- 1基于uniapp运动健身打卡目标计划系统 微信小程序xnxwb
- 2编程及C/C++初学者 FAQ 四、教材、习题和示例_钱能c++与how toprogram是一本书吗
- 3Python菜鸟起飞day11_ 线程、进程、协程(二、多进程)___mp_main__
- 4关闭NetworkManager服务_为什么要关闭networkmanager
- 5DataX导数据从mysql到hive回顾_datax mysql同步到hive模板
- 6HTTP api & RPC & REST & RESTful & GraphQL_全知科技 graphql soap restful xml json-rpc
- 7react-native修改android包名_rn 获取 android 包名称
- 8Kali linux安装wine兼容层在kali上使用windows版微信_kali安装微信
- 9微信小程序中表单的验证_wechat-validate
- 10ONLYOFFICE中利用chatGPT帮助我们策划一场生日派对_使用chatgpt活动策划
【数字人】10、HyperLips | 使用 audio 实现对视频的高保真高清晰的唇部驱动_ip_lap 训练
赞
踩

论文:HyperLips: Hyper Control Lips with High Resolution Decoder for Talking Face Generation
代码:https://github.com/semchan/HyperLips
时间:2023.10
效果:需要 audio-driven + 待需要驱动人物的视频来实现唇部的驱动,测试给定样例后发现嘴部抖动严重,测试其他自有样例发现,脸部颜色偏红,嘴唇不清晰,牙齿不清晰
一、背景
talking head 可以用于很多场景,如数字助手、虚拟人、动画人物等待
talking head 一般可以进行如下分类:
- 只使用 audio-driven,也就是输入一段音频和一张图片,使用输入的音频来驱动这个图片来得到很多帧对应的图片来组成最终的视频。这种方式一般是 person-specific 的,如果需要对新的没见过的 person 来生成视频,需要重新训练,而且使用单帧图像驱动的效果不是很自然,容易产生形变。
- 同时使用 audio-driven 和 source video,也就是有一段该 person 的视频和驱动的音频,使用音频驱动模特的嘴部附近运动,这样得到的视频保真性更高。
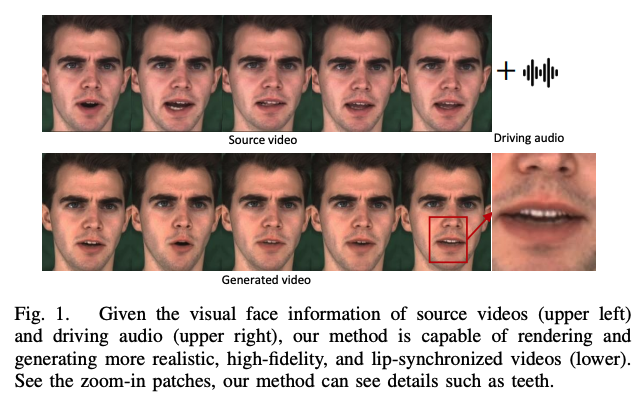
如图 1 所示,本文的的方法就是同时需要 audio-driven 和 source video 的方法,表情和动作都来自于 source video,比较自然。
所以作者在这里就提出了这种方法面临的两个问题:
- 如何生成更准确的唇形
- 如何渲染出更保真的面部,尤其是更清晰的牙齿和唇部
在之前:
- wav2lip:提出了唇形合成判别器来提升唇部的准确性
- SyncTalkFace:提出了 audio lip memory,也就是使用嘴部区域的视觉特征和对应的 audio 来强化 audio-visual 的关系
- IP_LAP:使用 transformer-base 关键点生成,来推理 lip 和 关键点的关系
这些方法主要是聚焦于在 decoding 之前对 audio 和 visual 进行融合,但是 audio 和 visual 的维度不同,所以需要将这两个特征变成相同的尺寸再进行特征融合
本文的方法:两阶段
-
第一阶段:使用了一个基于 audio information 的 hypernetwork 来控制嘴唇的合成形状
将视觉的 face 信息编码到隐空间,然后使用 HyperConv convolution 对隐空间特征进行特征修正,将修正后的特征 decode 得到 visual face content。HyperConv的权重参数是通过使用音频特征作为输入来构建一个超网络来生成的,从而实现在渲染的视觉内容中对嘴唇运动的音频控制。使用超网络是为了避免在视觉和音频特征融合过程中的额外操作,并更好地确保生成视频中的嘴唇同步。本文想法与音频条件扩散模型[24]类似,它将音频信息作为条件变量,但这种方法采用扩散模型作为网络架构,这增加了对计算资源的需求。
-
第二阶段:提出了一个高分辨率解码器(HRDecoder)来进一步优化生成面部的保真度。利用第一阶段生成的面部数据和相应的面部草图训练网络,在草图的指导下,实现面部增强。
为了渲染出更高保真度的面部,DINet[22] 提出了一种形变填充网络来实现高分辨率视频上的面部视觉配音,但如果嘴部区域覆盖了背景,它可能会产生面部以外的人工痕迹。IP_LAP[21]利用从下半部遮挡的目标面部和静态参考图像中提取的先验外观信息,但如果在参考图像中无法检测到 landmark,它可能会失败。另一种可能的方法是基于如 Wav2lip[8] 或 SyncTalkFace[20] 等网络增加输入分辨率,但这不仅增加了训练资源的需求,而且渲染效果不佳,导致持续的人工痕迹。所以本文使用的是 HRDecoder 来提升面部保真度
二、相关工作
2.1 Audio-Driven Talking Face Generation
在只使用音频输入的音频驱动的说话面部生成方法中[12]–[16],通常需要收集特定于人物的音频和视频并进行重新训练。通过引入神经辐射场(NeRF)[25]来表示说话头部的场景[13],可以控制它以在新视角下渲染面部。RAD-NeRF [12]将本质上高维的说话肖像表示分解为三个低维特征网格,使得可以实时渲染说话肖像。GeneFace [14]提出了一个变分运动生成器,以生成准确和富有表现力的面部标志,并使用基于NeRF的渲染器来渲染高保真帧。由于缺乏先验信息,这些任务仍然难以渲染出逼真的表情和自然的动作。
为了驱动单个面部图像,ATVGnet [17]设计了一种级联 GAN 方法来生成说话面部视频,该视频对不同的面部形状、视角、面部特征和嘈杂的音频条件具有鲁棒性。
最近,SadTalker [18]提出了一个新颖的系统,用于使用生成的逼真的3D运动系数,进行风格化的音频驱动单图像说话面部动画,改善了运动同步和视频质量,但仍然无法生成准确的表情和自然的运动序列。
使用源视频驱动音频的方法是最具竞争力的,因为它可以提供足够逼真的面部表情和自然运动信息。Wav2lip [8]、SyncTalkFace [20]、IP LAP [21]、DINET [22]都属于这一类别,主要关注如何生成更好的唇部同步和更高保真度的面部。
2.2 HyperNetwork
Hypernetwork 最初提出是为了生成一个更大网络的权重。在进化计算中,直接操作由数百万个权重参数组成的大型搜索空间是困难的。一种更有效的方法是进化一个较小的网络来生成一个更大网络的权重结构,以便搜索被限制在更小的权重空间内。
权重生成的概念易于用于可控生成任务。Chiang等人[27]利用它来控制3D场景表示的风格。UPST-NeRF[28]使用hypernetwork来控制3D场景的通用真实风格转换。
随着大型语言模型(LLMs)[29]–[32]和生成模型[33]的兴起,hypernetwork 也成为了微调 LLMs的 必要技能之一。本质上,hypernetwork 中生成权重参数以控制大型网络方法的想法与Audio Conditioned Diffusion Model[24]和Latent Diffusion Models中的Conditioning Mechanisms[33]相似,这两者都通过控制变量实现了解码的可控输出。然而,在本文的方法中,执行可控生成相对简单,而不是使用扩散模型进行生成。
2.3 Prior Based Face Restoration
面部修复是指从降质的面部图像中恢复高质量面部图像的过程。
面部修复分为无先验和基于先验的方法。
FSRNet使用一个粗糙的超分辨率(SR)网络来恢复粗糙图像,然后分别通过精细的SR编码器和先验面部传递图估计网络进行处理。最后,将图像特征和先验信息输入到精细的SR解码器中以获得结果。
在文献[37]中,它使用语义标签作为面部先验。语义标签是通过面部解析网络从输入图像或粗糙去模糊图像中提取的。最终的清晰图像是通过输入模糊图像和面部语义标签的拼接来由去模糊网络生成的。
Yin等人提出了一个联合对齐和面部超分辨率网络,以共同学习地标定位和面部修复。
在本文的工作中,作者使用从第一阶段生成的相对低质量面部检测到的地标草图作为输入,以指导 HRDecoder 实现面部增强,以渲染高保真度面部。
三、方法
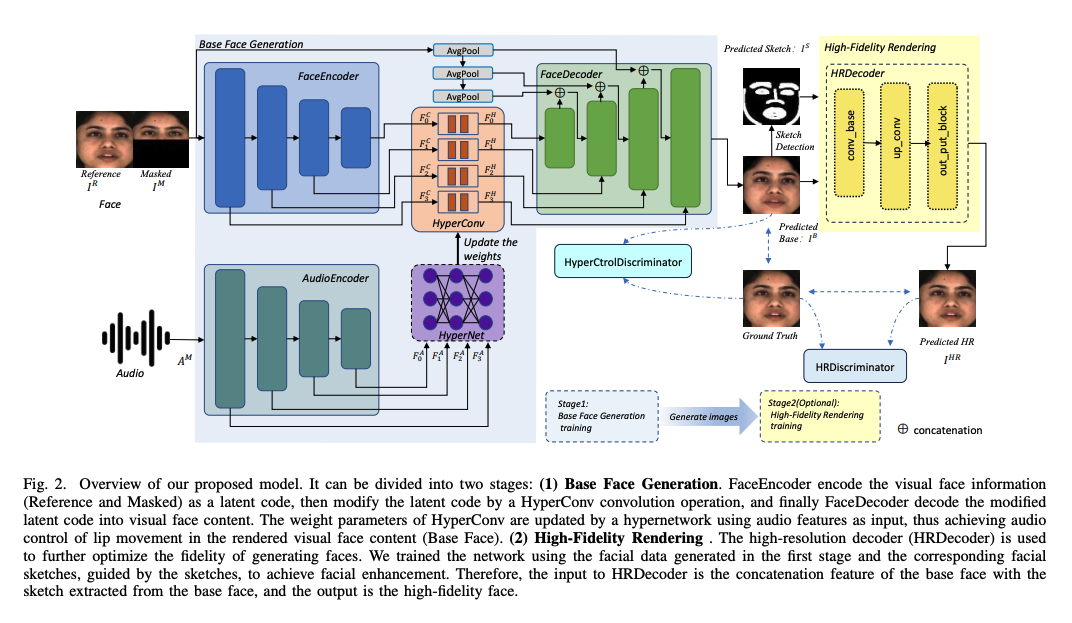
本文方法的框架结构如图 2 所示,给定一个 audio 和一段视频:
- 第一阶段:使用基于 audio feature 的 hypernetwork 来控制视觉上自然的视觉特征
- 第二阶段:使用第一阶段得到的 faec data 和对应的面部 sketches 来提升质量
3.1 Base Face Generation
1、Hyper Control Lips:
-
首先,给定 reference image I R I^R IR 和 masked image I M I^M IM(对 reference 遮挡下半部分),FaceEncoder 通过将 I R I^R IR 和 I M I^M IM concat 起来,得到 latent code 如下:
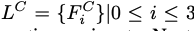
-
然后,使用 HyperConv’s convolution 来对 L C L^C LC 进行处理,得到:

过程为如下,其中 Θ \Theta Θ 是 HyperConv 的权重参数,是由 HyperNet 预测得到的。HyperNet 由 MLP 组成
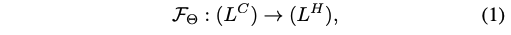
audio feature A M A^M AM 如下,是使用 AudioEncoder 得到的。声音特征的 mel 频谱的尺寸是 16*80,
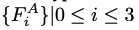
-
最后,使用 FaceDecoer 来对 L H L_H LH 进行解码,得到预测的 base face:

2、Loss Function for Base Face Generation
为了同时保证唇形同步性和保真性,作者使用多个 loss 来优化
① 优化 quality discriminator: HyperCtrolDiscriminator ( D B D^B DB),也就是质量判别器,所以整个生成过程用公式表达如下, ⊕ \oplus ⊕ 表示 concat:
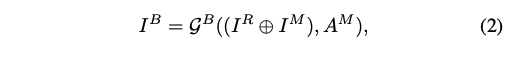
- g B g^B gB:base face generation,包括: FaceEncoder, HyperConv, FaceDecoder, AudioEncoder 和 HyperNet
- 公式 2 就表示,base face generation 的输入是 reference image I R I^R IR 和 masked image I M I^M IM 的 concat,以及声音特征 A M A^M AM
- 经过生成器后,就得到了 predicated base face I B I^B IB
优化 quality discriminator 的 loss 如下:
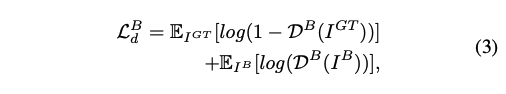
-
Base Adversarial Loss:对抗 loss,来让生成的图片更真实
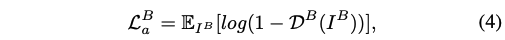
-
Base Reconstruction Loss:使用 L1 loss 来衡量生成的 face 和 gt 的距离,让重建的 face 更接近 gt
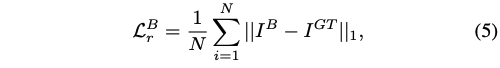
-
Base LPIPS Loss:使用可以学习的 LPIPS loss 来让生成的图片更加接近人眼视觉感受的真实性和自然性
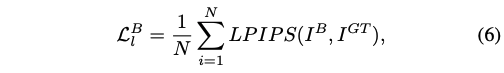
-
Base Audio-Visual Sync Loss:作者使用 LRS2 训练了一个 audio-visual 同步的模型, F A F^A FA 和 F V F^V FV,用这两个模型提取到的特征分别是 f a f_a fa 和 f v f_v fv,这两个模型输出的特征使用 cos 相似度来衡量如公式 7,loss 如公式 8
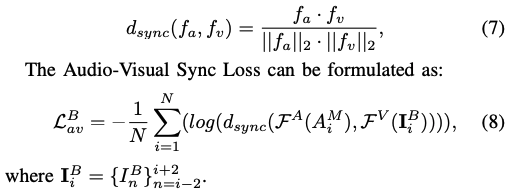
-
最终 base face generation stage 的训练 loss 如下
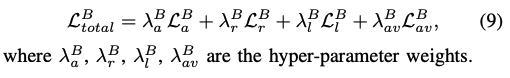
3.2 High-Fidelity Rendering
1、HRDecoder
HRDecoder 组成如下:
- base convolution module
- upsampling convolution module,是 transposed convolution,主要用于将低分辨率特征提高到高分辨率
- output convolution block
HRDecoder:
- 输入:第一阶段输出的 base face,对应的 face landmark sketch(两者 concat)
- 输出:高保真的 face(主要依靠的是 landmark sketch 的指导)
HRDecoder 的公式表达:
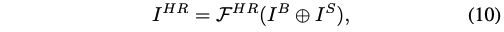
- ⊕ \oplus ⊕:concat
- I S I^S IS:face landmark sketch
- I H R I^{HR} IHR:高保真的 face
第二阶段 HRDecoder 使用的训练数据是第一阶段训练好的模型生成的 base face 和 对应的 landmark sketches
2、High-Fidelity Rendering loss 函数
在这个阶段,为了生成高保真的 face,作者定义了一个判别器 HRDiscriminator,该 HRDiscriminator 的 loss 如下:
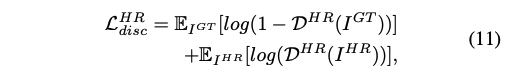
-
HR Adversarial Loss:对抗 loss,为了保证 HRDecoder 的真实性
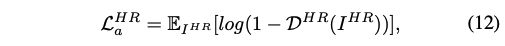
-
HR Perceptual Loss:感知 loss,使用预训练的 VGG ( ϕ \phi ϕ) 来抽取图像特征,并计算生成的图片和真实图片的 VGG 特征的 L1 loss
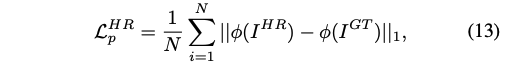
-
HR Reconstruction Loss:重建 loss,计算生成图片和真实图片的 L1 loss
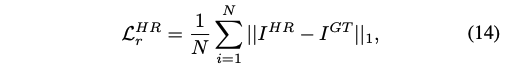
-
HR Lip Loss:为了进一步优化嘴唇区域,作者使用嘴唇区域的 mask 来计算该区域的 lpips loss 和 重建 loss:
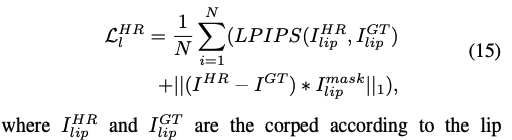
-
最终的 loss 如下:
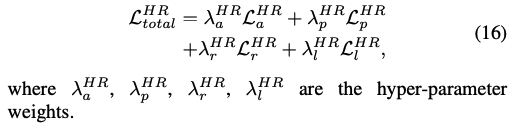
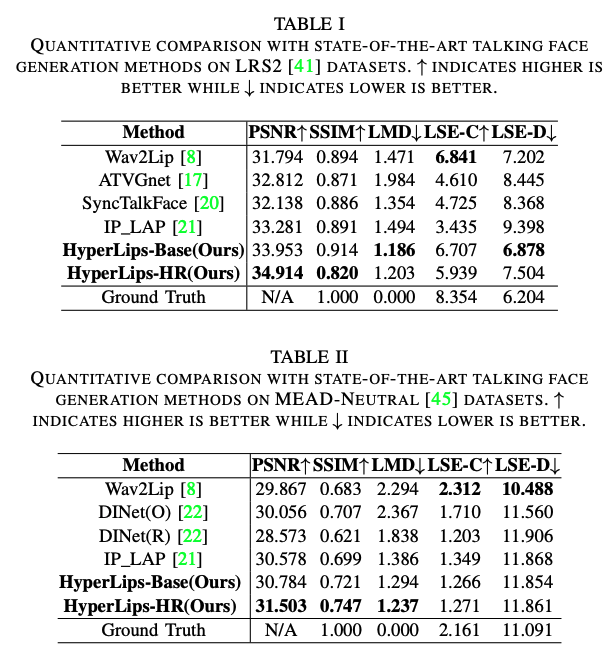
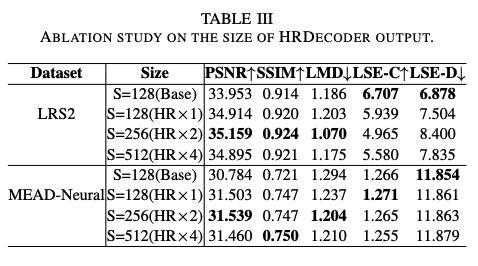
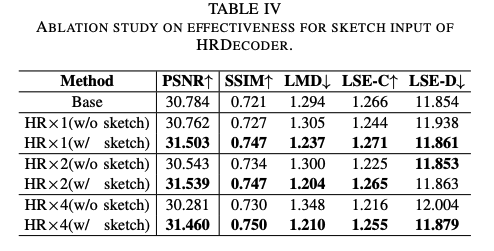
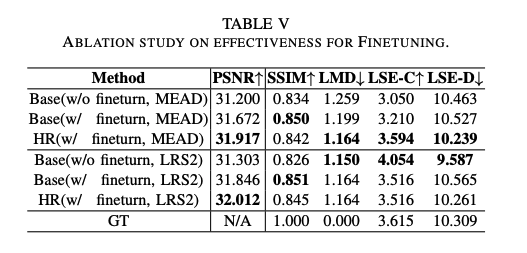
四、效果
实验细节:
- 对 video frame 从中间裁剪 128x128,25fps
- HyperLips-Base 和 HyperLipsHR 的学习率都为 0.0001
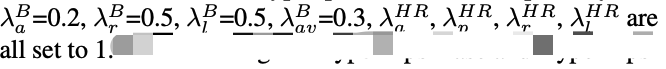
数据:
- LRS2
- MEAD-Neutral