
- 1微信小程序开发系列-14模块的导入与导出_微信小程序如何导入模块
- 2【数据平台】之Cassandra大数据利器_cassandra多数据中心搭建
- 3samba、ftp、nfs、dhcp、dns和ntp搭建_smb ftp
- 4Springboot 整合Quartz_springboot整合quartz
- 5RabbitMQ介绍、搭建、管理后台使用
- 6卷积层,池化层,全连接层_卷积层,池化层,全连接层
- 7线性回归与逻辑回归_逻辑回归和线性回归
- 8【开发工具集】功能强大的网络设置工具——IPOP
- 9个人网站搭建(Day 12)— 部署服务器(上) 服务器的基础设置_自行部署(推荐):下载喜欢会员站模板,部署到自己的服务器上; 共享免部署:使用跟玩
- 10Github Actions 持续集成服务
基于大数据技术的python+django电影视频数据分析可视化系统_基于大数据技术的分析系统
赞
踩
近年来,互联网与移动终端的普及,网络上的电影娱乐信息数量海量增加。这其中自然不乏关注视频的民众,而现在正处于大数据时代,随着信息量的增多,为用户提供便捷的搜索服务也更加具有挑战性[1]。大规模存储信息并精确搜索的代价是巨大的,人们需要在信息搜索的快捷性与成本中找到平衡,网络视频标题的抽取已经成为了信息抽取和网络爬虫不可避免的一个环节。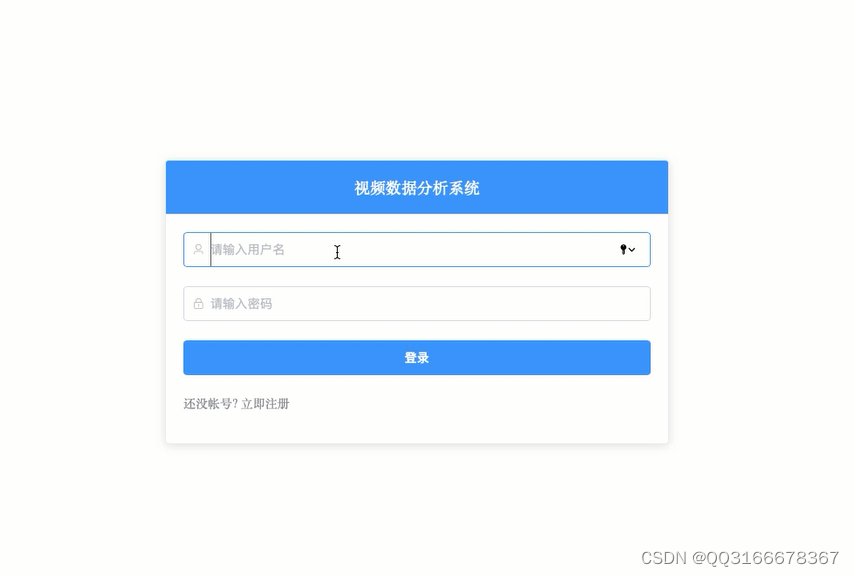 因此设计并实现一个具有良好健壮性和扩展性的系统非常有必要。系统主要开发工具是PyCharm,主要技术为html、css以及django开源框架的结合,前端使用 vue+elementui后端使用python+django.主要实现了用户注册,登录, 以及优酷视频的抓取,当前视频热门分析,视频类别占比分析等
因此设计并实现一个具有良好健壮性和扩展性的系统非常有必要。系统主要开发工具是PyCharm,主要技术为html、css以及django开源框架的结合,前端使用 vue+elementui后端使用python+django.主要实现了用户注册,登录, 以及优酷视频的抓取,当前视频热门分析,视频类别占比分析等
在本系统的开发过程中,研究学习了如何使用scrapy、Django这两大框架,体会到了python语言的“极简至优美”,我接触到了这几个框架的前沿知识,对自己可以站在巨人的肩膀上兴奋不已。我在系统开发过程中,经历了由抓取数据至存储数据再至前端页面展示数据,这样的经历让我收获颇丰。通过这段时间的研究,我越发了解到爬虫已经渗透进了我们生活的方方面面。在这个大数据的时代,数据就是资源,爬虫作为获取数据的一大利器,需要我们更深入的研究与掌握。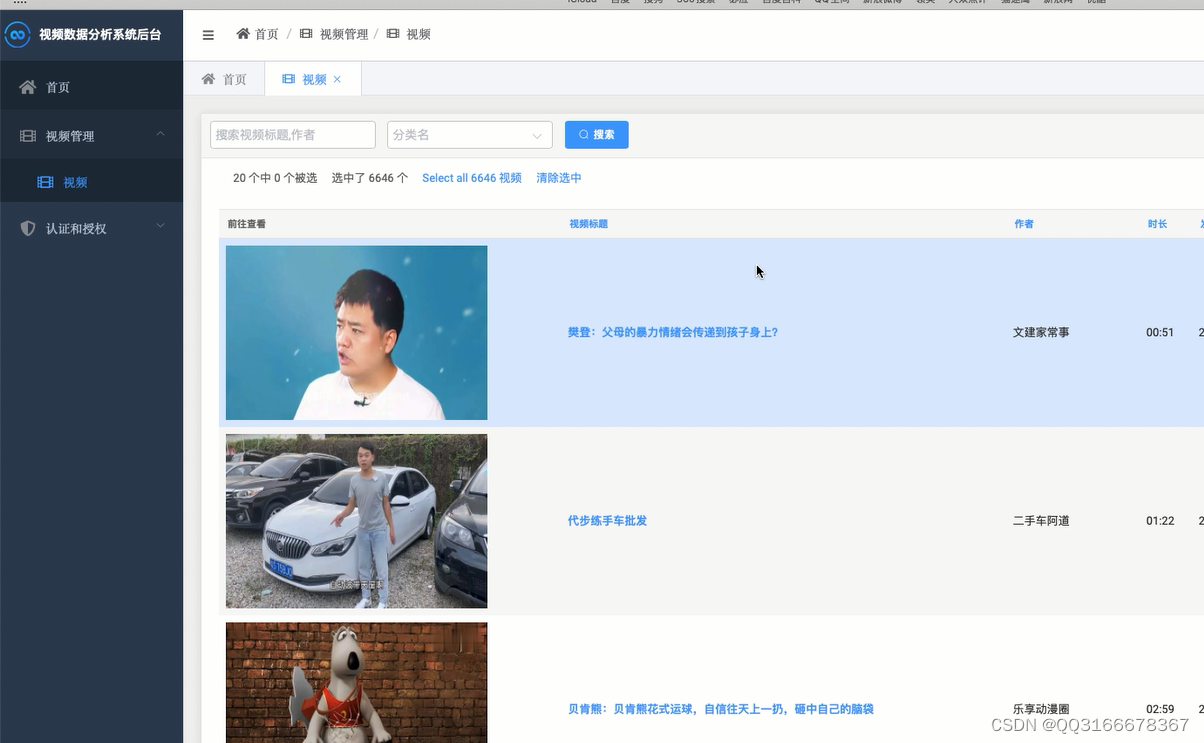
虽然毕业设计功能复杂,过程繁琐,但我的收获却更加丰富。在这次毕业设计中,我实现了系统的登录和注册功能;网络爬虫功能;视频优酷视频数据可视化和薪资预测以及优酷视频推荐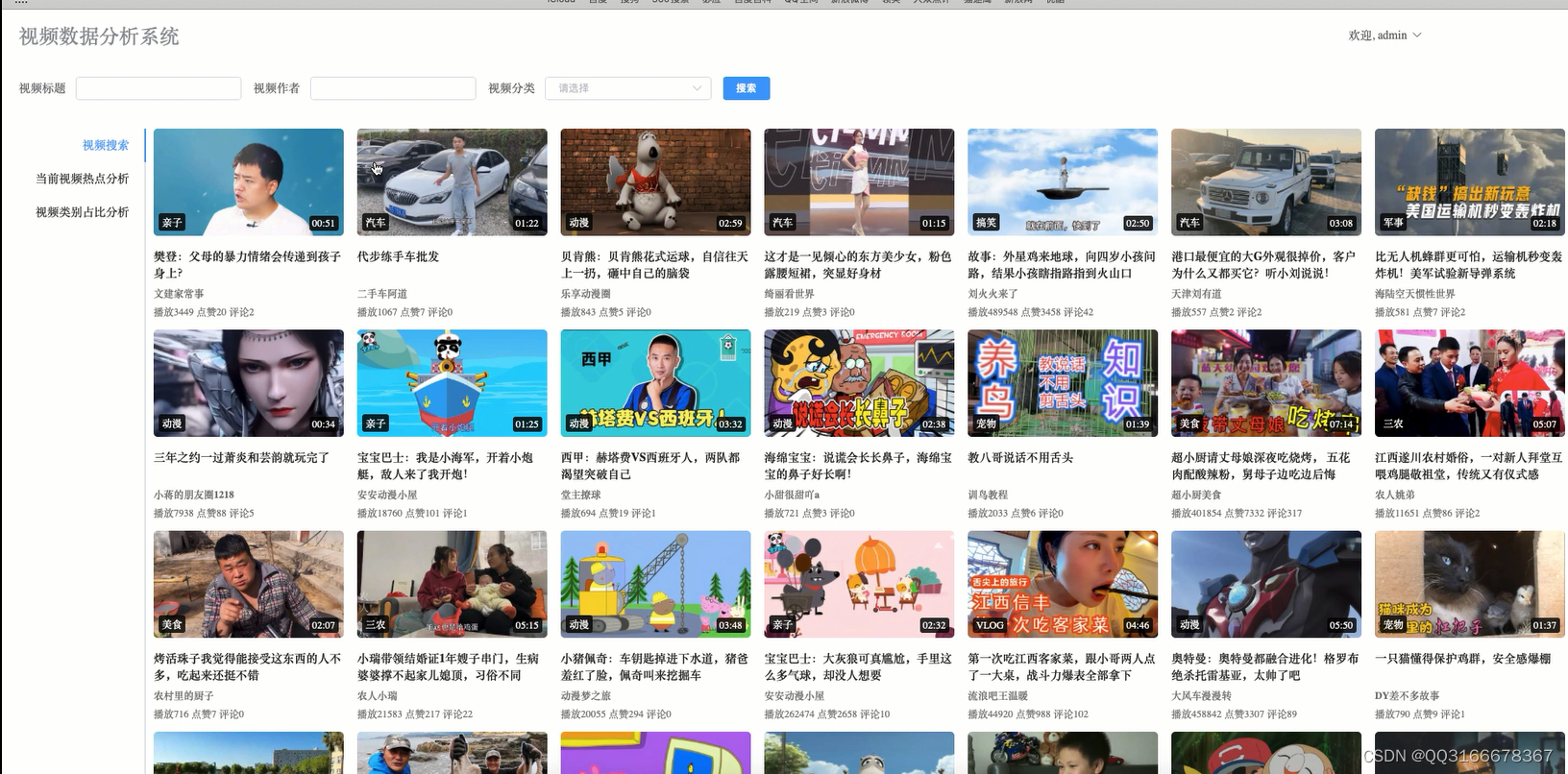 。在进行系统开发的过程中,各种系统的适用条件,各种开发工具的选用标准,各种语法的应用方式,我都是随着设计的不断深入而不断熟悉并学会应用的。和老师的沟通交流更使我从实用的角度对设计有了新的认识也对自己提出了新的要求在实际应用中,网络爬虫不只有抓取优酷视频,应该多抓取一些其他视频网站的数据,比如智联视频等,而我在一开始设计的时候却没有意识到这个问题,只是在研究优酷视频的抓取和反抓取功能,这在实际应用的情况算是重大失误了,而我通过这次毕业设计让我提前了解了这些知识,这是很珍贵的。
。在进行系统开发的过程中,各种系统的适用条件,各种开发工具的选用标准,各种语法的应用方式,我都是随着设计的不断深入而不断熟悉并学会应用的。和老师的沟通交流更使我从实用的角度对设计有了新的认识也对自己提出了新的要求在实际应用中,网络爬虫不只有抓取优酷视频,应该多抓取一些其他视频网站的数据,比如智联视频等,而我在一开始设计的时候却没有意识到这个问题,只是在研究优酷视频的抓取和反抓取功能,这在实际应用的情况算是重大失误了,而我通过这次毕业设计让我提前了解了这些知识,这是很珍贵的。
目 录
摘要 1
abstract 1
目 录 1
1 绪论 3
1.1 开发背景 3
1.2 开发意义 3
2 开发技术介绍 3
2.1 Python介绍 3
2.2 Django介绍 4
2.3 xpath介绍 5
2.4 Vue介绍 5
2.5 Scrapy架构 5
2.6 开发环境搭建 6
3 系统设计 7
3.1 可行性分析 7
3.2 系统功能分析 8
3.3 爬虫设计 8
3.4 功能模块设计 10
3.5 突破反爬虫设计 10
3.6 系统文件结构介绍 11
3.7 scrapy爬虫主要文件介绍 12
4 详细实现 12
4.1 系统注册登陆 12
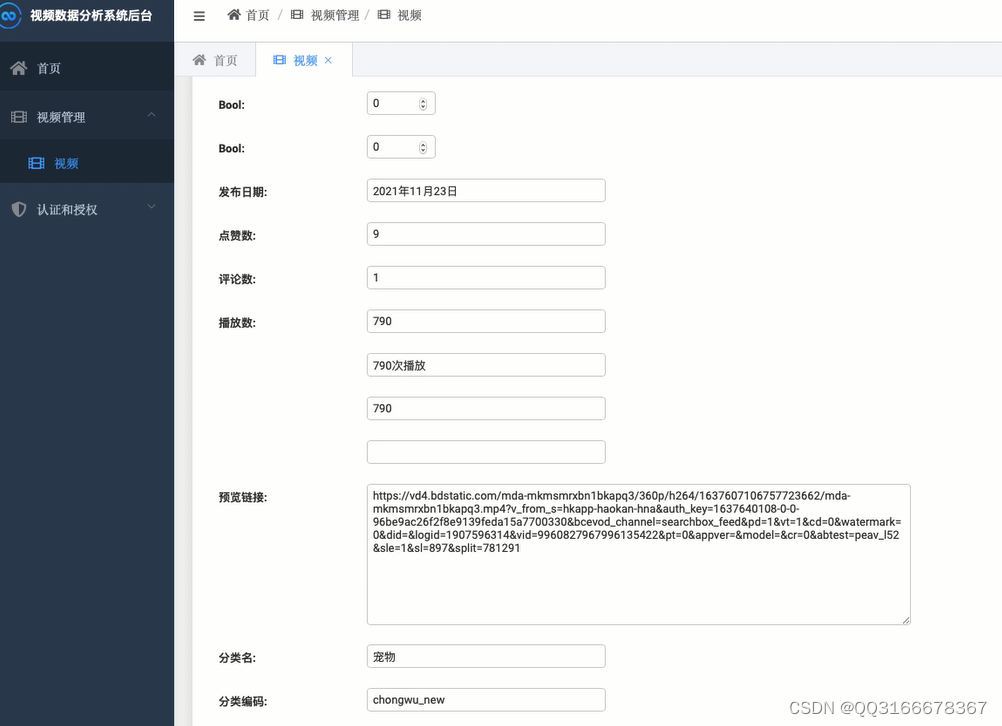
4.2 优酷视频数据抓取 14
4.3 爬虫抓取策略 14
4.4 当前视频热点分析 15
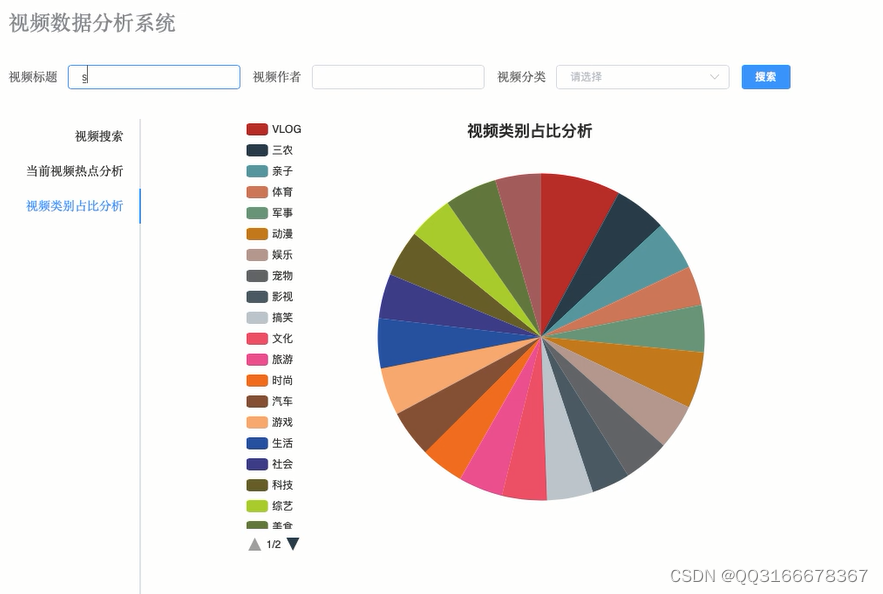
4.5 视频类别占比分析 16
5 系统测试 16
5.1 软件测试的环境 16
5.2 测试的重要性 17
5.3 数据爬取功能测试 17
5.4 数据展示测试 17
结束语 18
参考文献 20
致谢 22


