
- 1用AI一键搞定绘画推文,引爆流量,轻松日入1200+,小白轻松易上手_ai推文
- 2配电房智能巡检机器人怎么选?
- 3江苏计算机考研专硕国家线,【江苏考研】近五年各专业考研国家线及趋势汇总,超全数据一目了然!...
- 4AI大模型学习白话笔记(五)-- Function Calling_大模型推理fucation call
- 5VS Code插件之Cordova Tools
- 6Spring Boot WebSocket 客户端_springboot创建websocket客户端_springboot websocket客户端
- 7 Padavan 路由器获取唯一IPv6 解决无网络访问权限
- 8电大计算机技术应用毕业论文,电大计算机软件
- 9linux基础命令练习题_修改文件a.txt权限为文件拥有者有读写执行权限、属组用户有读权限、其他人没有权
- 10网络安全等级保护测评-安全计算环境-AIX-上篇_等保测评安全计算环境符合情况怎么填
elastic ik分词搜索_全文搜索引擎Elasticsearch的初体验
赞
踩
一、简介
关于Java Web的开发周边技术,搜索引擎也是经常被用到的,其中solr和es是被当作技术选型经常出现的,他们都是基于lucene,但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。而今天所讲的es,它是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。

二、安装
首先就是要安装es,它是需要jdk的一个环境,这个想必大家都准备好了,然后去下载es的压缩包,或者用docker去启动一个es的容器,这里下载它的压缩包:
解压刚才下载的压缩包,然后进入bin目录,可以看到一些es的相关命令:
使用bin目录中的elasticsearch命令启动:
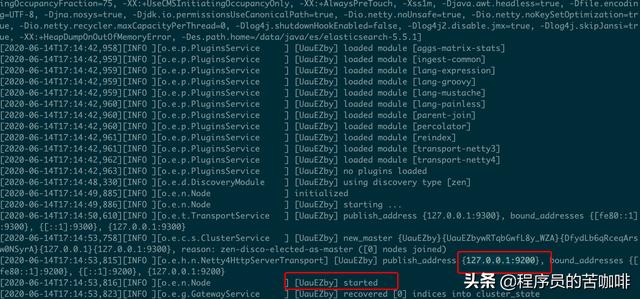
它会启动在9200端口,这是我们可以访问一下http://127.0.0.1:9200/:
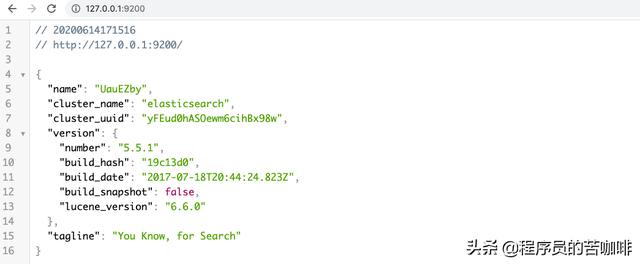
看它的tagline:ou Know, for Search。证明启动成功了,可以开始我们的搜索了。
三:概念
在使用es之前,先来了解一些它的基本概念:
1、Node:单个 Elastic 实例称为一个节点(node)
2、Cluster:一组节点构成一个集群(cluster),Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
3、Index:Elastic 数据管理的顶层单位就叫做 Index(索引),Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
4、Document:Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
5、Type:Document 可以分组,这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
四:中文分词
在搜索引擎中,还有一个重要的设置,那就是中文分词的设置,毕竟国内开发不得不安装这个插件,就像编码处理一样,刚才在bin目录中大家也看到一个命令:elasticsearch-plugin,我们可以利用它来安装中文分词神器-ik中文分词器,安装命令如下:
/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.1/elasticsearch-analysis-ik-5.5.1.zip
接着,重新启动 Elastic,就会自动加载这个新安装的插件。
五:数据的操作
1、新建Index,指定需要分词的字段:
命令curl -X PUT 'localhost:9200/cities' -d '{ "mappings": { "city": { "properties": { "name": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "desc": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" } } } }}'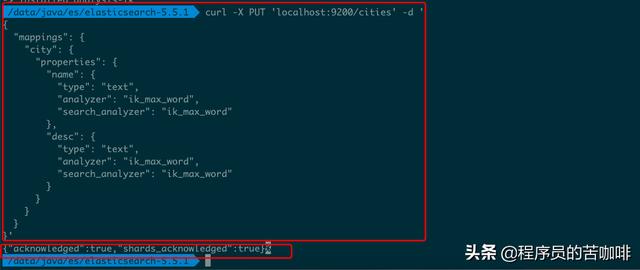
上述操作新建一个名称为cities的 Index,里面有一个名称为city的 Type。person有两个属性:name和desc。analyzer是字段文本的分词器,search_analyzer是搜索词的分词器。ik_max_word分词器是插件ik提供的,可以对文本进行最大数量的分词。{"acknowledged":true,"shards_acknowledged":true}是服务器返回的JSON值,acknowledged=true表示操作成功。
2、新增记录
向指定的 /Index/Type 发送 PUT 请求,就可以在 Index 里面新增一条记录。
命令curl -X PUT 'localhost:9200/cities/city/1' -d '{ "name": "北京", "desc": "帝都,北漂的人想出去,外边的人想北漂。"}'
如图所示,服务器返回的 JSON 对象,会给出 Index、Type、Id、Version 等信息。
在请求的路径中,最后的1是该条记录的 Id,它不一定是数字,任意字符串都可以。新增记录的时候,也可以不指定 Id,这时要改成 POST 请求。
命令:curl -X POST 'localhost:9200/cities/city' -d '{ "name": "上海", "desc": "上海滩,多少人想成为许文强一样的人物"}'
3、查看记录
向/Index/Type/Id发出 GET 请求,就可以查看这条记录。
命令curl 'localhost:9200/cities/city/1?pretty=true'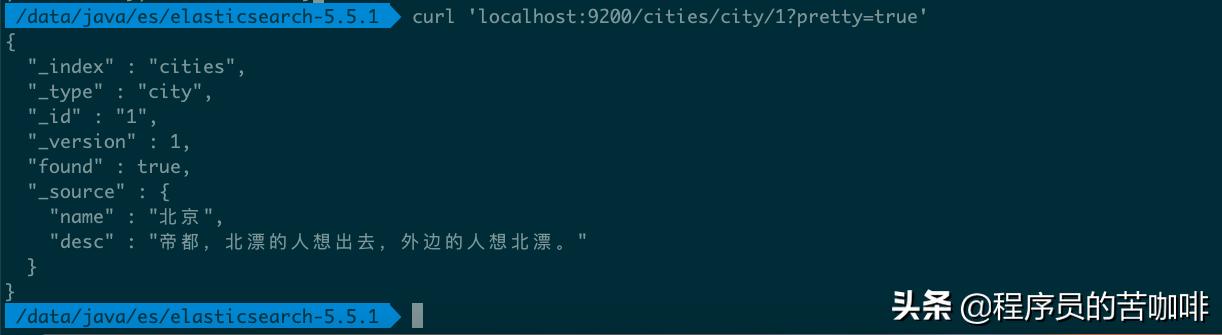
4、删除记录
删除记录就是发出 DELETE 请求。
命令curl -X DELETE 'localhost:9200/cities/city/1'
5、更新记录
更新记录就是使用 PUT 请求,重新发送一次数据。
命令:curl -X PUT 'localhost:9200/cities/city/AXKyTASFQrU13vhMO-rj' -d '{ "name": "上海", "desc": "上海滩,多少人想成为许文强一样的人物,还需要丁力一样的帮手"}'
6、返回所有记录
使用 GET 方法,直接请求/Index/Type/_search,就会返回所有记录。我们把刚才删除的北京添加进来,再查询:
命令curl 'localhost:9200/cities/city/_search'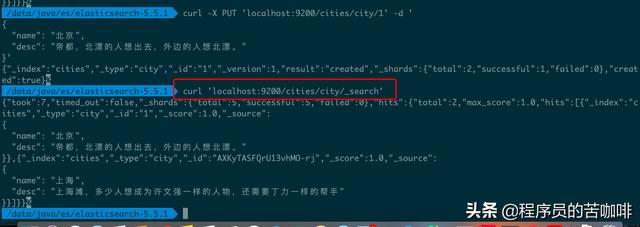
7、全文搜索
Elastic 有自己的查询语法,要求 GET 请求带有数据体。
命令:curl 'localhost:9200/cities/city/_search' -d '{ "query" : { "match" : { "desc" : "北漂" }}}'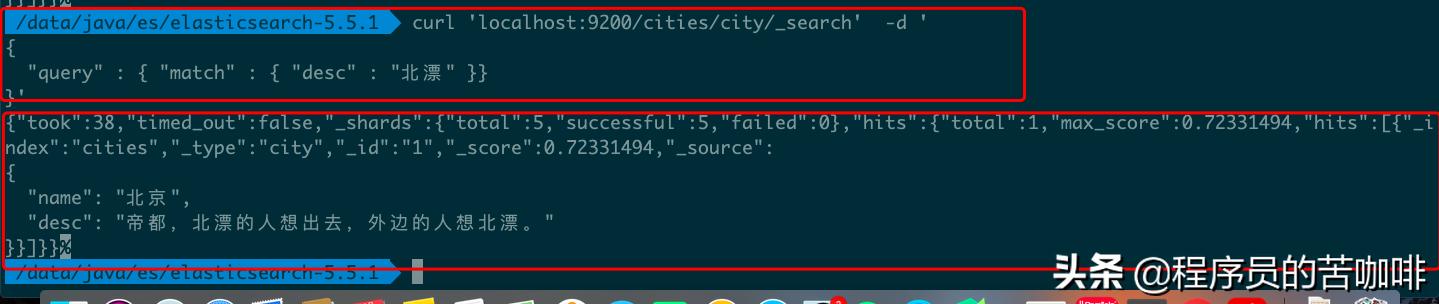
上面是查询语法,下面是查询结果。
8、逻辑运算
如果有多个搜索关键字, Elastic 认为它们是or关系。
命令:curl 'localhost:9200/cities/city/_search' -d '{ "query" : { "match" : { "desc" : "北漂 许文强" }}}'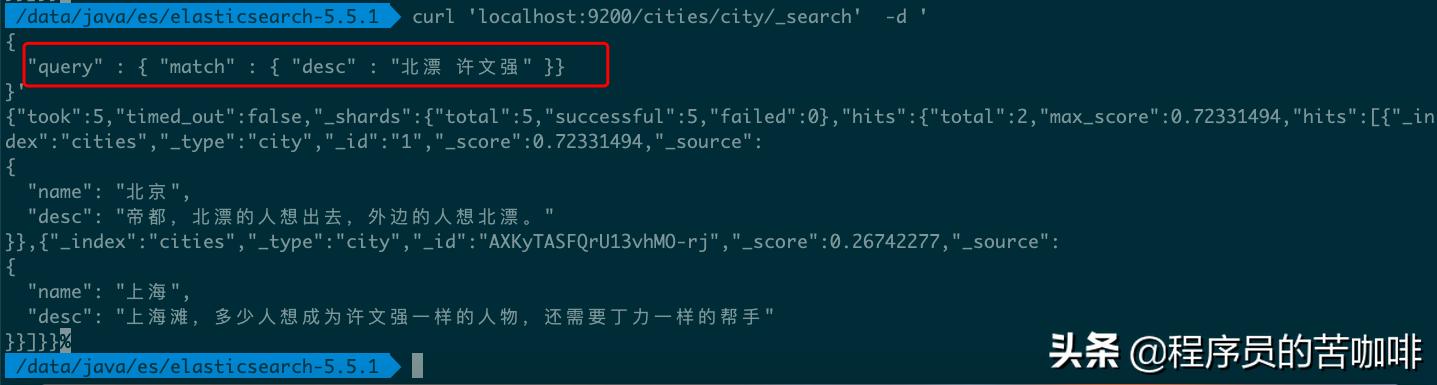
如果要执行多个关键词的and搜索,必须使用布尔查询。
命令:curl 'localhost:9200/cities/city/_search' -d '{ "query": { "bool": { "must": [ { "match": { "desc": "北漂" } }, { "match": { "desc": "许文强" } } ] } }}'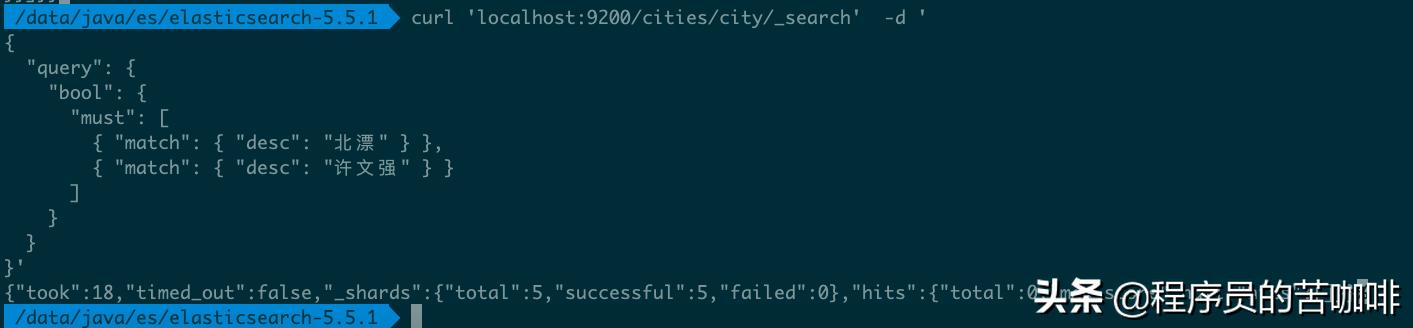
没有结果返回。
elasticsearch在日常开发中用途很多,感兴趣可以动手试一试,了解一下它都有什么功能。


