- 1spring-boot-maven-plugin:介绍_lib-provided
- 2扩展卡尔曼滤波与粒子滤波例程
- 3postgresql 查找慢sql之二: pg_stat_statements_可以使用pg_stat_statements去查询运行时间长的sql语句。
- 4智能音响蓝牙调试经验_ap6212 pcm接口
- 5往linux内核函数挂钩子_linux内核任务切换时增加钩子函数
- 6c#如何根据时间戳校验本地系统时间_c#怎么获取被人修改了系统时间
- 7挑战UnityShader学习之三_工欲善其事必先利其器Standard面板详细解析和代码自定义_unity的standard
- 8chart.js使用学习——饼图/环形图_js chart.js绘制饼图
- 9Blob 下载类型 type 大全_blob.type
- 10Unity的粒子系统的界面官方手册英文翻译+使用注意知识_size by speed ue4中文
大模型——LLAMA模型
赞
踩
论文导读
ChatGPT具有指令遵循能力和泛化性,论文对ChatGPT背后的指令微调和RLHF技术进行详细描述。
背景
gpt-3模型首次超过千亿数量级,但是由于参数规模大,无法使用微调方法,那么出来了提示学习
提示学习:给一个任务描述,输出模型
提示学习隐含假设:预训练模型包含丰富知识
预训练模型 提示学习 预训练+微调 预训练+提示+预测
论文动机
InstructGPT参数越来越大,但是表现不好,不能遵循用户意图。为了解决这个问题,作者提出一种基于预训练语言模型的人类指令生成方法,根据用户给定的条件,生成符合用户需要的文本指令,并将这些指令作为输入送入预训练语言模型中,从而控制输出结果。
InstructGPT技术手段:人工标注数据+强化学习
step1:从测试用户提交的prompt(指令或问题),随机抽取一批,靠专业的标注人员给出高质量的答案,然后用标注好的<prompt,answer>数据来Fine-tuneGPT3模型。
step2:
- 训练回报模型:目的为了减轻标注困难。
- 随机抽取用户提交的prompt,使用第一阶段Fine-tune好的模型,对于每个prompt,由模型生成不同的回答。
- 标注人员对结果进行相应标准进行排序。
论文泛读
基础知识:
- 预训练模型:简单理解已经读过很多书的东西
- 提示学习:简单理解是一个老师,根据不同问题,给预训练模型提示或者建议。
- 语言模型(无监督训练):任务是预测一个句子在语言中出现的概率。(判断一个句子是否符合常规)。
- 现在很多大模型都是来源于BERT(包括GPT)。
- LLAMA是ChatGPT问世之后的产物,属于GPT类的语言模型。语料中包含数万亿个tokens.
- GPT一代:堆叠12个解码器层,但不具备transformer解码器所具有的解码器-解码器注意力子层。但是有自注意力层。
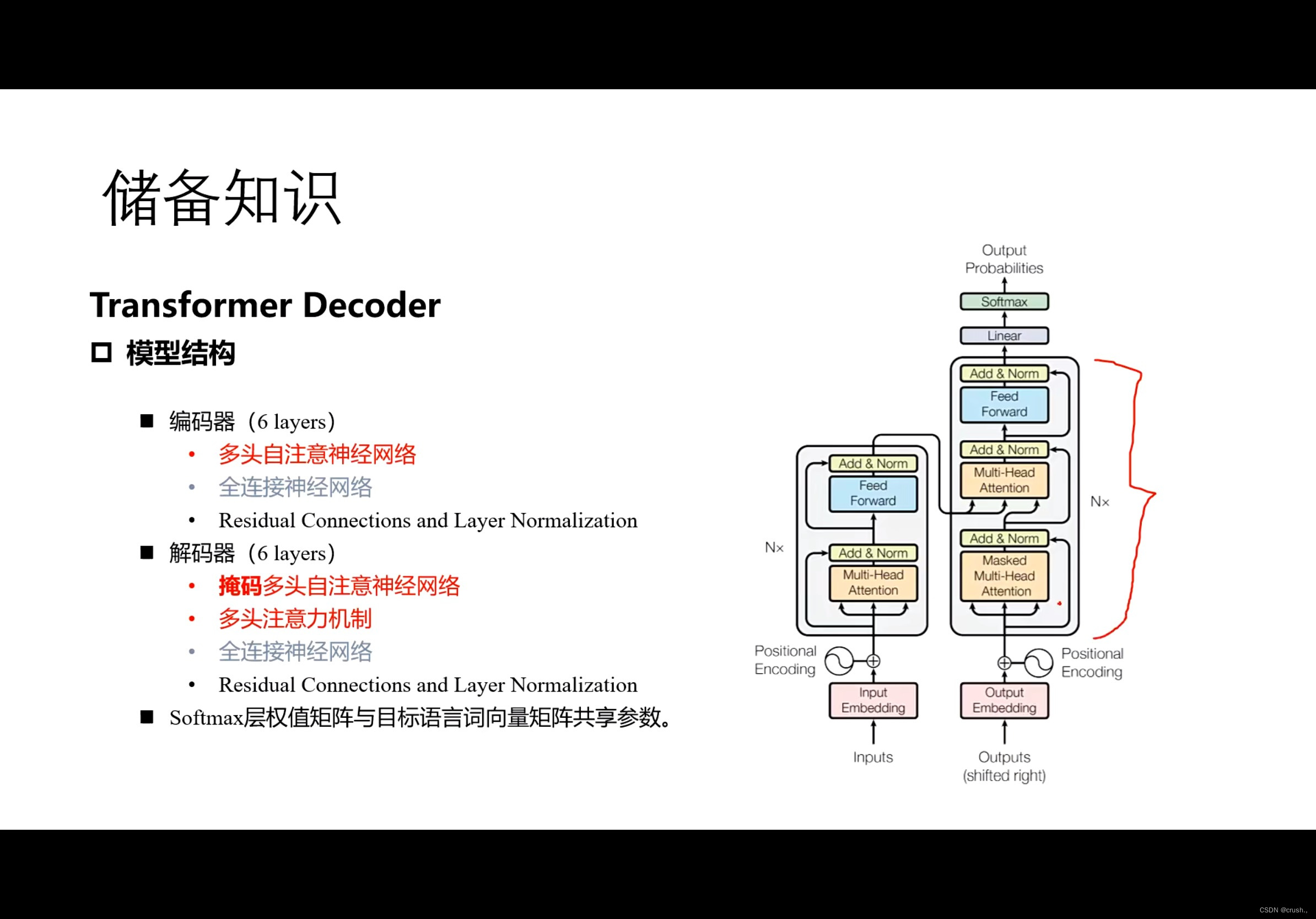
Transformer Decoder模型结构:
编码器
多头自注意神经网络
全连接神经网络
解码器
掩码多头自注意力神经网络
多头自注意力机制
全连接神经网络
背景介绍
LLaMA是基础语言模型的集合,参数范围7B到65B。数据来源于公开的数据集。
LLaMA和其它语言模型的关联
LLaMA与GPT、GPT-3类似,使用transformer architecture来预测给定单词或token序列作为输入的下一个单词或token.不同的是,它使用更多的token训练,得到较小的模型,这使他更高效,资源密集度更低。
发展史
InstructGPT(基于提示学习的一系列模型)>GPT3.5(大规模预训练)>ChatGPT模型(高质量的数据标注和反馈学习)。
LLaMA特点
- 参数量和训练语料:四种尺寸7B 13B 33B 65B
- 语种:20多种
- 生成方式:和GPT一样
- 所需资源更小
论文精读
LLaMA模型训练方法和GPT-3差不多,在大量语料中,使用transformer优化器进行模型训练。
LLaMA数据集:Common Crawl大规模网络文本数据集和其它开源数据集。
数据集:
Common Crawl 67% 数据的预处理来保证数据质量:
fastText线性分类器来执行语言识别来删除非英文页面.
n-gram语言模型过滤低质量内容。
C4 15% 数据集是Common Crawl网络爬取语料库的版本。
预处理还包括去重和语言识别步骤。
主要依赖启发式方法。
Github 4.5% wikipedia 4.5% 其它
模型结构 :网络基于transformer架构,并作部分改进。
Pre-normalzation:为了提高训练稳定性,对每一个transformer子层的输入进行归一化,而不是对输出进行归一化。
SwiGLU激活函数:代替ReLU非线性激活函数,提高性能。
好处:
SwiGLU激活函数收敛速度更快、效果更好(因为使用了门控机制,更好的控制信息流动)。
SwiGLU激活函数和ReLU都拥有线性通道,可以使梯度很容易通过激活的units,更快收敛。
和ReLU相比,更具有表达力。
Rotary Embeddings : 删除了绝对位置嵌入,在网络的每一层中添加了旋转位置嵌入。
旋转位置嵌入:将位置信息编码为一个旋转矩阵,然后将该矩阵与输入向量相乘,从而得到一个新的向量表示。好处是能够更好捕捉序列中不同位置之间的关系,更好的处理序列中旋转对称性,提高性能。
旋转对称性:物体在旋转后仍然具有相同的性质。
实验分析和讨论
模型参数:参数越大,学习率越低。
优化训练:使用因果多头注意力算子的高效实现。 为了提高训练效率,减少在带有检查点的反向传播过程中重新计算激活量,通过手动实 现变换器层的反向功能来实现,不依赖PyTorch autograd。
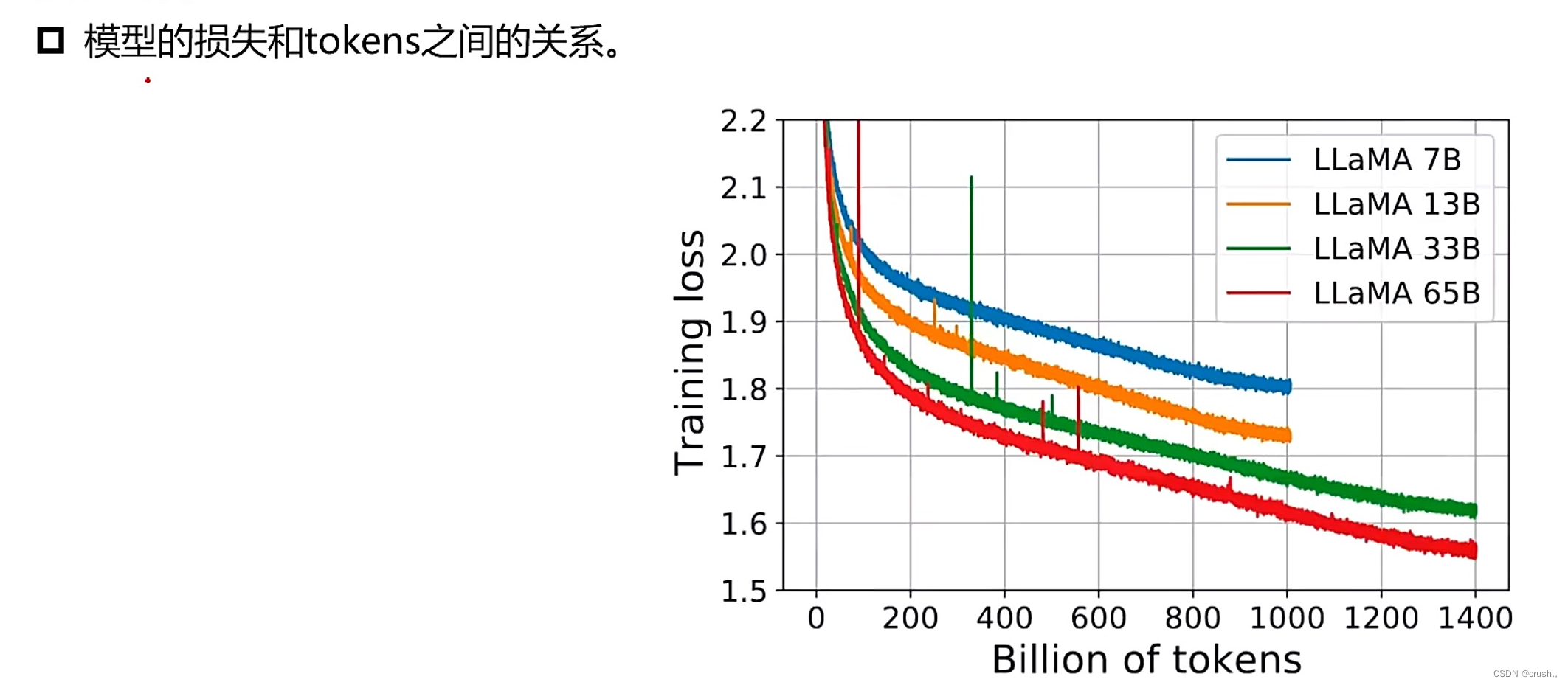
训练时间:包含1.4T token的数据集进行训练需要21天。
实验结果: