
- 1PyTorch版YOLOv4训练自己的数据集---基于Google Colab_whisper训练自己数据
- 2神经网络基础 —— Seq2Seq的应用_seq1的优先级高于seq2怎么用
- 3Python实战:史上最全| 圣诞树画法_python 3d粒子圣诞树
- 4springboot2.3.x整合JWT_springboot 整合jwt
- 5大语言模型原理与工程实践:适配器微调
- 6数据分析软件之SPSS、Stata、Matlab_spss和stata
- 7【Vue3】Axios简易二次封装+token+跨域问题+接口同步调用使用。_vue3 axios token
- 8ERR! configure error gyp ERR! stack Error: Can't find Python executable "python"_gyp err! configure error gyp err! stack error: can
- 9个人博客系统_个人博客应该有哪些功能
- 10【网路安全 --- pikachu靶场安装】超详细的pikachu靶场安装教程(提供靶场代码及工具)
人工智能万卡 GPU 集群的硬件和网络架构_万卡集群需要多少4090
赞
踩

万卡 GPU 集群互联:硬件配置和网络设计
一、背景
自从 OpenAI 推出 ChatGPT 以来,LLM 迅速成为焦点关注的对象,并取得快速发展。众多企业纷纷投入 LLM 预训练,希望跟上这一波浪潮。然而,要训练一个 100B 规模的 LLM,通常需要庞大的计算资源,例如拥有万卡 GPU 的集群。以 Falcon 系列模型为例,其在 4096 个 A100 组成的集群上训练 180B 模型,训练 3.5T Token 耗时将近 70 天。随着数据规模不断膨胀,对算力的需求也日益增长。例如,Meta 在训练其 LLaMA3 系列模型时使用了 15T 的 Token,这一过程是在 2 个 24K H100 集群上完成的。
本文深入探讨构建大规模GPU集群的关键组件与配置。涵盖多样GPU类型与服务器配置,网络设备(网卡、交换机、光模块)调优,以及数据中心网络拓扑设计(如3-Tier、Fat-Tree)。特别聚焦NVIDIA DGX A100与DGX H100 SuperPod的精准配置与网络布局,同时概览业界万卡集群标准拓扑。助您全面理解,高效构建大规模GPU集群。
构建超万卡GPU集群是一项复杂的挑战,涉及存储网络、管理网络等多个维度。尽管本文仅触及冰山一角,但已深入探讨了广泛采用的树形拓扑结构。值得注意的是,电力与冷却系统作为集群稳定运行的关键,同样不可或缺。未来,集群的构建与维护还需在这些方面持续精进。
二、相关组件
2.1 GPU
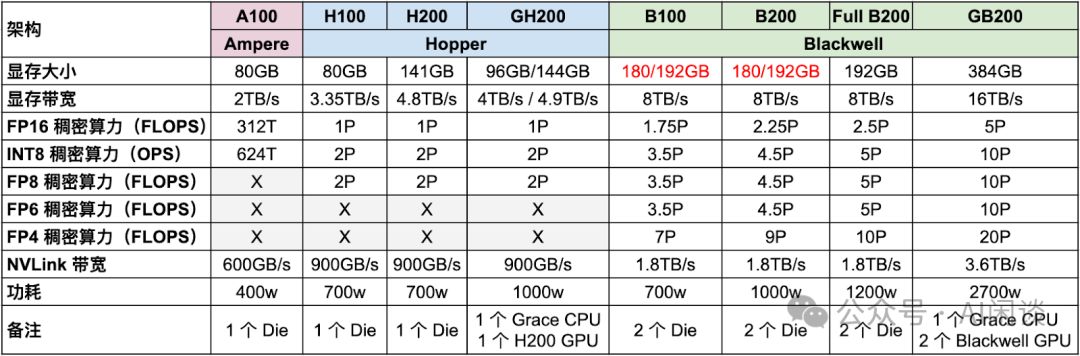
Ampere、Hopper及最新Blackwell系列GPU持续进化,如图表所示,显存、算力及NVLink性能均显著增强,彰显其强大的技术迭代与性能提升。
- A100升级至H100,FP16稠密算力提升超3倍,功耗从400w增至700w,效能显著提升,为高性能计算注入新动力。
- H200升级至B200,FP16稠密算力翻倍,功耗仅从700w增至1000w,性能提升显著,能效比优异。
- Blackwell GPU以其FP4精度支持,算力高达FP8的两倍。NVIDIA报告中,FP4算力与Hopper架构FP8算力对比,凸显了显著的加速优势,展现了Blackwell GPU的卓越性能。
- GB200搭载完整的Full B200芯片,而B100和B200则是其简化版本,确保性能与成本的精准平衡。
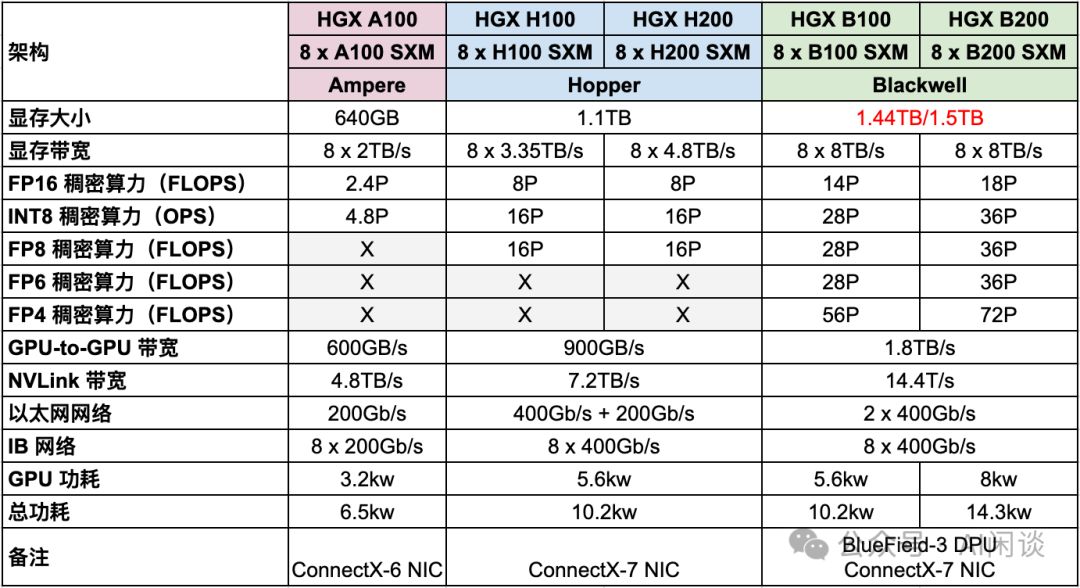
2.2 HGX
HGX,NVIDIA倾力打造的高性能服务器,集8或4个GPU于一身,搭载Intel或AMD CPU。其NVLink与NVSwitch技术实现全面互联,确保性能极致释放(8个GPU为NVLink全互联上限)。散热系统采用风冷设计,确保稳定运行。HGX,引领服务器性能新纪元。
- HGX A100升级至HGX H100和HGX H200,FP16稠密算力激增3.3倍,同时功耗控制不到原两倍,性能卓越,效率领先。
- HGX B100和B200在FP16稠密算力上实现近2倍提升,相较HGX H100和H200,功耗保持相当,最多节省近半,性能卓越且能效出众。
- HGX B100与B200网络保持原配,后向IB网卡维持8x400Gb/s高速传输,无需升级,确保稳定高效。
NVIDIA DGX与HGX,专为深度学习、人工智能及大规模计算打造的高性能解决方案,各具特色,满足不同设计及应用需求。
- DGX,专为普通消费者打造,提供即插即用高性能方案,配备完整软件支持,涵盖NVIDIA深度学习软件栈、驱动与工具,预构建且封闭,轻松满足您的多样化需求。
- HGX,专为云服务提供商与大规模数据中心运营商打造,构建高性能定制解决方案的利器。模块化设计,支持按需定制硬件,作为硬件平台或参考架构,助力客户构建卓越性能。
2.3 网络
2.3.1 网卡
这里主要介绍 ConnectX-5/6/7/8,是 Mellanox 的高速网卡,都支持以太网和 IB(InfiniBand)。2016 年发布 ConnectX-5,2019 年 NVIDIA 收购 Mellanox,然后 2020 年发布了 ConnectX-6,2022 年发布 ConnectX-7,2024 年 GTC 大会上老黄介绍了 ConnectX-8,还没看到详细参数。几个网卡对应的简要配置如下所示,可以看出,基本上每一代的总带宽都翻倍,下一代估计能到 1.6Tbps:

2.3.2 交换机
NVIDIA提供以太网和IB交换机,支持数十至数百端口。其总吞吐量(双向交换能力)计算为最大带宽乘以端口数再乘以2,这里的2代表双向传输。这一配置确保高性能的数据传输和处理能力。
Spectrum-X系列以太网交换机,支持高带宽数据传输,满足多样化网络需求。尽管低带宽也兼容,但总端口数固定,故在此主要展示高带宽数据。
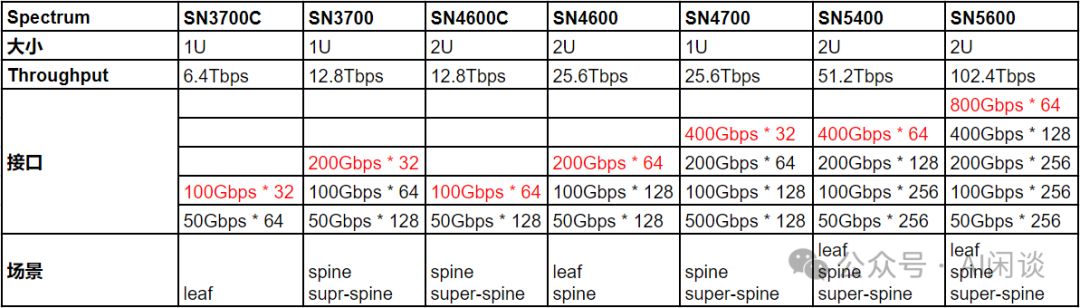
如下图为常见的 Quantum-X 系列 IB 交换机:

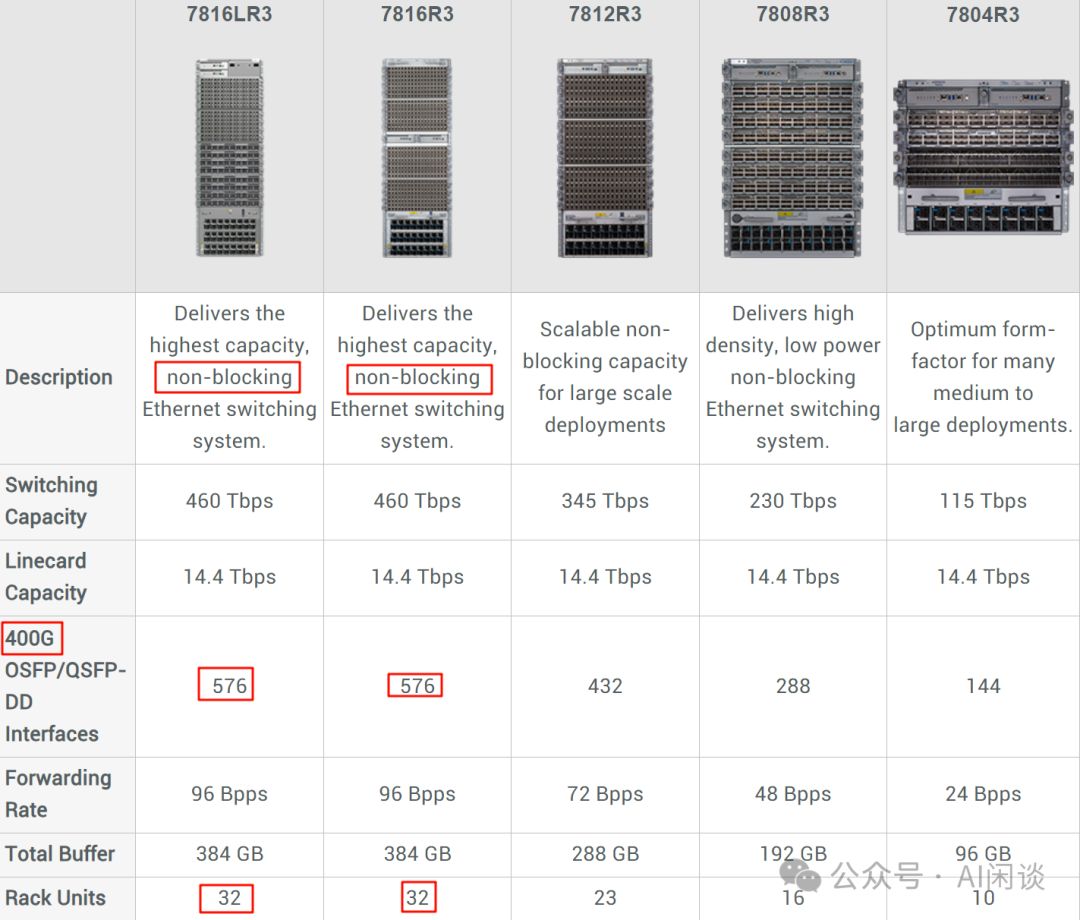
除了以上的 Mellanox 交换机外,现在也有很多数据中心会采用框式交换机(Modular Switch),比如 Meta 最近的 Building Meta's GenAI Infrastructure 中提到其构建了 2 个包含 24K H100 的 GPU 集群,其中使用了 Arista 7800 系列交换机,而 7800 系列就包含框式交换机,如下图所示,7816LR3 和 7816R3 甚至可以提供 576 Port 的 400G 高速带宽,其内部通过高效的总线或者交换背板互联,传输和处理的延迟非常低:
2.3.3 光模块
光模块是光纤通信的核心,可将电信号高效转化为光信号,通过光纤传输,实现超高速率、长距离通信,且抗电磁干扰能力强。它集成发射器与接收器,前者负责电转光,后者实现光转电,为现代通信提供坚实技术支撑。下图为光模块结构示意,展现其工作原理与卓越性能。

SFP与QSFP,光纤通信中两大光模块接口。SFP小巧便携,QSFP则四倍扩展。两者在尺寸、带宽及应用上各有千秋:S


