
- 1对于程序员来说,2024年的冬天有点冷,互联网大厂裁员,字节跳动面试必问_为什么2024年程序员不好找工作了
- 2[渝粤教育] 西北工业大学 模拟电子技术基础 参考 资料_在某放大电路中,测得晶体管的三个电极①、②、③的流入电流分别为-1.2ma、-0.03ma
- 3关于os.environ[]和os.getenv()和os.environ.get()三者简单区别
- 4TensorFlow中LSTM神经网络详解_tensorflow lstm
- 5vscode调试mysql5.7.37教程_mysql 源码调试 vscode
- 6Windows上位机C++串口通信 原理+库代码编写+库运用(机甲大师逐曦战队算法组主线教程1)_c++串口库
- 7量子位 | 2024年AI还能帮你干什么?这十个趋势必须关注_2024aigc应用层十大趋势
- 8LaTex使用技巧10:公式中的各种英文字体_latex 英文字体
- 9RabbitMQ发布与订阅模式类型_mq订阅模式
- 10仓颉编程语言开发指南 -- 基础数据类型_仓颉编程语言开发指南pdf
八大排序,各显神通_小米安全键盘排列顺序
赞
踩
排序是数据处理中一种很重要也很常用的运算,一般情况下,排序操作在数据处理过程中要花费许多时间,为了提高计算机的运行效率,我们提出并不断改进各种各样的排序算法,这些算法也从不同角度展示了算法设计的重要原则和技巧。在小编的世界中,排序就是对一组杂乱无章的数据进行各种各样的排序,使其从无序的数据变成有序的数据,排序的目的就是为了方便查找,分内部排序和外部排序。如下图所示:
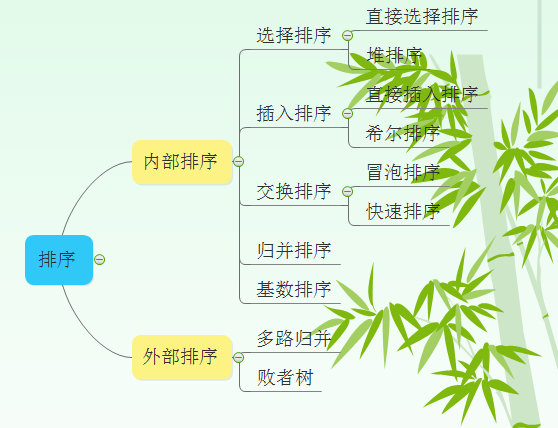
今天这篇博文,小编主要简单的总结一下内部排序,让我们一起来揭开排序的神秘面纱,看看他们到底按照怎样的规则进行一一排序的,总的来说,在排序中,有三种基本的排序,选择排序、插入排序和交换排序,其余的排序都是在这三种基本的排序上演化或者是优化而来的,首先我们来看选择排序。
选择排序---直接选择排序
选择排序包括两种,分别是直接选择排序和堆排序,选择排序的基本思想是每一次在n-i+1(i=1,2,3,...,n-1)个记录中选取键值最小的记录作为有序序列的第i个记录,首先我们来看选择排序中的第一种排序---直接选择排序。直接选择排序的基本思想是,在第i次选择操作中,通过n-i次键值间比较,从n-i+1个记录中选出键值最小的记录,并和第i(1小于等于1小于等于n-1)个记录交换,说了基本思想之后,赶脚还是稀里糊涂的,我们来看一下直接选择排序具体是如何排序的,如下图所示:‘
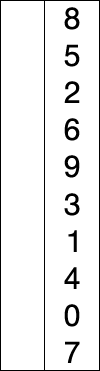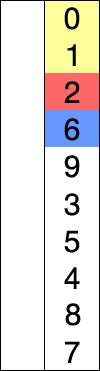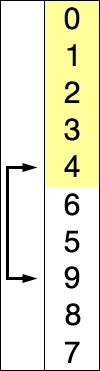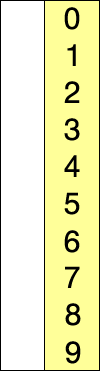
如上所示的一组序列为8、5、2、6、9、3、1、4、0、7,首先我们在这个里面选取一个最小的数当然最大的也可以,具体根据要求来进行选择,我们以从小到大的顺序进行排列,首先,我们选取一个最小的数字0,0和8进行交互位置,经过第一次选择之后,序列的顺序变成0、5、2、6、9、3、1、4、8、7,接着进行第二次选择,再选择一个最小的数字1,1和5交互位置,依次类推,直到该序列是有序序列为止。
选择排序---堆排序
接着我们来看选择排序中的另一种排序---堆排序,由上面的直接选择排序分析,我们知道,在n个键值中选出最小值,至少进行n-1次比较,然而继续在剩余的n-1个键值中选择出第二个小的值是否一定要进行n-2次比较呢?如果能利用钱n-1次比较所得信息,是否可以减少以后各次选中的次数比较呢?基本这个,我们来看堆排序,堆排序是指利用堆积树(堆)这种数据结构所设计的一种排序算法,利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。我们来看堆排序到底是怎么排的呢?下面我们以小堆为例,如下图所示:

如上图所示的序列是6、5、3、1、8、7、2、4,我们首先将其构建成一个堆,通过构建我们发现这个时候的序列为8、6、7、4、5、3、2、1,接着,我们1和8进行比较,发现1小于8,所以交互位置,刨去8,这个时候的序列为1、6、7、4、5、3、2,发现7比1大,交互位置,1比3小,交互位置,构成的是一个大顶堆了,这个时候,只需要7跟二叉树的最后一个节点进行比较即可,刨去7,依次类推,小编这里用语言描述的不是很准确,没有立体感,很难进行想象,小伙伴可以仔细看上面的这个动态图是如何进行堆排序的。
插入排序---直接插入排序
常用的插入排序有两种,直接插入排序和希尔排序,首先我们来看直接插入排序,直接插入排序是一种简单的排序方法,她的基本思想是依次将每个记录插入到一个已排好序的有序表中去,从而得到一个新的、记录数增加1的有序表,就好比图书馆整理图书的这么一个过程,接着我们来看一下,直接插入排序的具体排序,如下图所示:
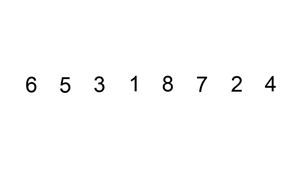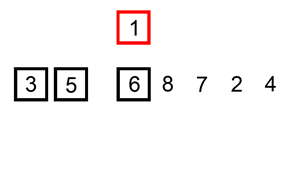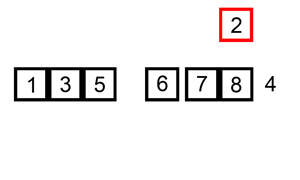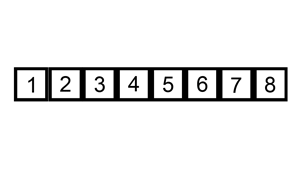
如上图所示的一组序列为6、5、3、1、8、7、2、4,首先6和5比较,6比5大交互位置,接着3和5比较,6比3大交互位置,3和5比,交互位置,现在的序列就是3、5、6、1、8、7、2、4,这个时候要把1插入到序列中,首先在徐磊中查找以确定1所应插入的位置,然后就行插入操作,从6起向左顺序查找,由于1小于3,所以1插入的位置就是3的前面,一般情况下,第i(i大于等于1)个记录进行插入操作时,R1、 R2,...,是排好序的有序数列,取出第i个元素,在序列中找到一个合适的位置并将她插入到该位置上即可。
插入排序---希尔排序
基本思想:算法先将要排序的一组数按某个增量d(n/2,n为要排序数的个数)分成若干组,每组中记录的下标相差d.对每组中全部元素进行直接插入排序,然后再用一个较小的增量(d/2)对它进行分组,在每组中再进行直接插入排序。当增量减到1时,进行直接插入排序后,排序完成。我们来看下面的一张图,如下所示:

我们来看一个关于希尔排序的例子,如下图所示:

希尔排序具体的做法结合上述排序,我们可以很清楚的看出来,先取一个小于n的整数d1作为第一个增量,把序列分为d1个组,即将所有距离为d1倍数序号的记录放在同一个组中,在各组内进行直接插入排序,然后去第二个增量d2,d2小于d1,重复上述分组和排序工具,依次类推,直至所取的增量di=1,即所有记录放在同一组进行直接插入排序为止。
交换排序---冒泡排序
交换排序的基本思想是,比较两个记录键值的大小,如果这两个记录键值的大小出现逆序,则交换这两个记录,这样将键值较小的记录向序列前部移动,键值较大的记录向序列后部移动。首先我们来看交换排序中的第一种排序---冒泡排序,首先将第一个记录的键值和第二个键值进行比较,若为逆序,即R[1].key大于R[2].key,则将这两个记录交换,然后继续比较第二个和第三个记录的键值,依此类推,直到完成第n-1个记录和第n个记录的键值比较交换为止,上述过程称为第一趟起泡,其结果使键值最大的记录移到了第n个位置上,然后再进行第二趟起泡,即对前n-1个记录进行同样的操作,其结果是次大键值的记录安置在第n-1个位置上,重复上面的过程,当在一趟起泡过程中没有进行记录交换的操作时,整个排序过程终止,我们来看下面的一张图:
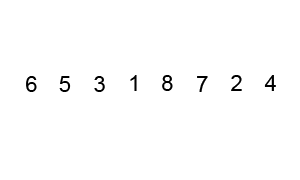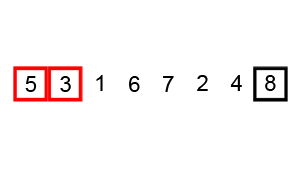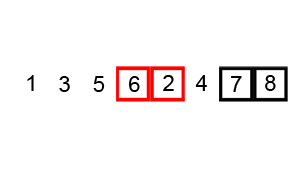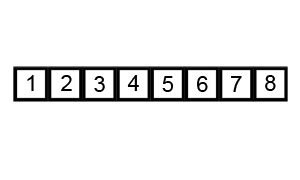
该方法的排序过程与气泡从水中往上冒的情况很相似,所以,美其名曰:冒泡排序,从上图我们可以很清楚的看出来,在排序的过程中,键值较小的记录好比气泡一样向上漂浮,键值较大的记录则向下沉。
交换排序---快速排序
快速排序是交互排序的一种,实质上是对冒泡排序的一种改进,快速排序的基本思想是,在n个记录中取某一个记录的键值为标准,通常取第一个记录键值为基准,通过一趟排序将待排的记录分为小于或等于这个键值的两个独立的部分,这是一部分的记录键值均比另一部分记录的键值小,然后,对这两部分记录继续分别进行快速排序,以达到整个序列有序,我们来看下面的一张图:

归并排序
所谓的归并,是将两个或两个以上的有序文件合并成为一个新的有序文件,归并排序是把一个有n个记录的无序文件看成是由n个长度为1的有序子文件组成的文件,然后进行两两归并,如此重复,直至最后形成包含n个归并,得到n/2个长度为2或者1的有序文件,再两两归并,如此重复,直至最后形成包含n个记录的有序文件位置,这种反复将两个有序文件归并成一个有序文件的排序方法称为二路归并排序。二路归并排序的核心操作是将一堆数组中前后相邻的两个有序序列归并为一个有序序列,如下图所示:
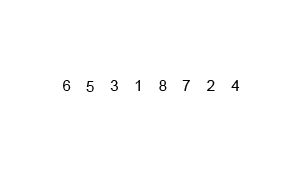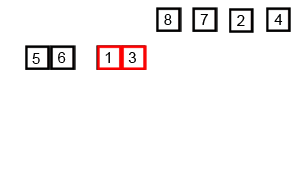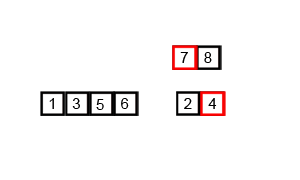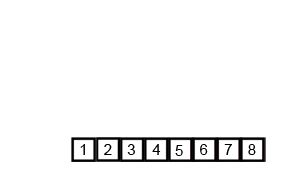
基数排序
基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort,顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序,其时间复杂度为O (nlog(r)m),其中r为所采取的基数,而m为堆数,在某些时候,基数排序法的效率高于其它的稳定性排序法。我们来看下面的一个例子:

8种排序的分类,稳定性,时间复杂度和空间复杂度总结如下所示:

小编寄语:该博客,小编简单的介绍了八种排序方法,分别详细的介绍了每种排序到底是如何排序的,以及在博文的结尾,把各种算法的时间复杂度以及空间复杂度整理成了一张表格,希望可以帮助到有需要的小伙伴。排序是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为“有序”的记录序列。分内部排序和外部排序。若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。反之,若参加排序的记录数量很大,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。内部排序的过程是一个逐步扩大记录的有序序列长度的过程。

