
- 1opensuse 安装docker_opensuse latte dock
- 2AGI之MFM:《多模态基础模型:从专家到通用助手》翻译与解读之视觉理解、视觉生成_multimodal foundation models
- 3oracle基础知识介绍(自己的笔记)_oracle介绍
- 4python3+requests接口自动化测试框架_python+request接口自动化测试框架_python接口自动化框架
- 5Python requirements.txt 详解(项目依赖模块)
- 6网络流问题求解及Gurobi+Python代码(最大流/最小成本网络流/多商品网络流)_gurobi测试代码
- 7ALTER SEQUENCE 语句
- 8C# 基于Emgu类库 调用笔记本摄像头进行脸部识别_c# emgucv方形答题卡识别
- 9Linux 内核配置项详解 myimx6_inet xfrm mode transport
- 10基于Darknet的YOLOv4目标检测的环境配_yolov4环境配置
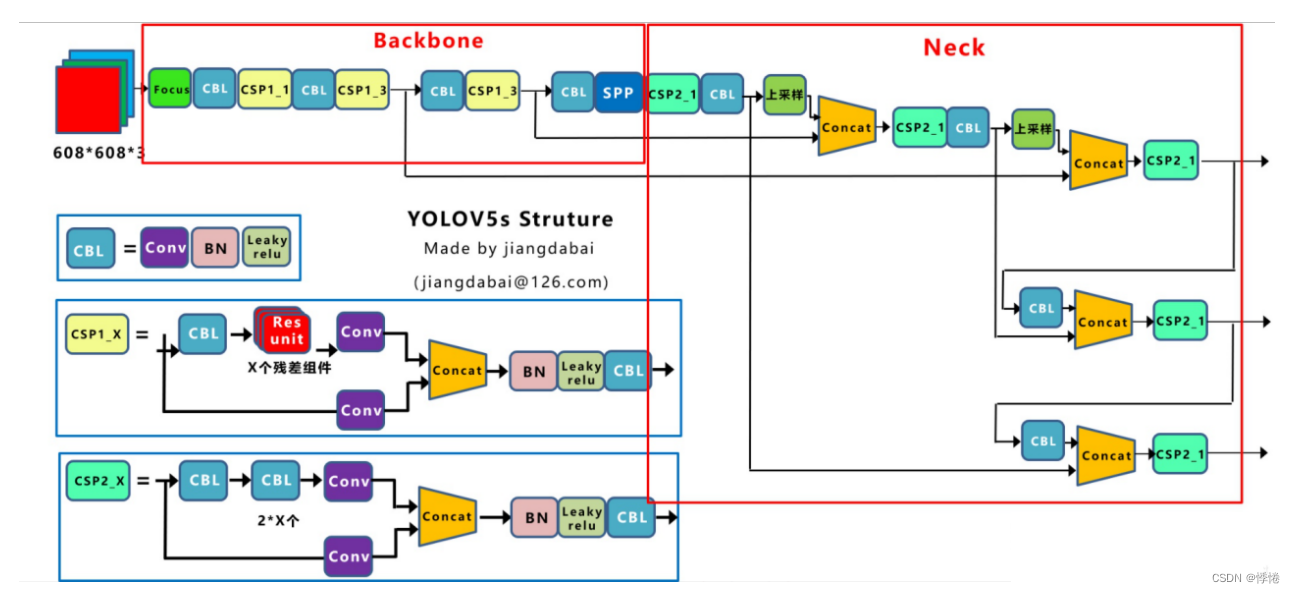
【Yolov系列】Yolov5学习(一):大致框架_yolov5框架
赞
踩
一、Yolov5网络结构
Yolov5特点: 合适于移动端部署,模型小,速度快
Yolov5骨干结构:CSPDarknet53网络
Yolov5主要有Yolov5s、Yolov5m、Yolov5l、Yolov5x四个版本。这几个模型的结构基本一样,不同的是depth_multiple模型深度和width_multiple模型宽度这两个参数。 Yolov5s网络是Yolov5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。
Yolov5不同版本结构示意图:
Yolov5框架示意图:

(1)输入层:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Bockbone:Focus结构、CSP结构
(3)Neck:CSP结构、FPN+PAN结构
(4)Head:CIOU_Loss、NMS非极大值抑制
二、输入端
(1)Mosaic数据增强算法
Yolov5在输入端采用了Mosaic数据增强算法,Mosaic 数据增强算法将多张图片按照一定比例组合成一张图片,使模型在更小的范围内识别目标,Mosaic 数据增强算法一般使用四张进行拼接。

Mosaic数据增强的主要步骤为:
(1)随机选取图片拼接基准点坐标(xc,yc),另随机选取四张图片。
(2)四张图片根据基准点,分别经过尺寸调整和比例缩放后,放置在指定尺寸的大图的左上,右上,左下,右下位置。
(3)根据每张图片的尺寸变换方式,将映射关系对应到图片标签上。
(4)依据指定的横纵坐标,对大图进行拼接。处理超过边界的检测框坐标。
采用Mosaic数据增强的方式有几个优点:
(1)丰富数据集: 随机使用4张图像,随机缩放后随机拼接,增加很多小目标,大大增加了数据多样性。
(2)增强模型鲁棒性: 混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标。
(3)加强批归一化层(Batch Normalization)的效果: 当模型设置 BN 操作后,训练时会尽可能增大批样本总量(BatchSize),因为 BN 原理为计算每一个特征层的均值和方差,如果批样本总量越大,那么 BN 计算的均值和方差就越接近于整个数据集的均值和方差,效果越好。
(4)Mosaic 数据增强算法有利于提升小目标检测性能: Mosaic 数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率包含小目标,从而提升了模型的检测能力。
ps:
Mosaic 数据增强算法参考 了CutMix数据增强算法。CutMix数据增强算法使用两张图片进行拼接,它通过将两张随机样本按比例混合,并分配分类结果,来丰富数据集的多样性并提高模型的鲁棒性和泛化能力。
CutMix数据增强的主要步骤为:
(1)首先随机生成一个裁剪框,然后裁剪掉A图中的相应位置。
(2)用B图相应位置的区域(ROI)放到A图中被裁剪的区域中形成新的样本。
(3)在计算损失时,A区域中被cut掉的位置随机填充训练集中其他数据的区域像素值,分类结果按一定比例分配,采用加权求和的方式进行求解。
CutMix数据增强算法的优缺点:
优点:能生成更具挑战性的训练样本,生成更平滑的决策边界,提高数据增强的多样性,减少过拟合的风险。
缺点:实现需要一定技巧,需要选择合适的参数和调整损失函数等,如果实现不当可能会降低模型性能。
(2)自适应锚框计算
在Yolov3、Yolov4中,对于不同的数据集,都会使用单独的脚本计算先验框 anchor。然后在训练时,网络会在 anchor 的基础上进行预测,输出预测框,再和标签框进行对比,最后进行梯度的反向传播。
在 Yolov5 中,则是将此功能嵌入到整个训练代码里中。所以在每次训练开始之前,它都会根据不同的数据集来自适应计算 anchor。如果觉得计算的锚框效果并不好,也可以在代码中将此功能关闭。
自适应锚框计算的具体过程:
①获取数据集中所有目标的宽和高。
②将每张图片中按照等比例缩放的方式到 resize 指定大小,这里保证宽高中的最大值符合指定大小。
③将 bboxes 从相对坐标改成绝对坐标,这里乘以的是缩放后的宽高。
④筛选 bboxes,保留宽高都大于等于两个像素的 bboxes。
⑤使用 k-means 聚类三方得到n个 anchors,与YOLOv3、YOLOv4 操作一样。
⑥使用遗传算法随机对 anchors 的宽高进行变异。倘若变异后的效果好,就将变异后的结果赋值给 anchors;如果变异后效果变差就跳过,默认变异1000次。这里是使用 anchor_fitness 方法计算得到的适应度 fitness,然后再进行评估。
【Yolov系列】Yolov5学习(一)补充1.1:自适应锚框计算
【Yolov系列】Yolov5学习(一)补充1.2:自适应锚框计算详解+代码注释
(3)自适应图片缩放(Adaptive Image Scaling)
- 根据原始图片大小和imgsz(输入图片大小)计算缩放比例
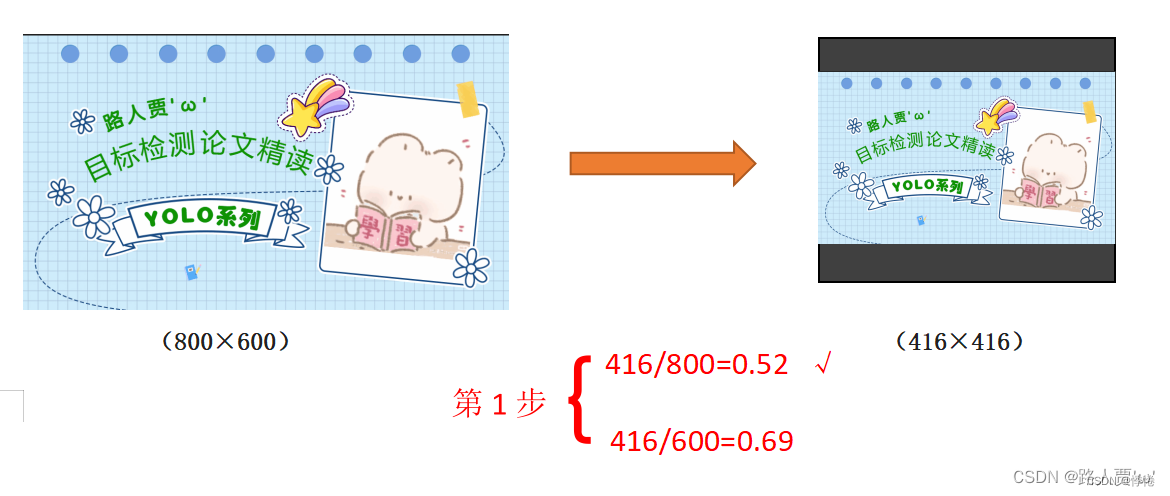
原始图像大小为800*600,imgsz为416*416,除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。 - 根据原始图片大小与缩放系数计算缩放后的图片大小
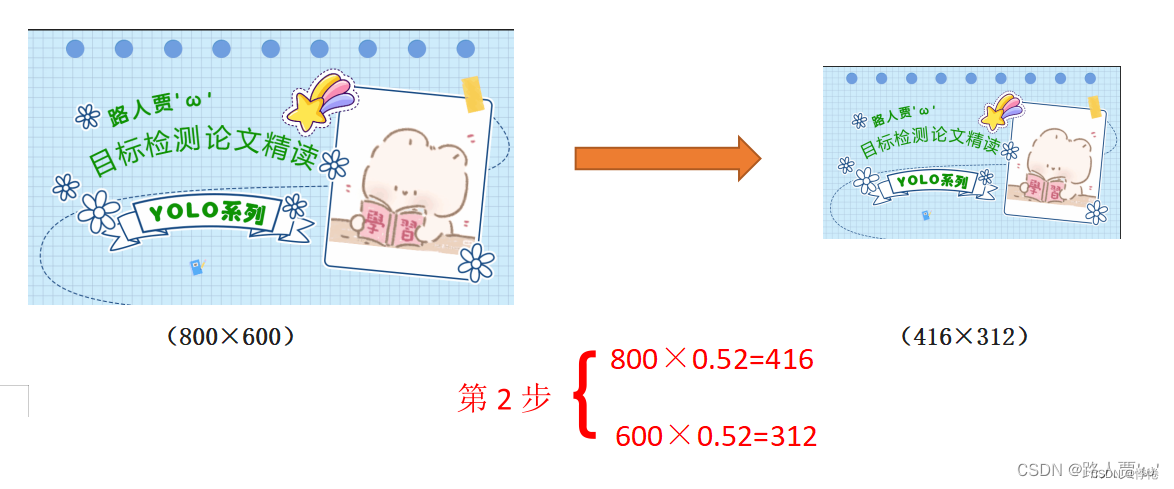
原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。 - 计算黑边填充数值
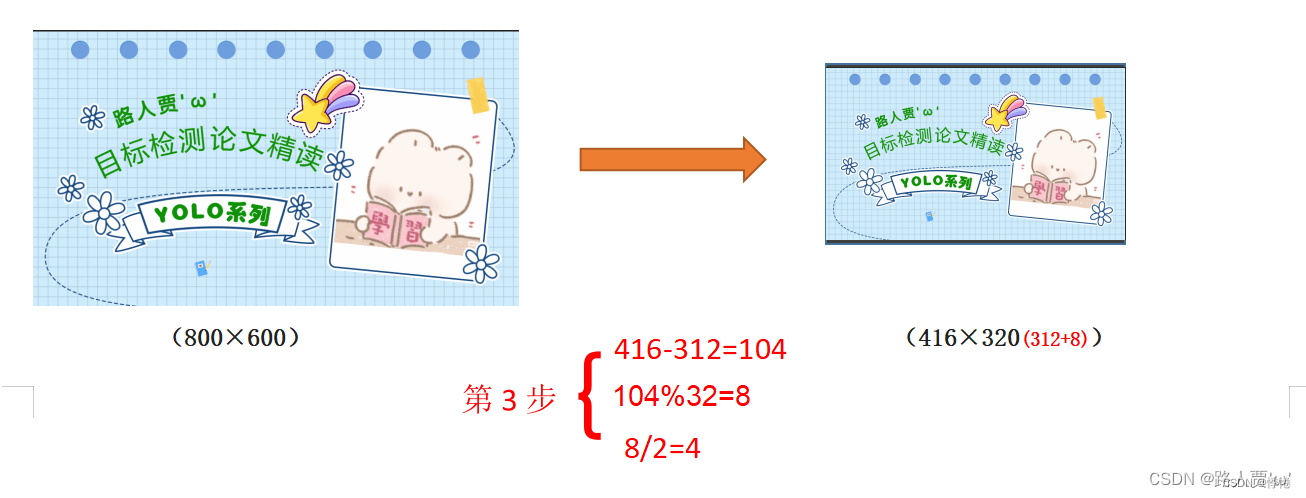
将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到8个像素,再除以2,即得到图片高度两端需要填充的数值。
注意:
(1)Yolov5中填充的是灰色,即(114,114,114)。
(2)训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
(3)为什么np.mod函数的后面用32?
因为YOLOv5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余。以免产生尺度太小走不完stride(filter在原图上扫描时,需要跳跃的格数)的问题,再进行取余。
自适应图片缩放(Adaptive Image Scaling)是一种基于目标尺度的图像缩放方式,它可以自适应地缩放输入图像的尺寸,以适应不同尺度目标的检测,可以有效地解决目标检测中存在的尺度不一致问题,提高检测精度和鲁棒性。
以YOLOv5s为例,详细介绍一下自适应图片缩放的原理和步骤:
阶段 过程 预处理阶段 首先,输入图像将被缩放到一个基准尺寸,如YOLOv5s中的默认基准尺寸是640x640像素
如果输入图像尺寸小于基准尺寸,则会通过插值算法将其缩放到基准尺寸;如果输入图像尺寸大于基准尺寸,则会将其缩放到一个较小的尺寸,并在后续的缩放过程中进行适当调整。网络输入阶段 在图像输入到网络之前,YOLOv5会根据图像中最大目标的尺度,动态地调整输入图像的尺寸。具体来说,YOLOv5会计算出图像中最大目标的尺寸,然后根据一定的缩放规则将图像缩放到一个适当的尺寸,以确保最大目标的尺寸可以被检测到。
例如,在YOLOv5s中,如果最大目标的尺寸小于80x80像素,则将图像缩放到640x640像素;如果最大目标的尺寸大于80x80像素但小于160x160像素,则将图像缩放到1280x1280像素;如果最大目标的尺寸大于160x160像素,则将图像缩放到1920x1920像素。
网络输出阶段 在网络输出时,YOLOv5会根据预测框的位置和尺寸,将检测结果映射回原始图像坐标系。由于输入图像的尺寸可能被缩放过,因此需要进行相应的反缩放操作,以便将检测结果映射回原始图像坐标系中。 性
三、Backbone
(1)Focus结构
Focus结构是一种用于特征提取的卷积神经网络层,用于将输入特征图中的信息进行压缩和组合,从而提取出更高层次的特征表示,它被用作网络中的第一个卷积层,用于对输入特征图进行下采样,以减少计算量和参数量。
Focus模块在Yolov5中是图片进入Backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长得差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以Yolov5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。
切片操作如下:
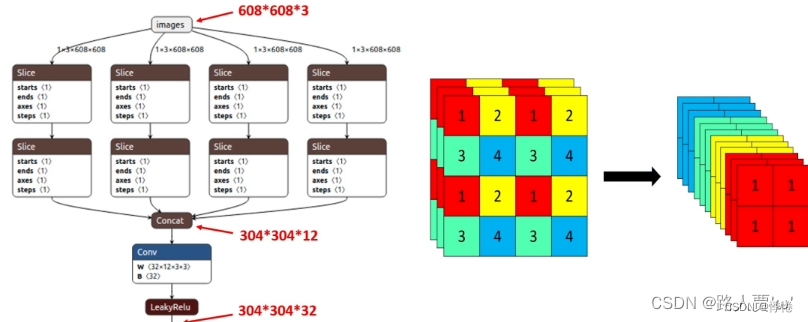
作用: 可以使信息不丢失的情况下提高计算力
不足:Focus 对某些设备不支持且不友好,开销很大,另外切片对不齐的话模型就崩了。
后期改进: 在新版中,Yolov5 将Focus 模块替换成了一个 6 x 6 的卷积层。两者的计算量是等价的,但是对于一些 GPU 设备,使用 6 x 6 的卷积会更加高效。
【Yolov系列】Yolov5学习(一)补充2:Focus模块详解
(2)CSP_1_X结构
术语:
CBL:Conv(卷积层)+BN(Batch Normalization,批归一化)+Leaky ReLU(带泄露的修正线性单元
Leaky ReLU(带泄露的修正线性单元):x>=0,f(x)=x;x<0,f(x)=ax,a为随机超参数,一般取值为0.01。Leaky ReLU是一种激活函数,用于在神经网络中引入非线性。与标准的ReLU函数不同,Leaky ReLU允许负输入值有一个小的非零斜率,这有助于避免在训练过程中出现“死亡ReLU”问题,即某些神经元在训练过程中不再激活。
Concat操作:一种在深度学习中常见的张量拼接方法,主要用于将两个或多个张量(如特征图)在某一维度上进行拼接(如通道数拼接),从而扩充张量的维度。在YOLOv5等目标检测模型中,Concat操作被用于特征融合,特别是在混合尺度特征融合中。在Concat操作中,张量可以在某个维度上不同,但在其他维度上必须相等。
Add操作:通常指的是将两个或多个张量(如特征图)逐元素相加。这种操作在特征融合、残差连接等场景中非常常见。在特征融合方面,Add操作保持通道数不变,特征图相加,使每个通道下的特征信息更加丰富。在Add操作时,相加的张量必须具有相同的形状,因为它们是逐元素相加的。如果张量的形状不匹配,需要先进行必要的调整(如通过插值、裁剪或填充等方法)以确保它们可以正确相加。
Bottleneck(瓶颈层):由三部分组成:
- 1x1 卷积层:用于降低输入的通道数(维度),以减少计算复杂度。这一步主要是为了在保持特征质量的同时减少维度。
- 3x3 卷积层:经过 1x1 卷积层降维后,使用 3x3 卷积核进行特征提取。这一步负责增强特征表示能力。
- 1x1 卷积层:通过 1x1 卷积层将通道数恢复到原始维度。这一步是为了恢复特征的维度,并提供给下一层使用。
- 残差结构:将处理后结果与原特征图执行add操作
Yolov5中主要有两种Bottleneck:BottleneckTrue、BottleneckFalse。BottleneckTrue即为上述Bottleneck结构,BottleneckFalse不包含残差结构。
SPP结构:
SPP是空间金字塔池化,作用是一个实现一个自适应尺寸的输出。(传统的池化层如最大池化、平均池化的输出大小是和输入大小挂钩的,但是我们最后做全连接层实现分类的时候需要指定全连接的输入,所以我们需要一种方法让神经网络在某层得到一个固定维度的输出,而且这种方法最好不是resize(resize会失真),由此SPP应运而生,其最早是何凯明提出,应用于RCNN模型)。
具体参考:SPP和SPPF(in YOLOv5)
混叠效应:在统计、信号处理和相关领域中,混叠是指取样信号被还原成连续信号时产生彼此交叠而失真的现象。当混叠发生时,原始信号无法从取样信号还原。而混叠可能发生在时域上,称做时间混叠,或是发生在频域上,被称作空间混叠。在视觉影像的模拟数字转换或音乐信号领域,混叠都是相当重要的议题。因为在做模拟-数字转换时若取样频率选取不当将造成高频信号和低频信号混叠在一起,因此无法完美地重建出原始的信号。为了避免此情形发生,取样前必须先做滤波的操作。

CSP_1_X结构是YOLOv5网络结构中的一个重要组成部分。这种结构主要应用在Backbone层中,而Backbone是网络中较深的部分。

CSP_1_X结构的特点。它将输入分为两个分支:
- 一个分支先通过CBL:Conv(卷积)+BN(批归一化)+Leaky ReLU(激活函数),再经过多个残差结构(BottleneckTrue * X),然后再进行一次卷积;
- 另一个分支则直接进行卷积。
之后两个分支进行concat操作,再经过BN,进行一次激活,最后再进行一个CBL操作。
CSP_1_X结构作用:可以增加层与层之间反向传播的梯度值,从而避免因为网络加深而带来的梯度消失问题。有助于提取到更细粒度的特征,同时不必担心网络退化的问题。有助于提升网络的目标检测性能。
四、Neck
(1)CSP_2_X结构
CSP_2_X结构的特点。它将输入分为两个分支:
- 一个分支先通过CBL:Conv(卷积)+BN(批归一化)+Leaky ReLU(激活函数),再经过多个CBL结构(CBL*2*X),然后再进行一次卷积;
- 另一个分支则直接进行卷积。
之后两个分支进行concat操作,再经过BN,进行一次激活,最后再进行一个CBL操作。
CSP_2_X结构作用:有助于提取到更细粒度的特征,同时不必担心网络退化的问题。有助于提升网络的目标检测性能。
(2)FPN+PAN结构
1. FPN(Feature Pyramid Networks,特征金字塔网络)
FPN论文地址:Feature Pyramid Networks for Object Detection
原来多数的目标检测算法仅仅根据最终的特征图输出做预测,但是对于目标检测算法特征图的特征来说:低层的特征语义信息比较少但目标位置准确;高层的特征语义信息丰富但目标位置粗略。因此识别不同尺寸的目标一直是目标检测的难点,尤其是小目标检测。
FPN(Feature Pyramid Networks,特征图金字塔网络)是2017年提出的一种网络,主要解决的是物体检测中的多尺度问题,在基本不增加原有模型计算量的情况下,通过简单的网络连接改变,大幅度提升了小物体的检测性能。
目前多尺度目标检测的图像算法有以下几种:
(1)图像金字塔
- 将输入图像resize成不同尺寸,得到图像金字塔(下图左侧为图像金字塔);
- 利用卷积神经网络在图像金字塔上进行特征提取,构建出特征金字塔(下图右侧为特征金字塔);
- 得到特征金字塔后,对特征金字塔分别进行预测,最后统计所有尺寸的预测结果。

(2)Feature map预测
直接对图像进行特征提取,仅使用神经网络某一层输出的feature map进行预测,一般是网络最后一层feature map(例如Fast R-CNN、Faster R-CNN、VGG16等)。
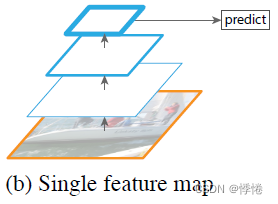
ps:
靠近网络输入层的feature map包含粗略的位置信息,导致预测的目标狂bbox不准确,靠近最后网络最后一层的feature map会忽略小物体信息。
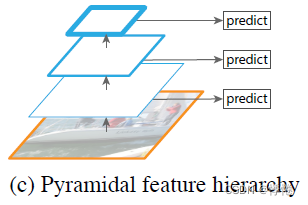
(3)特征金字塔
同时利用低层特征和高层特征,分别在不同的层同时进行预测。像SSD(Single Shot Detector)就是采用这种多尺度特征融合的方式,从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量(正向传播都已经计算出来了)。但是SSD没有使用足够底层的特征,SSD使用最底层的特征是VGG的conv4_3。
(4)FPN(特征金字塔网络)
把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息,得到高分辨率、强语义的特征(即加强了特征的提取)。具体操作为对网络最后一层的feature map做上采样,上采样的结果再与对应尺寸的feature map进行融合,融合结果分别进行预测。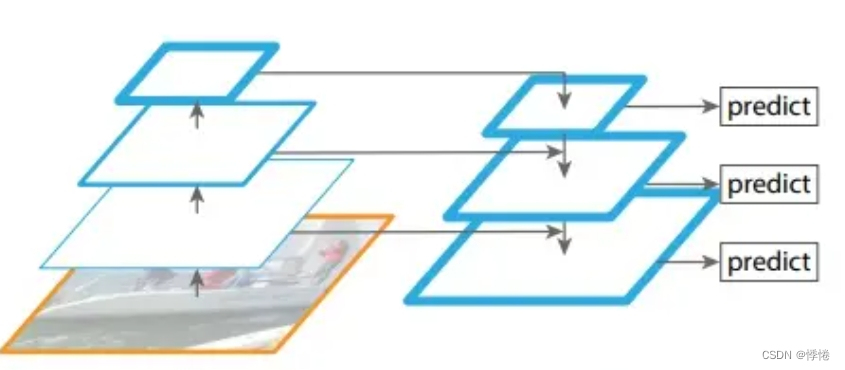
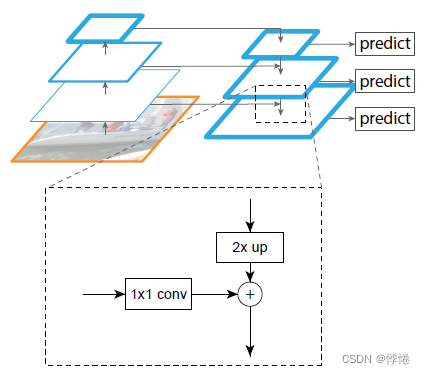
FPN网络大致结构如下:一个自底向上的线路、一个自顶向下的线路、横向连接(lateral connection,图中放大的区域是横向连接)
4-1 自底而上
自底向上的过程就是神经网络普通的前向传播过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,将不改变feature map大小的层归为一步,因此每次抽取的特征都是每步的最后一个层输出,这样就能构成特征金字塔。
4-2 自顶而下
把高层特征图进行上采样(比如最近邻上采样),然后把该特征横向连接(lateral connections )至前一层特征,因此高层特征得到加强。
上采样几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素,从而扩大原图像的大小。通过对特征图进行上采样,使得上采样后的特征图具有和下一层的特征图相同的大小,这样做主要是为了利用底层的位置细节信息。
上采样:
【Yolov系列】Yolov5学习(一)补充2:Focus模块详解 第一节相关知识中的第二小节上采样相关知识
4-3 横向连接
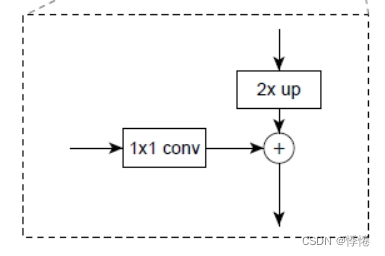
1*1 conv:前一层的特征图经过1*1的卷积核卷积,目的为改变通道数,使得特征图通道数和后一层上采样的特征图通道数相同,便于特征图融合。
连接方式:像素间的加法,add操作。
Yolov5中的连接方式是concat操作。
重复迭代该过程,直至生成最精细的特征图。得到精细的特征图之后,用3*3的卷积核再去卷积已经融合的特征图,目的是消除上采样的混叠效应,以生成最后需要的特征图。
2. PAN
PAN 结构自底向上进行下采样,使顶层特征包含图像位置信息,两个特征最后进行融合,使不同尺寸的特征图都包含图像语义信息和图像特征信息,保证了对不同尺寸的图片的准确预测。
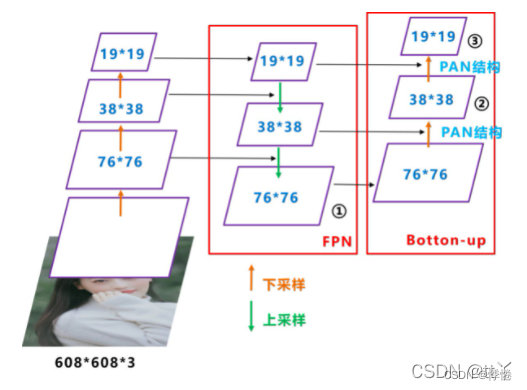

具体操作为:
- 在FPN的自上而下形成的特征金字塔的基础上,复制FPN特征金字塔中最下方的feature map,变成PAN特征金字塔的最底层;
- 对PAN特征金字塔的最底层进行一个下采样操作,同时对原特征金字塔的倒数第二层进行卷积操作;
- 将FPN特征金字塔倒数第二层卷积结果与下采样后的最底层进行concat操作,特征图融合后的尺寸发生变化。
3. FPN+PAN
FPN层自顶向下传达强语义特征(高层语义是经过特征提取后得到的特征信息,它的感受野较大,提取的特征抽象,有利于物体的分类,但会丢失细节信息,不利于精确分割。高层语义特征是抽象的特征)。而PAN则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合。
五、Head
(1)CIOU_LOSS
目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。Yolov5的损失函数构成为:
- Classificition Loss(分类损失函数):二元交叉熵损失函数(BCE loss)
- Bounding Box Regeression Loss(回归损失函数):CIOU_LOSS
Bounding Box Regeression Loss近些年的发展过程是:IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
1. IOU_Loss
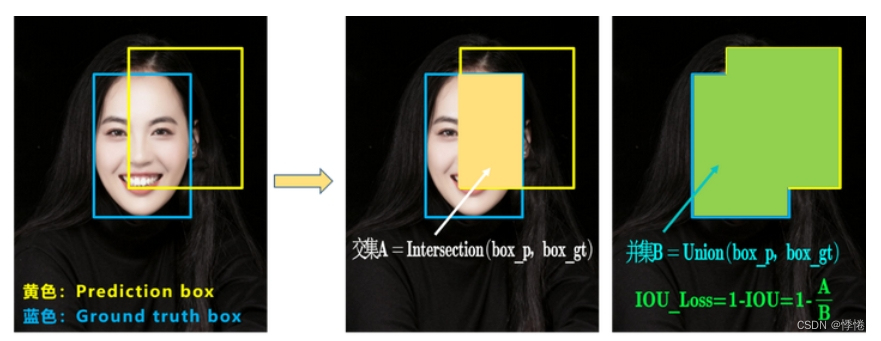
IOU_Loss的计算简单,主要是使用交并集面积,但存在着两个问题。

- 如状态1所示,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
- 如状态2、3所示,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。
2. GIOU_Loss
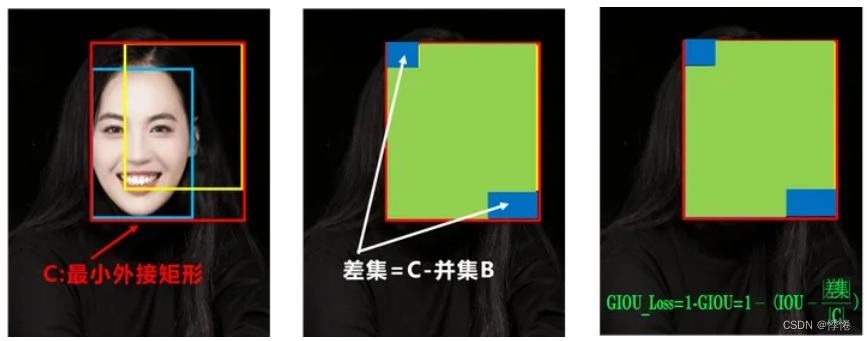
GIOU_Loss相比于IOU_Loss增加了最小外接矩形和相交尺度的衡量方式,缓解了IOU_Loss的问题。但仍存在一个问题。

- 如状态1、2、3所示,预测框在目标框内部且预测框大小一致的情况下,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。
3. DIOU_Loss
好的目标框回归损失函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。
针对IOU和GIOU存在的问题,主要从两个方面进行考虑:
- 如何最小化预测框和目标框之间的归一化距离?
- 如何在预测框和目标框重叠时,回归的更准确?
针对第一个问题,DIOU_Loss(Distance_IOU_Loss)由此诞生

DIOU_Loss考虑了重叠面积和中心点距离,当目标框包裹预测框的时候,直接度量2个框的中心点距离,因此DIOU_Loss收敛的更快。
但DIOU_Loss并没有考虑长宽比。
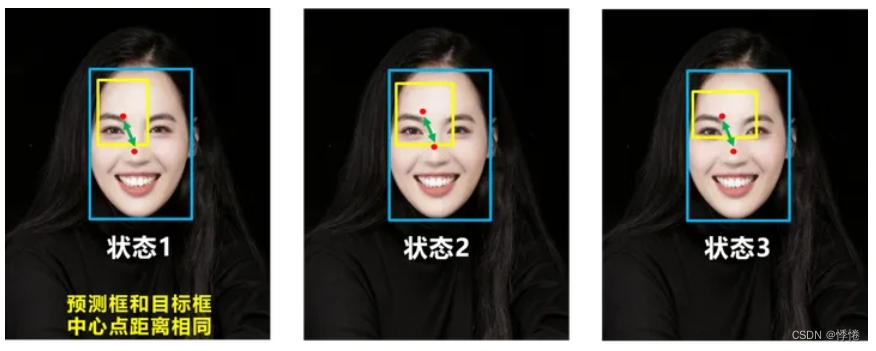
-
如状态1、2、3所示,目标框包裹预测框,且预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。
4. CIOU_Loss
CIOU_Loss和DIOU_Loss前面的公式都是一样的,但是在此基础上增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。
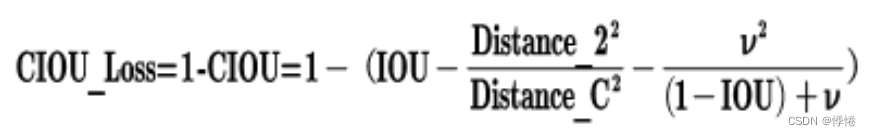
其中v是衡量长宽比一致性的参数,可以定义为:
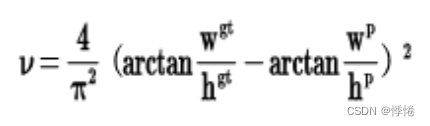
这样CIOU_Loss就将目标框回归损失函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了。
5. Loss函数不同点
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
Yolov5中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。
(2)NMS非极大值抑制
NMS 的本质是搜索局部极大值,抑制非极大值元素。
非极大值抑制,主要就是用来抑制检测时冗余的框。因为在目标检测中,在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,所以我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
算法流程:
- 对所有预测框的置信度降序排序;
- 选出置信度最高的预测框,确认其为正确预测,并计算他与其他预测框的 IOU;
- 根据步骤2中计算的 IOU 去除重叠度高的,IOU > threshold 阈值就直接删除;
- 剩下的预测框返回第1步,直到没有剩下的为止。
IOU( Intersection over Union):预测框(Bounding Box)与真实框(Ground Truth Box)之间的重叠程度。计算方式如下:
- 交集(Intersection):预测框与真实框之间的重叠区域面积。
- 并集(Union):预测框与真实框所占的总区域面积,包括它们之间的非重叠部分。
- IOU 值:交集面积除以并集面积,得到一个介于 0 和 1 之间的数值。IOU 值越接近 1,表示预测框与真实框的重叠程度越高,预测越准确;反之,IOU 值越接近 0,表示预测框与真实框的重叠程度越低,预测越不准确。
SoftNMS:
当两个目标靠的非常近时,置信度低的会被置信度高的框所抑制,那么当两个目标靠的十分近的时候就只会识别出一个 BBox。为了解决这个问题,可以使用 SoftNMS。SoftNMS的基本思想是用稍低一点的分数来代替原有的分数,而不是像 NMS 一样直接置零。
DIOU_nms:
将IOU计算部分改为DIOU方式,在重叠的目标检测时考虑边界框中心点的位置信息,重叠的目标也可以回归出来。
对于一些遮挡重叠的目标,确实会有一些改进,虽然大多数状态下效果差不多,但在不增加计算成本的情况下,有稍微的改进也是好的。
注意:CIOU_Loss计算中包含影响因子v,涉及groudtruth的信息,而测试推理时,是没有groundtruth的。因此不更改为CIOU方式


六、参考文章
一文搞懂激活函数(Sigmoid/ReLU/LeakyReLU/PReLU/ELU)
什么是FPN(Feature Pyramid Networks--特征金字塔)?
Yolov5代码解析(输入端、BackBone、Neck、输出端))

