
- 1使用idea 把一个git分支的部分提交记录合并到另一个git分支上_idea 将一部分提交同步到其他项目
- 2【OpenCV】给图像添加噪声_翻转,切割,增加噪声
- 3python批量命名教程_《自拍教程69》Python 批量重命名音频文件,AV专家必备!
- 4四年背的单词 笔记目录_119.23.244.79:8081/topic/frame/race/login.html
- 5pip安装pandas
- 6Kafka:什么是kafka? ①_kafka kafka
- 7Linux如何创建文件在指定的目录?_在指定目录下创建文件
- 8Unity_VRTK 3.2.1_UI手柄射线检测点击事件的问题_unity htc vrtk 射线 点击ui
- 9YOLOV5源码的详细解读_yolov5代码详解
- 10资深SRE带你看阿里云香港故障_sre故障复盘需要关注的问题
全网最详细中英文ChatGPT接口文档(五)30分钟快速入门ChatGPT——手把手示例教程:如何建立一个人工智能回答关于您的网站问题,小白也可学_chatgpt in english website
赞
踩
30分钟开始使用ChatGPT——Models模型

How to build an AI that can answer questions about your website 如何建立一个人工智能,回答有关您的网站的问题
This tutorial walks through a simple example of crawling a website (in this example, the OpenAI website), turning the crawled pages into embeddings using the Embeddings API, and then creating a basic search functionality that allows a user to ask questions about the embedded information. This is intended to be a starting point for more sophisticated applications that make use of custom knowledge bases.
本教程介绍了一个简单的示例,该示例包括爬取网站(在本例中为OpenAI网站),使用Embeddings API将爬取的页面转换为嵌入内容,然后创建一个基本的搜索功能,允许用户询问有关嵌入信息的问题。这旨在作为使用自定义知识库进行更复杂应用程序的起点。
Getting started 入门
Some basic knowledge of Python and GitHub is helpful for this tutorial. Before diving in, make sure to set up an OpenAI API key and walk through the quickstart tutorial. This will give a good intuition on how to use the API to its full potential.
Python和GitHub的一些基本知识对本教程很有帮助。在开始之前,请确保设置OpenAI API密钥并浏览快速入门教程。这将使您对如何充分利用API的潜力有一个很好的直觉。
Python is used as the main programming language along with the OpenAI, Pandas, transformers, NumPy, and other popular packages. If you run into any issues working through this tutorial, please ask a question on the OpenAI Community Forum.
Python与OpenAI、Pandas、transformers、NumPy和其他流行的功能包被用作主要编程语言。如果您在本教程中遇到任何问题,请在OpenAI社区论坛上提问。
To start with the code, clone the full code for this tutorial on GitHub. Alternatively, follow along and copy each section into a Jupyter notebook and run the code step by step, or just read along. A good way to avoid any issues is to set up a new virtual environment and install the required packages by running the following commands:
要从代码开始,请在GitHub上克隆本教程的完整代码。或者,按照下面的步骤操作,将每一部分复制到Jupyter笔记本中,然后一步一步地运行代码,或者只是阅读。避免任何问题的一个好方法是通过运行以下命令设置新的虚拟环境并安装所需的软件包:
python -m venv env
source env/bin/activate
pip install -r requirements.txt
- 1
- 2
- 3
- 4
- 5
Setting up a web crawler 设置Web爬网程序
The primary focus of this tutorial is the OpenAI API so if you prefer, you can skip the context on how to create a web crawler and just download the source code. Otherwise, expand the section below to work through the scraping mechanism implementation.
本教程的重点是OpenAI API,因此如果您愿意,可以跳过有关如何创建网络爬虫的上下文,直接下载源代码。否则,请展开下面的部分以完成刮擦机制的实现。
Learn how to build a web crawler 了解如何构建网络爬虫
Acquiring data in text form is the first step to use embeddings. This tutorial creates a new set of data by crawling the OpenAI website, a technique that you can also use for your own company or personal website.
获取文本形式的数据是使用嵌入的第一步。本教程通过爬取OpenAI网站创建了一组新的数据,这种技术也可以用于您自己的公司或个人网站。

While this crawler is written from scratch, open source packages like Scrapy can also help with these operations.
虽然这个爬虫是从头开始编写的,但是像Scrapy这样的开源包也可以帮助完成这些操作。
This crawler will start from the root URL passed in at the bottom of the code below, visit each page, find additional links, and visit those pages as well (as long as they have the same root domain). To begin, import the required packages, set up the basic URL, and define a HTMLParser class.
这个爬虫将从下面代码底部传入的根URL开始,访问每个页面,查找其他链接,并访问这些页面(只要它们具有相同的根域)。开始,导入所需的包,设置基本URL,并定义一个HTMLParser类。
import requests
import re
import urllib.request
from bs4 import BeautifulSoup
from collections import deque
from html.parser import HTMLParser
from urllib.parse import urlparse
import os
# Regex pattern to match a URL
HTTP_URL_PATTERN = r'^http[s]*://.+'
domain = "openai.com" # <- put your domain to be crawled
full_url = "https://openai.com/" # <- put your domain to be crawled with https or http
# Create a class to parse the HTML and get the hyperlinks
class HyperlinkParser(HTMLParser):
def __init__(self):
super().__init__()
# Create a list to store the hyperlinks
self.hyperlinks = []
# Override the HTMLParser's handle_starttag method to get the hyperlinks
def handle_starttag(self, tag, attrs):
attrs = dict(attrs)
# If the tag is an anchor tag and it has an href attribute, add the href attribute to the list of hyperlinks
if tag == "a" and "href" in attrs:
self.hyperlinks.append(attrs["href"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
The next function takes a URL as an argument, opens the URL, and reads the HTML content. Then, it returns all the hyperlinks found on that page.
下一个函数将URL作为参数,打开URL并读取HTML内容。然后,它返回在该页上找到的所有超链接。
# Function to get the hyperlinks from a URL
def get_hyperlinks(url):
# Try to open the URL and read the HTML
try:
# Open the URL and read the HTML
with urllib.request.urlopen(url) as response:
# If the response is not HTML, return an empty list
if not response.info().get('Content-Type').startswith("text/html"):
return []
# Decode the HTML
html = response.read().decode('utf-8')
except Exception as e:
print(e)
return []
# Create the HTML Parser and then Parse the HTML to get hyperlinks
parser = HyperlinkParser()
parser.feed(html)
return parser.hyperlinks
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
The goal is to crawl through and index only the content that lives under the OpenAI domain. For this purpose, a function that calls the get_hyperlinks function but filters out any URLs that are not part of the specified domain is needed.
目标是只对OpenAI域下的内容进行爬行和索引。为此,需要一个调用 get_hyperlinks 函数但过滤掉不属于指定域的任何URL的函数。
# Function to get the hyperlinks from a URL that are within the same domain
def get_domain_hyperlinks(local_domain, url):
clean_links = []
for link in set(get_hyperlinks(url)):
clean_link = None
# If the link is a URL, check if it is within the same domain
if re.search(HTTP_URL_PATTERN, link):
# Parse the URL and check if the domain is the same
url_obj = urlparse(link)
if url_obj.netloc == local_domain:
clean_link = link
# If the link is not a URL, check if it is a relative link
else:
if link.startswith("/"):
link = link[1:]
elif link.startswith("#") or link.startswith("mailto:"):
continue
clean_link = "https://" + local_domain + "/" + link
if clean_link is not None:
if clean_link.endswith("/"):
clean_link = clean_link[:-1]
clean_links.append(clean_link)
# Return the list of hyperlinks that are within the same domain
return list(set(clean_links))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
The crawl function is the final step in the web scraping task setup. It keeps track of the visited URLs to avoid repeating the same page, which might be linked across multiple pages on a site. It also extracts the raw text from a page without the HTML tags, and writes the text content into a local .txt file specific to the page.
crawl 函数是网页抓取任务设置的最后一步。它跟踪访问过的URL,以避免重复同一个页面,这可能是跨网站上的多个页面链接。它还从没有HTML标记的页面中提取原始文本,并将文本内容写入特定于该页面的本地.txt文件。
def crawl(url):
# Parse the URL and get the domain
local_domain = urlparse(url).netloc
# Create a queue to store the URLs to crawl
queue = deque([url])
# Create a set to store the URLs that have already been seen (no duplicates)
seen = set([url])
# Create a directory to store the text files
if not os.path.exists("text/"):
os.mkdir("text/")
if not os.path.exists("text/"+local_domain+"/"):
os.mkdir("text/" + local_domain + "/")
# Create a directory to store the csv files
if not os.path.exists("processed"):
os.mkdir("processed")
# While the queue is not empty, continue crawling
while queue:
# Get the next URL from the queue
url = queue.pop()
print(url) # for debugging and to see the progress
# Save text from the url to a <url>.txt file
with open('text/'+local_domain+'/'+url[8:].replace("/", "_") + ".txt", "w", encoding="UTF-8") as f:
# Get the text from the URL using BeautifulSoup
soup = BeautifulSoup(requests.get(url).text, "html.parser")
# Get the text but remove the tags
text = soup.get_text()
# If the crawler gets to a page that requires JavaScript, it will stop the crawl
if ("You need to enable JavaScript to run this app." in text):
print("Unable to parse page " + url + " due to JavaScript being required")
# Otherwise, write the text to the file in the text directory
f.write(text)
# Get the hyperlinks from the URL and add them to the queue
for link in get_domain_hyperlinks(local_domain, url):
if link not in seen:
queue.append(link)
seen.add(link)
crawl(full_url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
The last line of the above example runs the crawler which goes through all the accessible links and turns those pages into text files. This will take a few minutes to run depending on the size and complexity of your site.
上例的最后一行运行了爬行器,它遍历所有可访问的链接,并将这些页面转换为文本文件。根据站点的大小和复杂性,这将需要几分钟的时间来运行。
Building an embeddings index 构建嵌入索引
CSV is a common format for storing embeddings. You can use this format with Python by converting the raw text files (which are in the text directory) into Pandas data frames. Pandas is a popular open source library that helps you work with tabular data (data stored in rows and columns).
CSV是存储嵌入的常用格式。通过将原始文本文件(位于text目录中)转换为Pandas数据框,可以在Python中使用此格式。Pandas是一个流行的开源库,可以帮助您处理表格数据(以行和列存储的数据)。
Blank empty lines can clutter the text files and make them harder to process. A simple function can remove those lines and tidy up the files.
空白的空行会使文本文件混乱,使它们更难处理。一个简单的函数可以删除这些行并整理文件。
def remove_newlines(serie):
serie = serie.str.replace('\n', ' ')
serie = serie.str.replace('\\n', ' ')
serie = serie.str.replace(' ', ' ')
serie = serie.str.replace(' ', ' ')
return serie
- 1
- 2
- 3
- 4
- 5
- 6
Converting the text to CSV requires looping through the text files in the text directory created earlier. After opening each file, remove the extra spacing and append the modified text to a list. Then, add the text with the new lines removed to an empty Pandas data frame and write the data frame to a CSV file.
将文本转换为CSV需要遍历前面创建的文本目录中的文本文件。打开每个文件后,删除多余的空格并将修改的文本附加到列表中。然后,将删除了新行的文本添加到空的Pandas数据框中,并将数据框写入CSV文件。
Extra spacing and new lines can clutter the text and complicate the embeddings process. The code used here helps to remove some of them but you may find 3rd party libraries or other methods useful to get rid of more unnecessary characters.
额外的间距和新行会使文本混乱,并使嵌入过程复杂化。这里使用的代码有助于删除其中的一些字符,但您可能会发现第三方库或其他方法有助于删除更多不必要的字符。
import pandas as pd
# Create a list to store the text files
texts=[]
# Get all the text files in the text directory
for file in os.listdir("text/" + domain + "/"):
# Open the file and read the text
with open("text/" + domain + "/" + file, "r", encoding="UTF-8") as f:
text = f.read()
# Omit the first 11 lines and the last 4 lines, then replace -, _, and #update with spaces.
texts.append((file[11:-4].replace('-',' ').replace('_', ' ').replace('#update',''), text))
# Create a dataframe from the list of texts
df = pd.DataFrame(texts, columns = ['fname', 'text'])
# Set the text column to be the raw text with the newlines removed
df['text'] = df.fname + ". " + remove_newlines(df.text)
df.to_csv('processed/scraped.csv')
df.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Tokenization is the next step after saving the raw text into a CSV file. This process splits the input text into tokens by breaking down the sentences and words. A visual demonstration of this can be seen by checking out our Tokenizer in the docs.
标记化是将原始文本保存到CSV文件后的下一步。此过程通过分解句子和单词将输入文本拆分为标记。通过查看文档中的Tokenizer可以看到这方面的可视化演示。
A helpful rule of thumb is that one token generally corresponds to ~4 characters of text for common English text. This translates to roughly ¾ of a word (so 100 tokens ~= 75 words).
一个有用的经验法则是,对于普通英语文本,一个标记通常对应于文本的4个字符。这大约相当于一个单词的¾(所以100个标记= 75个单词)。
The API has a limit on the maximum number of input tokens for embeddings. To stay below the limit, the text in the CSV file needs to be broken down into multiple rows. The existing length of each row will be recorded first to identify which rows need to be split.
API对用于嵌入的输入标记的最大数量有限制。要保持在限制之下,CSV文件中的文本需要分解为多行。将首先记录每一行的现有长度,以确定需要拆分哪些行。
import tiktoken
# Load the cl100k_base tokenizer which is designed to work with the ada-002 model
tokenizer = tiktoken.get_encoding("cl100k_base")
df = pd.read_csv('processed/scraped.csv', index_col=0)
df.columns = ['title', 'text']
# Tokenize the text and save the number of tokens to a new column
df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x)))
# Visualize the distribution of the number of tokens per row using a histogram
df.n_tokens.hist()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
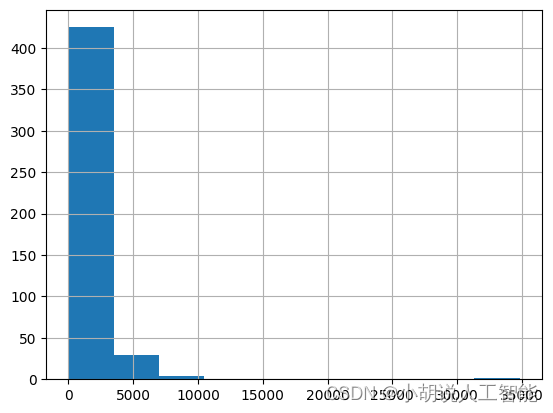
The newest embeddings model can handle inputs with up to 8191 input tokens so most of the rows would not need any chunking, but this may not be the case for every subpage scraped so the next code chunk will split the longer lines into smaller chunks.
最新的嵌入模型可以处理多达8191个输入标记的输入,因此大多数行不需要任何分块,但对于每个被抓取的子页可能不是这样,因此下一个代码块将把较长的行分成较小的块。
max_tokens = 500
# Function to split the text into chunks of a maximum number of tokens
def split_into_many(text, max_tokens = max_tokens):
# Split the text into sentences
sentences = text.split('. ')
# Get the number of tokens for each sentence
n_tokens = [len(tokenizer.encode(" " + sentence)) for sentence in sentences]
chunks = []
tokens_so_far = 0
chunk = []
# Loop through the sentences and tokens joined together in a tuple
for sentence, token in zip(sentences, n_tokens):
# If the number of tokens so far plus the number of tokens in the current sentence is greater
# than the max number of tokens, then add the chunk to the list of chunks and reset
# the chunk and tokens so far
if tokens_so_far + token > max_tokens:
chunks.append(". ".join(chunk) + ".")
chunk = []
tokens_so_far = 0
# If the number of tokens in the current sentence is greater than the max number of
# tokens, go to the next sentence
if token > max_tokens:
continue
# Otherwise, add the sentence to the chunk and add the number of tokens to the total
chunk.append(sentence)
tokens_so_far += token + 1
return chunks
shortened = []
# Loop through the dataframe
for row in df.iterrows():
# If the text is None, go to the next row
if row[1]['text'] is None:
continue
# If the number of tokens is greater than the max number of tokens, split the text into chunks
if row[1]['n_tokens'] > max_tokens:
shortened += split_into_many(row[1]['text'])
# Otherwise, add the text to the list of shortened texts
else:
shortened.append( row[1]['text'] )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
Visualizing the updated histogram again can help to confirm if the rows were successfully split into shortened sections.
再次可视化更新的直方图有助于确认行是否成功拆分为缩短的部分。
df = pd.DataFrame(shortened, columns = ['text'])
df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x)))
df.n_tokens.hist()
- 1
- 2
- 3

The content is now broken down into smaller chunks and a simple request can be sent to the OpenAI API specifying the use of the new text-embedding-ada-002 model to create the embeddings:
内容现在被分解成更小的块,可以向OpenAI API发送一个简单的请求,指定使用新的text-embedded-ada-002模型来创建嵌入:
import openai
df['embeddings'] = df.text.apply(lambda x: openai.Embedding.create(input=x, engine='text-embedding-ada-002')['data'][0]['embedding'])
df.to_csv('processed/embeddings.csv')
df.head()
- 1
- 2
- 3
- 4
- 5
- 6
This should take about 3-5 minutes but after you will have your embeddings ready to use!
这应该需要大约3-5分钟,但之后您将有您的嵌入准备使用!
Building a question answer system with your embeddings 使用嵌入式构建问答系统
The embeddings are ready and the final step of this process is to create a simple question and answer system. This will take a user’s question, create an embedding of it, and compare it with the existing embeddings to retrieve the most relevant text from the scraped website. The text-davinci-003 model will then generate a natural sounding answer based on the retrieved text.
嵌入已经准备好了,这个过程的最后一步是创建一个简单的问答系统。这将接受用户的问题,创建一个嵌入,并将其与现有的嵌入进行比较,以检索从抓取的网站最相关的文本。然后,text-davinci-003模型将基于检索到的文本生成听起来自然的回答。

Turning the embeddings into a NumPy array is the first step, which will provide more flexibility in how to use it given the many functions available that operate on NumPy arrays. It will also flatten the dimension to 1-D, which is the required format for many subsequent operations.
将嵌入转换为NumPy数组是第一步,这将为如何使用NumPy数组提供更大的灵活性,因为NumPy数组上有许多可用的函数。它还会将尺寸展平为1-D,这是许多后续操作所需的格式。
import numpy as np
from openai.embeddings_utils import distances_from_embeddings
df=pd.read_csv('processed/embeddings.csv', index_col=0)
df['embeddings'] = df['embeddings'].apply(eval).apply(np.array)
df.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
The question needs to be converted to an embedding with a simple function, now that the data is ready. This is important because the search with embeddings compares the vector of numbers (which was the conversion of the raw text) using cosine distance. The vectors are likely related and might be the answer to the question if they are close in cosine distance. The OpenAI python package has a built in distances_from_embeddings function which is useful here.
既然数据已经准备好了,这个问题需要转换成一个简单函数的嵌入。这一点很重要,因为嵌入搜索使用余弦距离比较数字向量(原始文本的转换)。这两个向量很可能是相关的,如果它们的余弦距离很近,就可能是这个问题的答案。OpenAI python包有一个内置的 distances_from_embeddings 函数,在这里很有用。
def create_context(
question, df, max_len=1800, size="ada"
):
"""
Create a context for a question by finding the most similar context from the dataframe
"""
# Get the embeddings for the question
q_embeddings = openai.Embedding.create(input=question, engine='text-embedding-ada-002')['data'][0]['embedding']
# Get the distances from the embeddings
df['distances'] = distances_from_embeddings(q_embeddings, df['embeddings'].values, distance_metric='cosine')
returns = []
cur_len = 0
# Sort by distance and add the text to the context until the context is too long
for i, row in df.sort_values('distances', ascending=True).iterrows():
# Add the length of the text to the current length
cur_len += row['n_tokens'] + 4
# If the context is too long, break
if cur_len > max_len:
break
# Else add it to the text that is being returned
returns.append(row["text"])
# Return the context
return "\n\n###\n\n".join(returns)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
The text was broken up into smaller sets of tokens, so looping through in ascending order and continuing to add the text is a critical step to ensure a full answer. The max_len can also be modified to something smaller, if more content than desired is returned.
文本被分解为更小的标记集,因此按升序循环并继续添加文本是确保完整答案的关键步骤。如果返回的内容多于所需的内容,max_len也可以修改为更小的值。
The previous step only retrieved chunks of texts that are semantically related to the question, so they might contain the answer, but there’s no guarantee of it. The chance of finding an answer can be further increased by returning the top 5 most likely results.
上一步只检索了与问题语义相关的文本块,因此它们可能包含答案,但不能保证一定包含答案。通过返回前5个最可能的结果,可以进一步增加找到答案的机会。
The answering prompt will then try to extract the relevant facts from the retrieved contexts, in order to formulate a coherent answer. If there is no relevant answer, the prompt will return “I don’t know”.
然后,回答提示将尝试从检索到的上下文中提取相关事实,以便形成连贯的回答。如果没有相关答案,提示会返回“我不知道”。
A realistic sounding answer to the question can be created with the completion endpoint using text-davinci-003.
可以使用 text-davinci-003 创建具有完成终点的问题的实际答案。
def answer_question(
df,
model="text-davinci-003",
question="Am I allowed to publish model outputs to Twitter, without a human review?",
max_len=1800,
size="ada",
debug=False,
max_tokens=150,
stop_sequence=None
):
"""
Answer a question based on the most similar context from the dataframe texts
"""
context = create_context(
question,
df,
max_len=max_len,
size=size,
)
# If debug, print the raw model response
if debug:
print("Context:\n" + context)
print("\n\n")
try:
# Create a completions using the question and context
response = openai.Completion.create(
prompt=f"Answer the question based on the context below, and if the question can't be answered based on the context, say \"I don't know\"\n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer:",
temperature=0,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=stop_sequence,
model=model,
)
return response["choices"][0]["text"].strip()
except Exception as e:
print(e)
return ""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
It is done! A working Q/A system that has the knowledge embedded from the OpenAI website is now ready. A few quick tests can be done to see the quality of the output:
完成了!现在已经准备好了一个工作中的Q/A系统,其中包含了来自OpenAI网站的知识。可以进行一些快速测试来查看输出的质量:
answer_question(df, question="What day is it?", debug=False)
answer_question(df, question="What is our newest embeddings model?")
answer_question(df, question="What is ChatGPT?")
- 1
- 2
- 3
- 4
- 5
The responses will look something like the following:
响应将如下所示:
"I don't know."
'The newest embeddings model is text-embedding-ada-002.'
'ChatGPT is a model trained to interact in a conversational way. It is able to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests.'
- 1
- 2
- 3
- 4
- 5
If the system is not able to answer a question that is expected, it is worth searching through the raw text files to see if the information that is expected to be known actually ended up being embedded or not. The crawling process that was done initially was setup to skip sites outside the original domain that was provided, so it might not have that knowledge if there was a subdomain setup.
如果系统不能回答预期的问题,则需要搜索原始文本文件,以查看预期已知的信息是否最终被嵌入。最初完成的爬网过程被设置为跳过所提供的原始域之外的站点,因此如果设置了子域,它可能不知道这些站点。
Currently, the dataframe is being passed in each time to answer a question. For more production workflows, a vector database solution should be used instead of storing the embeddings in a CSV file, but the current approach is a great option for prototyping.
目前,每次都要传入数据帧来回答一个问题。对于更多的生产工作流,应该使用矢量数据库解决方案,而不是将嵌入存储在CSV文件中,但当前的方法是原型化的一个很好的选择。
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。

