自然语言处理)RNN、LSTM、TextCNN_text cnn 和rnn以及lstm
赞
踩
目录
- 文章来源:忆_恒心(CSDN)
0 前言:
自然语言处理中,RNN、LSTM和TextCNN的学习基本上是躲不开的,这些基本的模型需要有一个比较清晰的了解,这对后面做对比实验的时候会有很多的帮助。
本篇文章的目的就是帮助读者分析从RNN到LSTM在到textCNN的应用过程。
1.从RNN到LSTM
RNN 与DNN.CNN不同,它能处理序列问题.
常见的序列问题:
- 一段段连续的语音
- 一段段连续的手写文字
- 一条句子等等。
这些序列长短不一,又比较难拆分成一个个独立的样本来训练
RNN就是假设我们的样本是基于序列的。
1.1 RNN
比如这么一个例子:
”我” “吃” “苹果“ 词性与前个词语有很大的关系,所以RNN可以解决
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随着时间反向传播。
激活函数: tanh 函数的收敛速度要快于 sigmoid 函数,而且梯度消失的速度要慢于 sigmoid 函数
利用BPTT算法训练网络时容易出现梯度消失的问题,当序列很长的时候问题尤其严重,因此上面的RNN模型一般不能直接应用。而较为广泛使用的是RNN的一个特例LSTM。
标准的RNN中,重复的模块只有一个非常简单的结构,例如一个tanh层
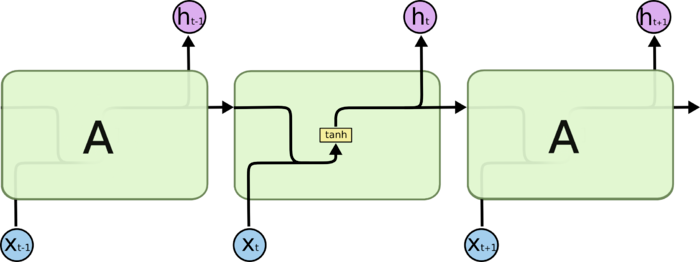
1.2 LSTM模型
LSTM 同样是这样的结构,但是重复的模块的结构更加复杂。不同于 单一神经网络层,整体上除了 h 在随时间流动,细胞状态 c 也在随时间流动。细胞状态(cell) c 就代表着长期记忆,而状态 h 代表了短期记忆。
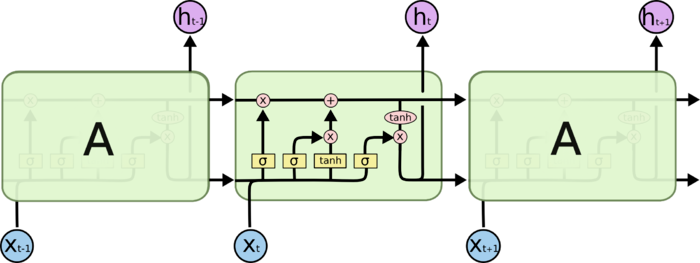
从上图中可以看出,在每个序列索引位置 t 时刻向前传播的除了和RNN一样的隐藏状态 ht ,还多了另一个隐藏状态,如图中上面的长横线。这个隐藏状态我们一般称为细胞状态(Cell State),记为 Ct 。如下图所示:
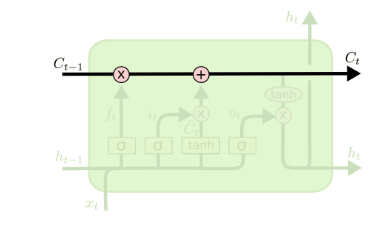
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力
1.2.1遗忘门(forget gate)
顾名思义,是控制是否遗忘的

输出一个在 0 到 1 之间的数值,这个数值决定要遗忘多少历史信息。1 表示“完全保留”,0 表示“完全舍弃”。
1.2.2 输入门
输入门(input gate)负责处理当前序列位置的输入,1.从RNN到LSTM被存放在细胞状态中。
1.2.3 输出门
当为0时,门完全关闭,当为1时,门完全打开。输入门控制这当前输入值有多少信息流入到当前的计算中,遗忘门控制着历史信息中有多少信息流入到当前计算中
1.3 使用循环神经网络模型
- 在这个模型中,每个词先通过嵌⼊入层得到特征向量量。
- 然后,我们使⽤用双向循环神经⽹网络对特征序列进⼀步编码得到序列列信息。
- 最后,我们将编码的序列信息通过全连接层变换为输出。
具体来说,我们可以将双向长短期记忆(LSTM)在最初时间步和最终时间步的隐藏状态连结,作为特征序列的表征传递给输出层分类。
在下⾯面实现的 BiRNN 类中,
- Embedding 实例即嵌⼊入层,
- LSTM 实例例即为序列列编码的隐藏层,
- Linear实例例即⽣生成分类结果的输出层。

2 textCNN
-
简单的一个维度的时间序列 ---- 循环神经网络RNN
-
一维图像,用一维卷积神经网络来捕捉临近词之间的关联-----TextCNN
2.1 需要解决的问题:
-
多输入通道的一维互关运算---单输⼊入通道的\二维互相关运算。
-
时序最大池化(一维全局最大池化)
- TextCNN的计算
2.1.1 多输入通道的一维互关运算
实现代码
注意:
torch.stack()
在自然语言处理和卷及神经网络中, 通常为了保留–[序列(先后)信息] 和 [张量的矩阵信息] 才会使用stack。
https://blog.csdn.net/xinjieyuan/article/details/105205326
2.1.2 时序最大池化
(max-over-pooling)假设输⼊入包含多个通道,各通道由不不同时间步上的数值组成,各通道的输出即,该通道所有时间步中最大的数值.通过普通的池化实现全局池化

2.2 TEXT CNN模型
计算主要分为以下几步:
-
定义多个一维卷积,并对输入分别做卷积运算----可以使用⼀维卷积来表征时序数据
-
对输出的所有通道分别做时序最大化,再将这些输出值连接为向量
-
通过全连接层将连接后的向量变换为有关各类别的输出。(同时采DROUPT层正则化,前向传播的时候)

其实比较清晰的话,还是参考论文下面的图片
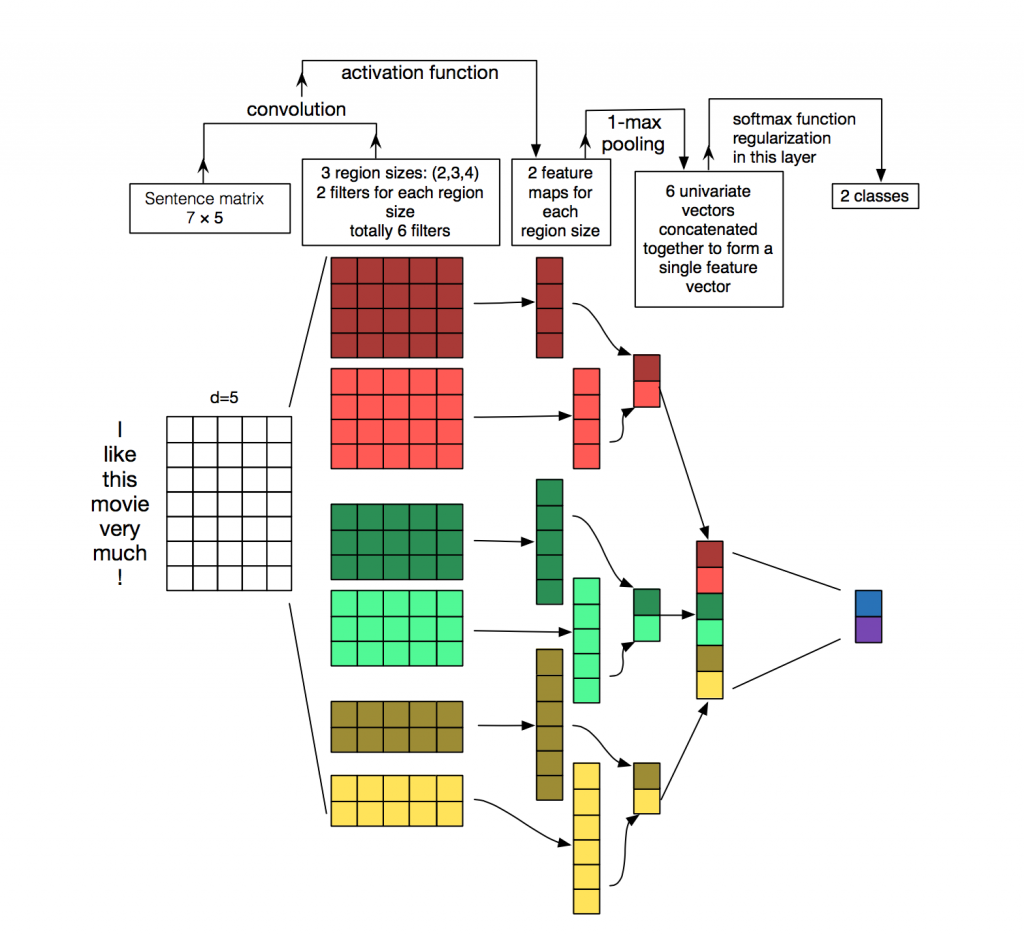
2.3 TextCNN实现:

训练并评价模型

注意:关于nn.CrossEntroyLoss交叉熵的理解
https://blog.csdn.net/geter_CS/article/details/84857220
小结:
- 可以使⽤用⼀维卷积来表征时序数据。
- 多输入通道的⼀维互相关运算可以看作单输⼊入通道的⼆维互相关运算。
- 时序最⼤大池化层的输⼊入在各个通道上的时间步数可以不同。
- textCNN主要使⽤用了⼀维卷积层和时序最⼤大池化层
参考文献
-
Bi-LSTM网络:https://www.cnblogs.com/jiangxinyang/p/10208163.html
-
动手学习深度学习
-
深度学习之RNN到LSTM:https://www.cnblogs.com/jiangxinyang/p/9362922.html
-
pytorch损失函数之nn.CrossEntropyLoss()、nn.NLLLoss():https://blog.csdn.net/geter_CS/article/details/84857220

