- 1如何快速入门sift算法_离散空间极值点与连续空间极值点
- 2基于Java+Vue+uniapp微信小程序健身小助手系统设计和实现_java健身助手
- 3Python tkinter库之Canvas 直线等分圆弧(割圆术)_python等分圆弧
- 4element-ui的el-menu路由模式下选中无颜色_el-menu移入不改变颜色
- 5【CI/CD】基于 Jenkins+Docker+Git 的简单 CI 流程实践(上)_设置ci流程,选择git
- 6unity3d 透明贴图双面显示
- 7彻底搞清楚map和flatmap_flatmap与map怎么都理解不了
- 8微软宣布.NET Core 3.0之后的下一个版本将是.NET 5,支持跨平台、移动开发_as p.net是什么的下一个版本
- 9大模型——LLAMA模型
- 10android源码编译环境准备(1)
从软件哲学角度谈 Amazon SageMaker(第一讲)
赞
踩

概览
如果你喜欢哲学并且你是一个 IT 从业者,那么你很可能对软件哲学感兴趣,你能发现存在于软件领域的哲学之美。接下来我将用两讲,带大家从软件哲学的角度来了解亚马逊云科技的拳头级产品 Amazon SageMaker 。
Amazon SageMaker :
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/whatis.html
本讲我们将从:
天下没有免费的午餐——权衡之道
简单之美——大道至简
没有规矩不成方圆——循规蹈矩
三个部分来进行论述。
首先,了解亚马逊云科技的拳头级产品 Amazon SageMaker ,有两个出发点:
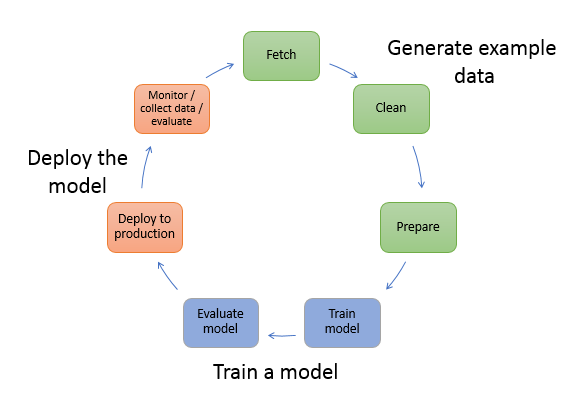
一是 SageMaker 本身设计所遵循的软件哲学;二是从软件哲学的角度我们应该如何使用 SageMaker 提供的功能。SageMaker 是一个全托管的机器学习平台(包括传统机器学习和深度学习),它覆盖了整个机器学习的生命周期,如下图所示:
天下没有免费的午餐
——权衡之道
软件有很多的品质(品质也叫非功能性需求):性能(比如时间性能,空间性能,模型性能),可用性,易用性,可扩展性,兼容性,可移植性,灵活性,安全性,可维护性,成本等。一个软件没有办法满足所有的品质,因此我们在和用户交流的过程中,要真的弄清楚用户想要的是什么(没有想象中那么简单),哪个或者哪些软件的品质是用户当前最关心的。
很多软件品质经常会互相制约(一个经典的例子就是安全性和时间性能,安全这个品质就是一个让人又爱又恨的东西,一般来说需要加入安全性的时候,在其他上下文不变的情况下,基本上时间性能就会变差了),所以我们需要权衡,而在权衡的时候一定要把握好“度“。
对于 SageMaker 来说:
SageMaker Processing job 要求数据的输入和输出都需要在 S3 ,基本原理图如下:
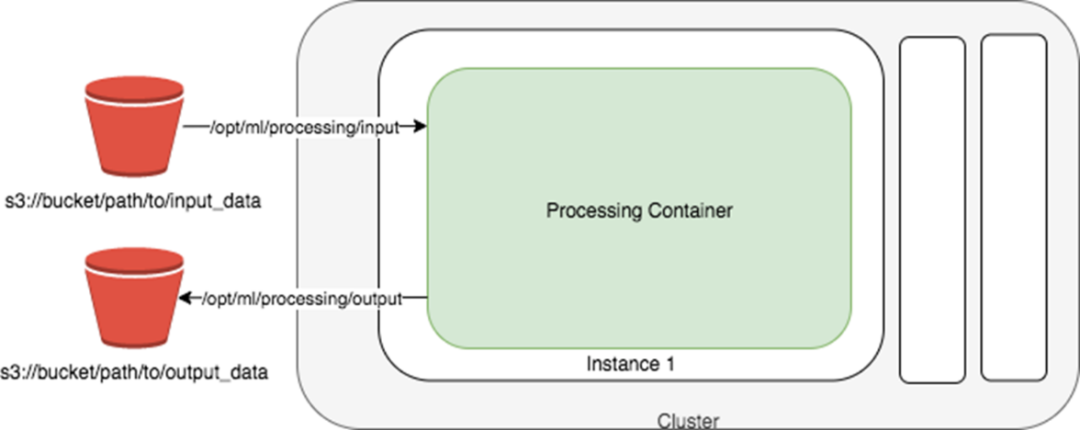
SageMaker Processing job 提供了托管的单个实例或者集群来做数据预处理,特征工程以及模型评估。如果你的原始数据并没有存放在 S3 ,这个时候你需要权衡空间性能与可托管性(可托管性的好处是很多运维的工作就不需要你关心了,交给了亚马逊云科技来运维),是把数据从源拷贝到 S3 来使用托管的 Processing job 服务还是就地来用自建的集群来处理;如果你的原始数据本身就存放在 S3 ,那么直接用 Processing job 来使用 Sklearn 或者 SparkML 来进行数据预处理或者特征工程是你的首选。
SageMaker 的内建算法对数据输入格式的要求以及可配置的有限的超参数。SageMaker 提供的内建算法(SageMaker 对常见的 ML 任务基本都提供了一种或者多种算法)对数据输入格式的要求以及提供的超参数可能与开源界的算法的数据输入格式和提供的超参数有区别。这里你需要权衡易用性与灵活性:如果你只是想实现一个 ML 的任务并且不想关注算法的实现细节,那么可以优先尝试 SageMaker 的内建算法;如果你想更深入了解算法的实现细节以及更灵活的超参数设置,那么建议的选择是把你的算法或者开源的算法迁移到 SageMaker 中。
SageMaker 训练时的 HPO 自动超参数优化功能的使用。自动超参数优化的初衷是为了减轻算法工程师/数据科学家/应用科学家们手工调参的痛苦。SageMaker 的 HPO 自动超参数优化对于内建算法和非内建算法都支持,并提供了贝叶斯搜索和随机搜索两种方式供你选择。不是所有的算法都需要走自动超参数调优,需要权衡模型性能(就是指模型效果)与成本。一般来说,对于深度学习模型或者海量数据集的情况下可能做自动超参数调优的时间代价和成本代价太大。因此在实际的 ML 项目中,用户很少对深度学习模型或者海量数据集做自动超参数调优;对于传统的机器学习模型并且在数据集不大的情况下,可以考虑用自动超参数调优来找到可能的最优解。
SageMaker 内建的 inference pipeline 的数据流。SageMaker Inference pipeline 可以把多个容器(容器中可以跑特征处理逻辑或者跑模型 serving 逻辑)串接起来,它的目的是把推理时的特征处理模块和模型串接起来,或者把多个模型做成上下游串接起来。它的数据流是这样的:
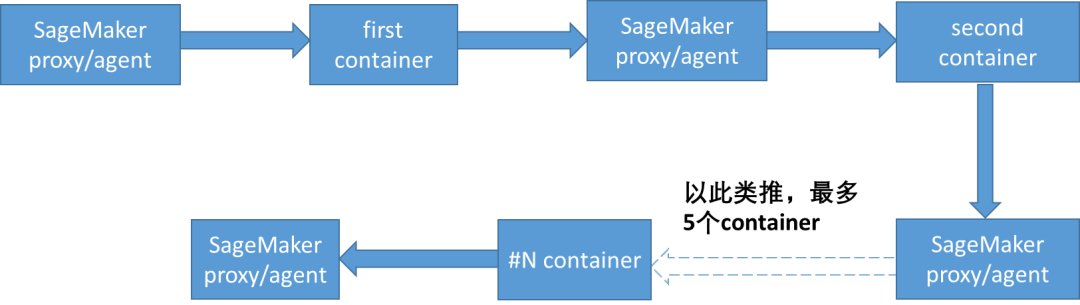
也就是说,每个容器的输出由 SageMaker 内部组件做中转,该组件把上一个容器的输出做为新的 request 发送到下一个容器。通过使用 Inference pipeline 这个功能可以简单方便的实现模型的上下游串接或者特征处理模块和模型的串接,但从上面的数据流可以看到会带入一些延迟,这个时候你需要考虑延迟是否在可以接受的范围内并使用 Inference pipeline,也就是需要权衡易用性与时间性能。
SageMaker 中对于 Tensorflow 和 Pytorch 两种框架都提供了多种训练方式。训练方式包括开源框架原生的方式以及 SageMaker 专门实现的针对这两种框架的数据并行和模型并行两种方式。SageMaker的数据并行训练方式适合每个 GPU 卡可以跑完整的模型训练但是数据集是海量的情况;SageMaker 的模型并行训练方式适合单个 GPU 卡无法直接跑模型训练的情况(比如模型太大了)。
也就是说,在海量数据集大规模训练或者超大模型训练的场景,使用 SageMaker 的这两种专有的训练方式比框架原生的训练方式会更高效,但是使用 SageMaker 的数据并行和模型并行的训练方式的话,对于框架的版本有要求并且需要一定的代码修改,因此需要你权衡代码的可移植性与时间性能
简单之美——大道至简
“简单”可能的含义有很多,比如精简,简朴,可读性好等。
“简单”的度量标准可能每个人的理解都不一样,但是一个通用的原则是,“您”在设计软件的时候尽量多想着:“软件需要别人来用,还需要别人来迭代和维护”,您一定要高抬贵手。“简单”的对立面就是“复杂”,业界的共识是通过降低复杂度来得到高质量长生命期的软件,而如何降低复杂度是每个软件设计人员以及开发人员无时无刻需要关注的事情。
在 SageMaker 中的体现:
SageMaker 是基于 container 的设计,到目前为止没有选择 Kubernetes。在当前业界大兴 Kubernetes 的情况下, SageMaker 并没有随大流。Kubernetes 的功能很强大但是很复杂,对于 SageMaker 来说,很多 Kubernetes 的功能用不上,那么为了减少软件依赖以及降低复杂度,SageMaker 选择了更轻量的设计(杀鸡真的没有必要用牛刀)。
SageMaker high level API(high level API 指的是SageMaker Python SDK,这个 API 的使用习惯类似常见的 ML 框架比如 Sklearn )设计很简洁,类层次也很清晰(分层就是一种降低复杂度的方法),很多 feature 通过简单的参数设置就能搞定。比如通过简单的设置 distribution 参数就把底层复杂的分布式环境部署隐藏掉了(信息隐藏也是降低复杂度的一种方法),让 API 调用者的关注点更集中在训练脚本本身;比如简单的设置模型的 S3 保存位置,SageMaker 就会帮助你在训练结束或者训练中断时把对应目录下的模型压缩打包并上传到 S3 指定路径;比如通过设置 git_config 参数,你就可以直接用 github 中的代码在 SageMake 中来训练,而不需要你关心代码的搬迁过程。
SageMaker 提供了多种算法选择:内建算法,BYOS(基于预置的机器学习框架来自定义算法),BYOC(自定义算法设计并自己来打包容器镜像)和第三方应用市场(在 Amazon Marketplace 中挑选第三方算法包,直接在 Amazon SageMaker 中使用)。而 BYOS 和 BYOC 是 SageMaker 中实际用的最多的两种选择。那如何选择 BYOS 和 BYOC ?总的来说,优先看 BYOS 是否能满足需求。BYOS 相对于 BYOC 要容易,需要迁移到 SageMaker 的工作量也少。而选择 BYOC,常见的是如下的情景:
情景1 | SageMaker中的内置框架的python版本不是你需要的版本 |
情景2 | 你需要一个完全不同于SageMaker的那些内置框架比如paddlepaddle |
情景3 | 有些用户习惯使用基于docker image的容器跑ML,那么BYOC可能对他们来说比较容易过渡。 |
情景4 | 有些用户代码分为两部分:底层基础平台级别代码,上层用户定制代码。 底层代码打包为docker image 并push到ECR以BYOC方式跑通。 上层用户指定docker image为上面打包好的image,然后跑自己的定制代码。这样做的好处是,代码管理分离,不会发生纯BYOS方式上层用户误修改底层代码的问题。 |
情景5 | BYOC一次性安装了相关的软件包; 如果用到的软件包不在SageMaker内置的容器镜像中,BYOS每次都有安装软件包的过程。 |
除了上面这些情景,尽量优先考虑 BYOS 的方式,它使用方式简单,学习曲线也短。
SageMaker 提供了两个变量 sagemaker_program 和 sagemaker_submit_directory 来帮助你轻松的完成 BYOC 的调试。前者告知 SageMaker 把这个参数的值作为 user entry point(就是用户提供的需要 SageMaker 调用的脚本),后者则是这个 entry_point对应的代码以及它所依赖的代码打包后的 S3 路径。通过设置这两个参数,在调试代码的时候只是需要把修改后的代码重新打包上传就可以,而不是每次都 build docker file,简单方便而且很节省时间。
没有规矩不成方圆
——循规蹈矩
拥有丰富经验的你可能听过或者践行过契约式编程,而契约式编程简单说就是,你需要按照对方的一些约定来 coding 。一般来说,只要是提供给别人使用的软件/工具,或多或少都会有一些约定。SageMaker 从尽量减少代码侵入性和最小代码迁移工作量的思路出发,提供了很多约定。
在SageMaker中的体现:
训练时,数据Channel相关的约定:
_ | 介绍 |
Channel 命名 | 使用SageMaker API设置数据 channel的时候,channel名字你可以随意选取比如名字取为 “train”,然后通过SageMaker设置的环境变量 SM_CHANNEL_{channel_name}(其中的{channel_name}换成你设置 channel的名字,“train”对应的就是 SM_CHANNEL_TRAIN)就可以获得channel中数据的本地路径 “/opt/ml/input/data/train”。SageMaker会把数据集拷贝到这个约定好的路径,那么你的程序只有遵守约定才能读取到需要的数据。 |
Channel 顺序 | 环境变量中多个channel的名字的顺序与调用SageMaker estimator fit API时写入的顺序是不同的。比如对于在fit API时设置 {'training':train_s3, 'training-2':train2_s3, 'evaluation': validate_s3} 这样的三个channel, 环境变量SM_CHANNELS被设置为['evaluation', 'training', 'training-2'], 也就是说最后一个channel ' evaluation'出现在环境变量 SM_CHANNELS中的第一个, 其他channel则是按照原来顺序排列,在训练脚本中读取数据的时候一定要注意这个细节,否则会出问题。 |
训练容器本地路径相关的约定,如下图所示:
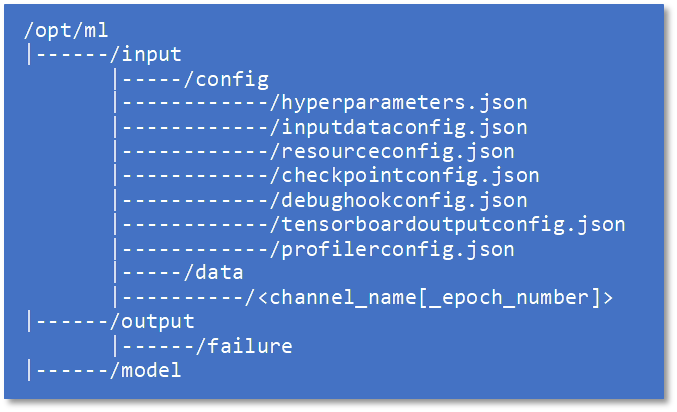
我们重点关注下表中的四种路径(除了下面这些路径,训练过程中放置在其他路径下的文件,在训练结束后都会被丢弃):
四种路径:
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/model-train-storage.html#model-train-storage-env-var-summary
路径 | 介绍 |
/opt/ml/ model | 这里存放最终的模型文件。 被SageMaker上传时机:训练结束(这个路径下的所有文件会被压缩打包后上传)。 |
/opt/ml/ output/data | 这个一般存放的是训练过程中的一些和模型文件以及checkpoint没有关系的文件(比如验证集评估结果文件)。 被SageMaker上传时机:训练结束(这个路径下的所有文件会被压缩打包后上传)。 |
配置的 checkpoint local path 路径 | 这个是为了让SageMaker来帮助你自动上传checkpoint或者在开始训练任务前把 checkpoint从S3下载到这个路径。 被SageMaker上传时机:训练中近实时上传(但是这些文件并不压缩和打包)。 |
配置的 tensorbaord log local path路径 | 这个是为了让SageMaker来帮助你自动上传tensorboard的log到指定的S3路径。 被SageMaker上传时机:训练中近实时上传。 |
SageMaker 给容器提供了很多方便使用的环境变量,包括 SageMaker 相关的和内建框架相关的。比如 SageMaker 相关的一部分环境变量如下:

SageMaker 内建的 TF serving 框架的 service side batch 相关的环境变量如下:

SageMaker 内建算法对输入数据格式的要求。SageMaker 内建算法对输入数据的格式要求可能和开源算法对数据格式的要求不同,如果不注意这个,在调试模型的时候可能会出现比较奇怪的结果。比如 SageMaker 目标检测算法对 BBOX 的格式要求如下:对于 json 格式的输入标注文件, 要求的坐标格式是 [top, left, width, height],如果你的数据集的标注是 PASCAL VOC 格式的(xmin,ymin,xmax,ymax)或者是 COCO 格式的(x,y,width,height),都需要做不同的转换;对于 recordIO 格式的输入文件, 要求坐标格式是相对坐标,[xmin/width,ymin/height,xmax/width,ymax/height]。
Spot 实例与 SageMaker checkpoint 机制的配合。为了节省成本,使用 spot 实例进行训练是首选。为了让 spot 实例被回收对你的训练任务造成的影响最小化, SageMaker 通过两个参数 checkpoint_local_path和checkpoint_s3_uri 来助你一臂之力(当然你不使用 spot 实例,也仍然可以利用 SageMaker的checkpoint 机制)。这样训练 job 被 spot 回收中断以后并自动重新开始训练后,就不用从头开始训练了,而是从最新的 checkpoint 开始接着训练(SageMaker 提供了 checkpoint 上传和下载的机制,你需要修改你的代码来配合,也就是你需要从约定的 checkpoint local 路径来初始化你的模型参数,否则是空谈),从而在节省成本的同时节省训练时间。
总结
这一讲我们从 天下没有免费的午餐——权衡之道、简单之美——大道至简、没有规矩不成方圆——循规蹈矩 三个部分,以软件哲学角度来介绍了 SageMaker 的一些设计思想以及如何使用 SageMaker 的一些功能。下一讲我们将从其他四个哲学维度来进一步介绍 SageMaker。
本篇作者

梁宇辉
亚马逊云科技
机器学习产品技术专家
负责基于亚马逊云科技的机器学习方案的咨询与设计,专注于机器学习的推广与应用,深度参与了很多真实用户的机器学习项目的构建以及优化。对于深度学习模型分布式训练,推荐系统和计算广告等领域具有丰富经验。


听说,点完下面4个按钮
就不会碰到bug了!