在需要搭建平台或配置环境时,按照传统的做法,需要下载相应软件包,然后进行配置,经过大量的操作后还需要进行功能测试,查看是否工作正常。如果不正常,则意味着更多的时间代价和不可控的风险。一旦需要服务器迁移(例如从阿里云迁移到腾讯云),往往需要重新部署和调试。这些琐碎而无趣的“体力活”,极大地降低了工作效率。
Docker提供了一种更为聪明的方式,通过容器来打包应用,意味着迁移只需要在新的服务器上启动需要的容器就可以了。这无疑将节约大量的宝贵时间,并降低部署过程出现问题的风险。
同理,在搭建数据分析hadoop-spark-zeppelin平台时,同样可以使用docker技术来制作镜像,通过启动容器来启动应用,首先需要修改Hadoop、Spark及Zeppelin的配置文件,然后再制作dockerfile。
具体配置Hadoop、Spark、Zeppelin的步骤以及具体制作的dockerfile的步骤如下所示:
1.配置Hadoop
/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ cat core-site.xml
/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ cat hdfs-site.xml
/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ cat hadoop-env.sh
![]()
/usr/local/hadoop/hadoop-2.6.0/etc/hadoop$ cat slaves
![]()
2 配置Spark
/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ cat spark-env.sh
![]()
/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ cat slave
![]()
/usr/local/spark/spark-1.5.2-bin-hadoop2.6/conf$ cat spark-defaults.conf
![]()
3 配置Zeppelin
/usr/local/zeppelin-0.6.0-bin-all/conf$ cat zeppelin-env.sh
![]()
/usr/local/zeppelin-0.6.0-bin-all/conf$ cat zeppelin-site.xml
4 制作Dockerfile
从docker hub仓库拉取ubuntu的基础镜像:docker pull ubuntu。
1) 使用该基础镜像并添加作者信息:
| 1 2 3 | FROM ubuntu
MAINTAINER from XXX |
2) 安装必要的工具并建立必要的文件夹:
| 1 2 3 4 5 6 7 8 9 | RUN apt-get update && apt-get –y install sudo
RUN sudo apt-get -y install openssh-server
RUN sudo apt-get -y install rsync
RUN sudo apt-get install -y supervisor
RUN mkdir /var/run/sshd |
3) 修改sshd_config以及ssh_config 文件:
| 1 2 3 4 5 | RUN sed -i 's/PermitRootLogin prohibit-password/ PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed -i 's/PermitEmptyPasswords no/PermitEmptyPasswords yes/' /etc/ssh/sshd_config
RUN sed -i 's/# StrictHostKeyChecking ask/StrictHostKeyChecking no/' /etc/ssh/ssh_config |
4) 配置免密码登录:
| 1 2 3 4 5 6 7 | RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa
RUN cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
RUN chmod 0600 ~/.ssh/authorized_keys
RUN chmod 0700 ~/.ssh |
5) 配置环境变量:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | ENV JAVA_HOME /usr/local/java/jdk1.8.0_45
ENV SPARK_HOME ${SPARK_HOME}/bin:/usr/local/spark/spark-1.5.2-bin-hadoop2.6
ENV HADOOP_HOME /usr/local/hadoop/hadoop-2.6.0
ENV HADOOP_OPTS "$HADOOP_OPTS -Djava.library.path=/usr/local/hadoop/hadoop-2.6.0/lib/native"
ENV HADOOP_COMMON_LIB_NATIVE_DIR $HADOOP_HOME/lib/native
ENV CLASSPATH $CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME
ENV PATH ${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH:${SPARK_HOME}/bin
RUN echo 'export JAVA_HOME=/usr/local/java/jdk1.8.0_45'>>/etc/profile
RUN echo 'export SPARK_HOME=${SPARK_HOME}/bin:/usr/local/spark/spark-1.5.2-bin-hadoop2.6'>>/etc/profile
RUN echo 'export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0'>>/etc/profile
RUN echo 'export HADOOP_OPTS="$HADOOP_OPTS -XX:-PrintWarnings-Djava.library.path=/usr/local/hadoop/hadoop-2.6.0/lib/native"'>>/etc/profile
RUN echo 'export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native'>>/etc/profile
RUN echo'export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME'>>/etc/profile
RUN echo 'export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH:${SPARK_HOME}/bin'>>/etc/profile |
6) 将下载并配置好的Hadoop、Java、Spark以及Zeppelin放在适当位置:
| 1 2 3 4 5 6 7 | COPY hadoop /usr/local/hadoop
COPY java /usr/local/java
COPY spark /usr/local/spark
COPY zeppelin-0.6.0-bin-all /usr/local/zeppelin-0.6.0-bin-all |
7) 格式化Hadoop HDFS的namenode:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | WORKDIR /usr/local/hadoop/hadoop-2.6.0/hdfs/namenode
RUN sudo rm –rf *
WORKDIR /usr/local/hadoop/hadoop-2.6.0/hdfs/datanode
RUN sudo rm -rf *
WORKDIR /usr/local/hadoop/hadoop-2.6.0/tmp
RUN sudo rm -rf *
WORKDIR /usr/local/hadoop/hadoop-2.6.0
RUN bin/hdfs namenode –format |
8) 将启动脚本start.sh放置在合适路径:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | /*
#!/bin/bash
#start.sh
echo "127.0.0.1 singlenode" >> /etc/hosts
/usr/local/hadoop/hadoop-2.6.0/sbin/stop-all.sh
/usr/local/hadoop/hadoop-2.6.0/sbin/start-dfs.sh /usr/local/spark/spark-1.5.2-bin-hadoop2.6/sbin/stop-all.sh
/usr/local/spark/spark-1.5.2-bin-hadoop2.6/sbin/start-all.sh
cd /usr/local/zeppelin-0.6.0-bin-all
bin/zeppelin-daemon.sh start
/bin/bash
*/
COPY start.sh /usr/local/start.sh |
9) 使用supervisord来管理:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | /*
#supervisord.conf
[supervisord]
nodaemon=true
[program:sshd]
command=/usr/sbin/sshd –D
[program:start]
command=sh /usr/local/start.sh&& tail -f
startsecs=30
[program:bin]
command=/bin/bash
*/
COPY supervisord.conf /etc/supervisor/conf.d/supervisord.conf
RUN chmod 755 /etc/supervisor/conf.d/supervisord.conf |
10) 对外暴露22,50070,8080,4040,8090端口:
| 1 | EXPOSE 22 50070 8080 4040 8090 |
11) 设置container启动时执行的操作:
| 1 | CMD ["/usr/bin/supervisord"] |
5 在当前dockerfile的目录下build镜像
| 1 | docker build -t hadoopsparkzeppelinimage . |
6 运行新镜像
| 1 | docker run –d –P hadoopsparkzeppelinimage |
此时可以通过运行该容器的Ubuntu的IP和映射的50070端口访问Hadoop的HDFS,映射的8080端口访问Spark、映射的8090端口访问Zeppelin,如下图所示:
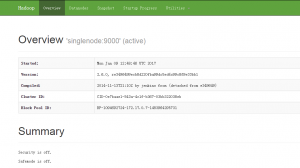
访问Hadoop页面
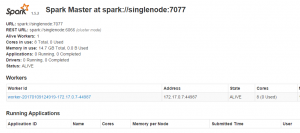
访问Spark页面
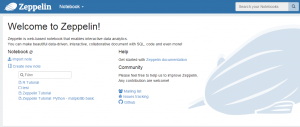
访问Zeppelin页面
至此,单节点的Hadoop-Spark-Zeppelin镜像就做好并启动了,该docker镜像可用于部署有docker环境的Ubuntu机器下。
对于运维来说,Docker提供了一种可移植的标准化部署过程,使得规模化、自动化、异构化的部署成为可能甚至是轻松简单的事情;而对于开发者来说,Docker提供了一种开发环境的管理方法,包括映像、构建、共享等功能, 将来会让普通用户使用起来。通过将数据分析平台Hadoop-Spark-Zeppelin docker化,使得数据分析人员不用在陷入配置Hadoop、Spark以及Zeppelin环境的重复劳动,将精力投入到核心的数据分析工作中去。
windows or linux下抢建数据集群:
1、Docker溯源
Docker的前身是名为dotCloud的小公司,主要提供的是基于 PaaS(Platform as a Service,平台及服务)平台为开发者或开发商提供技术服务,并提供的开发工具和技术框架。因为其为初创的公司,又生于IT行业,dotCloud受到了IBM,亚马逊,google等公司的挤压,发展举步维艰。于是,在2013年dotCloud 的创始人,年仅28岁的Solomon Hykes做了一个艰难的决定:将dotCloud的核心引擎开源!然而一旦这个基于 LXC(Linux Container)技术的核心管理引擎开源,dotCloud公司就相当于走上了一条"不归路"。可正是这个孤注一掷的举动,却带来了全球技术人员的热潮,众程序员惊呼:太方便了,太方便了。也正是这个决定,让所有的IT巨头也为之一颤。一个新的公司也随之出世,它就是:Docker。可以说,Docker是一夜成名的!!
2、认识docker
2.1 镜像、容器、仓库
首先,需要了解一下几个概念:
镜像(image):Docker 镜像就是一个只读的模板,镜像可以用来创建 Docker 容器。Docker 提供了一个很简单的机制来创建镜像或者更新现有的镜像,用户甚至可以直接从其他人那里下载一个已经做好的镜像来直接使用。镜像是一种文件结构。Dockerfile中的每条命令都会在文件系统中创建一个新的层次结构,文件系统在这些层次上构建起来,镜像就构建于这些联合的文件系统之上。Docker官方网站专门有一个页面来存储所有可用的镜像,网址是:index.docker.io。
容器( Container):容器是从镜像创建的运行实例。它可以被启动、开始、停止、删除。每个容器都是相互隔离的、保证安全的平台。可以把容器看做是一个简易版的 Linux 环境,Docker 利用容器来运行应用。
仓库:仓库是集中存放镜像文件的场所,仓库注册服务器(Registry)上往往存放着多个仓库,每个仓库中又包含了多个镜像,每个镜像有不同的标签(tag)。目前,最大的公开仓库是 Docker Hub,存放了数量庞大的镜像供用户下载。
2.2 docker定义
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上。Docker是一个重新定义了程序开发测试、交付和部署过程的开放平台,Docker则可以称为构建一次,到处运行,这就是Docker提出的"Build once,Run anywhere"
Docker仓库用来保存我们的images,当我们创建了自己的image之后我们就可以使用push命令将它上传到公有或者私有仓库,这样下次要在另外一台机器上使用这个image时候,只需要从仓库上pull下来就可以了。注意:Docker不是容器,而是管理容器的引擎!
Docker中文手册上解释说:Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的、可移植的、自给自足的容器。开发者在笔记本上编译测试通过的容器可以批量地在生产环境中部署,包括VMs(虚拟机)、bare metal、OpenStack 集群和其他的基础应用平台。
从这里我们可以看出,Docker并非是容器,而是管理容器的引擎。Docker是为应用打包、部署的平台,而非单纯的虚拟化技术。
3、docker安装
3.1 环境准备
先检查你的机器是否支持硬件虚拟化技术(Hardware Virtualization Technology)并且已被启用。什么是硬件虚拟化技术
对于windows系统,可以通过两种方式查看CPU是否支持虚拟化,具体操作步骤及方法点击这里
你可以在 任务管理器->性能 中查看到你的电脑是否开启了虚拟化
3.2 下载docker
下载地址1:http://mirrors.aliyun.com/docker-toolbox/windows/docker-toolbox/
下载地址2:https://docs.docker.com/toolbox/overview/
3.3 安装docker
安装没有什么特别注意的,安装完成后,桌面上会增加三个图标:
双击Docker Quickstart Terminal图标,就会启动一个终端,第一次启动的话你会看到命令行会输出一些东西,这是docker在初始化配置,等待一下,它会配置Docker Toolbox,之后,当它完成后,你会看到启动成功的画面。
这个终端是运行在bash环境下的,而不是标准的windows命令行,因为Docker需要运行在bash环境下,否则一些命令无法运行。
4、docker入门
4.1 查看docker版本信息
输入docker version
4.2 查看所有容器
输入docker ps -a
4.3 检查Docker,Compose和Machine的版本
4.4 运行docker run hello-world以测试从Docker Hub中拉取图像并启动容器
5、docker国内源加速
在搜索镜像或下载的时候会出现类似Error response from daemon: Get https://index.docker.io/v1/search?q=sameersbn&n=25: dial tcp: lookup index.docker.io on 192.168.65.1:53: read udp 192.168.65.2:45190->192.168.65.1:53: i/o timeout这样的提示,主要原因是镜像都在国外,访问过慢,所以我们需要换成国内的docker源加速,下面这个是免费的,速度很快,很赞!https://www.daocloud.io/mirror#accelerator-doc,具体更改步骤如下:
到刚才的网站注册一个id,然后就可以看到对应系统的镜像加速地址了,记下地址,然后在终端中依次打入下面四条命令(替换其中的加速地址)。
docker-machine ssh ubuntu
sudo sed -i "s|EXTRA_ARGS='|EXTRA_ARGS='--registry-mirror=index.docker.io/khwunchai/zeppelin-hdp |g" /var/lib/boot2docker/profile
exit
docker-machine restart ubuntu
1
2
3
4
这样就可以飞速的pull和search镜像了。
6、安装ubuntu系统镜像
国内源我们已经更新好了,现在试一下安装镜像的速度吧,输入docker search ubuntu后,不会再提示上步出现的错误,而是很快返回镜像的库说明,再输入docker pull ubuntu安装ubuntu镜像,如图所示:
输入docker run -it ubuntu bash进入ubuntu系统,输入exit可以退出容器
docker 1.8版本后,windows下有新版docker承载客户端docker toolbox替代了原来的boot2docker
docker toolbox安装后,运行过程中可以配置一系列windows环境变量,让windows命令行终端中也能运行docker命令,就和linux下直接运行docker命令一样的效果,激动吧。但遗憾的是并不傻瓜化,toolbox在start虚拟机后,还需要运行一些命令,才能在windows终端中直接运行docker命令:
1、启动一个docker虚拟机(本处暂定容器名为default),注意toolbox和boot2docker不一样的地方在boot2docker始终只有一个默认虚拟机,而于toolbox可以初始化多个虚拟机了,可以分散存储镜像不用担心硬盘空间的问题
>docker-machine start default
结果:
Starting VM...
Started machines may have new IP addresses. You may need to re-run the `docker-machine env` command.
docker主动提示下一步应该进行的操作,其实也就是本文所说的配置环境变量
如果不配置,尝试一下直接运行
>docker ps
报错:
Get http://127.0.0.1:2375/v1.20/containers/json: dial tcp 127.0.0.1:2375: ConnectEx tcp: No connection could be made because the target machine actively refused it..
* Are you trying to connect to a TLS-enabled daemon without TLS?
* Is your docker daemon up and running?
docker认为你并没有启动虚拟机
2、按照上一步操作docker的提示运行命令
>docker-machine env default
显示:
export DOCKER_TLS_VERIFY="1"
export DOCKER_HOST="tcp://192.168.99.100:2376"
export DOCKER_CERT_PATH="C:\Users\Administrator\.docker\machine\machines\default"
export DOCKER_MACHINE_NAME="default"
# Run this command to configure your shell:
# eval "$(docker-machine env default)"
显示结果就是你应该运行来配置环境变量的命令,docker帮你打印出来方便下一步执行
但是客官看得到,命令是export,这是linux下配置环境变量的命令而不是windows的
3、记得docker安装的时候有个安装可选项MSSYS-git UNIX tools吗,这个工具就是让你在windows下运行linux命令的工具,其实就是一堆linux命令的windows版,现在进入sh环境
>sh
显示:
sh-3.1$
现在可以运行上一步的操作提示
sh-3.1$ export DOCKER_TLS_VERIFY="1"
sh-3.1$ export DOCKER_HOST="tcp://192.168.99.100:2376"
sh-3.1$ export DOCKER_CERT_PATH="C:\Users\Administrator\.docker\machine\machines\default"
sh-3.1$ export DOCKER_MACHINE_NAME="default"
这样环境变量就配置好了,但是复制黏贴运行4条命令不觉得麻烦吗,其实docker已经告诉你怎么操作比较方便了
sh-3.1$ eval "$(docker-machine env default)"
一条语句搞定
4、现在在sh环境下再次尝试运行:
>docker ps
CONTAINER ID IMAGE COMMAND
e3fc159255c2 yohobuysns "/bin/bash" ................
b35da18c020c redis "/entrypoint.sh redis" ...................
84ca9ffb72ff memcached "memcached" ....................
大功告成
注意:在sh环境下配置好环境变量后,就不要再退出sh环境了,退出运行docker命令的话客户端又会报docker进程未启动的错,只能在sh环境中使用docker命令。总结使用起来还是太繁杂,不够傻瓜化,当然docker的底层lxc本来就是linux的独享,能在windows下经由虚拟机运行起来已经不错了,希望以后通过和微软的合作能打通windows底层,让docker在windows下的运行也和linux下一样便捷。
---------------------
在WSL上连接windows的Docker Daemon
相信大多数朋友使用WSL并不是为了实际开发,而是为了熟悉linux 操作.既然如此,让docker在WSL上真正跑起来,完全是有意义的.
在已经安装好docker的windows上打开cmd命令行,执行docker-machine ls可以看到当前本机运行的docker daemon.URL就是进程运行的地址.
在WSL的ubuntu上执行
docker -H 192.168.99.100:2376
1
提示Are you trying to connect to a TLS-enabled daemon without TLS?
显然需要配置证书,可以在config配置文件当中设置免TLS连接,但是毕竟不是安全的做法.关于TLS的原理可以查看:TLS整理(下):TLS如何保证安全
不管你看了原理还是没看,下一步应该在客户端,也就是WSL的linux上配置证书与密钥.
在windows的cmd中执行:
docker-machine regenerate-certs --client-certs default
1
注: default是我本机的docker server的名称. 可对应上图中的NAME修改.
执行完毕,生成密钥文件ca.pem,cert.pem,key.pem
在你的windows的
C:\Users\<windows系统登录用户名>\.docker\machine\machines\default(对应NAME)文件夹当中.
在WSL当中访问/mnt/c/ 然后得到上述 ca.pem,cert.pem,key.pem三个文件,复制到/home/你的ubuntu用户文件夹/.docker 当中(比如我的是/home/chrisyang/.docker/).如不清楚目标文件夹,在WSL中执行docker即可看到.
在WSL中运行
docker -H 192.168.99.100:2376 --tlsverify version
1
成功打印出client和server的版本信息,连接完成.
执行
docker -H 192.168.99.100:2376 --tlsverify run hello-world
---------------------
目前对docker支持最好的是Ubuntu系统,docker不支持在windows上运行,必须借助docker-machine。docker提供了toolbox用于在windows和mac平台安装docker。
工具箱包括:
docker machine
Docker Engine
Kitematic
docker命令行运行环境
Oracle VM VirtualBox
安装之前需要检查BIOS中虚拟化的设置是否已打开,参考此页面
1、下载安装文件
https://www.docker.com/toolbox
2、双击安装文件进行安装
3、运行docker run hello-world
运行时出现下面的问题
| 1 2 3 |
|
如下解决:
| 1 2 |
|
显示环境变量:
| 1 2 3 4 5 6 7 |
|
设置环境变量:
| 1 |
|
再次运行:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
配置加速器:
| 1 2 3 4 |
|
注意
docker用户的密码是tcuser
可用于winscp传输文件
Docker为C/S架构,服务端为docker daemon,客户端为docker.service.支持本地unix socket域套接字通信与远程socket通信。默认为本地unix socket通信,要支持远程客户端访问需要做如下设置(仅用于测试,生产环境开启会极大增加不安全性:由于开了监听端口,任何人可以通过远程连接到docker daemon服务器进行操作):
1、设置daemon监听连接:
添加本地默认监听端口,模式为IP:port
Ubuntu:
修改daemon配置:/etc/docker/daemon.json,添加如下行:
复制代码 代码如下:
{"hosts": ["fd://", "tcp://0.0.0.0:2375"]}(需要花括号,如果有多行设置,每行都需要花括号,设置了fd://自动便是unix socket
重启docker:
| 1 |
|
查看有了“-H”表示成功
| 1 2 3 4 |
|
Centos7:
/etc/docker/daemon.json会被docker.service的配置文件覆盖,直接添加daemon.json不起作用。可以有如下几种设置:
1、直接编辑配置文件:Centos中docker daemon配置文件在/lib/systemd/system/docker.service,找到以下字段,在后面添加如下,注意,此处不能用"fd://",否则报错
| 1 2 3 4 |
|
执行
| 1 2 |
|
2、systemctl edit docker.service,或者编辑vim /etc/systemd/system/docker.service.d/override.conf(必须这样,少一行都不行,unix://也不能按官方写fd://)
| 1 2 3 |
|
同样执行
| 1 2 |
|
最后查看是否成功,添加了-H参数,启动了端口(端口默认为2375,但是可以改):
| 1 2 3 4 5 |
|
一、软件准备
1、基础docker镜像:ubuntu,目前最新的版本是18
2、需准备的环境软件包:

(1) spark-2.3.0-bin-hadoop2.7.tgz (2) hadoop-2.7.3.tar.gz (3) apache-hive-2.3.2-bin.tar.gz (4) jdk-8u101-linux-x64.tar.gz (5) mysql-5.5.45-linux2.6-x86_64.tar.gz、mysql-connector-java-5.1.37-bin.jar (6) scala-2.11.8.tgz (7) zeppelin-0.8.0-bin-all.tgz
二、ubuntu镜像准备
1、获取官方的镜像:
docker pull ubuntu
2、因官方镜像中的apt源是国外资源,后续扩展安装软件包时较麻烦。先修改为国内源:
(1)启动ubuntu容器,并进入容器中的apt配置目录
| 1 |
|
(2)先将原有的源文件备份:
| 1 |
|
(3)换为国内源,这里提供阿里的资源。因官方的ubuntu没有艰装vi等软件,使用echo指令写入。需注意一点,资源必须与系统版本匹配。
| 1 2 3 4 5 6 7 8 9 10 |
|
3、退出容器,提交镜像
| 1 2 |
|
生成的ubuntu镜像,就可以做为基础镜像使用。
三、spark-hadoop集群配置
先前所准备的一列系软件包,在构建镜像时,直接用RUN ADD指令添加到镜像中,这里先将一些必要的配置处理好。这些配置文件,都来自于各个软件包中的conf目录下。
1、Spark配置
(1)spark-env.sh
声明Spark需要的环境变量
SPARK_MASTER_WEBUI_PORT=8888 export SPARK_HOME=$SPARK_HOME export HADOOP_HOME=$HADOOP_HOME export MASTER=spark://hadoop-maste:7077 export SCALA_HOME=$SCALA_HOME export SPARK_MASTER_HOST=hadoop-maste export JAVA_HOME=/usr/local/jdk1.8.0_101 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
(2)spark-default.conf
关于spark的默认配置
spark.executor.memory=2G spark.driver.memory=2G spark.executor.cores=2 #spark.sql.codegen.wholeStage=false #spark.memory.offHeap.enabled=true #spark.memory.offHeap.size=4G #spark.memory.fraction=0.9 #spark.memory.storageFraction=0.01 #spark.kryoserializer.buffer.max=64m #spark.shuffle.manager=sort #spark.sql.shuffle.partitions=600 spark.speculation=true spark.speculation.interval=5000 spark.speculation.quantile=0.9 spark.speculation.multiplier=2 spark.default.parallelism=1000 spark.driver.maxResultSize=1g #spark.rdd.compress=false spark.task.maxFailures=8 spark.network.timeout=300 spark.yarn.max.executor.failures=200 spark.shuffle.service.enabled=true spark.dynamicAllocation.enabled=true spark.dynamicAllocation.minExecutors=4 spark.dynamicAllocation.maxExecutors=8 spark.dynamicAllocation.executorIdleTimeout=60 #spark.serializer=org.apache.spark.serializer.JavaSerializer #spark.sql.adaptive.enabled=true #spark.sql.adaptive.shuffle.targetPostShuffleInputSize=100000000 #spark.sql.adaptive.minNumPostShufflePartitions=1 ##for spark2.0 #spark.sql.hive.verifyPartitionPath=true #spark.sql.warehouse.dir spark.sql.warehouse.dir=/spark/warehouse
(3)节点声明文件,包括masters文件及slaves文件
主节点声明文件:masters
hadoop-maste
从节点文件:slaves
hadoop-node1 hadoop-node2
2、Hadoop配置
(1)hadoop-env.sh
声明Hadoop需要的环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_101
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_IDENT_STRING=$USER
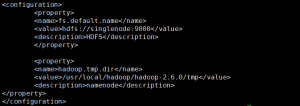
(2)hdfs-site.xml
主要设置了Hadoop的name及data节点。name节点存储的是元数据,data存储的是数据文件
<?xml version="1.0"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop2.7/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop2.7/dfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
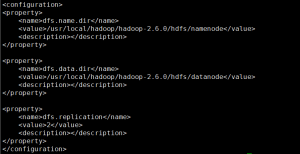
(3)core-site.xml
设置主节点的地址:hadoop-maste。与后面启动容器时,设置的主节点hostname要一致。
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-maste:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.oozie.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.oozie.groups</name>
<value>*</value>
</property>
</configuration>
(4)yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-maste</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-maste:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-maste:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-maste:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop-maste:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-maste:8088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>5</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>22528</value>
<discription>每个节点可用内存,单位MB</discription>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>4096</value>
<discription>单个任务可申请最少内存,默认1024MB</discription>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
<discription>单个任务可申请最大内存,默认8192MB</discription>
</property>
</configuration>
(5)mapred-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<!-- 配置实际的Master主机名和端口-->
<value>hadoop-maste:10020</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/stage</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/mr-history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/mr-history/tmp</value>
</property>
</configuration>
(6)主节点声明文件:master
hadoop-maste
3、hive配置
(1)hive-site.xml
主要两个:一是hive.server2.transport.mode设为binary,使其支持JDBC连接;二是设置mysql的地址。
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop-hive:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>hive.server2.transport.mode</name>
<value>binary</value>
</property>
<property>
<name>hive.server2.thrift.http.port</name>
<value>10001</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop-mysql:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>
</configuration>
4、Zeppelin配置
(1)zeppelin-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_101 export MASTER=spark://hadoop-maste:7077 export SPARK_HOME=$SPARK_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
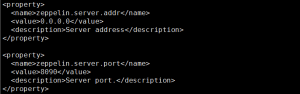
(2)zeppelin-site.xml
http端口默认8080,这里改为18080。为方便加载第三方包,mvnRepo也改为阿里的源。
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>zeppelin.server.addr</name> <value>0.0.0.0</value> <description>Server address</description> </property> <property> <name>zeppelin.server.port</name> <value>18080</value> <description>Server port.</description> </property> <property> <name>zeppelin.server.ssl.port</name> <value>18443</value> <description>Server ssl port. (used when ssl property is set to true)</description> </property> <property> <name>zeppelin.server.context.path</name> <value>/</value> <description>Context Path of the Web Application</description> </property> <property> <name>zeppelin.war.tempdir</name> <value>webapps</value> <description>Location of jetty temporary directory</description> </property> <property> <name>zeppelin.notebook.dir</name> <value>notebook</value> <description>path or URI for notebook persist</description> </property> <property> <name>zeppelin.notebook.homescreen</name> <value></value> <description>id of notebook to be displayed in homescreen. ex) 2A94M5J1Z Empty value displays default home screen</description> </property> <property> <name>zeppelin.notebook.homescreen.hide</name> <value>false</value> <description>hide homescreen notebook from list when this value set to true</description> </property> <property> <name>zeppelin.notebook.storage</name> <value>org.apache.zeppelin.notebook.repo.GitNotebookRepo</value> <description>versioned notebook persistence layer implementation</description> </property> <property> <name>zeppelin.notebook.one.way.sync</name> <value>false</value> <description>If there are multiple notebook storages, should we treat the first one as the only source of truth?</description> </property> <property> <name>zeppelin.interpreter.dir</name> <value>interpreter</value> <description>Interpreter implementation base directory</description> </property> <property> <name>zeppelin.interpreter.localRepo</name> <value>local-repo</value> <description>Local repository for interpreter's additional dependency loading</description> </property> <property> <name>zeppelin.interpreter.dep.mvnRepo</name> <value>http://maven.aliyun.com/nexus/content/groups/public/</value> <description>Remote principal repository for interpreter's additional dependency loading</description> </property> <property> <name>zeppelin.dep.localrepo</name> <value>local-repo</value> <description>Local repository for dependency loader</description> </property> <property> <name>zeppelin.helium.node.installer.url</name> <value>https://nodejs.org/dist/</value> <description>Remote Node installer url for Helium dependency loader</description> </property> <property> <name>zeppelin.helium.npm.installer.url</name> <value>http://registry.npmjs.org/</value> <description>Remote Npm installer url for Helium dependency loader</description> </property> <property> <name>zeppelin.helium.yarnpkg.installer.url</name> <value>https://github.com/yarnpkg/yarn/releases/download/</value> <description>Remote Yarn package installer url for Helium dependency loader</description> </property> <property> <name>zeppelin.interpreters</name> <value>org.apache.zeppelin.spark.SparkInterpreter,org.apache.zeppelin.spark.PySparkInterpreter,org.apache.zeppelin.rinterpreter.RRepl,org.apache.zeppelin.rinterpreter.KnitR,org.apache.zeppelin.spark.SparkRInterpreter,org.apache.zeppelin.spark.SparkSqlInterpreter,org.apache.zeppelin.spark.DepInterpreter,org.apache.zeppelin.markdown.Markdown,org.apache.zeppelin.angular.AngularInterpreter,org.apache.zeppelin.shell.ShellInterpreter,org.apache.zeppelin.file.HDFSFileInterpreter,org.apache.zeppelin.flink.FlinkInterpreter,,org.apache.zeppelin.python.PythonInterpreter,org.apache.zeppelin.python.PythonInterpreterPandasSql,org.apache.zeppelin.python.PythonCondaInterpreter,org.apache.zeppelin.python.PythonDockerInterpreter,org.apache.zeppelin.lens.LensInterpreter,org.apache.zeppelin.ignite.IgniteInterpreter,org.apache.zeppelin.ignite.IgniteSqlInterpreter,org.apache.zeppelin.cassandra.CassandraInterpreter,org.apache.zeppelin.geode.GeodeOqlInterpreter,org.apache.zeppelin.jdbc.JDBCInterpreter,org.apache.zeppelin.kylin.KylinInterpreter,org.apache.zeppelin.elasticsearch.ElasticsearchInterpreter,org.apache.zeppelin.scalding.ScaldingInterpreter,org.apache.zeppelin.alluxio.AlluxioInterpreter,org.apache.zeppelin.hbase.HbaseInterpreter,org.apache.zeppelin.livy.LivySparkInterpreter,org.apache.zeppelin.livy.LivyPySparkInterpreter,org.apache.zeppelin.livy.LivyPySpark3Interpreter,org.apache.zeppelin.livy.LivySparkRInterpreter,org.apache.zeppelin.livy.LivySparkSQLInterpreter,org.apache.zeppelin.bigquery.BigQueryInterpreter,org.apache.zeppelin.beam.BeamInterpreter,org.apache.zeppelin.pig.PigInterpreter,org.apache.zeppelin.pig.PigQueryInterpreter,org.apache.zeppelin.scio.ScioInterpreter,org.apache.zeppelin.groovy.GroovyInterpreter</value> <description>Comma separated interpreter configurations. First interpreter become a default</description> </property> <property> <name>zeppelin.interpreter.group.order</name> <value>spark,md,angular,sh,livy,alluxio,file,psql,flink,python,ignite,lens,cassandra,geode,kylin,elasticsearch,scalding,jdbc,hbase,bigquery,beam,groovy</value> <description></description> </property> <property> <name>zeppelin.interpreter.connect.timeout</name> <value>30000</value> <description>Interpreter process connect timeout in msec.</description> </property> <property> <name>zeppelin.interpreter.output.limit</name> <value>102400</value> <description>Output message from interpreter exceeding the limit will be truncated</description> </property> <property> <name>zeppelin.ssl</name> <value>false</value> <description>Should SSL be used by the servers?</description> </property> <property> <name>zeppelin.ssl.client.auth</name> <value>false</value> <description>Should client authentication be used for SSL connections?</description> </property> <property> <name>zeppelin.ssl.keystore.path</name> <value>keystore</value> <description>Path to keystore relative to Zeppelin configuration directory</description> </property> <property> <name>zeppelin.ssl.keystore.type</name> <value>JKS</value> <description>The format of the given keystore (e.g. JKS or PKCS12)</description> </property> <property> <name>zeppelin.ssl.keystore.password</name> <value>change me</value> <description>Keystore password. Can be obfuscated by the Jetty Password tool</description> </property> <!-- <property> <name>zeppelin.ssl.key.manager.password</name> <value>change me</value> <description>Key Manager password. Defaults to keystore password. Can be obfuscated.</description> </property> --> <property> <name>zeppelin.ssl.truststore.path</name> <value>truststore</value> <description>Path to truststore relative to Zeppelin configuration directory. Defaults to the keystore path</description> </property> <property> <name>zeppelin.ssl.truststore.type</name> <value>JKS</value> <description>The format of the given truststore (e.g. JKS or PKCS12). Defaults to the same type as the keystore type</description> </property> <!-- <property> <name>zeppelin.ssl.truststore.password</name> <value>change me</value> <description>Truststore password. Can be obfuscated by the Jetty Password tool. Defaults to the keystore password</description> </property> --> <property> <name>zeppelin.server.allowed.origins</name> <value>*</value> <description>Allowed sources for REST and WebSocket requests (i.e. http://onehost:8080,http://otherhost.com). If you leave * you are vulnerable to https://issues.apache.org/jira/browse/ZEPPELIN-173</description> </property> <property> <name>zeppelin.anonymous.allowed</name> <value>true</value> <description>Anonymous user allowed by default</description> </property> <property> <name>zeppelin.username.force.lowercase</name> <value>false</value> <description>Force convert username case to lower case, useful for Active Directory/LDAP. Default is not to change case</description> </property> <property> <name>zeppelin.notebook.default.owner.username</name> <value></value> <description>Set owner role by default</description> </property> <property> <name>zeppelin.notebook.public</name> <value>true</value> <description>Make notebook public by default when created, private otherwise</description> </property> <property> <name>zeppelin.websocket.max.text.message.size</name> <value>1024000</value> <description>Size in characters of the maximum text message to be received by websocket. Defaults to 1024000</description> </property> <property> <name>zeppelin.server.default.dir.allowed</name> <value>false</value> <description>Enable directory listings on server.</description> </property> </configuration>
三、集群启动脚本
整套环境启动较为烦琐,这里将需要的操作写成脚本,在容器启动时,自动运行。
1、环境变量
先前在处理集群配置中,用到许多环境变量,这里统一做定义profile文件,构建容器时,用它替换系统的配置文件,即/etc/profile
profile文件:
if [ "$PS1" ]; then
if [ "$BASH" ] && [ "$BASH" != "/bin/sh" ]; then
# The file bash.bashrc already sets the default PS1.
# PS1='\h:\w\$ '
if [ -f /etc/bash.bashrc ]; then
. /etc/bash.bashrc
fi
else
if [ "`id -u`" -eq 0 ]; then
PS1='# '
else
PS1='$ '
fi
fi
fi
if [ -d /etc/profile.d ]; then
for i in /etc/profile.d/*.sh; do
if [ -r $i ]; then
. $i
fi
done
unset i
fi
export JAVA_HOME=/usr/local/jdk1.8.0_101
export SCALA_HOME=/usr/local/scala-2.11.8
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export SPARK_HOME=/usr/local/spark-2.3.0-bin-hadoop2.7
export HIVE_HOME=/usr/local/apache-hive-2.3.2-bin
export MYSQL_HOME=/usr/local/mysql
export PATH=$HIVE_HOME/bin:$MYSQL_HOME/bin:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
2、SSH配置
各个容器需要通过网络端口连接在一起,为方便连接访问,使用SSH无验证登录
ssh_config文件:
Host localhost StrictHostKeyChecking no Host 0.0.0.0 StrictHostKeyChecking no Host hadoop-* StrictHostKeyChecking no
3、Hadoop集群脚本
(1)启动脚本:start-hadoop.sh
#!/bin/bash echo -e "\n" hdfs namenode -format -force echo -e "\n" $HADOOP_HOME/sbin/start-dfs.sh echo -e "\n" $HADOOP_HOME/sbin/start-yarn.sh echo -e "\n" $SPARK_HOME/sbin/start-all.sh echo -e "\n" hdfs dfs -mkdir /mr-history hdfs dfs -mkdir /stage echo -e "\n":
(2)重启脚本:restart-hadoop.sh
#!/bin/bash echo -e "\n" echo -e "\n" $HADOOP_HOME/sbin/start-dfs.sh echo -e "\n" $HADOOP_HOME/sbin/start-yarn.sh echo -e "\n" $SPARK_HOME/sbin/start-all.sh echo -e "\n" hdfs dfs -mkdir /mr-history hdfs dfs -mkdir /stage echo -e "\n"
3、Mysql脚本
(1)mysql 初始化脚本:init_mysql.sh
#!/bin/bash cd /usr/local/mysql/ echo ..........mysql_install_db --user=root................. nohup ./scripts/mysql_install_db --user=root & sleep 3 echo ..........mysqld_safe --user=root................. nohup ./bin/mysqld_safe --user=root & sleep 3 echo ..........mysqladmin -u root password 'root'................. nohup ./bin/mysqladmin -u root password 'root' & sleep 3 echo ..........mysqladmin -uroot -proot shutdown................. nohup ./bin/mysqladmin -uroot -proot shutdown & sleep 3 echo ..........mysqld_safe................. nohup ./bin/mysqld_safe --user=root & sleep 3 echo ........................... nohup ./bin/mysql -uroot -proot -e "grant all privileges on *.* to root@'%' identified by 'root' with grant option;" sleep 3 echo ........grant all privileges on *.* to root@'%' identified by 'root' with grant option...............
4、Hive脚本
(1)hive初始化:init_hive.sh
#!/bin/bash cd /usr/local/apache-hive-2.3.2-bin/bin sleep 3 nohup ./schematool -initSchema -dbType mysql & sleep 3 nohup ./hive --service metastore & sleep 3 nohup ./hive --service hiveserver2 & sleep 5 echo Hive has initiallized!
四、镜像构建
(1)Dockfile
FROM ubuntu:lin
MAINTAINER reganzm 183943842@qq.com
ENV BUILD_ON 2018-03-04
COPY config /tmp
#RUN mv /tmp/apt.conf /etc/apt/
RUN mkdir -p ~/.pip/
RUN mv /tmp/pip.conf ~/.pip/pip.conf
RUN apt-get update -qqy
RUN apt-get -qqy install netcat-traditional vim wget net-tools iputils-ping openssh-server libaio-dev apt-utils
RUN pip install pandas numpy matplotlib sklearn seaborn scipy tensorflow gensim #--proxy http://root:1qazxcde32@192.168.0.4:7890/
#添加JDK
ADD ./software/jdk-8u101-linux-x64.tar.gz /usr/local/
#添加hadoop
ADD ./software/hadoop-2.7.3.tar.gz /usr/local
#添加scala
ADD ./software/scala-2.11.8.tgz /usr/local
#添加spark
ADD ./software/spark-2.3.0-bin-hadoop2.7.tgz /usr/local
#添加Zeppelin
ADD ./software/zeppelin-0.8.0-bin-all.tgz /usr/local
#添加mysql
ADD ./software/mysql-5.5.45-linux2.6-x86_64.tar.gz /usr/local
RUN mv /usr/local/mysql-5.5.45-linux2.6-x86_64 /usr/local/mysql
ENV MYSQL_HOME /usr/local/mysql
#添加hive
ADD ./software/apache-hive-2.3.2-bin.tar.gz /usr/local
ENV HIVE_HOME /usr/local/apache-hive-2.3.2-bin
RUN echo "HADOOP_HOME=/usr/local/hadoop-2.7.3" | cat >> /usr/local/apache-hive-2.3.2-bin/conf/hive-env.sh
#添加mysql-connector-java-5.1.37-bin.jar到hive的lib目录中
ADD ./software/mysql-connector-java-5.1.37-bin.jar /usr/local/apache-hive-2.3.2-bin/lib
RUN cp /usr/local/apache-hive-2.3.2-bin/lib/mysql-connector-java-5.1.37-bin.jar /usr/local/spark-2.3.0-bin-hadoop2.7/jars
#增加JAVA_HOME环境变量
ENV JAVA_HOME /usr/local/jdk1.8.0_101
#hadoop环境变量
ENV HADOOP_HOME /usr/local/hadoop-2.7.3
#scala环境变量
ENV SCALA_HOME /usr/local/scala-2.11.8
#spark环境变量
ENV SPARK_HOME /usr/local/spark-2.3.0-bin-hadoop2.7
#Zeppelin环境变量
ENV ZEPPELIN_HOME /usr/local/zeppelin-0.8.0-bin-all
#将环境变量添加到系统变量中
ENV PATH $HIVE_HOME/bin:$MYSQL_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$ZEPPELIN_HOME/bin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$PATH
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && \
chmod 600 ~/.ssh/authorized_keys
COPY config /tmp
#将配置移动到正确的位置
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/profile /etc/profile && \
mv /tmp/masters $SPARK_HOME/conf/masters && \
cp /tmp/slaves $SPARK_HOME/conf/ && \
mv /tmp/spark-defaults.conf $SPARK_HOME/conf/spark-defaults.conf && \
mv /tmp/spark-env.sh $SPARK_HOME/conf/spark-env.sh && \
mv /tmp/zeppelin-env.sh $ZEPPELIN_HOME/conf/zeppelin-env.sh && \
mv /tmp/zeppelin-site.xml $ZEPPELIN_HOME/conf/zeppelin-site.xml && \
cp /tmp/hive-site.xml $SPARK_HOME/conf/hive-site.xml && \
mv /tmp/hive-site.xml $HIVE_HOME/conf/hive-site.xml && \
mv /tmp/hadoop-env.sh $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/master $HADOOP_HOME/etc/hadoop/master && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/start-hadoop.sh ~/start-hadoop.sh && \
mkdir -p /usr/local/hadoop2.7/dfs/data && \
mkdir -p /usr/local/hadoop2.7/dfs/name && \
mv /tmp/init_mysql.sh ~/init_mysql.sh && chmod 700 ~/init_mysql.sh && \
mv /tmp/init_hive.sh ~/init_hive.sh && chmod 700 ~/init_hive.sh && \
mv /tmp/restart-hadoop.sh ~/restart-hadoop.sh && chmod 700 ~/restart-hadoop.sh && \
mv /tmp/zeppelin-daemon.sh ~/zeppelin-daemon.sh && chmod 700 ~/zeppelin-daemon.sh
#创建Zeppelin环境需要的目录,设置在zeppelin-env.sh中
RUN mkdir /var/log/zeppelin && mkdir /var/run/zeppelin && mkdir /var/tmp/zeppelin
RUN echo $JAVA_HOME
#设置工作目录
WORKDIR /root
#启动sshd服务
RUN /etc/init.d/ssh start
#修改start-hadoop.sh权限为700
RUN chmod 700 start-hadoop.sh
#修改root密码
RUN echo "root:555555" | chpasswd
CMD ["/bin/bash"]
(2)构建脚本:build.sh
echo build Spark-hadoop images docker build -t="spark" .
(3)构建镜像,执行:
./build.sh
五、容器构建脚本
(1)创建子网
所有的网络,通过内网连接,这里构建一个名为spark的子网:build_network.sh
echo create network docker network create --subnet=172.16.0.0/16 spark echo create success docker network ls
(2)容器启动脚本:start_container.sh
echo start hadoop-hive container... docker run -itd --restart=always --net spark --ip 172.16.0.5 --privileged --name hive --hostname hadoop-hive --add-host hadoop-node1:172.16.0.3 --add-host hadoop-node2:172.16.0.4 --add-host hadoop-mysql:172.16.0.6 --add-host hadoop-maste:172.16.0.2 --add-host zeppelin:172.16.0.7 spark-lin /bin/bash echo start hadoop-mysql container ... docker run -itd --restart=always --net spark --ip 172.16.0.6 --privileged --name mysql --hostname hadoop-mysql --add-host hadoop-node1:172.16.0.3 --add-host hadoop-node2:172.16.0.4 --add-host hadoop-hive:172.16.0.5 --add-host hadoop-maste:172.16.0.2 --add-host zeppelin:172.16.0.7 spark-lin /bin/bash echo start hadoop-maste container ... docker run -itd --restart=always --net spark --ip 172.16.0.2 --privileged -p 18032:8032 -p 28080:18080 -p 29888:19888 -p 17077:7077 -p 51070:50070 -p 18888:8888 -p 19000:9000 -p 11100:11000 -p 51030:50030 -p 18050:8050 -p 18081:8081 -p 18900:8900 -p 18088:8088 --name hadoop-maste --hostname hadoop-maste --add-host hadoop-node1:172.16.0.3 --add-host hadoop-node2:172.16.0.4 --add-host hadoop-hive:172.16.0.5 --add-host hadoop-mysql:172.16.0.6 --add-host zeppelin:172.16.0.7 spark-lin /bin/bash echo "start hadoop-node1 container..." docker run -itd --restart=always --net spark --ip 172.16.0.3 --privileged -p 18042:8042 -p 51010:50010 -p 51020:50020 --name hadoop-node1 --hostname hadoop-node1 --add-host hadoop-hive:172.16.0.5 --add-host hadoop-mysql:172.16.0.6 --add-host hadoop-maste:172.16.0.2 --add-host hadoop-node2:172.16.0.4 --add-host zeppelin:172.16.0.7 spark-lin /bin/bash echo "start hadoop-node2 container..." docker run -itd --restart=always --net spark --ip 172.16.0.4 --privileged -p 18043:8042 -p 51011:50011 -p 51021:50021 --name hadoop-node2 --hostname hadoop-node2 --add-host hadoop-maste:172.16.0.2 --add-host hadoop-node1:172.16.0.3 --add-host hadoop-mysql:172.16.0.6 --add-host hadoop-hive:172.16.0.5 --add-host zeppelin:172.16.0.7 spark-lin /bin/bash echo "start Zeppeline container..." docker run -itd --restart=always --net spark --ip 172.16.0.7 --privileged -p 38080:18080 -p 38443:18443 --name zeppelin --hostname zeppelin --add-host hadoop-maste:172.16.0.2 --add-host hadoop-node1:172.16.0.3 --add-host hadoop-node2:172.16.0.4 --add-host hadoop-mysql:172.16.0.6 --add-host hadoop-hive:172.16.0.5 spark-lin /bin/bash echo start sshd... docker exec -it hadoop-maste /etc/init.d/ssh start docker exec -it hadoop-node1 /etc/init.d/ssh start docker exec -it hadoop-node2 /etc/init.d/ssh start docker exec -it hive /etc/init.d/ssh start docker exec -it mysql /etc/init.d/ssh start docker exec -it zeppelin /etc/init.d/ssh start echo start service... docker exec -it mysql bash -c "sh ~/init_mysql.sh" docker exec -it hadoop-maste bash -c "sh ~/start-hadoop.sh" docker exec -it hive bash -c "sh ~/init_hive.sh" docker exec -it zeppelin bash -c "$ZEPPELIN_HOME/bin/zeppelin-daemon.sh start" echo finished docker ps
(3)容器停止并移除:stop_container.sh
docker stop hadoop-maste docker stop hadoop-node1 docker stop hadoop-node2 docker stop hive docker stop mysql docker stop zeppelin echo stop containers docker rm hadoop-maste docker rm hadoop-node1 docker rm hadoop-node2 docker rm hive docker rm mysql docker rm zeppelin echo rm containers docker ps
六、运行测试
依次执行如下脚本:
1、创建子网
./build_network.sh
2、启动容器
./start_container.sh
3、进入主节点:
docker exec -it hadoop-maste /bin/bash
jps一下,进程是正常的
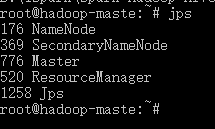
4、访问集群子节点
ssh hadoop-node2
一样可以看到,与主节点类似的进程信息
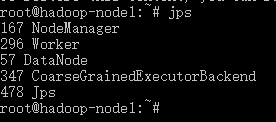
说明集群已经是搭建起来。
5、Spark测试
访问:http://localhost:38080
进入Zeppelin交互界面,新建一个note,使用Spark为默认的解释器
import org.apache.commons.io.IOUtils
import java.net.URL
import java.nio.charset.Charset
// Zeppelin creates and injects sc (SparkContext) and sqlContext (HiveContext or SqlContext)
// So you don't need create them manually
// load bank data
val bankText = sc.parallelize(
IOUtils.toString(
new URL("http://emr-sample-projects.oss-cn-hangzhou.aliyuncs.com/bank.csv"),
Charset.forName("utf8")).split("\n"))
case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
val bank = bankText.map(s => s.split(";")).filter(s => s(0) != "\"age\"").map(
s => Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
).toDF()
bank.registerTempTable("bank")
可视化报表,如下图:

说明Spark已经是成功运行。
对各个模块做个测试
Mysql 测试
1、Mysql节点准备
为方便测试,在mysql节点中,增加点数据
进入主节点
docker exec -it hadoop-maste /bin/bash进入数据库节点
ssh hadoop-mysql创建数据库
create database zeppelin_test;创建数据表
create table user_info(id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(16),age INT);增加几条数据,主键让其自增:
- insert into user_info(name,age) values("aaa",10);
- insert into user_info(name,age) values("bbb",20);
- insert into user_info(name,age) values("ccc",30);
2、Zeppelin配置
配置驱动及URL地址:
- default.driver ====> com.mysql.jdbc.Driver
- default.url ====> jdbc:mysql://hadoop-mysql:3306/zeppelin_test
使zeppelin导入mysql-connector-java库(maven仓库中获取)
mysql:mysql-connector-java:8.0.123、测试mysql查询
- %jdbc
- select * from user_info;
应能打印出先前插入的几条数据。
Hive测试
本次使用JDBC测试连接Hive,注意上一节中,hive-site.xml的一个关键配置,若要使用JDBC连接(即TCP模式),hive.server2.transport.mode应设置为binary。
1、Zeppelin配置
(1)增加hive解释器,在JDBC模式修改如下配置
- default.driver ====> org.apache.hive.jdbc.HiveDriver
-
- default.url ====> jdbc:hive2://hadoop-hive:10000
(2)添加依赖
- org.apache.hive:hive-jdbc:0.14.0
- org.apache.hadoop:hadoop-common:2.6.0
2、测试
Zeppelin增加一个note
增加一个DB:
- %hive
- CREATE SCHEMA user_hive
- %hive
- use user_hive
创建一张表:
- %hive
- create table if not exists user_hive.employee(id int ,name string ,age int)
插入数据:
- %hive
- insert into user_hive.employee(id,name,age) values(1,"aaa",10)
再打印一下:
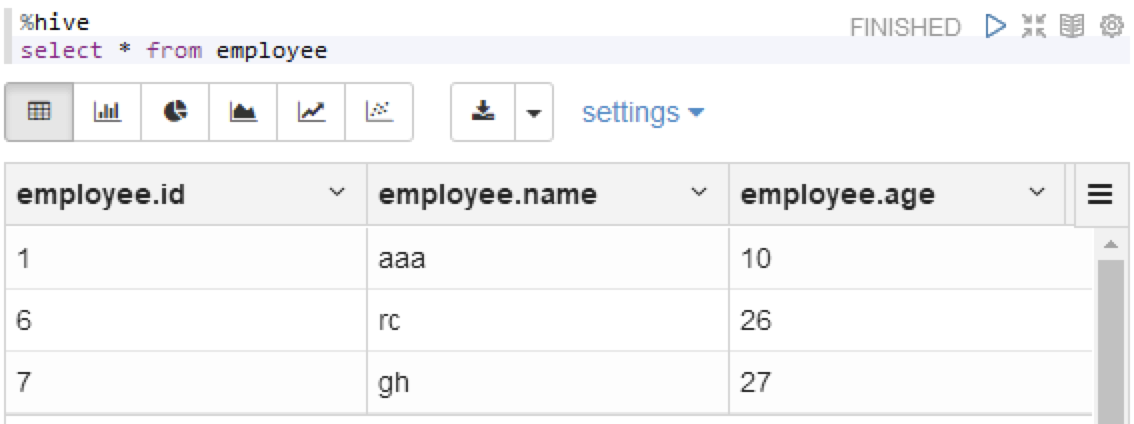
- %hive
- select * from user_hive.employee
所有的操作,都是OK的。
另外,可以从mydql中的hive.DBS表中,查看到刚刚创建的数据库的元信息:
- %jdbc
- select * frmo hive.DBS;
如下: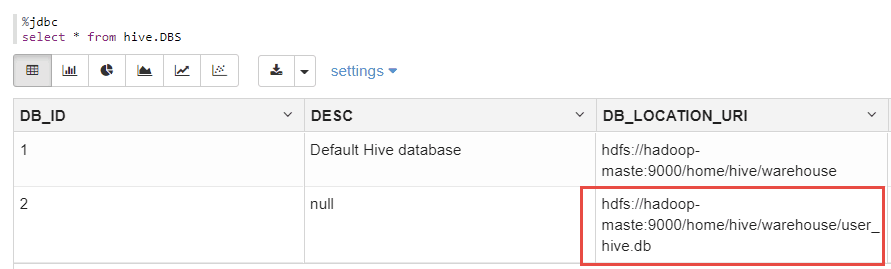
上图显示了刚刚创建的DB的元数据。
登录Hadoop管理后台,应也能看到该文件信息(容器环境将Hadoop的50070端口映射为宿主机的51070)
http://localhost:51070/explorer.html#/home/hive/warehouse/user_hive.db可以看到,user_hive.db/employee下,有刚刚创建的数据文件,如下:
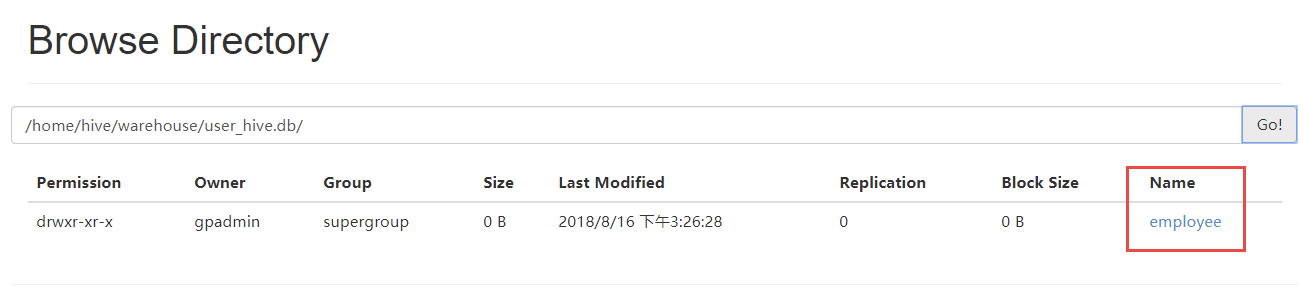
分布式测试
在上一节基础上,进入主从节点,可以看到,在相同的目录下,都存在有相同的数据内容,可见上一节对于hive的操作,在主从节点是都是生效的。操作如下:
主节点:
- root@hadoop-maste:~# hdfs dfs -ls /home/hive/warehouse/user_hive.db/employee
- Found 1 items
- -rwxr-xr-x 2 gpadmin supergroup 9 2018-08-15 11:36 /home/hive/warehouse/user_hive.db/employee/000000_0
从节点:
- root@hadoop-node1:~# hdfs dfs -ls /home/hive/warehouse/user_hive.db/employee
- Found 1 items
- -rwxr-xr-x 2 gpadmin supergroup 9 2018-08-15 11:36 /home/hive/warehouse/user_hive.db/employee/000000_0
测试 Spark 操作 hive
通过spark向刚才创建的user_hive.db中写入两条数据,如下:
- import org.apache.spark.sql.{SQLContext, Row}
- import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType}
- import org.apache.spark.sql.hive.HiveContext
- //import hiveContext.implicits._
-
- val hiveCtx = new HiveContext(sc)
-
- val employeeRDD = sc.parallelize(Array("6 rc 26","7 gh 27")).map(_.split(" "))
-
- val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("age", IntegerType, true)))
-
- val rowRDD = employeeRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt))
-
- val employeeDataFrame = hiveCtx.createDataFrame(rowRDD, schema)
-
- employeeDataFrame.registerTempTable("tempTable")
-
- hiveCtx.sql("insert into user_hive.employee select * from tempTable")

运行之后,查一下hive
- %hive
- select * from employee
可以看到,数据已经写进文件中了