
- 1成功实操记录ChatGLM6b大模型_hf-mirror下载chatglm-6b需要多久
- 2详细介绍别人电脑访问到自己电脑运行的项目_如何让其他计算机访问自己的计算机的资源
- 3Win10 TensorFlow(gpu)安装详解_tensorflow-gpu
- 4vscode-Connecting with SSH timed out
- 5Java:2022年最流行的Web开发Java框架_外部开发最流行的框架
- 6【Linux】线程池的简易实现(懒汉模式)
- 7win10 搭建php服务器搭建,Win10平台下安装并配置php
- 8如何实现企微群机器人定时发送消息提醒?_企业微信机器人定时发送消息设置
- 9【SCons】SCons编译软件工程(一)_scon软件
- 10MYSQL下载及安装完整教程_怎么下载mysql
资深SRE带你看阿里云香港故障_sre故障复盘需要关注的问题
赞
踩
一、故障背景
12月18日阿里云香港Region发生重大故障,多个重要互联网服务受到影响,包括澳门日报、金融管理局、澳门银河、莲花卫视、澳门水泥厂等基础服务,澳觅和MFood等外卖平台,多个区块链交易所也受到影响。详情见官方故障报告《关于阿里云香港Region可用区C服务中断事件的说明 (aliyun.com)》。我的新书《SRE原理与实践:构建高可靠性互联网应用》刚发布,借此机会推荐给所有关注互联网服务可靠性的人。本文我会深入分析故障情况和潜在问题,并对照书中内容来探讨问题根源及解决思路,详细内容请阅读原书。

图1:新书封面
https://item.jd.com/13603499.html
互联网服务中断是个行业难题
本次故障给客户造成直接经济损失和品牌形象的影响。云厂商按照SLA赔偿对大部分客户来说是微不足道的、与损失难以对等;对云而言,支付SLA赔偿是一个损失,更重要是影响了客户对云的信任,可能会促使一些客户实施迁云或者选择多云架构;影响了市民和客户服务,特别是本地生活服务的那些用户、交易平台需要进行投资的用户。
互联网服务中断是个行业难题,国外故障监测网站Downdetector统计了2022年前十大报障最多的互联网服务,如下图2所示。故障报告最多是Spotify和WhatsApp,用户主动报告近300万例。故障并不鲜见,我书中开篇列举了近4年行业典型故障,触目惊心,有的故障导致损失上亿美元,有的导致企业市值蒸发千亿,有些严重影响用户生活。
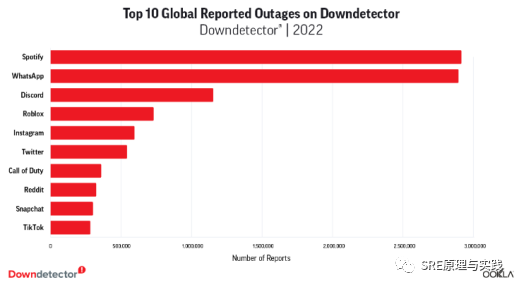
图2:2022全球故障报告次数Top10(源自 Downdetector.com)
二、机房->云产品->业务几个层都暴露严重问题
把故障过程先简单描述一下,由于制冷设备故障引起的机房内服务器不可用,机房故障影响了ECS、RDS、OSS、SLB、NAT等云产品,同时由于容量不够导致管控系统和API调用不可用,造成了大量的客户业务不能使用。可以看出这里涉及三层服务,机房及服务器、云产品及管控系统、业务服务。这三层任何一个出现问题都可能导致业务故障。如何分析可靠性问题并识别风险,详见书中3.4《可靠性分析与架构风险》。
(一)直接原因:制冷系统的伪高可用
先看冷机修复的问题
其时间线如下:
12月18日08:56,阿里云监控到香港可用区C机房包间通道温控告警
12:30,冷机设备供应商到场
14:47,排查遇到困难,其中一个包间因高温触发了强制消防喷淋
15:20,经冷机设备商工程师现场手工调整配置,冷机群控解锁完成并独立运行
18:55,4台冷机恢复到正常制冷量
21:36,大部分机房包间服务器陆续启动并完成检查
22:50,被喷淋的包间逐步供电和服务器启动。
存在几个明显问题:
1、处理过程问题1:响应和到场时间太晚,香港不大,三个半小时才到。
2、处理过程问题2:没有预案要靠现场排查现场改逻辑,三个小时才查到并解锁群控逻辑。
3、处理过程问题3:处理过程忽视了温度持续升高及喷淋系统的自动化逻辑,触发了喷淋程序,造成部分硬件损坏,导致一个包间故障时长被延长。
4、架构设计问题1:制冷设备容灾没有经过演练,以为有了4+4容灾,实际上主备设备共用了水路循环系统。导致容灾切换失败。在书中也举了网络专线的共用单一节点导致故障的例子。
5、架构设计问题2:冷机群控逻辑导致只能批量启动冷机,而没法单台独立启动。架构设计脱离实际或是考虑不周。架构设计中容易出现这样的问题,过度设计而脱离实际或主次不分。
6、可能的问题:处理冷机故障过程没有做好协同管理,涉及众多客户、阿里云本部人员(基础设施及各个云产品人员)、现场代维人员、冷机公司人员,导致故障被拉长。比如到其他AZ申请资源的高峰是比较晚的时候了,早做迁移其实问题更小。
冷机故障并非个例,做好处理预案才是王道。今年7月,由谷歌和甲骨文运营的伦敦东部数据中心在该地区有记录以来最强烈的热浪中遭受了崩溃。该国部分地区气温甚至高于40摄氏度。
阿里云在基础设施层面的管理失责问题
机房制冷故障不完全是阿里云责任,但他们也出现了几个问题:
1、选择机房时没有发现制冷设备存在风险,也没有要求验证和巡检发现
2、处理人员在修复过程风险评估不准,机房多方沟通协同过程可能存在不够顺畅的问题
3、现场工程师对喷淋系统的工作机制不太清楚或忙中疏忽
书中也有详细探讨如何应对灾难型故障。见书中5.2 灾难型故障快速修复,部分内容如下图3所示。

图3:灾难型故障快速修复
(二)部分云产品及管控系统有明显缺陷
本次故障影响时间较长跟阿里云产品及管控系统也有关系。
云产品架构和配套系统问题。
有云产品依赖故障AZ(Available Zone可用区)的服务
自定义镜像数据服务依赖了故障AZ的OSS服务,部分RDS实例依赖了部署在故障AZ的代理服务。很明显这部分产品架构设计存在问题,不仅要考虑产品自身的高可用,还有考虑依赖的配套服务是否高可用。
有多个云产品是单AZ的。
VPN、Privatelink、部分GA实例、SLB、NAT服务。没有很快实现跨AZ容灾逃逸。
管控系统是个容易被忽视的问题。
在书中第6章有详细讨论。部分单AZ产品的容灾切换或迁移工具不够完备,管控工具在灾难发生时是救命稻草,管控系统不可用或不好用,会造成主备切换不成功的问题。
1.管控系统架构设计有问题
ECS管控服务、RDS管控服务、Dataworks、k8s用户控制台、操作API都出现了故障,且完全修复时间最晚。API的是核心服务,是管控系统和客户调用的核心服务,不应该这么容易挂,而且我认为应该有更高的优先级。
2.管控系统依赖配套的部署架构有问题
本故障中新扩容的ECS管控系统启动时依赖的中间件服务部署在故障AZ,导致较长时间内无法扩容,这点容易被忽视。
3.管控系统容量设计不足的问题
没有考虑到单AZ挂了后,客户涌入到其他AZ造成管控请求打爆。客户发起的管控请求再多,估计也不会特别大,管控系统的容量到底达到了多少而被打爆的,阿里云没有详述。这里有另外一个可能是其他AZ的资源不足或开资源要等待,造成请求的拥塞。
管控系统是故障后的救命稻草,应该有更高的可靠性。在书中6.2.2脆弱性因素分析一节有详细讨论,部分内容见下图4。
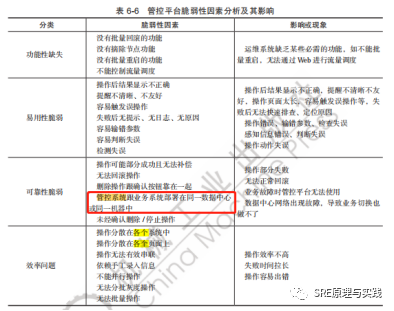
图4:管控平台脆弱性分析
在第7章工程师工作内容小节,有专门讨论工程师要负责管控系统的可靠性。
(三)业务方要负主体责任:明确可靠性核心保障对象是业务
首先要明确,可靠性保障的真正对象是业务,业务不能把可靠性责任都托付给公有云。首先要在业务层负起可靠性的主体责任。机房故障无法绝对避免,机房网络、电力、制冷总有概率出问题,或遭遇火灾、雷劈、地震、洪水、老鼠等天灾人祸。如何才能AZ故障发生后而不影响业务呢?
1、首先,应制定RTO(Recovery Time Objective,修复时间目标)。明确业务容灾需求,设计对应的可靠性架构方案,这涉及一定的资源成本投入。为消除单点灾难型故障,可以有多种架构:单机群多副本架构、容灾备份架构、同城双活架构、两地三中心架构、异地多活架构、多云/混合云/融合云架构。
2、即使不做冗余部署,也应建立符合RPO(Recovery Point Objective,恢复点目标)的备份,并异地存储。如在本次故障中如果知道会挂20几个小时,通过异地重新部署系统也可能是更好方案。
其实不仅有单AZ故障,容易出现灾难风险的点很多,如果不提前关注并解决,出问题是大概率的,书中有详细梳理并提出如何实现业务层的高可用。
三、故障处理与指挥协同的混乱
灾难型故障是一场遭遇战,指挥协同得当可最短时间结束战斗,取得胜利。我不是内部人士,以下部分内容凭经验猜测和业界反馈,认为可能存在以下问题:
1、内部沟通协作过程的问题。
可能存在对风险评估不足,没有在比较早的时候把风险级别提到最高,处理过程可能也存在误判,延误了故障处理。有些云产品服务响应较快,出现故障苗头(知道制冷故障但服务器还没大面积故障时)就开始处理了,有些云产品就比较迟缓,没有意识到风险正在到来。
2、对外信息通报问题、没有及时引导的问题。
这点被业界吐槽比较多,没有告知完整信息,而仅告知是盈科机房制冷设备故障,有推卸责任的嫌疑,且Status Page(服务可用性页面)更新不及时,受影响云产品不清晰,这让很多客户蒙圈。其实客户希望看到的是故障起因和具体影响范围、严重程度、可能恢复时长、建议方案、官方修复进展时间线等。
3、跟客户的协同混乱、帮助客户恢复业务无序低效。
从业界反馈来看,很多客户没有被告知准确的故障影响而是被云产品故障短信轰炸。没有很好组织用户有序迁移。很多客户到当天很晚还在抱怨没有恢复,其中是否都是用了单AZ产品的业务。
把云服务器和云产品启动了就算恢复了是不够的。有点遗憾,阿里云在12.25(故障一周后)发出的详细报告没有从客户角度分析恢复的过程。从微博反馈看,有不少客户恢复得比云的修复更晚很多。
在书中第5章介绍了如何进行一个大型故障的应急协同,也讨论了各种类型故障修复的方案,以及预案平台的建设等,值得互联网业务服务的工程师团队参考。
四、总结与复盘
深入复盘、有效整改、重建信任是重点工作。故障带来的损失无疑是巨大的,不仅是直接经济价值,也可能损失了客户对云的信任、客户企业可能可能损失了用户对他们的信任。按照SLA进行赔偿并不是客户最想要的,更需要深入复盘和有效整改,才能逐步重建信任。从受影响云客户角度也应该进行深入复盘,业务不能把可靠性责任都托付给公有云。使用单AZ冗余的产品是划算的吗?成本与风险的平衡点把握是否准确?最后要问,谁要对这次故障承担责任?谁要整改?怎么改?如何做好复盘可以阅读本书的第7章,复盘过程、复盘问题、根因分析、有效整改等方面都有深入讨论,提出了复盘“五条归零”的科学要求。
发生如此严重故障,阿里云的SLA肯定不好看,阿里云部分员工的年终估计也会 受到影响,更重要的是众多客户对阿里云甚至公有云的信任也可能大打折扣,依赖阿里云的企业将承受很大压力,他们同样也受到市民与客户的质疑。他们的2022年总结和2023年开局都不会很轻松。

