
- 1用 Sentence Transformers v3 训练和微调嵌入模型
- 2网络中常见攻击及其防御方式_smurf攻击
- 3华为od机试真题:火星符号运算(Python)
- 4git 克隆/拉取分支指定目录(稀疏检出)_git clone 分支个别文件夹
- 5git配置gitlab报错:Clone failed: Could not create work tree dir ‘ppt_indicators‘: Permission denied
- 6【计算机网络】一文带你弄懂DNS解析过程(最强详解!!)
- 7Ubuntu 20.04 LTS 安装zabbix监控部署_ubuntu20.04安装zabbix
- 8苹果开源iOS和macOS内核源代码 | 十一献礼_macos 和 ios 内核 xnu 可编译源代码
- 9Prometheus 监控 RabbitMQ
- 10用Python写个方面级情感分析系统
CNN(卷积神经网络)基础网络总结_widerestnet
赞
踩
一.网络分类
按网络结构、网络性质分为
- VGG系列网络
- 基于Inception块的网络
- 基于残差结构的网络
- 轻量型网络
- 注意力机制相关网络
- 其他变种
共计18种基础网络
二.详细介绍
1.VGG系列
VGG系列主要包括VGG11、VGG13、VGG16、VGG19,结构大差不差,都是由基本模块进行堆叠而成
(1)核心思想:
将大卷积核(例如:5x5,7x7)转化为多个小卷积(3x3)核进行替代,5x5conv用2个3x3conv代替,7x7conv用3个3x3卷积进行代替
(2)网络结构:
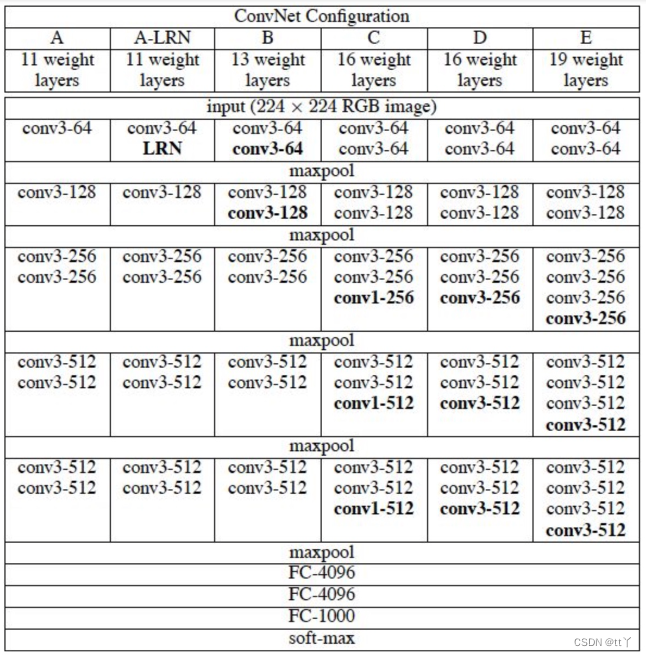
不论VGG11、VGG13、VGG16还是VGG19都是由以下结构构成的
- 5层卷积
- 每层卷积之间使用maxpool连接
- 所有激活函数均使用ReLU函数
- 3层全连接层(FC)
- softmax输出层
其中每层卷积层使用的卷积尺寸均为3x3,并且每经过一层卷积,通道数翻倍,直到输出通道数达到512
更加直观的结构图如下图
(3)VGG系列的优缺点
优点:
1.结构简单
整个网络都是由3x3conv和2x2的maxpool构成+3个FC+softmax
2.使用小卷积核
通过使用小卷积核代替大卷积核,减少参数,相当于进行了更多非线性映射
VGG模型能够实现多次非线性变换。这种设计允许网络在不同的抽象层次上逐步提取特征,从简单的边缘、纹理到复杂的形状和物体组成部分。相较于使用单个大卷积核(如7x7或更大),多层小卷积核构成的深度结构能够构建出更丰富、更复杂的特征表示,从而提高模型对各种视觉模式的识别和区分能力
3.小池化层
跟AlexNet3x3池化相比VGG池化均采用2x2的池化核
4.层数更深,特征图更宽
卷积核集中在通道数的扩大上
缺点:
1.耗费更多的计算资源
2.内存占用大(140M)
VGG有三个FC层,绝大多数参数来自FC层
2.基于Inception块的网络
Inception块
将多个卷积或者池化操作进行并联,组成一个网络模块,将其视为一个整体,以这个整体为单位去组装整个网络
基本的Inception块
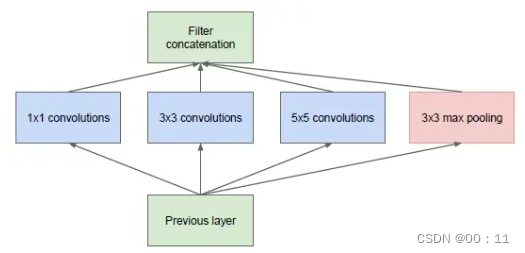
加宽了网络结构,实际上inception背后的基本假设是跨通道相关性和空间相关性的充分解耦
(1)GoogleNet
a.GoogleNet的Inception块

注:每个conv后都有一个ReLU
b.1x1 conv
多个卷积卷积操作进行并联容易产生太多参数
卷积层可学习参数个数 = 输入通道数 x 输出通道数 x 卷积尺寸
例如:(inputchannel = 64 ,outputchannel = 128 ,3)的卷积操作可学习参数个数为 64*128*3 = 24,576个
所以引入1x1 conv
1x1卷积在空间维度上不做任何操作,不改变宽高,用于实现升维和降维,1x1卷积可以实现特征图的降维,有效减少模型参数量和计算复杂度,有助于模型轻量化。相反,使用更多输出通道则可实现升维,增加模型的表达能力
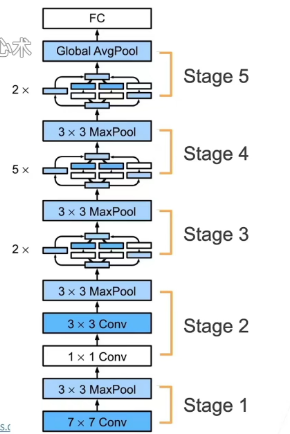
c.网络结构
5个stage,9个inception块
(2)InceptionV3
a.InceptionV3的Inception块
stage2:
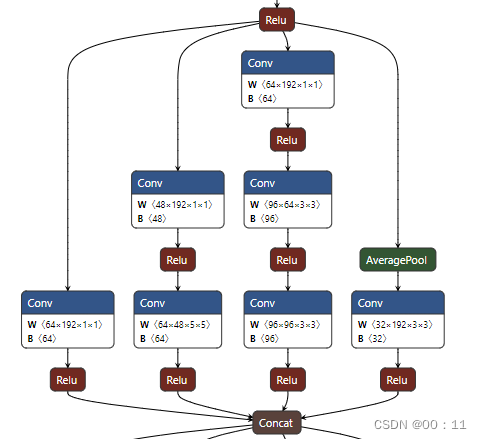
stage3:

stage4:
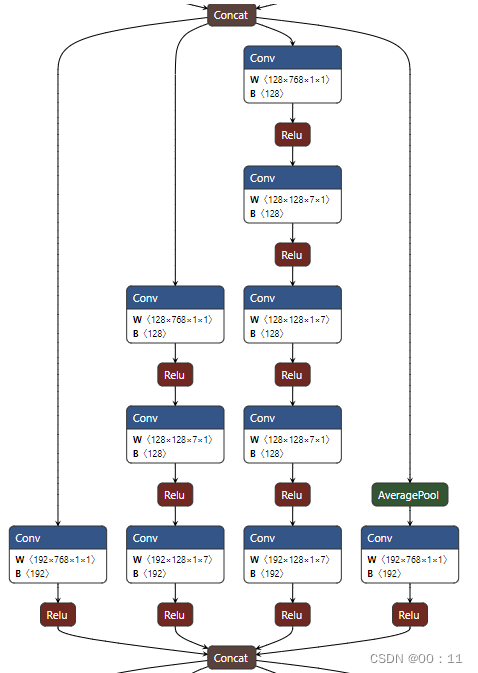
stage5:
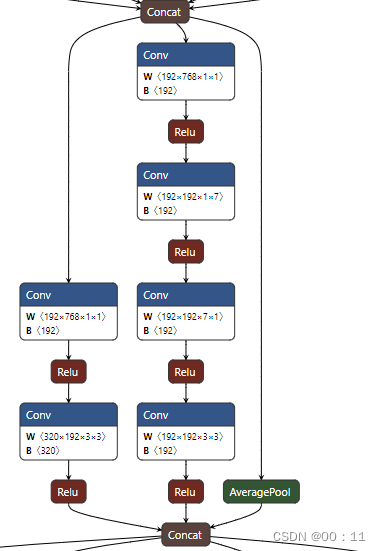
stage 6:

b. 改进
将部分3x3卷积换成1x7和7x1
c.网络结构
stage1:
每个conv后接一个relu

stage2:
3个stage2对应的基本模块进行堆叠
stage3:
1个stage3对应的基本模块进行堆叠
stage4:
4个stage4对应的基本模块进行堆叠
stage5:
1个stage5对应的基本模块进行堆叠
stage6:
2个stage6对应的基本模块进行堆叠
全局均值池化 globalaveragepool
(3)InceptionV4
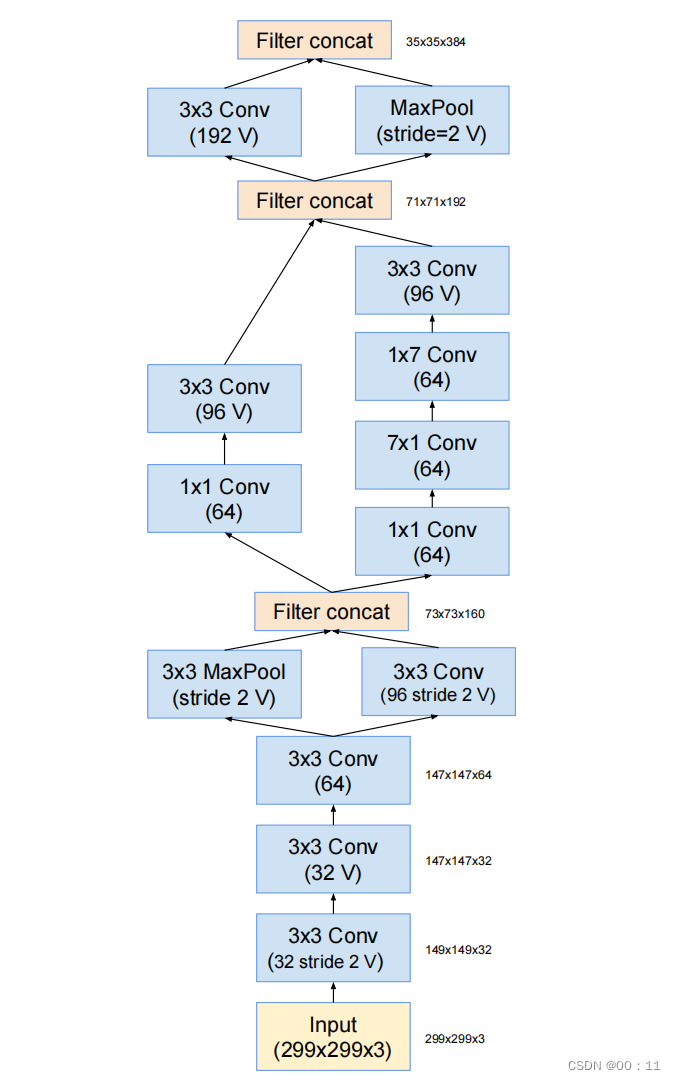
InceptionV4的三种基础Inception结构与InceptionV3中使用的结构基本一样,但InceptionV4引入了一些新的模块形状及连接设计,在网络的早期阶段引入了“Stem”模块,用于快速降低特征图的分辨率,从而减少后续Inception模块的计算量
a.基本模块
stem模块:
在网络的早期进行引入,快速降低特征图分辨率,减少后续计算量
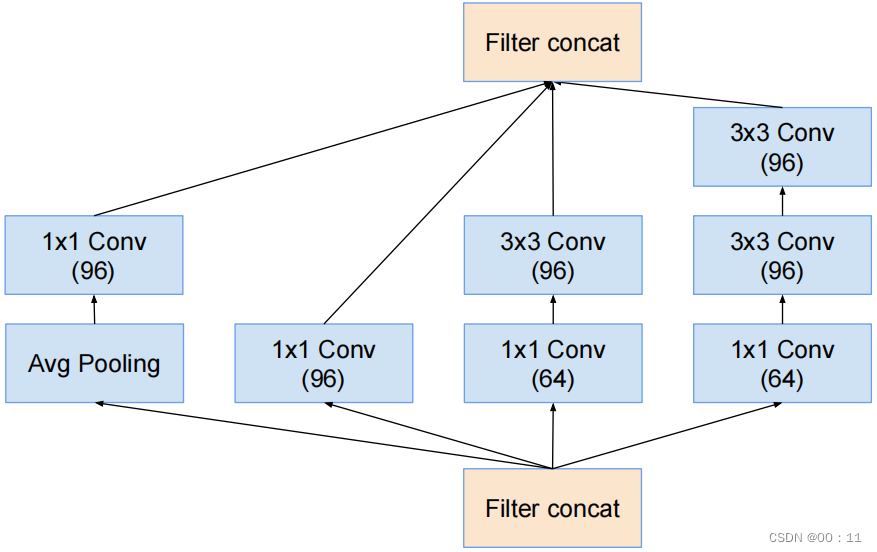
Inception-A结构:
Redution-A结构:
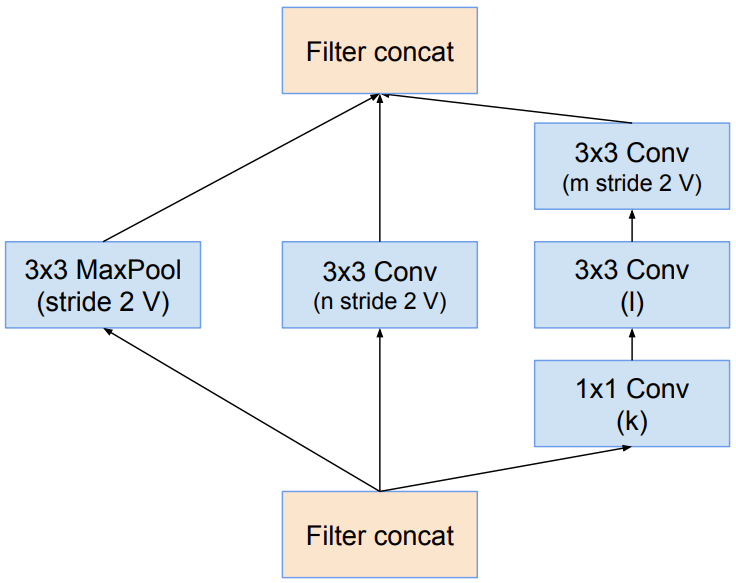
Inception B:
对应InceptionV3中结构的Ⅱ,将Inception的1x3conv和3x1conv变成了1x7conv和7x1conv
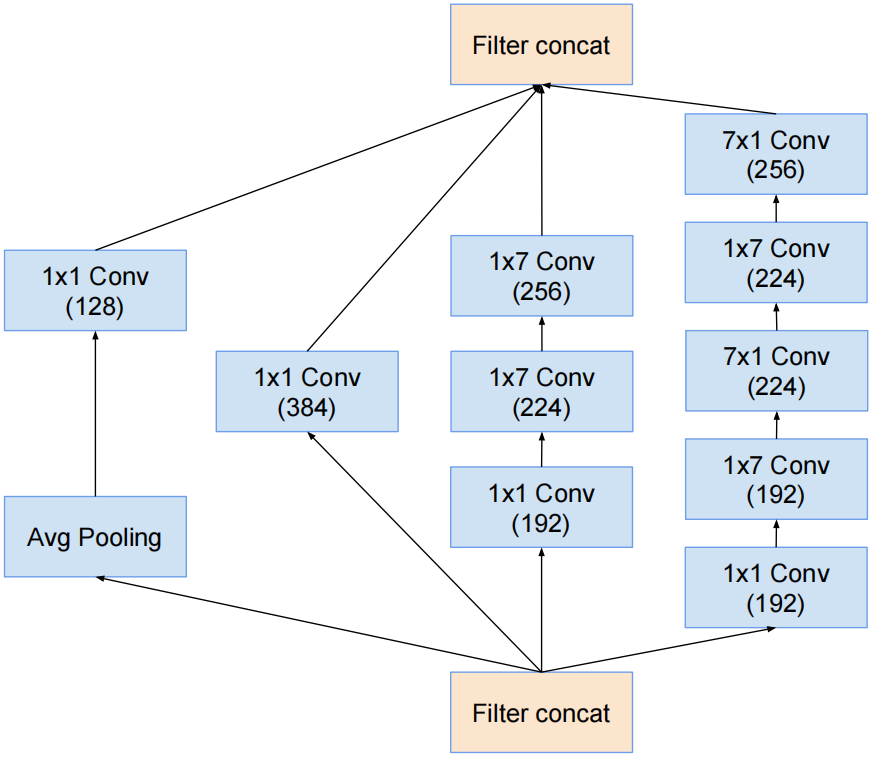
Redution-B结构:
特点:并行的不对称的1x1conv来降低计算量
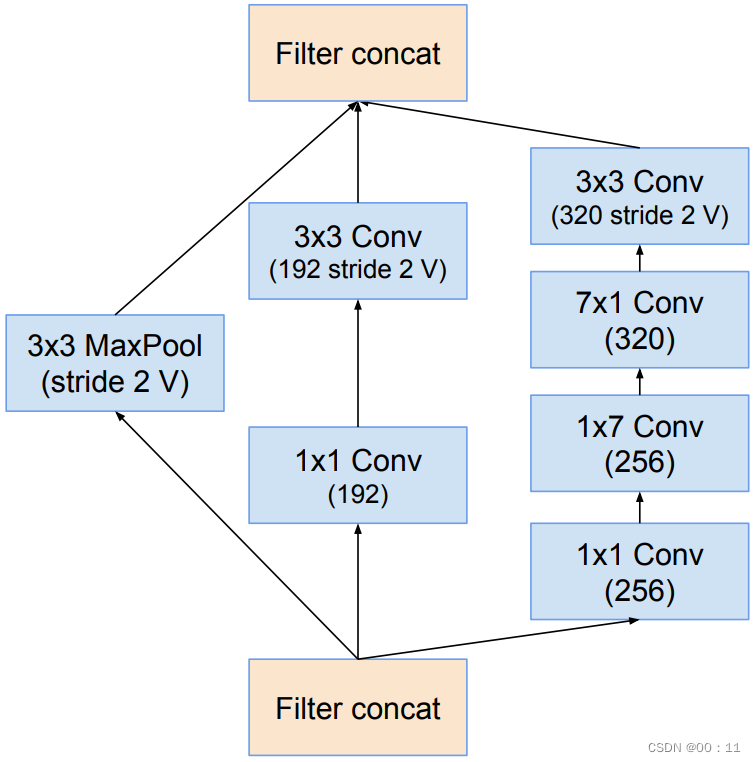
Inception-C结构:
将InceptionV3中结构Ⅲ的3x3conv变成了1x3conv和3x1conv并联结构
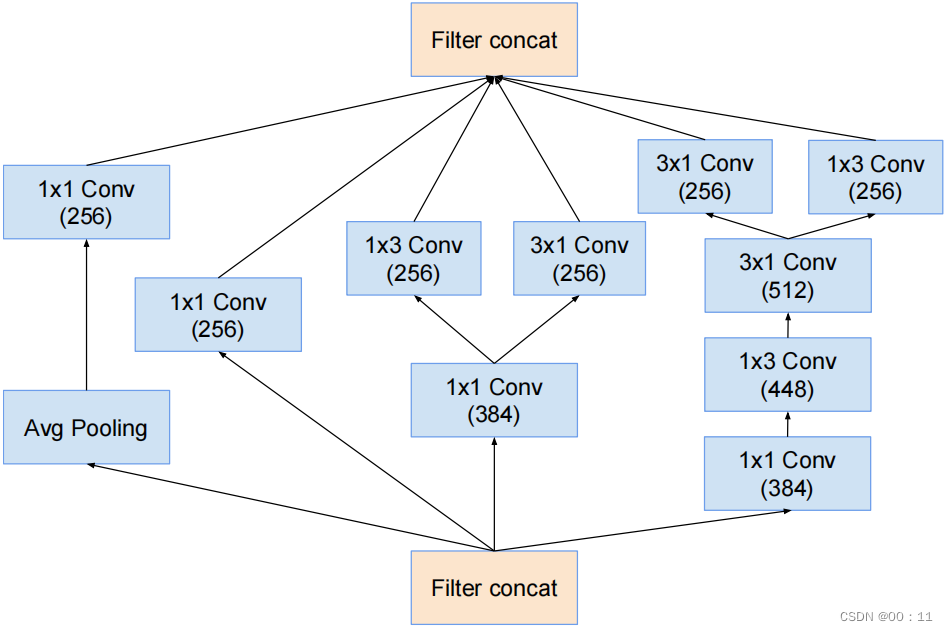
b.网络结构

(4)Inception_resnet_V2
将Inception模块和残差结构进行结合,和InceptionV4相同的计算损耗,但是训练速度比InceptionV4快
a.基本模块
stem:
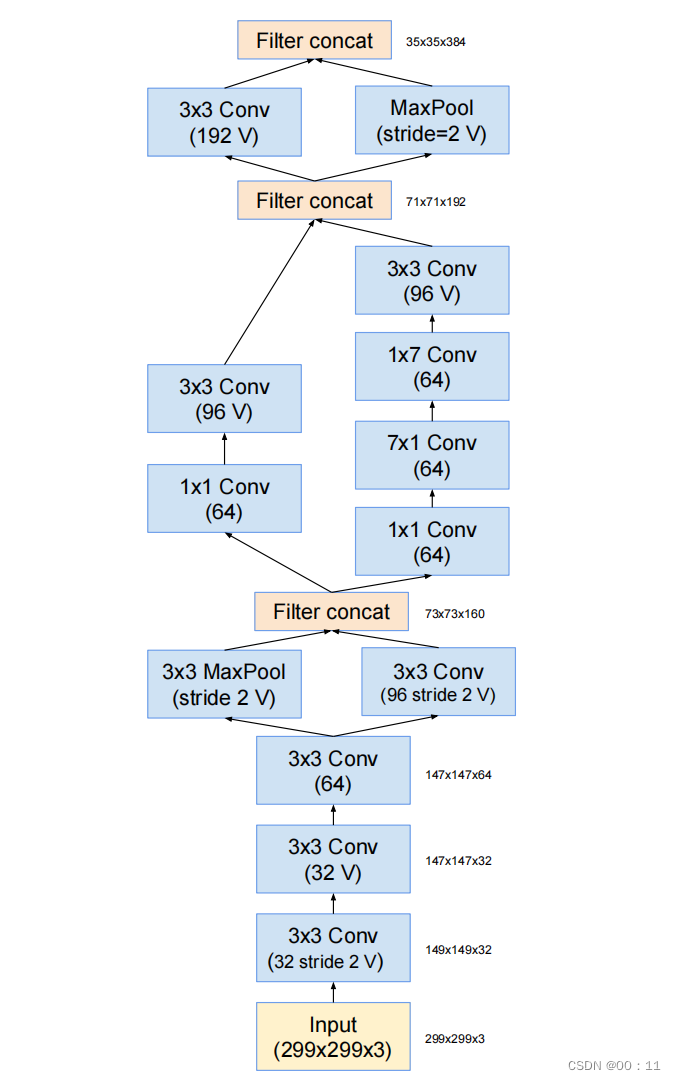
Inception-resnet-A结构:
1x1卷积的目的是为了保持主分支和shortcut分支的通道数一致

Inception-restnet-reduction-A结构:
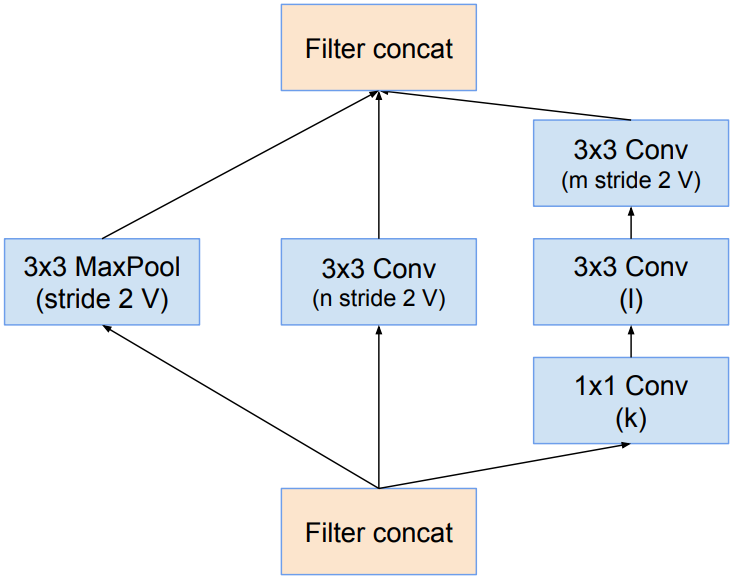
Inception-resnet-B:
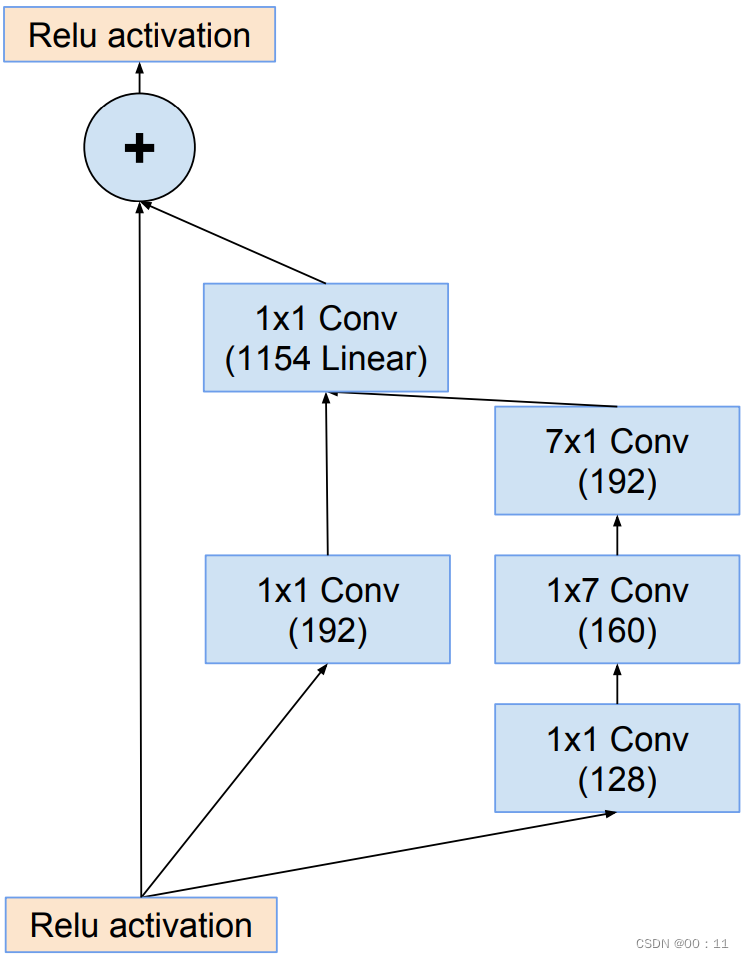
inception-resnet-reduction-B:
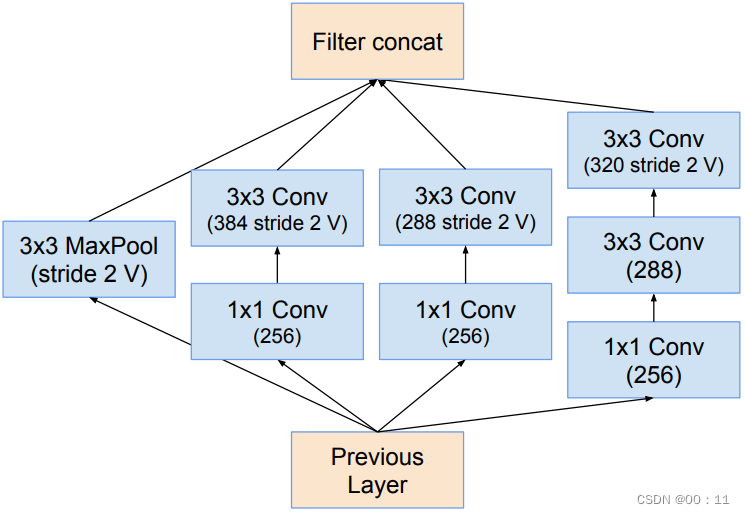
inception-resnet-C:
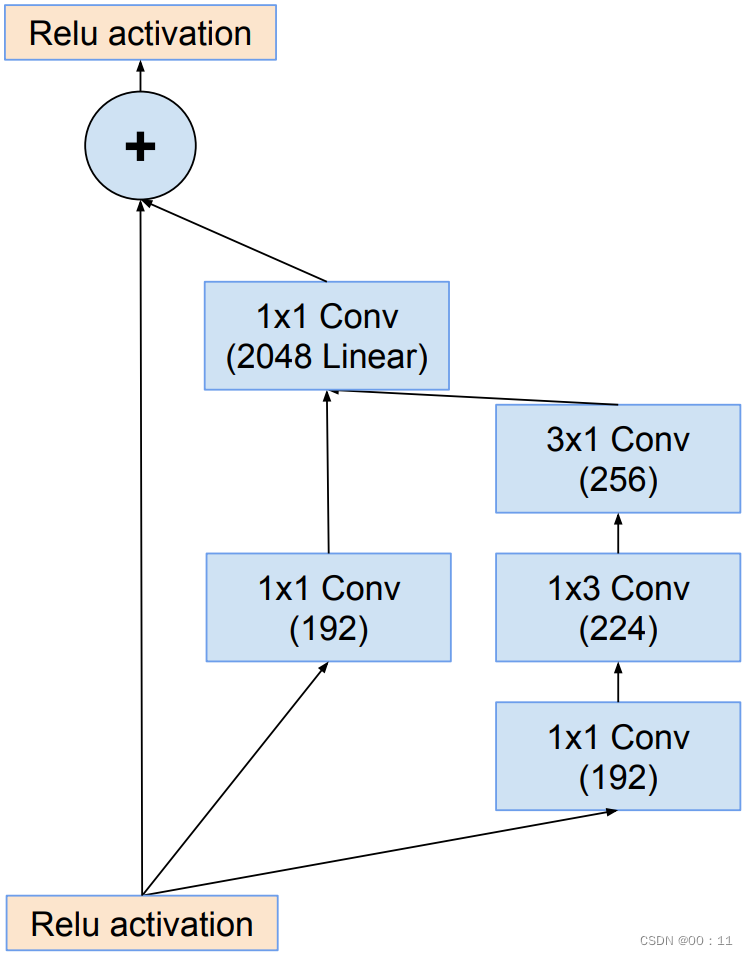
b.残差快的缩放
残差缩放因子:
为了防止随着网络层数增加导致的卷积核个数过多,对残差块的输出进行缩放能够稳定训练,因此引入残差缩放因子
作用:防止网络卷积数量较多,出现不稳定
通常取0.1-0.3
结构:
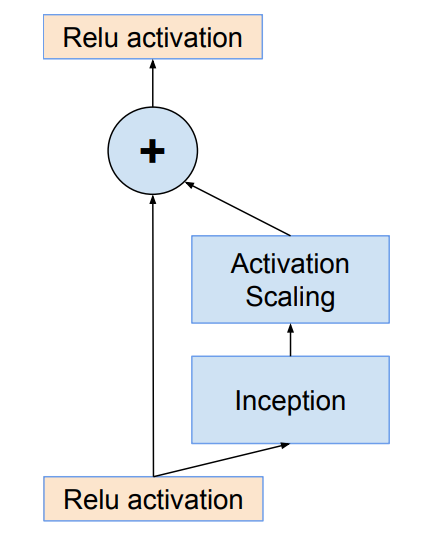
c.网络结构
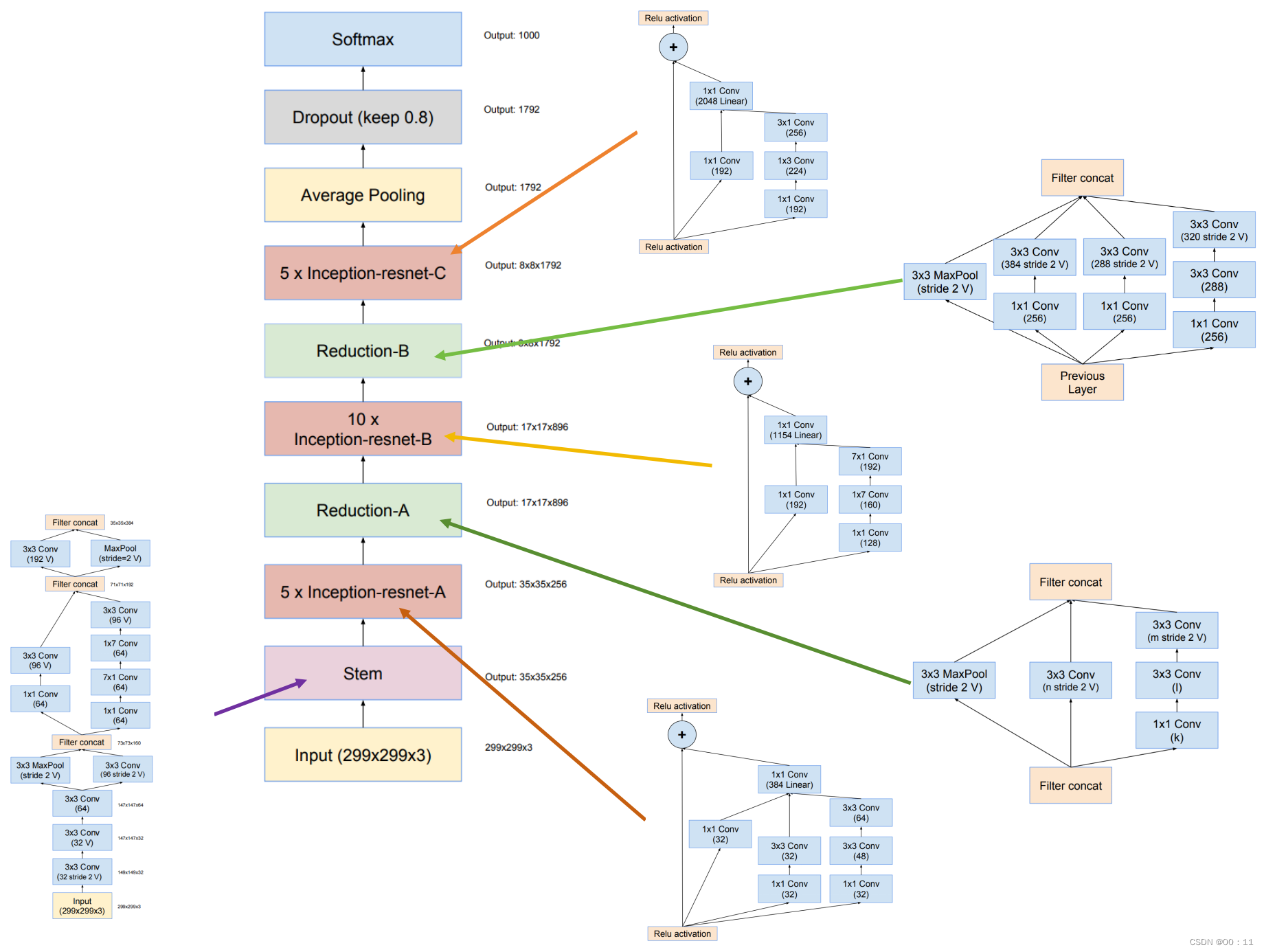
3.基于残差结构的网络
(1)resnet
a.resnet块
残差块的结构分为两种,浅层的resnet网络使用3x3conv-3x3conv(左图),较为深层的resnet使用1x1conv-3x3conv-1x1conv(右图)
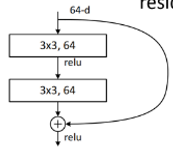
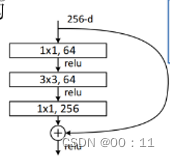
第二种结构中1x1卷积用来升维和降维,先用第一个1x1conv降低通道数,减少3x3conv卷积时的计算量,然后再用1x1卷积进行升维,还原维度
注:主分支和shortcut分支进行的是add操作,而不是concat
b.网络结构
多个残差快进行堆叠
若主支路的步长不为1,进行了下采样,那么需要在shortcut支路上添加1x1conv来调整通道数,使其保持一致
(2)resnext
a.思想
残差网络
分组卷积:每组包含多条并行路径,每条路径用于学习不同的特征
分组卷积的思想是源于inception,不同于inception的需要人为设计每个分支,resnext的每个分支的拓扑结构是相同的。最后再结合残差网络,得到的便是resnext
b.基数组
基数是用来确定有多少个并行路径,基数参数(通常表示为“C”)确定组内有多少个并行路径
c.模块结构
并行结构被实现为瓶颈块
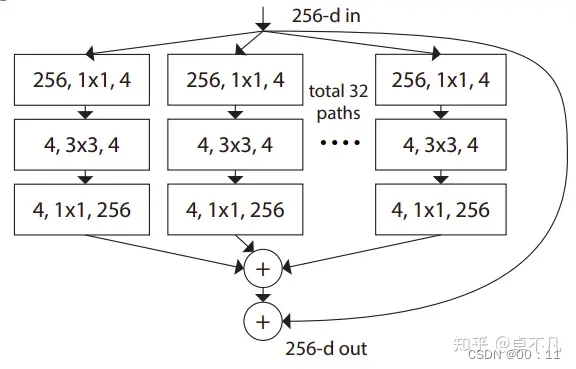
其中,1x1卷积用来降低输入特征维度,3x3卷积用来捕获更复杂的特征,然后用1x1卷积再还原通道的特征维度
(3) resnet_in_resnet
基于resnet更加泛化的网络结构,同时保留了两个流,分别是residual stream残差流和transient stream原始卷积流
RIR网络作为ResNet网络的二次开发在残差流(residual streams)和缓存流(non-residual streams)中 结合了残差网络和标准卷积网络的网络结构,该方法使用广义残差块(generalized residual blocks)保留了短接(identity shortcut connections)优化的优势同时提高了表达能力和简化了移除无效信息的难度
a.核心结构
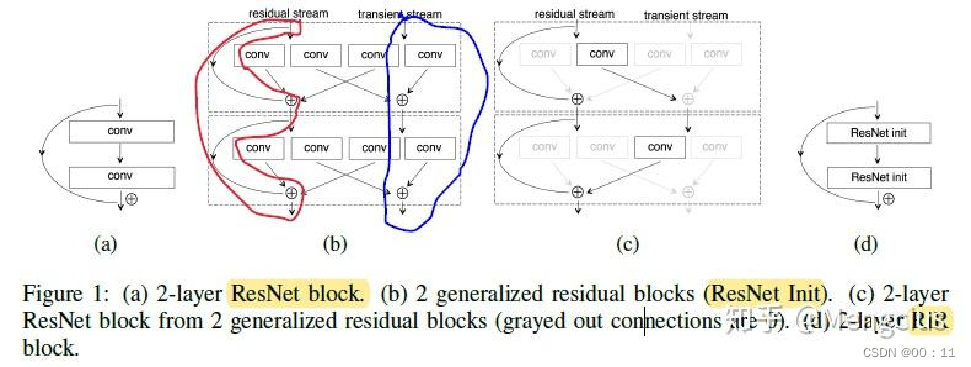

b.意义
RIR网络作为ResNet网络的二次开发在残差流(residual streams)和缓存流(non-residual streams)中 结合了残差网络和标准卷积网络的网络结构,该方法使用广义残差块(generalized residual blocks)保留了短接(identity shortcut connections)优化的优势同时提高了表达能力和简化了移除无效信息的难度
(4)preactresnet
a.核心-----前置激活
将conv---bn---relu的顺序换成了bn---relu---conv,即激活函数在卷积之前
作用:
简化优化过程:数据输入首先进行标准化,使得每一层的输入具有0均值和单位方差
增强relu的非线性表达能力:有效避免传统结构中由于输入分布偏斜导致relu大量输出为0,出现死神经元
改善梯度流:不管梯度有多深,整个网络中都不会产生梯度弥散问题
b.网络结构
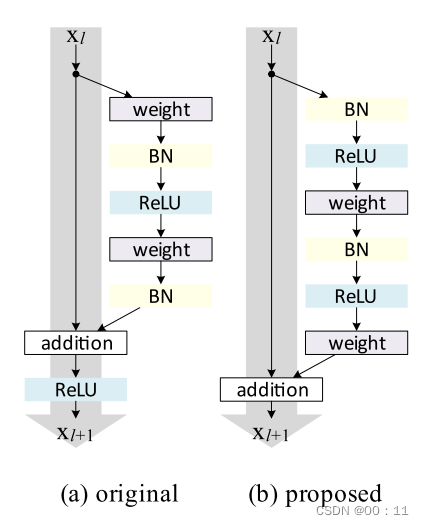
左图为resnet提出的网络结构,是经典的conv-bn-relu的结构,右图正是由于激活函数在卷积层之前,因此也被称为Preactresnet
(5)wideresnet
随着深度学习的发展,层数不断增加,分类精确度每提高百分之一的代价几乎是层数的两倍。所以训练特别深的网络存在一个问题-----特征利用率下降,很多学者便从另一角度对神经网络进行研究,不再一味的去追求神经网络的深度,而是考虑去加宽网络结构
a.宽残差块
通过增加特征通道数来加宽网络,wideresnet只比resnet多了一个加宽因子k
结构:


b.网络结构

c.特点
引入了dropout
由于需要大量数据进行扩充,批量归一化已经失效,引入了dropout这一正则化手段来防止过拟合
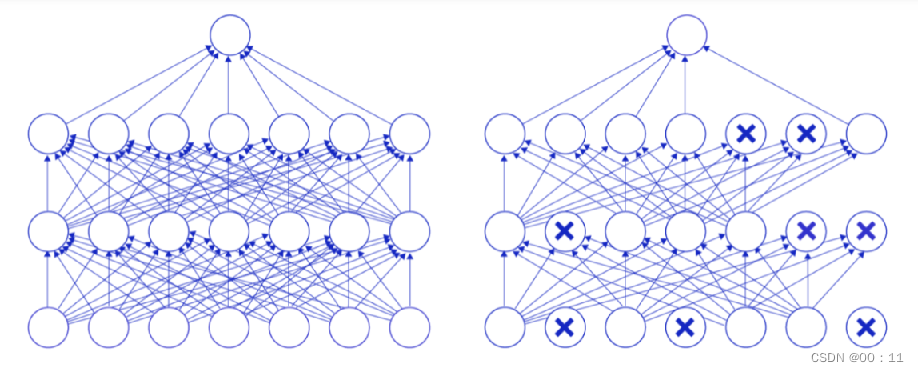
在神经网络学习过程中,随机删除一部分神经元。训练时,随机选出一部分神经元,将其输出设置为0,这些神经元不对外传递信号
左图是完整的神经网络,右图是应用了Dropout之后的网络结构。应用Dropout之后,会将标了× \times×的神经元从网络中删除,让它们不向后面的层传递信号。在学习过程中,丢弃哪些神经元是随机决定,因此模型不会过度依赖某些神经元,能一定程度上抑制过拟合
(6)senet
a.注意力机制
注意力机制是对提取的特征进行加权,进行提取重要特征忽略次要特征的作用不同模型的提取手段不同,旨在通过显式建模卷积特征通道之间的相互依赖关系 来提高网络的表示能力
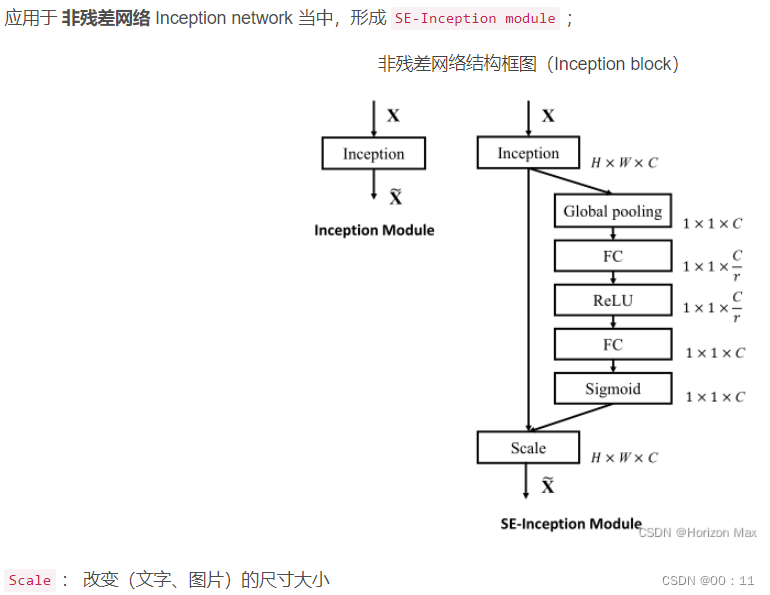
b.SE Block
分为压缩(Squeeze)和激励(Excitation)两部分
压缩:原始特征图像的维度为H*W*C,其中H是高度,W是宽度,C是通道数。压缩处理将H*W*C压缩为1*1*C,相当于把H*W压缩成一维,这一操作一般使用globalaveragepooling实现。
激励:使用包含两个全连接层的bottleneck结构来学习各个通道之间的关系,并得到不同的权重,第一个全连接层起到降维的作用,然后采用relu激活。第二个全连接层恢复原始维度,并使用Sigmoid激活函数对通道的权重进行归一化处理,最后进行scale操作。
整个操作可以看成学习到了各个通道的权重系数,从而使得模型对各个通道的特征更有辨别能力,这也算是一种attention机制。
总的来说SE Block就是在Layer的输入输出之间添加结构:

c.推广及应用
SE模块是通用的,可以嵌入到现有网络架构中,如ResNet和Inception,形成SE-ResNet和SE-Inception等变种

(7)stochasticdepth
随机动态网络,为了解决因网络结构太深所导致的梯度消失和训练时间过长等问题,实现了特征的重用
a.实现
训练过程中,随机让resnet中的一些层失效,直接通过skip connection传播,那么如何确定让哪些层失效呢?在训练过程中引入Bernoulli random随机概率参数,使用torch.bernoulli()函数进行bernouli试验,这个函数接收一个张量作为参数,返回一个同样形状的张量,其中每个元素为0(失败)或1(成功),并且每个元素值独立地以对应的输入概率进行产生。
使用的基本的residualblock结构为:conv-bn-relu-conv-bn
b.compare with dropout
相似:dropout是让反向传播过程中的一些权重的梯度随机变为0,stochasticdepth的方法是让整个某一层失效
不同:stochasticdepth可以调整整个网络的深度和宽度,dropout无法和BN层一起使用
4.轻量级模型
Mobilenet系列
深度可分离卷积(DW)
mobilenet模型是针对手机等嵌入式设备提出的一种轻量级神经网络,实际上整个网络也是深度可分离模块的堆叠
深度可分离卷积是mobilenet的基本单元包括深度卷积和逐点卷积
深度卷积:对于标准卷积来说,其卷积核运用到所有的通道上,而深度卷积每个卷积核对应一个输入通道,深度卷积是逐通道的操作,利用groups来实现
逐点卷积:使用的是1x1conv,是对深度卷积的输出进行融合
具体结构如下:
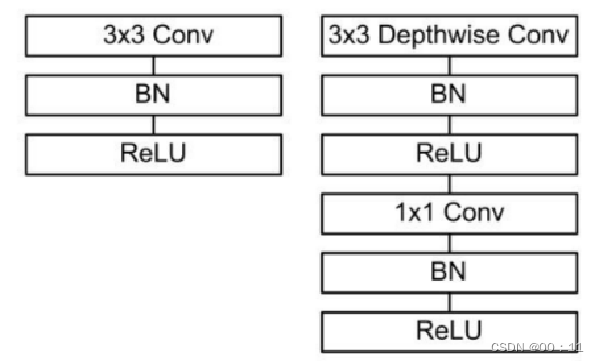
左图为传统卷积,右图为深度可分离卷积
(1)Mobilenet
由深度可分离卷积模块进行堆叠

a.网络结构
steam:
3x3conv--DW 3x3--point
conv1:
2个深度可分离模块进行堆叠
conv2:
2个深度可分离模块进行堆叠
conv3:
6个深度可分离模块进行堆叠
conv4:
2个深度可分离模块进行堆叠
池化层+全连接层:
globalaveragepool
(2)MobilenetV2
对比MobilenetV1吗,存在的问题包括结构简单,以及DW训练部分的kernel容易被训废掉,DW训练出来的kernel有不少是空的
a.反向残差块的构建
反向残差:
常规的残差结构是1x1降维---3x3卷积---1x1升维,呈现出沙漏形;
而反向残差结构是1x1升维---3x3DW卷积---1x1卷积降维,形成一个纺锤形
激励函数使用的是ReLU6
定义: f(x)= min(max(0,x),6)
如果tensor维度越低,卷积层的乘法计算量就越小。那么如果整个网络都是低维的tensor,那么整体计算速度就会很快。然而,如果只是使用低维的tensor效果并不会好。如果卷积层的过滤器都是使用低维的tensor来提取特征的话,那么就没有办法提取到整体的足够多的信息。所以,如果提取特征数据的话,我们可能更希望有高维的tensor来做这个事情,V2就设计这样一个结构来达到平衡
Shufflenet系列
(1)shufflenet
为了降低计算量,卷积网络通常在3x3conv之前增加一个1x1conv,用于通道间的信息流通和降维。然而在ResNext、MobileNet等高性能的网络中,1x1卷积却占用了大量的计算资源(通道数过多)。于是在shufflenet加入组卷积和通道混洗,目的在于优化网络结构,有效降低1x1逐点卷积计算量,高效轻量化网络
a.通道混洗
当前先进的轻量化网络大都使用深度可分离卷积或者组卷积,以降低网络的计算量,但这两种操作都无法改变特征的通道数,因此还需要使用1x1卷积

上图中a图代表了常规的两个组卷积操作,可以直观的看出如果没有逐点的1x1卷积或者通道混洗,最终输出的特征仅由一部分输入通道的特征计算得出,这一操作阻碍了信息的流通,进而降低了特征的表达能力
因此,我们希望在一个组卷积之后,能够将不同组的信息进行融合,类似于图b的操作,将每一个组的特征分散到不同组之后,再进行下一次组卷积,这样输出的特征就能够包含每一个组的特征,而通道混洗恰好可以实现这一过程,如图c。通道混洗可以通过几个常规的张量操作来实现,如下图所示。
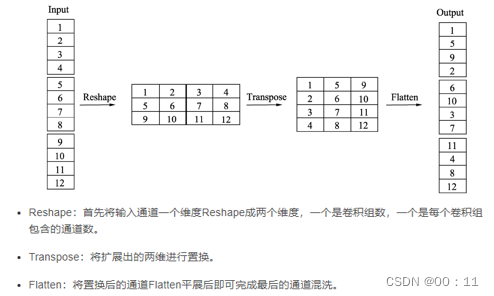
这里对输入通道做了1-12的编号,分成3个组,每组包含4个通道
b.混洗分组卷积(SGC)
将分组卷积和通道混洗机制相结合,将通道进行分组相比普通的卷积参数减少一半
![]()
分组卷积虽然可以使参数进行减少,但是会阻碍通道之间的流通,于是为了改善这一情况,引入了通道混洗操作,对于分组产生问题的解决方法就是引入混洗机制
c.网络结构
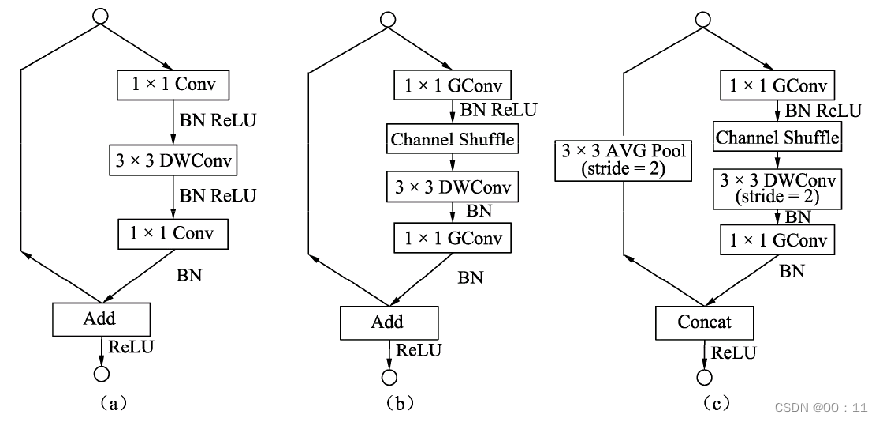
图a是一个带有深度可分离卷积的残差模块,这里的1×1是逐点的卷积。相比深度可分离卷积,1×1计算量较大。图b则是基本的ShuffleNet基本单元,可以看到1×1卷积采用的是组卷积,然后进行通道的混洗,这两步可以取代1×1的逐点卷积,并且大大降低了计算量。3×3卷积仍然采用深度可分离的方式。图c是带有降采样的ShuffleNet单元,在旁路中使用了步长为2的3×3平均池化进行降采样,在主路中3×3卷积步长为2实现降采样。另外,由于降采样时通常要伴有通道数的增加,ShuffleNet直接将两分支拼接在一起来实现了通道数的增加,而不是常规的逐点相加
(2)ShuffleV2----轻量级网络中的桂冠
效率对比图
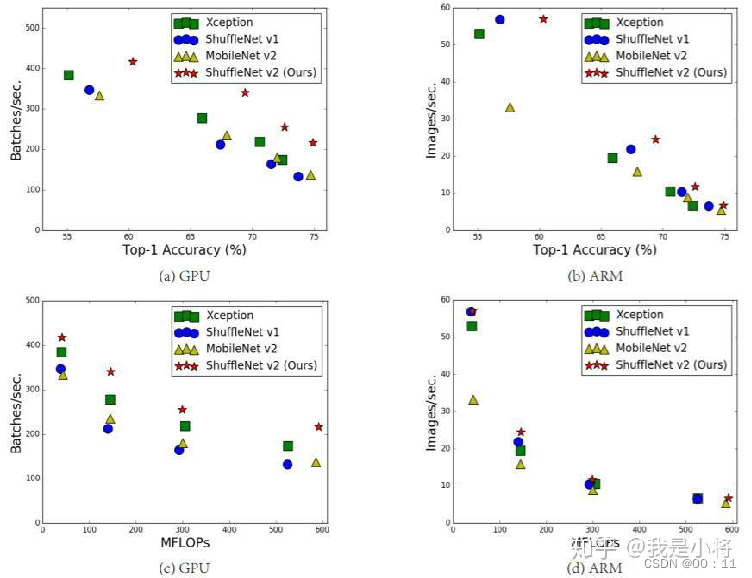
a.改进
降低参数实现轻量,1x1conv平衡输入和输出的大小,避免网络的碎片化,减少元素级运算。因此shufflenetV2提出了channel split,将输入通道分成两个分支,分别为c‘和c-c’,实际实现时c‘=c/2
b.网络结构

c.优势
从一定程度上说,ShuffleNetv2借鉴了DenseNet网络,把shortcut结构从Add换成了Concat,这实现了特征重用。但是不同于DenseNet,v2并不是密集地concat,而且concat之后有channel shuffle以混合特征,这或许是v2即快又好的一个重要原因
SqueezeNet
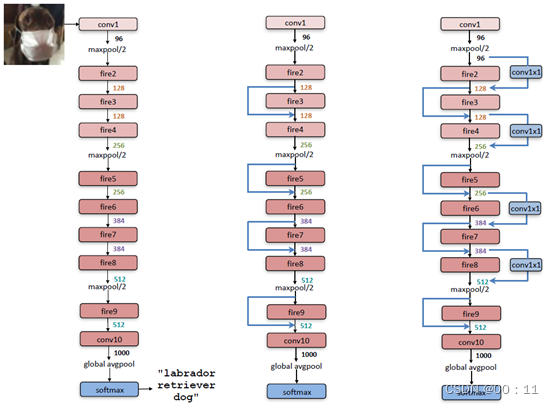
a.基本模块
SqueezeNet的基本模块是Fire Modules,Fire Modules分为Squeeze(压缩)层和Expand(扩张)层
Squeeze:主要通过1x1卷积来减少通道数量,以降低模型参数
Expand:通过1x1和3x3卷积来增加通道数量,以产生更丰富的特征,具体实现是将1x1卷积滤波器和3x3卷积滤波器进行并联
同时引入了三个可以调节维度的超参数

b.网络结构
使用多个Fire Modules进行堆叠,并且使用池化层来减少空间尺寸
5.DenseNet
DenseNet又称为密集型卷积神经网络,实现了特征重用,目的是解决梯度消失这一缺点,实现了缓解梯度消失、使特征传递更加有效、计算量和参数都更小等优点,同时性能比resnet要好,但是内存占用较大
a.对比

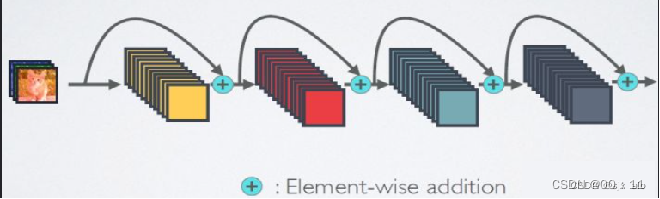
第一张图是ResNet的网络结构,ResNet网络的短路连接机制(其中+代表的是元素及相加操作)
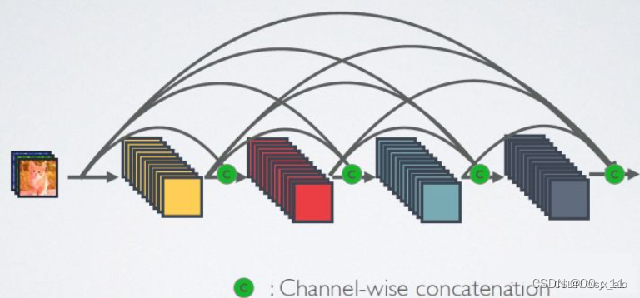
第二张图是DenseNet网络的密集连接机制(其中c代表的是channel级的连接操作),在这一网络中,每一层的特征都被保存下来,在后面的每次卷积操作中用到。每一层网络结构都用到了前面的所有信息(包括卷积操作前和卷积操作后的信息)
b.densenet的实现
该网络主要有Dense Block和Transition Layer两个部分组成
Dense Block的实现:
BN+ReLU+1x1 conv + BN + ReLU + 3x3Conv
卷积层的输入包含了前面所有层的输出特征,输出特征来自不同的层数,值分布差异较大,所以在输入到下一层之前,必须经过BN层将其数值进行标准化,然后再进行下一步操作
其中1x1conv为减少参数量
Transition Layer:
BN + ReLU + 1x1 Conv + 2x2 AvgPooling,用于连接两个相邻的denseblock。
利用压缩系数压缩模型,主要结构是一个卷积层和一个池化层
压缩系数:

Xception系列
主要思路就是将Inception网络中的Inception模块换成深度卷积可分离模块(DW),将空间的相关性与通道的相关性进行完全的解耦
a.xception和DW的区别
DW首先执行通道方向的空间卷积,再进行1x1卷积,而xception则是先进行1x1卷积
b.引入残差连接
浅层网络加入relu会导致信息丢失,而残差结构可以实现特征复用,从而缓解特征退化
c.网络结构
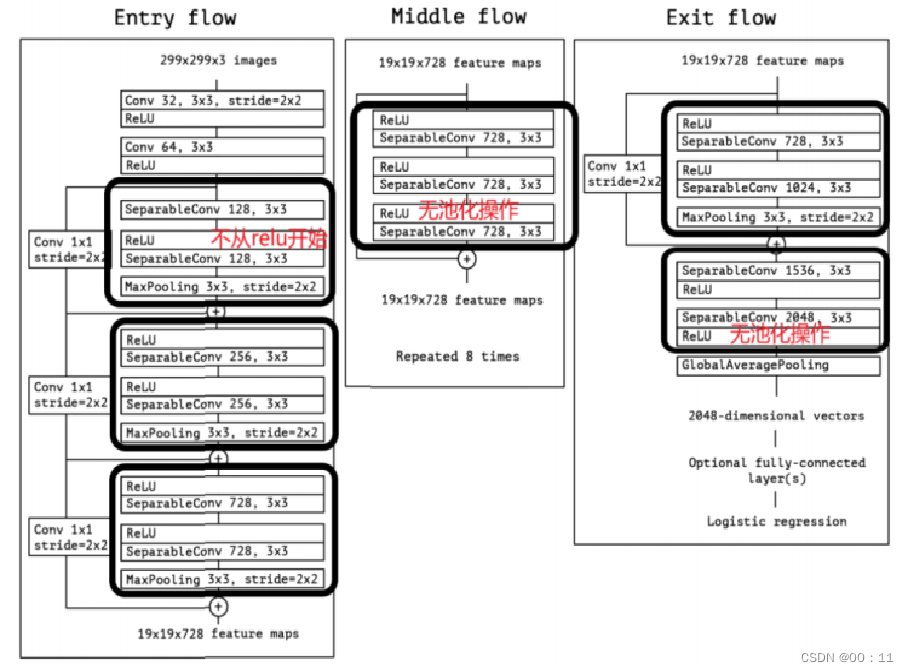
SeparalbeConv函数是由3x3的depthwise卷积和1x1的pointwise卷积组成,因此可以用于升维和降维
对CNN基础的网络模型进行一个简单总结,感谢大佬们的观看,欢迎大佬们进行批评指正

