
- 1大数据导论(二:大数据的架构)_大数据架构是一种结构化和基于模式的方法来简化定义完整的大数据架构的任务,hadoo
- 2【投稿优惠-EI稳定检索】2024第四届数据科学、机器学习和应用国际会议 (ICDSMLA 2024)_数据挖掘,深度学习的ei会议推荐2024
- 3【算法之排序篇】 堆排序详解!(源码+图解)_堆排序代码
- 4上海大厂Java面试经历:java后端主动发送数据给前端_好了,目前的状况是时间不够,后端不做分页,直接传给前端数据,遇上真实的面试题
- 5Git上传文件不能超过100M的解决办法_git超过100m
- 6【毕业设计/课程设计】基于SpringBoot的火车售票系统设计与实现(源码+文章) Java | JSP | MVC | Web_基于spring boot的火车站订票系统设计与实现
- 7springboot项目生成war包并部署到Tomcat服务器_将springboot项目打包成war包,并部署到tomcat中
- 8Windows&Linux搭建frp内网穿透,自用收藏_frplinux使用
- 9CUDA与cuDNN_cuda cudnn 作用
- 10Python内置函数iter()、next()、关键字yield与生成器 generator_python next关键字
SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking
赞
踩
链接
arxiv:https://arxiv.org/abs/2211.12194
Project page:https://sadtalker.github.io/
摘要
通过人脸图像和一段语音音频生成会说话的头部视频仍然存在许多挑战。例如,不自然的头部运动,扭曲的表情和身份修改。我们认为这些问题主要是因为从耦合的二维运动场中学习。另一方面,显式使用3D信息也存在表达生硬和视频不连贯的问题。我们提出了SadTalker,它从音频中生成3DMM的3D运动系数(头部姿势,表情),并隐式调制了一种新颖的3D感知面部渲染,用于说话的头部生成。为了学习真实的运动系数,我们明确地分别模拟音频和不同类型的运动系数之间的联系。准确地说,我们提出ExpNet通过提取系数和3d渲染的面部来从音频中学习准确的面部表情。对于头部姿势,我们通过一个有条件的VAE来设计PoseVAE来合成不同风格的头部运动。最后,将生成的三维运动系数映射到所提出的人脸渲染的无监督三维关键点空间,并合成最终的视频。我们进行了大量的实验,以证明我们的方法在运动和视频质量方面的优越性。

图1。该系统通过输入音频和单一参考图像生成多样、逼真、同步的对话视频。
1. 介绍
用语音音频制作静态人像图像是一项具有挑战性的任务,在数字人类创造、视频会议等领域有许多重要的应用。以往的研究主要集中在唇动的生成[2,28,29,48],因为唇动与言语有很强的联系。最近的工作还旨在生成一个包含其他相关动作的逼真的谈话面部视频,例如,头部姿势。他们的方法主要是通过地标[49]和潜在翘曲引入二维运动场[37,38]。但是生成的视频质量仍然不自然,受到偏好pose[16,48]、月模糊[28]、身份修改[37,38]、扭曲脸[37,38,46]的限制。
生成一个自然的说话头视频包含许多挑战,因为音频和不同动作之间的连接是不同的。也就是说,嘴唇运动与音频的联系最强,但音频可以通过不同的头部姿势和眨眼来传达。因此,以往基于面部标记的方法[2,49]和基于2D流的音频到表情网络[37,38]可能会产生扭曲的面部,因为头部运动和表情在其表示中没有完全解离。另一种流行的方法是基于潜能的人脸动画[16,28,48]。他们的方法主要针对说话人脸动画中的特定动作,难以合成高质量的视频。我们观察到,3D面部模型包含高度去耦的表示,可用于单独学习每种类型的运动。虽然在[46]中讨论了类似的观察结果,但他们的方法也会产生不准确的表情和不自然的动作序列。
基于上述观察,我们提出了一种通过隐式三维系数调制的程式化音频驱动的说话头视频生成系统SadTalker。为了实现这一目标,我们将3DMM的运动系数作为中间表示,并将我们的任务分为两个主要部分。一方面,我们的目标是从音频中生成逼真的运动系数(例如,头部姿势,嘴唇运动和眨眼),并单独学习每个运动以减少不确定性。对于表情,我们设计了一个新的音频-表情系数网络,通过提取唇动系数[28]和重构的3d面部[4]上的感知损失(唇读损失[1],面部标志损失)。对于程式化的头部姿态,采用条件VAE[5]算法,通过学习给定姿态的残差来模拟头部运动的多样性和逼真性。在生成逼真的3DMM系数后,我们通过新颖的3d感知面部渲染来驱动源图像。受face-vid2vid[40]的启发,我们学习了显式3DMM系数与无监督3D关键点域之间的映射。然后,通过源和驱动的无监督三维关键点生成弯曲场,对参考图像进行弯曲,生成最终视频。我们分别训练了表情生成、头部姿态生成和面部渲染的每个子网络,我们的系统可以以端到端方式进行推断。在实验中,几个指标显示了我们的方法在视频和运动方法方面的优势。
本文的主要贡献可以总结为:
- 我们提出了SadTalker,这是一个新颖的系统,使用生成的逼真3D运动系数进行程式化的音频驱动单图说话人脸动画。
- 从音频中学习3DMM模型的真实3D运动系数,分别给出ExpNet和PoseVAE。
- 提出了一种新的语义解缠和3d感知的面部渲染,以产生现实的说话头部视频。
- 实验表明,我们的方法在运动同步和视频质量方面达到了最先进的性能。
2. 相关工作
音频驱动的单图像说话脸生成。 早期的工作[28,29]主要是利用感知鉴别器产生准确的唇动。由于真实视频中包含许多不同的动作,ATVGnet[2]使用面部地标作为中间表示来生成视频帧。MakeItTalk[49]提出了一种类似的方法,不同的是,它从输入音频信号中分离出内容和扬声器信息。由于面部标志仍然是一个高度耦合的空间,在解纠缠的空间中生成说话的头部也是最近很流行的。PC-AVS[48]使用隐式潜码解出头部姿势和表情。然而,它只能产生低分辨率的图像,需要来自另一个视频的控制信号。Audio2Head[37]和Wang等[38]从视频驱动的方法[34]中得到灵感,制作了会说话的头脸。然而,这些头部运动仍然不生动,并产生扭曲的面部,无法准确识别。虽然已有文献[31,46]使用3dmm作为中间表示,但其方法仍面临表达式不准确[31]和明显伪影[46]的问题。
音频驱动的视频肖像。 我们的任务还涉及到视觉配音,目的是通过音频编辑人像视频。与音频驱动的单图像语音人脸生成不同,该任务通常需要在特定视频上进行训练和编辑。在深度视频人像[18]的基础上,这些方法利用3DMM信息进行人脸重建和动画。AudioDVP [43], NVP [36], AD-NeRF[10]学习重现表情编辑嘴型。除了嘴唇运动,即头部运动[22,45],情绪性谈话的面部[17]也得到关注。基于3DMM的方法在这些任务中发挥了重要作用,因为它可以从视频剪辑中拟合3DMM参数。虽然这些方法在个性化视频中取得了令人满意的效果,但它们的方法不能应用于任意照片和野外音频。
视频驱动的单图像语音人脸生成。 这个任务也被称为面部再现或面部动画,其目的是将源图像的运动传递给目标人物。近年来已被广泛探讨[13,31,34,35,39,40,42,44,47]。以往的工作也从源图像和目标中学习了一种共享的中间运动表示,大致可以分为基于地标[39]和无监督地标的方法[13,34,40,47],基于3DMM的方法[6,31,44]和潜在动画[24,42]。这个任务比我们的任务简单得多,因为它包含在同一域中的运动。我们的人脸渲染也受到了基于无监督地标的方法[40]和基于3DMM的方法[31]的启发,通过映射学习到的系数来生成真实的视频。然而,它们并不专注于生成真实的运动系数。
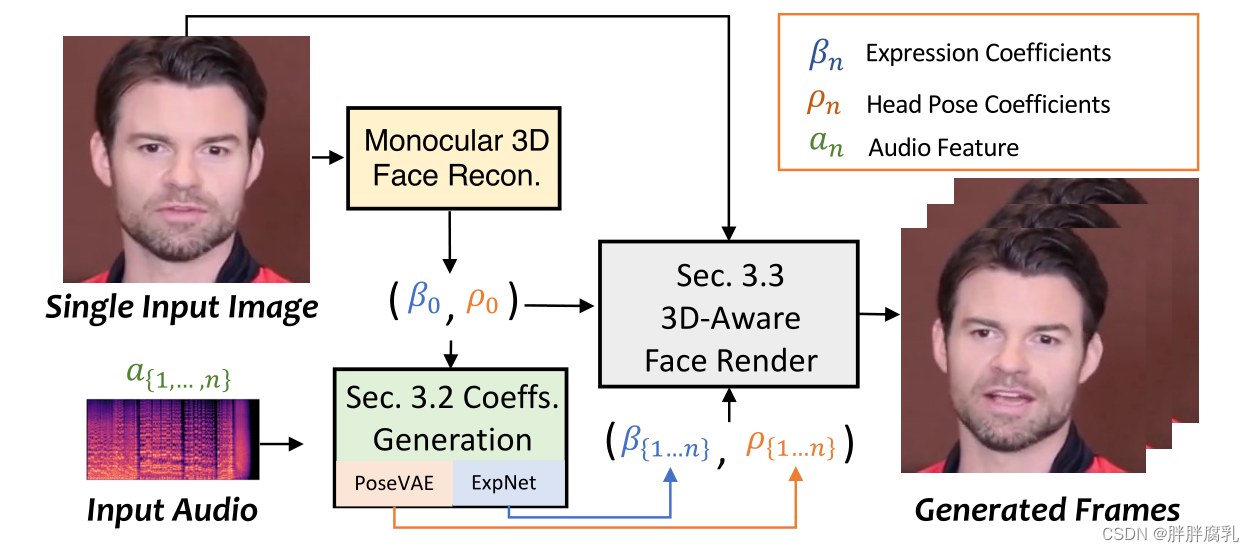
图2。主要管道。我们的方法使用3DMM的系数作为中间运动表示。为此,我们首先从音频中生成逼真的3D运动系数(面部表情β,头部姿势ρ),然后使用这些系数隐式地调节3D感知的面部渲染,以生成最终的视频
3. 方法
如图2所示,我们的系统使用三维运动系数作为说话头生成的中间表示。我们首先从原始图像中提取系数。然后利用ExpNet和PoseV AE分别生成逼真的3DMM运动系数。最后,提出了一种3d感知的面部渲染来生成说话头部视频。下面,我们将在第3.1节中简要介绍3D人脸模型,分别在第3.2节和第3.3节中设计音频驱动的运动系数生成和系数驱动的图像动画器。
3.1 三维人脸模型的初步研究
由于真实视频是在3D环境中捕获的,因此3D信息对于提高生成视频的真实感至关重要。然而,以往的作品[28,48,49]很少考虑3D空间,因为很难从单幅图像中获得准确的3D系数,高质量的面部渲染也很难设计。受最近的单幅图像深度三维重建方法[4]的启发,我们将预测的三维变形模型(3DMMs)的空间作为我们的中间表示。在3DMM中,三维面形S可以解耦为:
S
=
S
‾
+
α
U
i
d
+
β
U
e
x
p
,
\mathbf{S}=\overline{\mathbf{S}}+\alpha \mathbf{U}_{i d}+\beta \mathbf{U}_{e x p},
S=S+αUid+βUexp,
其中
S
‾
\overline{\mathbf{S}}
S 为3D人脸的平均形状,
U
i
d
\mathbf{U}_{i d}
Uid 和
U
exp
\mathbf{U}_{\exp }
Uexp为LSFM变形模型[1]的身份和表达的标准正交基。系数
α
∈
R
80
\alpha \in \mathbb{R}^{80}
α∈R80 和
β
∈
R
64
\beta \in \mathbb{R}^{64}
β∈R64 分别描述了人的身份和表达。为了保持位姿方差,
r
∈
S
O
(
3
)
\mathbf{r} \in S O(3)
r∈SO(3) 和
t
∈
R
3
\mathbf{t} \in \mathbb{R}^3
t∈R3表示头部旋转和平移。为了实现同一性无关系数生成[31],我们只对运动参数建模为
{
β
,
r
,
t
}
\{\beta, \mathbf{r}, \mathbf{t}\}
{β,r,t} 。我们从前面介绍的驾驶音频中分别学习了头部姿势
ρ
=
[
r
,
t
]
\rho=[\mathbf{r}, \mathbf{t}]
ρ=[r,t] 和表达系数
β
\beta
β 。然后,这些运动系数用于隐式调节我们的面部渲染,以实现最终的视频合成。
3.2 通过音频生成运动系数
如上所述,3D运动系数包含头部姿态和表情,其中头部姿态是全局运动,而表情是相对局部的。为此,把所有的东西都学了会在网络中造成巨大的不确定性,因为头部的姿势与音频的关系相对较弱,而嘴唇的运动是高度相关的。我们使用提出的PoseVAE和ExpNet生成头部姿态和表情的运动,分别介绍如下。
ExpNet 学习从音频中产生精确表达式系数的通用模型非常困难,原因有两个:1)音频到表达式不是不同身份的一对一映射任务。2)表达式系数中存在一些与声音无关的运动,这将影响预测的准确性。我们的ExpNet旨在减少这些不确定性。对于身份问题,我们通过第一帧的表达系数β0将表情运动与特定的人联系起来。为了减少自然说话中其他面部成分的运动权重,我们通过Wav2Lip[28]预训练网络和深度三维重建[4],只使用嘴唇运动系数作为系数目标。然后,其他微小的面部动作(例如眨眼)可以通过渲染图像上的额外地标损失来利用。
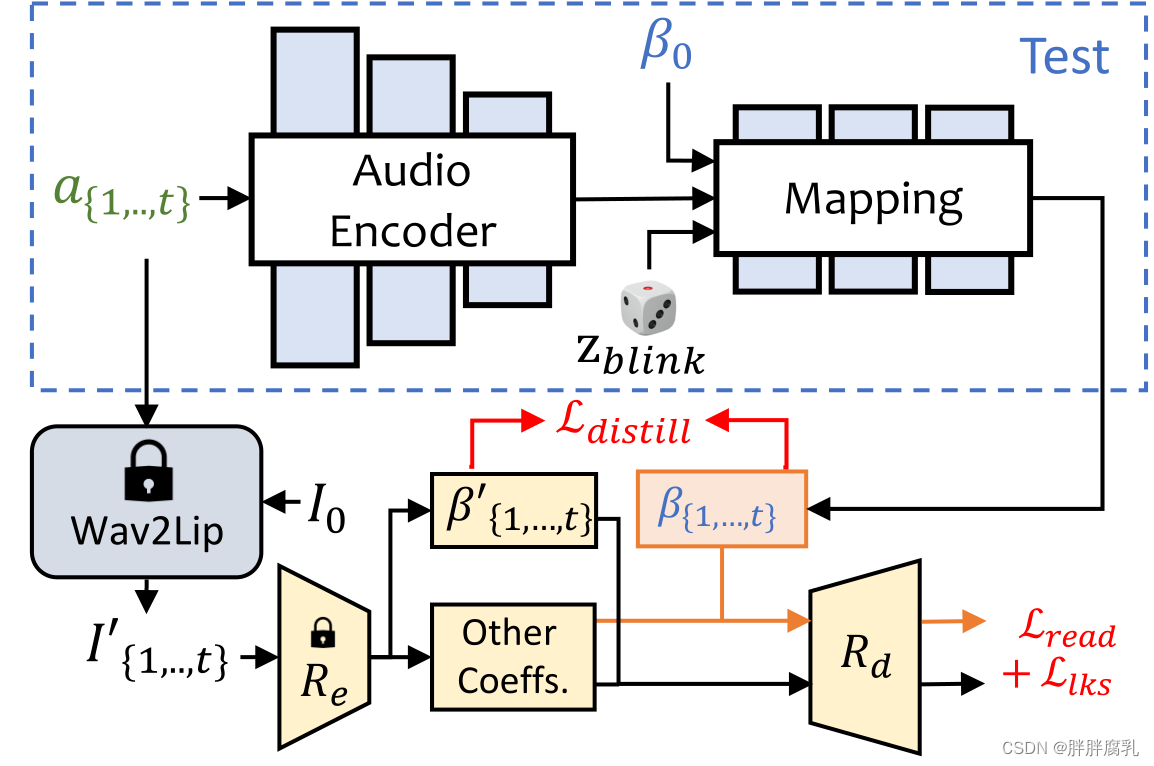
图3。我们的ExpNet结构。我们采用单目三维人脸重建模型[4] (
R
e
R_e
Re 和
R
d
R_d
Rd)来学习真实表情系数。其中
R
e
R_e
Re 是预训练的3DMM系数估计器,
R
d
R_d
Rd 是没有可学习参数的可微分3D人脸渲染。我们使用参考表达式
β
0
\beta_0
β0 来降低身份的不确定性,并使用预训练的Wav2Lip[28]生成的帧和第一帧作为目标表达系数,因为它只包含与嘴唇相关的运动。
如图3所示,我们从音频窗口
a
{
1
,
.
.
,
t
}
a_{\{1, . ., t\}}
a{1,..,t},其中每帧的音频特征是一个0.2s的梅尔谱图。为了训练,我们首先设计了一个基于resnet的音频编码器
Φ
A
[
11
,
28
]
\Phi_A[11,28]
ΦA[11,28] [11,28],将音频特征嵌入到一个潜在空间中。然后加入线性层作为映射网络
Φ
M
\Phi_M
ΦM 对表达式系数进行解码。在这里,我们还从参考图像中添加了参考表达
β
0
\beta_0
β0 ,以降低上述讨论的身份不确定性。由于我们在训练中使用lip-only系数作为ground truth,我们显式地添加一个眨眼控制信号
z
b
bink
∈
[
0
,
1
]
z_{b \text { bink }} \in[0,1]
zb bink ∈[0,1] 和相应的眼标损失来生成可控眨眼。
形式上,网络可以写成:
β
{
1
,
…
,
t
}
=
Φ
M
(
Φ
A
(
a
{
1
,
…
,
t
}
)
,
z
b
l
i
n
k
,
β
0
)
\left.\beta_{\{1, \ldots, t\}}=\Phi_M\left(\Phi_A\left(a_{\{1, \ldots, t}\right\}\right), z_{b l i n k}, \beta_0\right)
β{1,…,t}=ΦM(ΦA(a{1,…,t}),zblink,β0)
对于损失函数,我们首先使用 L distill \mathcal{L}_{\text {distill }} Ldistill 来评估lip - only表达式系数 R e R_e Re (Wav2Lip ( I 0 , a { 1 , … , t } ) \left(I_0, a_{\{1, \ldots, t\}}\right) (I0,a{1,…,t}) )与生成的 β { 1 , … , t } \beta_{\{1, \ldots, t\}} β{1,…,t} 之间的差异。注意,我们只使用wav2lip的第一帧 I 0 I_0 I0 来生成口型同步视频,这减少了除了嘴唇运动之外的姿势变化和其他面部表情的影响。此外,我们还涉及到可微的三维人脸渲染 R d R_d Rd ,以计算额外的感知损失在显式面部运动空间。如图3所示,我们通过计算关键点损失 L l k s \mathcal{L}_{l k s} Llks 来测量眨眼的范围和整体表达精度。预训练的唇读网络 Φ reader \Phi_{\text {reader }} Φreader 也被用作暂时性唇读损失 L read \mathcal{L}_{\text {read }} Lread ,以保持感知唇质量[8,28]。我们在补充资料中提供了更多的培训细节。
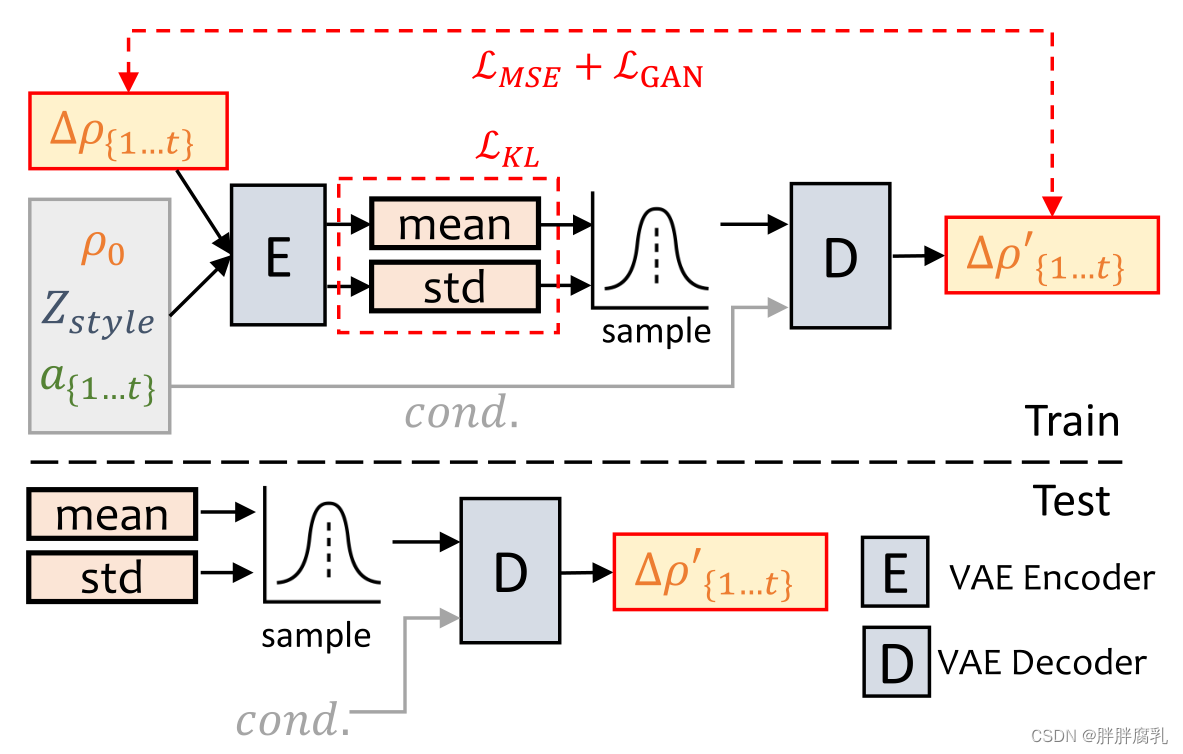
图4。PoseVAE管道。我们通过条件VAE结构学习输入头位
ρ
0
\rho_0
ρ0 的残差。
给定条件:第一帧
ρ
0
\rho_0
ρ0,样式标识
Z
style
Z_{\text {style }}
Zstyle 和音频剪辑
a
{
1
,
…
,
t
}
a_{\{1, \ldots, t\}}
a{1,…,t} 时,我们的方法学习了残差头位姿
Δ
ρ
{
1
,
…
,
t
}
=
ρ
{
1
,
…
,
t
}
−
ρ
0
\Delta \rho_{\{1, \ldots, t\}}=\rho_{\{1, \ldots, t\}}-\rho_0
Δρ{1,…,t}=ρ{1,…,t}−ρ0 。训练之后,我们可以只通过姿态解码器和条件(cond.)生成程式化的结果。
如图4所示,我们设计了一个基于VAE[20]的模型来学习真实说话视频中真实的、身份感知的程式化头部运动 ρ ∈ R 6 \rho \in \mathbb{R}^6 ρ∈R6。在训练中,姿态VAE使用基于编码器的结构在固定n帧上进行训练。编码器和解码器都是两层MLP,其中输入包含一个连续的 t t t 帧头姿态,我们将其嵌入到高斯分布中。在解码器中,学习网络从采样分布中生成t帧姿态。我们的PoseVAE不是直接生成姿态,而是学习第一帧的条件姿态 ρ 0 \rho_0 ρ0 的残差,这使得我们的方法能够在第一帧条件下生成更长的、稳定的、连续的头部运动。另外,根据CVAE[5],我们添加相应的音频特征 a { 1 , … , t } a_{\{1, \ldots, t\}} a{1,…,t} 和风格认同 Z style Z_{\text {style }} Zstyle 作为节奏意识和风格认同的条件。采用kl -散度 L K L \mathcal{L}_{K L} LKL测量所产生运动的分布。采用均方损耗 L M S E \mathcal{L}_{M S E} LMSE 和对抗损耗 L G A N \mathcal{L}_{G A N} LGAN 来保证生成的质量。我们在补充材料中提供了更详细的损失函数。
3.3 3d感知面部渲染
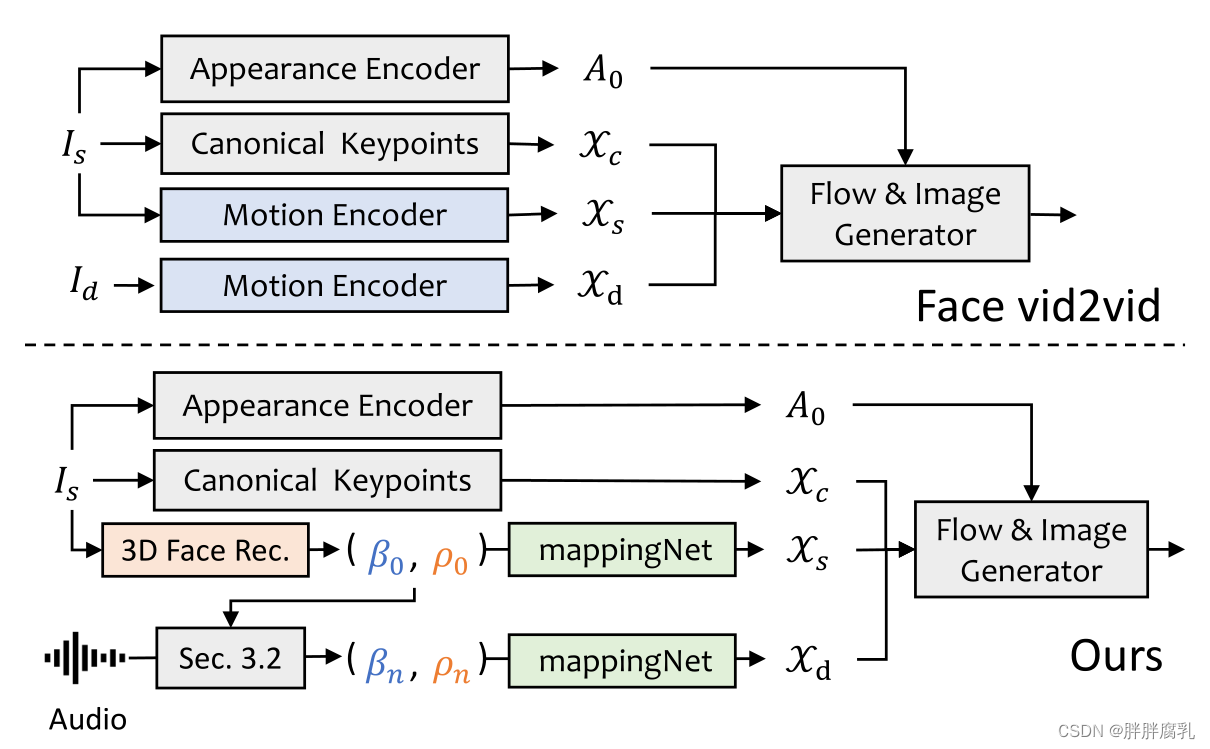
图5。提出的FaceRender及与facevid2vid[40]的比较。给定源图像
I
s
I_s
Is和驱动图像
I
d
I_d
Id, facevid2vid在无监督的三维关键点空间
X
c
X_c
Xc、
X
s
X_s
Xs和
X
d
X_d
Xd 中生成运动。然后通过外观
A
0
A_0
A0 和关键点生成图像。由于我们没有驾驶图像,我们使用显式解纠缠的3DMM系数作为代理,并将其映射到无监督的3D关键点空间。
在生成逼真的3D运动系数后,我们通过一个设计良好的3D感知图像动画器渲染最终的视频。我们从最近的图像动画方法face-vid2vid[40]中得到灵感,因为它隐式地从单张图像中学习3D信息。然而,在他们的方法中,需要一个真实的视频作为运动驱动信号。我们的面部渲染使它可以通过3DMM系数驾驶。如图5所示,我们提出mappingNet来学习显式3DMM运动系数(头姿和表情)与隐式无监督3D关键点之间的关系。我们的mappingNet是通过几个一维卷积层构建的。我们使用时间窗口的时间系数作为PIRenderer[31]进行平滑。不同的是,我们发现PIRenderer中的人脸对齐运动系数将极大地影响音频驱动视频生成的运动自然度,并提供了第4.4节中的实验。我们只使用表达式和头的系数姿势。对于训练,我们的方法包含两个步骤。首先,我们像原论文一样,以自监督的方式训练face-vid2vid[40]。在第二步中,我们冻结外观编码器、标准关键点估计器和图像生成器的所有参数以进行调优。然后,以重建的方式对地面实况视频的3DMM系数进行训练。我们利用 L 1 L_1 L1 损耗对无监督关键点进行监督,并在原始实现的基础上生成最终的视频。更多细节可以在补充资料中找到。
4 实验
4.1 实现细节和度量
数据集。我们使用V oxCeleb[25]数据集进行训练,其中包含1251个受试者的超过100k个视频。我们按照前面的图像动画方法[34]裁剪原始视频,并将视频大小调整为256×256。预处理后,数据用于训练我们的FaceRender。由于一些视频和音频在V oxCeleb中没有对齐,我们选择了46个科目的1890个对齐的视频和音频来训练我们的PoseV AE和ExpNet。输入音频被降采样到16kHz,并转换为与Wav2lip[28]设置相同的mel-频谱图。为了测试我们的方法,我们使用了来自HDTF数据集[46]的346个视频的前8秒视频(总共约70k帧),因为它包含高分辨率和野外说话的头部视频。这些视频也按照[34]进行裁剪和处理,并将大小调整为256 ×256以供评估。我们使用每个视频的第一帧作为参考图像来生成视频
实现细节。 ExpNet, PoseV AE和FaceRender都是单独训练的,我们使用Adam优化器[19]进行所有实验。经过训练后,我们的方法可以在没有任何人工干预的情况下以端到端方式进行推断。通过预训练的深度三维人脸重建方法[4]提取所有的3DMM参数。所有实验均在8个A100图形处理器上进行。ExpNet、PoseV AE和FaceRender的学习速率分别为2e−5、1e−4和2e−4。从时间上考虑,ExpNet使用连续5帧进行学习。PoseVAE是通过连续32帧学习的。FaceRender中的帧是逐帧生成的,为了稳定,系数为5连续帧。
评价指标。我们证明了我们的方法在多个指标上的优越性,这些指标在以前的研究中被广泛使用。我们采用Frechet Inception Distance (FID)[12,33]和累积概率模糊检测(CPBD)[26]来评估图像质量,其中FID用于评估生成帧的真实感,CPBD用于评估生成帧的锐度。为了评估身份保留,我们计算源图像与生成帧之间的身份嵌入的余弦相似度(CSIM),其中我们使用ArcFace[3]来提取图像的身份嵌入。为了评估嘴唇同步和嘴型,我们从Wav2Lip[28]中评估了嘴型的感知差异,包括距离评分(LSE-D)和置信度评分(LSE-C)。我们还进行了一些度量来评估生成帧的头部运动。对于生成的头部运动的多样性,使用Hopenet[27]计算从生成的帧中提取的头部运动特征嵌入的标准差。对于音频和生成的头部运动的对齐,我们计算节拍对齐分数,如Bailando [21]。
4.2 与其他最先进的方法进行比较

图6。我们将我们的方法与几种最先进的方法进行比较,用于生成单个图像音频驱动的说话头。我们的方法在嘴唇同步、身份保留、头部运动和图像质量方面产生了更高质量的结果。我们给出了上面的目标图像作为唇形和身份的参考。请参考我们补充的视频以便更好的比较。
我们比较了几种最先进的语音头视频生成(MakeItTalk [49], Audio2Head[37]和Wang等[38]1)和音频到表情生成(Wav2Lip [28], PC-AVS[48])的方法。评估直接在他们的公共检查点上执行。如表1所示,所提出的方法显示出更好的整体视频质量和头部姿态多样性,并且在嘴唇同步指标方面也显示出与其他完全说话头部生成方法相当的性能。我们认为,这些嘴唇同步指标对音频过于敏感,不自然的嘴唇运动可能会得到更好的分数。但是,我们的方法获得了与真实视频相似的分数,这说明了我们的优势。我们还在图6中说明了不同方法的可视化结果。在这里,我们给出了嘴唇参考,以可视化我们的方法的嘴唇同步。从图中可以看出,我们的方法具有与原始目标视频非常相似的视觉质量,并且与我们预期的头部姿势不同。与其他方法相比,Wav2Lip[28]产生了模糊的半面。“PC-AVS[48]”和“Audio2Head[37]”正在为身份保护而挣扎。Audio2Head只能生成前面的说话脸。此外,MakeItTalk[49]和Audio2Head[37]由于二维扭曲而产生失真的人脸视频。我们在后文中给出了视频对比,以显示更清晰的对比。
4.3 用户研究
我们进行用户研究来评估所有方法的性能。我们总共生成20个视频作为我们的测试。
这些样本包含几乎相同的性别,不同的年龄,姿势和表情,以显示我们的方法的鲁棒性。我们反转了20名参与者,让他们在视频清晰度、嘴唇同步、头部运动的多样性和自然性以及整体质量方面选择最佳方法。结果如表2所示,其中参与者喜欢我们的方法主要是因为视频和运动质量。我们还发现38%的参与者认为我们的方法比其他方法表现出更好的嘴唇同步,这与表1不一致。我们认为这可能是因为大多数参与者关注的是视频的整体质量,模糊和静止的视频影响了他们的观点[28,48]。
4.4 消融实验

图7。我们将我们的方法与基线方法进行比较,基线方法在没有任何条件的情况下从单个网络(从Speech2Gesture[9])学习所有系数。我们的方法显示了清晰的头部运动、身份保护和多样化的表情。
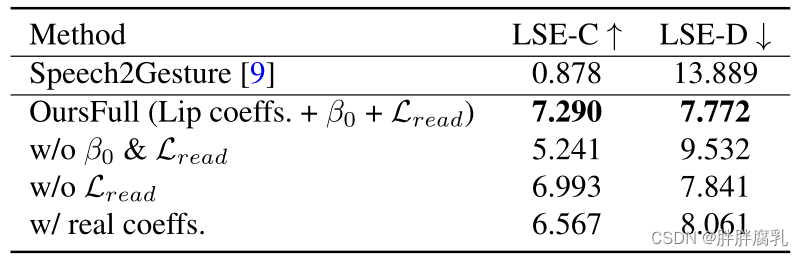
表3。消融治疗ExpNet。初始表达
β
0
\beta_0
β0、唇读损失
L
r
e
a
d
L_{read}
Lread 均显著提高性能。然而,当使用真实系数时,唇同步度量下降了很多。

图8。消融ExpNet。我们从生成的视频中选择四帧作为比较。我们的方法在很大程度上降低了音频到表情生成的不确定性。参考
β
0
\beta_0
β0 被用来提供识别信息,而只有唇系数产生更好的唇同步。注意,目标图像是作为身份和唇动参考提供的。
ExpNet消融实验。对于ExpNet,我们主要通过唇同步度量来评估每个组件的必要性。由于之前没有解卷积的方法,我们考虑一个基线(Speech2Gesture[9],这是一个音频到关键点生成网络)来联合学习头部姿态和表情系数。如表3和图7所示,将所有运动系数一起学习很难生成真实的说话头视频。然后我们考虑了所提出的ExpNet的变体,初始表达 β 0 \beta_0 β0 ,唇读损失 L r e a d L_{read} Lread 和lip - only系数的必要性都是至关重要的。视觉对比如图8所示,其中我们的方法没有初始表达 β 0 \beta_0 β0,正如预期的那样显示了巨大的身份变化。此外,如果我们使用真实系数来取代我们使用的纯唇系数,在唇同步时性能会下降很多。
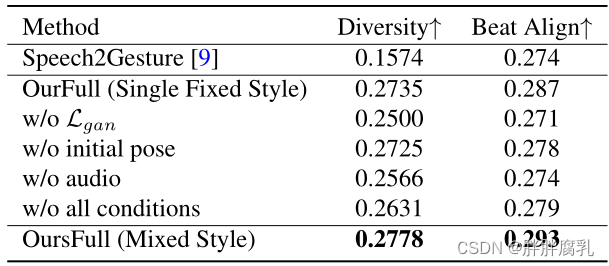
表4。消融实验PoseVAE的多样性和音频对齐。每个组件或条件都在很大程度上有助于生成真实的头部运动。
PoseVAE消融实验。我们根据运动多样性和音频节拍对齐来评估提出的PoseVAE。如表4所示,基线的Speech2Gesture[9]在姿态评估中表现也较差。至于我们的变体,由于我们的方法包含几个身份风格标签,为了更好地评估其他组件,我们首先考虑对我们的完整方法进行评估(OurFull, Single fixed style)的固定单热风格进行烧蚀研究。我们设置中的每个条件都有利于在多样性和节拍对齐方面的整体运动质量。我们进一步报告了我们的完整方法的混合风格的结果,该方法使用随机选择的身份标签作为风格,也显示出更好的多样性性能。由于姿态差异在图中难以显示,请参考我们的补充资料进行更好的对比。

图9。面部渲染的消融研究。在第一行中,我们直接将我们的方法与PIRenderer[31]进行面部动画比较,我们的方法显示了更好的表情建模。第二行是由相同运动系数生成的面部标志的轨迹图。使用额外的面部对准系数作为运动系数[31]的一部分将产生不现实的对准头部视频。
面部渲染消融消融实验。我们从两个方面对所提出的面部渲染进行消融研究。一方面,我们用PIRenderer[31]显示方法的重建质量,因为这两种方法都使用3DMM作为中间表示。如图9的第一行所示,由于稀疏无监督关键点的映射,所提出的人脸渲染具有更好的表情重构质量。其中精确的表达式映射也是实现唇同步的关键。此外,我们还评估了PIRenderer[31]中使用的附加对齐系数引起的姿态不自然性。如图9的第二行所示,我们绘制了生成视频中具有相同头部姿态和表情系数的地标的轨迹图。使用固定的或可学习的作物系数(作为我们poseVAE中的姿态系数的一部分)将生成面部对齐的视频,这作为自然视频来说很奇怪。我们将其去掉,直接使用头部姿态和表情作为调制参数,得到了更加真实的结果。

图10。局限性。在一些例子中,我们的方法可能会在嘴唇区域显示一些牙齿伪影,可以通过面部修复网络,即GFPGAN[41]进行改进。
4.5 局限性
虽然我们的方法从单个图像和音频生成真实的视频,但我们的系统仍然存在一些局限性。由于3dmm不能模拟眼睛和牙齿的变化,在某些情况下,我们的面部渲染中的mappingNet也将难以合成真实的牙齿。这种限制可以通过如图10所示的盲脸恢复网络[41]来改善。我们工作的另一个局限性是我们只关注嘴唇运动和眨眼,而不关注其他面部表情,如情绪和注视方向。因此,生成的视频具有固定的情感,这也降低了生成内容的真实感。我们认为这是未来的工作。
5. 总结
在本文中,我们提出了一种新的程式化音频驱动的说话头视频生成系统。我们使用3DMM的运动系数作为中间表示,并学习它们之间的关系。为了从音频中生成逼真的3D系数,我们提出了ExpNet和PoseVAE来实现逼真的表情和不同的头部姿势。为了模拟3DMM运动系数与真实视频之间的关系,我们受到图像动画方法[40]的启发,提出了一种新颖的3d感知人脸渲染方法。实验证明了该框架的优越性。由于我们预测了逼真的三维人脸系数,我们的方法也可以直接用于其他模式,即个性化的2D视觉配音[43],2D卡通动画[49],3D人脸动画[7]和基于nerf的4D说话头生成[14]。
道德考虑。我们考虑了所提出的方法的误用,因为它可以从单个人脸图像生成非常逼真的视频。生成的视频中同时插入可见和不可见视频水印,用于生成内容识别,类似于Dall-E[30]和Imagen[32]。我们也希望我们的方法能在伪证鉴定领域提供新的研究样本。
参考
[1] Volker Blanz and Thomas V etter. A morphable model for the synthesis of 3d faces. In ACM SIGGRAPH, 1999. 2, 3
[2] Lele Chen, Ross K Maddox, Zhiyao Duan, and Chenliang Xu. Hierarchical cross-modal talking face generation with dynamic pixel-wise loss. In CVPR, 2019. 2
[3] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou.Arcface: Additive angular margin loss for deep face recognition. In CVPR, 2019. 5
[4] Y u Deng, Jiaolong Yang, Sicheng Xu, Dong Chen, Y unde Jia, and Xin Tong. Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set.In CVPR Workshops, 2019. 2, 3, 4, 5, 12, 13, 14
[5] Carl Doersch. Tutorial on variational autoencoders. arXiv preprint arXiv:1606.05908, 2016. 2, 4
[6] Michail Christos Doukas, Stefanos Zafeiriou, and Viktoriia Sharmanska. Headgan: One-shot neural head synthesis and editing. In ICCV, 2021. 3
[7] Yingruo Fan, Zhaojiang Lin, Jun Saito, Wenping Wang, and Taku Komura. Faceformer: Speech-driven 3d facial animation with transformers. In CVPR, 2022. 8
[8] Panagiotis P . Filntisis, George Retsinas, Foivos ParaperasPapantoniou, Athanasios Katsamanis, Anastasios Roussos, and Petros Maragos. Visual speech-aware perceptual 3d facial expression reconstruction from videos. arXiv preprint arXiv:2207.11094, 2022. 4, 13
[9] Shiry Ginosar, Amir Bar, Gefen Kohavi, Caroline Chan, Andrew Owens, and Jitendra Malik. Learning individual styles of conversational gesture. In CVPR, 2019. 7, 8, 14
[10] Y udong Guo, Keyu Chen, Sen Liang, Y ong-Jin Liu, Hujun Bao, and Juyong Zhang. Ad-nerf: Audio driven neural radiance fields for talking head synthesis. In ICCV, 2021. 2
[11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. In CVPR, 2016.4
[12] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.In NeurIPS, 2017. 5
[13] Fa-Ting Hong, Longhao Zhang, Li Shen, and Dan Xu. Depthaware generative adversarial network for talking head video generation. In CVPR, 2022. 3
[14] Yang Hong, Bo Peng, Haiyao Xiao, Ligang Liu, and Juyong Zhang. Headnerf: A real-time nerf-based parametric head model. In CVPR, 2022. 8
[15] Phillip Isola, Jun-Y an Zhu, Tinghui Zhou, and Alexei A Efros.Image-to-image translation with conditional adversarial networks. CVPR, 2017. 14
[16] Xinya Ji, Hang Zhou, Kaisiyuan Wang, Qianyi Wu, Wayne Wu, Feng Xu, and Xun Cao. Eamm: One-shot emotional talking face via audio-based emotion-aware motion model. In ACM SIGGRAPH, 2022. 2 [17] Xinya Ji, Hang Zhou, Kaisiyuan Wang, Wayne Wu, Chen Change Loy, Xun Cao, and Feng Xu. Audio-driven emotional video portraits. In CVPR, 2021. 3 [18] Hyeongwoo Kim, Pablo Garrido, Ayush Tewari, Weipeng Xu, Justus Thies, Matthias Niessner, Patrick P´erez, Christian Richardt, Michael Zollh¨ofer, and Christian Theobalt. Deep video portraits. ACM Transactions on Graphics (TOG), 2018.2
[19] Diederik P Kingma and Jimmy Ba. A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. 5
[20] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. CoRR, abs/1312.6114, 2014. 4
[21] Siyao Li, Y u Weijiang, Gu Tianpei, Lin Chunze, Wang Quan, Qian Chen, Loy Chen Change, and Liu Ziwei. Bailando: 3d dance generation via actor-critic gpt with choreographic memory. In CVPR, 2022. 5
[22] Y uanxun Lu, Jinxiang Chai, and Xun Cao. Live speech portraits: real-time photorealistic talking-head animation. ACM Transactions on Graphics (TOG), 2021. 3
[23] Pingchuan Ma, Y ujiang Wang, Stavros Petridis, Jie Shen, and Maja Pantic. Training strategies for improved lip-reading. In ICASSP, 2022. 13 [24] Arun Mallya, Ting-Chun Wang, and Ming-Y u Liu. Implicit Warping for Animation with Image Sets. In NeurIPS, 2022. 3
[25] Arsha Nagrani, Joon Son Chung, and Andrew Zisserman.V oxceleb: a large-scale speaker identification dataset. In INTERSPEECH, 2017. 5, 11, 12
[26] Niranjan D. Narvekar and Lina J. Karam. A no-reference image blur metric based on the cumulative probability of blur detection (cpbd). TIP, 2011. 5
[27] Ruiz Nataniel, Eunji Chong, and Rehg James M. Fine-grained head pose estimation without keypoints. In CVPR Workshops, 2018. 5
[28] K R Prajwal, Rudrabha Mukhopadhyay, Vinay P .Namboodiri, and C.V .Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. In ACM MM, 2020. 2, 3, 4, 5, 6, 7, 11, 12
[29] Prajwal K R, Rudrabha Mukhopadhyay, Jerin Philip, Abhishek Jha, Vinay Namboodiri, and C V Jawahar. Towards automatic face-to-face translation. In ACM MM, 2019. 2
[30] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.9
[31] Y urui Ren, Ge Li, Y uanqi Chen, Thomas H Li, and Shan Liu. Pirenderer: Controllable portrait image generation via semantic neural rendering. In ICCV, 2021. 2, 3, 5, 8, 11, 14
[32] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S Sara Mahdavi, Rapha Gontijo Lopes, et al Photorealistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487, 2022. 9
[33] Maximilian Seitzer. pytorch-fid: FID Score for PyTorch.
https://github.com/mseitzer/pytorch- fid, August 2020. V ersion 0.2.1. 5
[34] Aliaksandr Siarohin, St´ephane Lathuili`ere, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. First order motion model for image animation. In NeurIPS, 2019. 2, 3, 5, 11
[35] Aliaksandr Siarohin, Oliver Woodford, Jian Ren, Menglei Chai, and Sergey Tulyakov. Motion representations for articulated animation. In CVPR, 2021. 3
[36] Justus Thies, Mohamed Elgharib, Ayush Tewari, Christian Theobalt, and Matthias Nießner. Neural voice puppetry: Audio-driven facial reenactment. In ECCV, 2020. 2
[37] Suzhen Wang, Lincheng Li, Y u Ding, Changjie Fan, and Xin Y u. Audio2head: Audio-driven one-shot talking-head generation with natural head motion. In IJCAI, 2021. 2, 5, 6, 7, 12
[38] Suzhen Wang, Lincheng Li, Y u Ding, and Xin Y u. Oneshot talking face generation from single-speaker audio-visual correlation learning. In AAAI, 2022. 2, 5, 6, 7, 12
[39] Ting-Chun Wang, Ming-Y u Liu, Andrew Tao, Guilin Liu, Jan Kautz, and Bryan Catanzaro. Few-shot video-to-video synthesis. In NeurIPS, 2019. 3
[40] Ting-Chun Wang, Arun Mallya, and Ming-Y u Liu. One-shot free-view neural talking-head synthesis for video conferencing. In CVPR, 2021. 2, 3, 4, 5, 8, 11, 14
[41] Xintao Wang, Y u Li, Honglun Zhang, and Ying Shan. Towards real-world blind face restoration with generative facial prior. In CVPR, 2021. 8 [42] Yaohui Wang, Di Yang, Francois Bremond, and Antitza Dantcheva. Latent image animator: Learning to animate images via latent space navigation. arXiv preprint arXiv:2203.09043, 2022. 3
[43] Xin Wen, Miao Wang, Christian Richardt, Ze-Yin Chen, and Shi-Min Hu. Photorealistic audio-driven video portraits.IEEE Transactions on Visualization and Computer Graphics, 26(12):3457–3466, 2020. 2, 8
[44] Fei Yin, Y ong Zhang, Xiaodong Cun, Mingdeng Cao, Y anbo Fan, Xuan Wang, Qingyan Bai, Baoyuan Wu, Jue Wang, and Y ujiu Yang. Styleheat: One-shot high-resolution editable talking face generation via pre-trained stylegan. In ECCV, 2022. 3
[45] Chenxu Zhang, Yifan Zhao, Yifei Huang, Ming Zeng, Saifeng Ni, Madhukar Budagavi, and Xiaohu Guo. Facial: Synthesizing dynamic talking face with implicit attribute learning. In ICCV, 2021. 3
[46] Zhimeng Zhang, Lincheng Li, Y u Ding, and Changjie Fan.Flow-guided one-shot talking face generation with a highresolution audio-visual dataset. In CVPR, 2021. 2, 5, 11, 12
[47] Jian Zhao and Hui Zhang. Thin-plate spline motion model for image animation. In CVPR, 2022. 3
[48] Hang Zhou, Yasheng Sun, Wayne Wu, Chen Change Loy, Xiaogang Wang, and Ziwei Liu. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In CVPR, 2021. 2, 3, 5, 6, 7, 12 [49] Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis, and Dingzeyu Li. Makelttalk:speaker-aware talking-head animation. ACM Transactions on Graphics (TOG), 2020. 2, 3, 5, 6, 7, 8, 12

