
- 1使用postman进行数据传输_postman event-stream数据接收
- 2No8.【spring-cloud-alibaba】基于OAuth2,新增加手机号验证码登录模式(不包含发短信,还没找到合适的短信发送平台)_oauth2.0手机号登录功能
- 3golang的map是不是并发安全的?怎么保证安全?
- 4力扣面试经典150 —— 1-5题
- 5基于微信小程序网上外卖订餐点餐系统设计与实现 毕业设计论文大纲提纲参考
- 6每天一个数据分析题(一百六十六)
- 7为什么LLM都用的Decoder only结构?_decoder-only的参数量只有encoder-decoder一半时,两者在预训练时的算力消耗相
- 8linux麒麟系统二级等保【三权分立策略】_银河麒麟操作系统怎么创建三权用户
- 9UE5 Python执行swarm lightmass构建_ue5添加lightmas
- 10ChatGPT调教指南 | 咒语指南 | Prompts提示词教程(二)
【正点原子FPGA连载】 第一章 MPSoC简介 摘自【正点原子】DFZU2EG/4EV MPSoC 之FPGA开发指南V1.0_zynq mpsoc book中文版
赞
踩
1)实验平台:正点原子MPSoC开发板
2)平台购买地址:https://detail.tmall.com/item.htm?id=692450874670
3)全套实验源码+手册+视频下载地址: http://www.openedv.com/thread-340252-1-1.html
第一章 MPSoC简介
Zynq UltraScale+ MPSoC是赛灵思推出的首款真正全可编程(All Programmable)异构多核处理SoC芯片。这款芯片采用台积电公司 (TSMC) 新一代 16nm FinFET 工艺制程,它包含一个可扩展的32位或64位多处理器 CPU、用于实时处理图形和视频的专用硬化引擎、先进的高速外设,以及可编程逻辑,可用于汽车驾驶员辅助与安全、无线和有线通信、数据中心以及连接与控制等多种应用领域。
本章包括以下几个部分:
11.1MPSoC简介
1.2FPGA简介
1.3MPSoC PL简介
1.4MPSoC PS简介
1.1MPSoC简介
Xilinx公司的FPGA芯片主要分为两大类,FPGA和SoC(System on Chip,片上处理系统),其中FPGA芯片只包含了可编程逻辑部分,而不包含处理器,如常见的Spartan系列、Artix系列、Kintex系列和Virtex系列。每一个系列又根据制造工艺和架构的不同,分为6系列(45nm)、7系列(28nm)、UltraScale(20nm)和UltraScale+(16nm),以提供不同的性能和功耗比。如下图所示:
图 1.1.1 Xilinx FPGA产品系列
Xilinx的SoC是将可编程逻辑部分和处理器单元以及常见处理器外设封装在一起,集成到单颗芯片中,并命名为“ZYNQ”,同样分为不同的系列,如Zynq-7000(28nm)、Zynq UltraScale+ MPSoC(16nm)、Zynq UltraScale+ RFSoC(16nm),如下图所示:

图 1.1.2 Xilinx SoC产品系列
Zynq7000系列组合了一个双核Arm Cortex-A9处理器和一个传统的现场可编程门阵列(FPGA)逻辑部件。由于该器件的可编程逻辑部分基于Xilinx 28nm工艺的7系列 FPGA,因此该系列产品的名称中添加了“7000”,以保持与7系列FPGA的一致性,同时也方便日后本系列新产品的命名。
Zynq UltraScale+ MPSoC的系统级性能功耗比相对Zynq-7000 SoC系列提升高达5倍。Zynq UltraScale+ MPSoC整合了一个双核或四核Cortex-A53处理器、双核Arm Cortex-R5F实时处理器和一个传统的现场可编程门阵列(FPGA)逻辑部件,该器件的可编程逻辑部分基于Xilinx 16nm FinFET+工艺的UltraScale+系列FPGA。
Zynq UltraScale+ 系列将高性能ARM多核多处理系统与ASIC级可编程逻辑相结合,并包含针对下一代系统的全套集成外设和连接内核。凭借针对不同工作负载的专业处理元件,Zynq UltraScale+ MPSoC 为合适任务集成合适引擎,以应对新的嵌入式挑战。
Zynq UltraScale+ MPSoC部分系列的产品,还包含了Arm Mail-400MP2(GPU)和H.264/H.265视频编解码器,可提供原生UltraHD压缩及专用引擎,满足动态电源管理与安全配置需求,可以说是对ZYNQ 7000的升级版本。Zynq UltraScale+ MPSoC非常适用于5G无线基础设施、面向数据中心和有线通信的软件定义网络、新一代汽车驾驶员辅助系统和无人驾驶系统 (ADAS)、工业物联网系统 (IIoT)、超高清和超高画质摄像机、航空电子以及便携式软件定义无线电等各种应用。
Zynq UltraScale+ RFSoC在SoC架构中集成数千兆采样RF数据转换器和软判决前向纠错 (SD-FEC)。配有ARM Cortex-A53处理子系统和UltraScale +可编程逻辑,该系列是业界唯一单芯片自适应射频平台。Zynq UltraScale+ RFSoC系列可为模拟、数字和嵌入式设计提供适当的平台,从而可简化信号链上的校准和同步。多代产品系列包含广泛的器件类型,具有不同的直接RF性能,可满足各种频谱需求和使用案例。
以上是对Xilinx产品系列的介绍,让大家对Xilinx的产品有一个初步的了解,以及开发板所使用的主控芯片在产品中的定位。在了解了Xilinx的不同产品之后,接下来我们详细介绍下Zynq UltraScale+ MPSoC系列产品。
Zynq UltraScale+ MPSoC产品在单个设备中集成了功能丰富的嵌入式处理系统(PS)和可编程逻辑(PL) UltraScale+架构,并且还包括片上存储器、多端口外部存储器接口以及丰富的外设连接接口集等等。
Zynq UltraScale+ MPSoC系列产品分三种类型,分别是CG型器件、EG型器件和EV型器件。其中CG型器件集成了由双核Arm Cortex-A53和双核Arm Cortex-R5F组成的64位处理系统;EG型器件集成了四核Arm Cortex-A53和双核Arm Cortex-R5F,除此之外EG型器件还集成了Arm Mali-400 MP2(GPU)用来专门进行图像处理操作;而EV型器件就更加强悍了,它在EG型器件的基础上再次增加了H.264/H.265 视频编解码器(VCU)用来专门进行视频处理操作,它可以支持60帧每秒(fps)的速率同时进行4Kx2K的编码和解码(约6亿像素/秒)或15帧每秒8Kx4K的编码和解码。如下图所示:

图 1.1.3 Zynq UltraScale+ MPSoC产品系列
Zynq UltraScale+ MPSoC产品命名规则如下图所示:
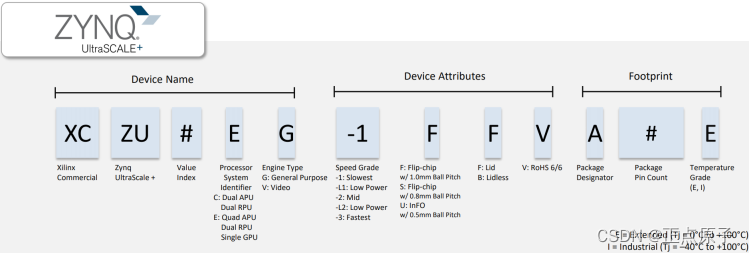
图 1.1.4 Zynq UltraScale+ MPSoC产品命名
Zynq UltraScale+ MPSoC除了嵌入式处理系统功能强大外,它还包含了可编程逻辑(PL) UltraScale+架构,能够灵活的去编辑我们想要的逻辑运算,实现各种各样的复杂功能。从本质上来讲,它还是一个片上处理系统(System on Chip,SoC)。那么,什么是“SoC”?
一个能够实现一定功能的电路系统由多个模块构成,如处理器、接口、存储器、模数转换器等等。这些功能模块可以由分立的器件来实现,然后在印刷电路板(PCB)上组合起来,最终形成板上系统(System-on-a-Board)。板上系统的示意图如下所示:
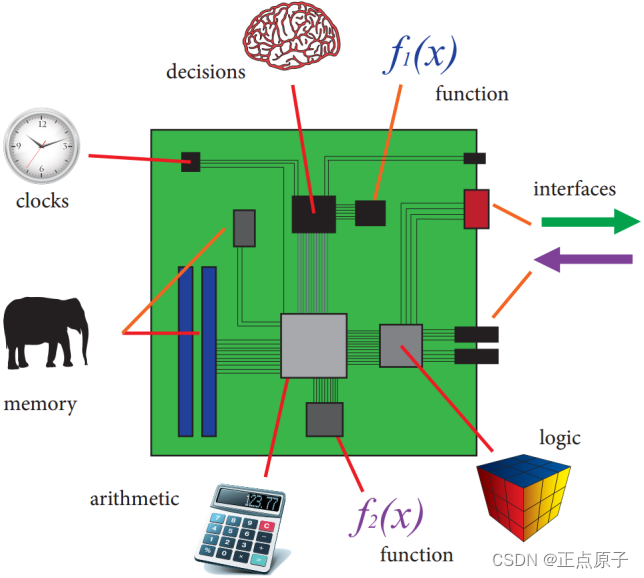
图 1.1.5板上系统
在上图所示的板上系统中,绿色的矩形代表印刷电路板(PCB),上面各种颜色的小矩形代表了系统中各个功能模块,如存储器等。这些模块的功能都由一个个独立的硅芯片分别实现的,它们之间通过PCB上的金属走线连接,最终构成一个完整的系统。
而片上系统(System-on-Chip)指的是在单个硅芯片就可以实现整个系统的功能,其示意图如下所示:
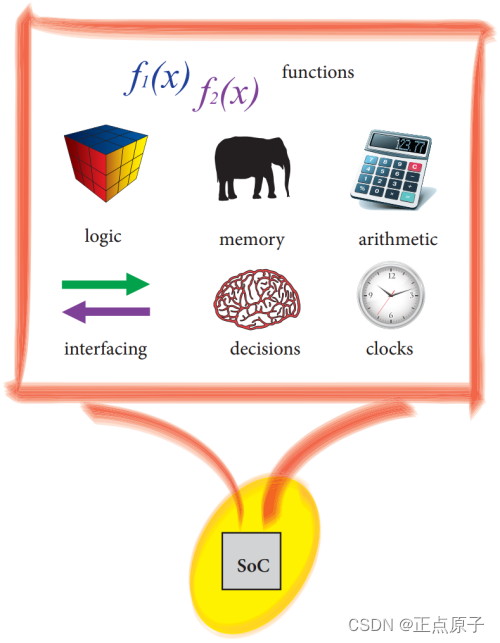
图 1.1.6 片上系统
如上图所示,片上系统SoC在一个芯片里就实现了存储、处理、逻辑和接口等各个功能模块,而不是像板上系统那样,需要用几个不同的物理芯片来实现。与板上系统相比,SoC的解决方案成本更低,能在不同的系统单元之间实现更快更安全的数据传输,具有更高的整体系统速度、更低的功耗、更小的物理尺寸和更好的可靠性。
在过去,SoC这个术语常用于指专用集成电路(Application Specific Integrated Circuit,ASIC)。基于 ASIC的SoC的代表性例子包括在PC、平板和智能手机上使用的处理器,如华为旗舰手机中的麒麟系列芯片。这些处理器典型地是由至少两个处理器核、存储器、图形处理器、接口和其他功能模块组合起来的。基于ASIC的SoC的主要缺点有两个:1、开发周期长且成本巨大;2、缺乏灵活性。开发ASIC时不可重用的工程投入是巨大的,使得这种SoC类型只适合于大批量而且寿命有限的产品中。
ASIC SoC的局限性导致它们不适用于很多应用,特别是当快速投入市场能力、灵活性和升级能力已经成为重要的关键因素。对于小批量或中批量的产品,ASIC SoC 也不是好的解决方案。
可编程片上系统(SOPC,System-on-Progammable-Chip)为上述应用提供了一个更灵活的解决方案:一种在可编程、可重新配置的芯片上实现的SoC。其中,可编程的芯片指的就是FPGA。FPGA天生的灵活性使其可以被随心所欲地重新配置,以实现不同系统的功能,包括嵌入式处理器。和使用ASIC来实现SoC相比,FPGA能构成更为基础灵活的平台,方便系统的升级。
与基于 ASSP 的固定 SoC 解决方案不同,Zynq UltraScale+ MPSoC 能通过灵活的32或64位数据宽度的处理系统提供最大的可扩展性。它能将关键应用(例如图形和视频管线)分配给专用处理模块来处 理,并通过有效的电源域 (power domain) 和电源孤岛 (power island) 来开启和关闭模块。Zynq UltraScale+ MPSoC 提供多种互连选项、DSP 模块以及可编程逻辑选择,因而具备整体灵活性,可满足 用户的各种应用需求。该产品系列具备出色可扩展性,使设计人员能够利用单个平台和行业标准工具开发出低成本以及高性能应用。
1.2FPGA简介
通过前面的介绍,我们知道Zynq UltraScale+ MPSoC中集成了ARM处理器与FPGA。Zynq UltraScale+ MPSoC作为一款全可编程SoC,其中FPGA的硬件可编程性功不可没。那么FPGA是什么呢,它的灵活性又从何而来呢?
1) 数字集成电路的发展
在数字集成电路中,门电路是最基本的逻辑单元,用以实现最基本的逻辑运算(与、或、非)和复合逻辑运算(与非、异或等)。与上述逻辑运算相对应,常用的门电路有与门、或门、非门、与非门、异或门等,其电路符号如下图所示:
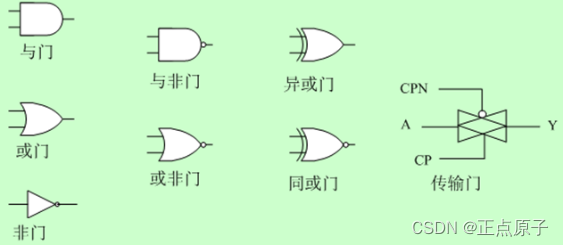
图 1.2.1 基本的门电路符号
在最初的数字逻辑电路中,每个门电路都是用若干个分立的半导体器件和电阻、电容连接而成的。不难想象,用这种单元电路组成大规模的数字电路是非常困难的,这就严重制约了数字电路的普遍应用。1961年,美国德州仪器公司(TI)率先将数字电路的元器件制作在同一片硅片上,制成了集成电路(Intergrated Circuits,IC),并迅速取代了分立器件电路。
早期的数字逻辑设计需要设计师在一块电路板上或者如下图所示的面包板上用导线将多个芯片连接在一起。每个芯片包含一个或多个逻辑门,或者一些简单的逻辑结构(比如触发器或多路复用器等)。如下图中所示的芯片是在1960和1970年代,很多设计中都会使用的德州仪器7400系列的器件。

图 1.2.2 使用74系列器件搭建的电路
自20世纪60年代以来,随着集成电路工艺水平的不断进步,集成电路的集成度也不断提高。数字集成电路经历了从小规模集成电路(Small Scale Integrated circuit,SSI),到中规模集成电路(Medium Scale Integrated circuit,MSI),再到大规模集成电路(Large Scale Integrated circuit,LSI),然后是超大规模集成电路(Very Large Scale Integrated circuit,VLSI),以及甚大规模集成电路(Ultra Large Scale Integrated circuit,ULSI)的发展过程。今天我们已经可以把十分复杂的数字系统制作在一个很小的硅片上,构成“片上系统”。
2) FPGA的由来
我们从逻辑功能的特点上将数字集成电路分类,可以分为通用型和专用型两类。前面介绍到的中、小规模集成电路(如74系列)都属于通用型数字集成电路。它们的逻辑功能都比较简单,而且是固定不变的。由于它们的这些功能在组成复杂数字系统时经常要用到,所以这些器件具有很强的通用性。
从理论上来讲,用这些通用型的中、小规模集成电路可以组成任何复杂的数字系统。随着集成电路的集成度越来越高,如果能把所设计的数字系统做成一片大规模集成电路,则不仅能减小电路的体积、重量和功耗,而且可以使电路的可靠性大为提高。像这种为某种专门用途而设计的集成电路称为专用集成电路,即所谓的ASIC(Application Specific Integrated Circuit)。
ASIC的使用在生产、生活中非常普遍,比如手机、平板电脑中的主控芯片都属于专用集成电路。

图 1.2.3 华为Mate 30手机中的麒麟990芯片
虽然ASIC有诸多优势,但是在用量不大的情况下,设计和制造这样的专用集成电路不仅成本很高,而且设计制造的周期也很长。可编程逻辑器件(Programmable Logic Device,PLD)的出现成功解决了这个矛盾。
可编程逻辑器件PLD是作为一种通用器件生产,但它的逻辑功能是由用户通过对器件进行编程来设定的。而且有些PLD的集成度很高,足以满足设计一般数字系统的需要。这样就可以由设计人员自行编程从而将一个数字系统“集成”在一片PLD上,做成“片上系统”(System on Chip,SoC),而不必去请芯片制造厂商设计和制作专用集成电路芯片了。
最后,我们再来总结一下这三种数字集成电路之间的差异。通用型数字集成电路和专用集成电路内部的电路连接都是固定的,所以它们的逻辑功能也是固定不变的。而可编程逻辑器件则不同,它们内部单元之间的连接是通过“写入”编程数据来确定的,写入不同的编程数据就可以得到不同的逻辑功能。
自20世纪70年代以来,PLD的研制和应用得到了迅速的发展,相继开发出了多种类型和型号的产品。PLD的发展历程如下图所示:
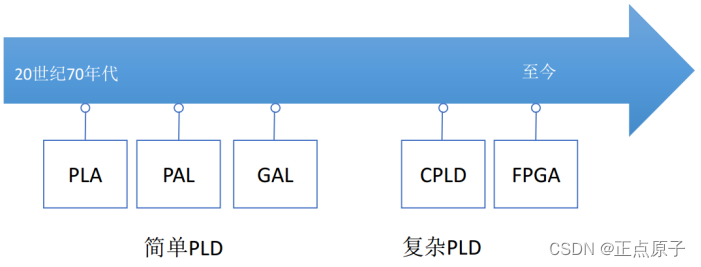
图 1.2.4 PLD的发展历程
目前常见的PLD大体上可以分为SPLD(simple PLD,简单PLD)、CPLD(complex PLD,复杂PLD)和FPGA(field-programmable gate array,现场可编程门阵列)。SPLD中又可分为PLA、PAL和GAL几种类型。FPGA也是一种可编程逻辑器件,但由于在电路结构上与早期已经广为应用的PLD不同,所以采用FPGA这个名称,以示区别。
通过对数字电路的学习我们知道,任何一个逻辑函数式都可以变换成与-或表达式,因而任何一个逻辑函数都能用一级与逻辑电路和一级或逻辑电路来实现。PLD最初的研制思想就来源于此。
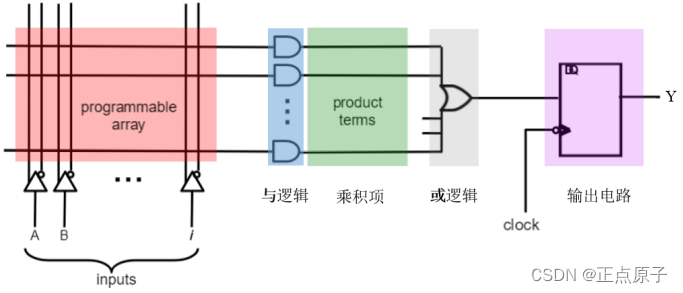
图 1.2.5 PAL器件的基本电路结构
上图是SPLD中PAL(可编程阵列逻辑)的电路结构图。通过对输入端(inputs)到与门之间的可编程阵列(programmable array)进行编程,利用PAL可以获得不同形式的组合逻辑函数。数字电路课程告诉我们,任何逻辑函数式都可以转化为若干乘积项(product tems)之和的形式,亦称“积之和”形式。通过对可编程阵列进行编程,与逻辑电路输出所需要的乘积项,再通过或逻辑电路将这些乘积项相加,就得到了最终的功能输出。然后该输出送给输出电路中的寄存器用于存储或者同步,当然也可以忽略寄存器直接输出。这就是PAL作为一种“可编程逻辑器件”能够实现不同逻辑功能的原理。
通过扩展SPLD的概念就可以得到CPLD。CPLD是复杂可编程逻辑器件,相当于将多个PAL用可编程互联阵列(Programmable Interconnect Array,PIA)连接起来,形成一个大的PLD,如下图所示:
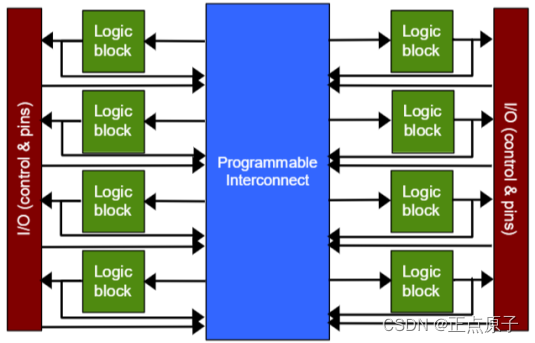
图 1.2.6 CPLD结构示意图
上图中的Logic block(逻辑块)通常被称为逻辑阵列模块,或者LAB(Logic Array Block)。每个LAB相当于一个PAL电路,不同型号的CPLD器件可以包含十几个甚至上百个LAB。通过PIA将这些LAB连接起来,就可以构成规模更大的逻辑电路了。另外,在PAL中,I/O管脚是直接连接到逻辑的。而在CPLD中,I/O管脚是通过PIA从器件的主要逻辑中分离出来的。I/O管脚有它自己的控制逻辑,I/O控制单元可以根据需要将相应的引脚设置成输入、输出或双向工作模式。
CPLD相对于SPLD最大的优势就是拥有更大的逻辑资源和布线的可能性。CPLD中LAB逻辑和PIA是完全可编程的,使得它具有在单芯片中非凡的设计灵活性。CPLD的I/O特性和功能也远比SPLD中简单的I/O更有价值。
FPGA是在PAL、GAL和CPLD等可编程逻辑器件的基础上进一步发展的产物,但是FPGA和其前辈CPLD有着非常大的差异。
FPGA由许多“可配置逻辑模块”(Configurable Logic Block,CLB)、输入/输出单元(I/O Block,IOB)和分布式的可编程互联矩阵(Programmable Interconnection Matrix,PIM)组成。在FPGA中,CLB被布置成阵列的形式,如图 1.2.7所示。可编程的布线资源分布在CLB与CLB之间,像大城市的街道一样纵横联接。这些布线资源分为行互联和列互联,可以跨过整个器件,也可以是局部CLB之间的互联。
我们将图 1.2.6与图 1.2.7进行对比可以发现,FPGA中的布线资源看上去似乎比CPLD中的互联阵列更简单,但它实际上提供了更大的功能性和连通性。FPGA中的布线资源使得器件中所有的逻辑资源都可以与芯片内其他资源进行通信,这种结构可以实现更大容量、低成本的逻辑器件。
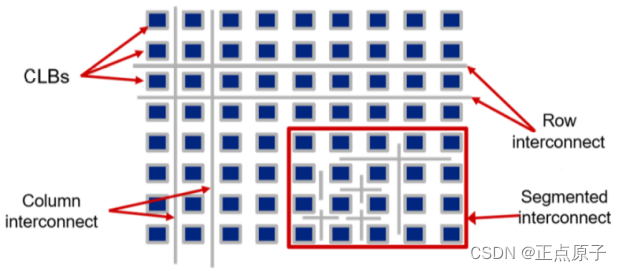
图 1.2.7 FPGA结构示意图
在前面所讲的各种SPLD和CPLD电路中,都采用了与或逻辑阵列加上输出逻辑单元的结构形式。而FPGA则采用了完全不同的电路结构形式(查找表,LUT),有关FPGA的结构我们将在本章ZYNQ PL简介中作详细介绍。
3) FPGA的用途
在介绍FPGA的用途之前,先给大家讲一个笑话:
话说一个资深工程师出国的时候带了一块FPGA开发板。
海关问道:“这是什么东西?”
工程师说:“FPGA开发板”。
海关又问:“FPGA是什么?”。
工程师回答说:“你想让它是什么,它就是什么(It can be whatever you want)”
能看懂这个笑话就说明你已经对FPGA有了一定的了解。作为一种可编程器件,FPGA能实现任何数字器件的功能,上至高性能CPU,下至简单的74电路,都可以用FPGA来实现。FPGA就像一张白纸,任由你在上面涂鸦或者作画;FPGA又如同一堆积木,随便你用来搭建城堡或者玩“过家家”。
FPGA是什么这个问题可能不太好回答。但是如果说FPGA用来干什么,那么答案就显而易见了。你可能都还没意识到,在我们的生活中,FPGA已经无处不在了。从你家里使用的高清电视,到附近的无线电接收塔;从银行门口的ATM机,到微软数据中心的服务器,都可以看到FPGA的身影。
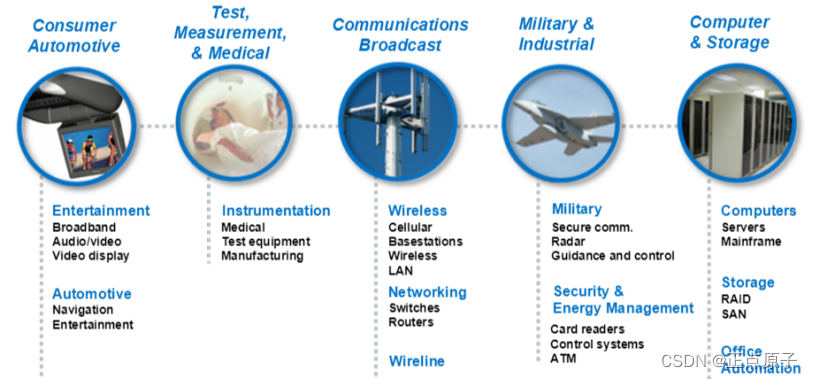
图 1.2.8 FPGA应用领域
如上图所示,FPGA广范应用在汽车、军用装备、图像处理、有线和无线通信、医药,以及工业控制等诸多领域。
可编程逻辑天生就为并行地实现算法提供了理想的资源。比如在图像处理中,要同时对大量的像素点进行数学运算,而FPGA就很适合像这种像素点级别的图像处理所需的快速、并行的操作。
FPGA并行的特性决定了它在某些特定行业应用上具有得天独厚的优势,例如在医疗领域。医学影像比普通图像纹理更多,分辨率更高,相关性更大。因此,为严格确保临床应用的可靠性,对图像的压缩、分割等预处理、图像分析及图像理解等要求更高。这些要求恰恰可以充分发挥FPGA的优势,通过FPGA加速图像压缩进程、删除冗余、提高压缩比、并确保图像诊断的可靠性。
在金融领域,由于采用流水线逻辑体系结构,数据流处理要求低延时,高可靠性。这在金融交易风险建模算法应用中是重要的关键点,而FPGA正具备了这种优势。类似的行业和领域还有很多,特别是在深度学习和神经网络,以及图像识别和自然语言处理等领域,FPGA正显示出其独有的优势。
1.3MPSoC PL简介
Zynq UltraScale+ MPSoC PL部分等价于FPGA,因此我们将首先介绍FPGA的架构。
简化的FPGA基本结构由6部分组成,分别为可编程输入/输出单元、基本可编程逻辑单元、嵌入式块RAM、丰富的布线资源、底层嵌入功能单元和内嵌专用硬核等,如下图所示:
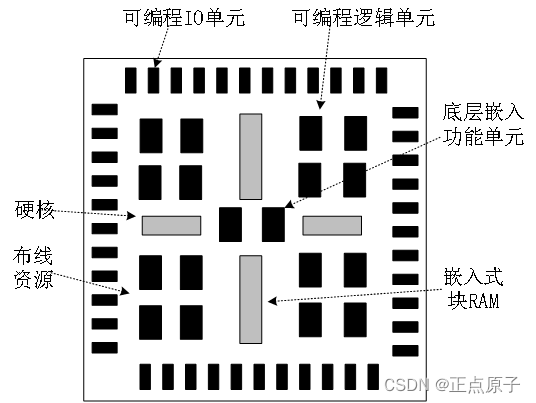
图 1.3.1 FPGA基本结构
每个单元的基本概念介绍如下。
- 可编程输入/输出单元
输入/输出(Input/Ouput)单元简称I/O单元,它们是芯片与外界电路的接口部分,完成不同电气特性下对输入/输出信号的驱动与匹配需求,为了使FPGA具有更灵活的应用,目前大多数FPGA的I/O单元被设计为可编程模式,即通过软件的灵活配置,可以适配不同的电气标准与I/O物理特性;可以调整匹配阻抗特性、上下拉电阻、以及调整驱动电流的大小等。
可编程I/O单元支持的电气标准因工艺而异,不同芯片商、不同器件的FPGA支持的I/O标准不同,一般来说,常见的电气标准有LVTTL,LVCMOS,SSTL,HSTL,LVDS,LVPECL和PCI等。值得一提的是,随着ASIC工艺的飞速发展,目前可编程I/O支持的最高频率越来越高,一些高端FPGA通过DDR寄存器技术,甚至可以支持高达2Gbit/s的数据数率。
Zynq UltraScale+ MPSoC上的通用输入/输出功能(IOB)合起来被称作SelectIO资源,每个I/O都是可配置的,可以遵循多种I/O标准。I/O分为高范围(high-range)、高性能(HP)和高密度(HD)三种类型。其中HR 类型提供最广泛的电压支持,从1.2V到3.3V。HP 类型支持1.0V到1.8V它对性能操作进行了优化。HD类型的IO一般一个BANK上由24个IO组成,能提供从1.2V到3.3V的电压支持。
所有的I/O引脚都封装在BANK中,每个BANK上可以封装52个HP引脚,或者52个HR引脚,或者24个HD引脚。每个BANK有一个公共的VCCO输出缓冲器电源,除了给输出缓冲器供电外也可以为输入缓冲器供电。此外,HR BANK可以一分为二,这两部分各自都有自己的VCCO供电。一些单端输入缓冲器需要一个内部产生的或外部应用的参考电压(VREF)。VREF引脚可以直接连接PCB,或者从FPGA内部产生。
所有输入和输出IO可以配置为组合型(wire)或注册型(reg)。所有输入和输出均支持DDR (Double data rate)。任何输入或输出都可以单独延迟高达1,250ps,分辨率为5-15ps,这种延迟被称为IDELAY和ODELAY。我们可以通过增减IODELAY的延迟步进进而调整IODELAY的延迟时间,也可以将IODELAY级联在一起,使单个方向上的延迟量增加一倍。
Zynq UltraScale+ MPSoC的IO资源还支持串并转换。每个I/O引脚拥有一个IOSERDES(ISERDES和OSERDES),能够执行2、4或8位可编程宽度的串行到并行或并行到串行转换。 - 基本可编程逻辑单元
基本可编程逻辑单元是可编程逻辑的主体,可以根据设计灵活地改变其内部连接与配置,完成不同的逻辑功能。FPGA一般是基于SRAM工艺的,其基本可编程逻辑单元几乎都是由查找表(LUT,Look Up Table)和寄存器(Register)组成。Xilinx UltraScale系列FPGA内部查找表可以配置为带有一个输出的6输入LUT,或者两个带有独立输出但共用输入的5输入LUT,查找表一般完成纯组合逻辑功能。FPGA内部寄存器结构相当灵活,可以配置为带同步/异步复位或置位的时钟使能触发器,也可以配置成锁存器,FPGA依赖寄存器完成同步时序逻辑设计。
一般来说,比较经典的基本可编程逻辑单元的配置是一个寄存器加一个查找表,但是不同厂商的寄存器与查找表也有一定的差异,而且寄存器与查找表的组合模式也不同。当然这些可编程逻辑单元的配置结构随着器件的不断发展也在不断更新,最新的一些可编程逻辑器件常常根据需求设计新的LUT和寄存器的配置比率,并优化其内部的连接构造。
例如,Altera可编程逻辑单元通常被称为LE(Logic Element),由一个寄存器加一个LUT构成。Altera大多数FPGA将10个LE有机地组合在一起,构成更大的功能单元——逻辑阵列模块(LAB,Logic Array Block)。LAB中除了LE还包含LE之间的进位链,LAB控制信号,局部互联线资源,LUT级联链,寄存器级联链等连线与控制资源。
Xilinx UltraScale系列FPGA中的可编程逻辑单元叫CLB(Configurable Logic Block,可配置逻辑块)每个CLB包含一个逻辑运算片(每个逻辑运算片包含8个LUT 16个寄存器)。逻辑运算片有两种类型,分别是SLICEL和SLICEM。SLICEM中的LUT可以配置为64位RAM、32位移位寄存器(SRL32)或两个16位移位寄存器。与上一代Xilinx设备中的CLB相比,UltraScale体系结构中的CLB增加了路由和连接性。并且UltraScale的CLB还有额外的控制信号去使能更大的寄存器封装,可以提高设备的利用率。 - 嵌入式块RAM
目前大多数FPGA都有内嵌的块RAM(Block RAM),FPGA内部嵌入可编程RAM模块,大大地拓展了FPGA的应用范围和使用灵活性。不同器件商或不同器件族的内嵌块RAM的结构不同,Lattice常用的块RAM大小是9Kbit;Altera的块RAM最灵活,一些高端器件内部同时含有3种块RAM结构,分别是M512 RAM,M4K RAM,M9K RAM。
每个基于UltraScale架构的设备都包含大量的36Kb块RAM(Block RAM,简称BRAM),可以配置为一个36Kb RAM或两个独立的18Kb RAM;每个块RAM都有两个完全独立的端口,且每个端口都可以读写数据,读写数据由时钟进行控制。每个块RAM列中有一个使能信号,这个信号能够让垂直相邻的块RAM之间级联,这样就可以创建大型、快速的存储阵列或者创建FIFO,而且大大降低了功耗。
对于RAM来说,所有输入的数据、地址、时钟使能信号和写入使能都会被寄存。比如说输入一个地址数据,这个地址数据就会被锁定(除非地址锁关闭)寄存,在下一次操作来临之前,地址寄存器的值是不会发生改变的。在写操作期间,也可以输出数据,输出的数据可以是先前存储的数据也可以是新写入的数据,当然在写操作期间也可以不输出数据。对于在设计中未使用的块RAM会自动关闭,以减少总功耗。在每个块RAM上还具有额外的引脚来控制动态功率的门控特性。
对于Xilinx UltraScale系列FPGA来说,除了具有BRAM资源外,还有一种UltraRAM 资源。UltraRAM是一种高密度、双端口、同步内存块,用于一些UltraScale+系列器件。这两个端口共用同一个时钟,可以处理4K x 72位的数据,每个端口都可以独立地对内存数组进行读写操作。UltraRAM支持两种类型的写操作方案,第一种模式与块RAM写操作模式一致;第二种模式允许控制数据的奇偶字节写入。多个UltraRAM块可以级联在一起创建更大的内存阵列。UltraRAM可以用专用的路径使整个列的存储区域连接在一起,这使得UltraRAM成为替代SRAM等外部存储器的理想解决方案,它可以灵活的支持级联从288Kb到36Mb的存储空间,用以满足许多不同的内存需求。 - 丰富的布线资源
布线资源连通FPGA内部的所有单元,而连线的长度和工艺决定着信号在连线上的驱动能力和传输速度。FPGA芯片内部有着丰富的布线资源,这些布线资源根据工艺、长度、宽度和分布位置的不同而划分为4类不同的类别:
第一类是全局布线资源,用于芯片内部全局时钟和全局复位/置位的布线;
第二类是长线资源,用以完成芯片Bank间的高速信号和第二全局时钟信号的布线;
第三类是短线资源,用于完成基本逻辑单元之间的逻辑互连和布线;
第四类是分布式的布线资源,用于专有时钟、复位等控制信号线。
在实际中设计者不需要直接选择布线资源,布局布线器可自动地根据输入逻辑网表的拓扑结构和约束条件选择布线资源来连通各个模块单元。从本质上讲,布线资源的使用方法和设计的结果有直接的关系。 - 底层嵌入功能单元
底层嵌入功能单元的概念比较笼统,这里我们指的是那些通用程度较高的嵌入式功能模块,比如PLL(Phase Locked Loop)、DLL(Delay Locked Loop)、DSP、CPU等。随着FPGA的发展,这些模块被越来越多地嵌入到FPGA的内部,以满足不同场合的需求。
目前大多数FPGA厂商都在FPGA内部集成了DLL或者PLL硬件电路,用以完成时钟的高精度、低抖动的倍频、分频、占空比调整、相移等功能。目前,高端FPGA产品集成的DLL和PLL资源越来越丰富,功能越来越复杂,精度越来越高。
另外,越来越多的高端FPGA产品将包含DSP或CPU等硬核,从而FPGA将由传统的硬件设计手段逐步过渡到系统级设计平台。例如Altera的Stratix IV、Stratix V等器件内部集成了DSP核;Xilinx的Virtes II和Virtex II pro系列FPGA内部集成了Power PC450的处理器。FPGA内部嵌入DSP或CPU等处理器,使FPGA在一定程度上具备了实现软硬件联合系统的能力,FPGA正逐步成为SOPC的高效设计平台。 - 内嵌专用硬核
这里的内嵌专用硬核与前面的底层嵌入单元是有区分的,这里讲的内嵌专用硬核主要指那些通用性相对较弱,不是所有FPGA器件都包含硬核。
在ZYNQ UltraScale的PL端和PS端各有一个系统监视模块——System Monitors,它就是一个硬核。System Monitors包含一个模数转换器(ADC),一个模拟多路复用器,片上温度和片上电压传感器等。我们可以利用这个模块监测芯片温度和供电电压,也可以用来测量外部的模拟电压信号。
1.4MPSoC PS简介
虽然我们在前面花费了大量的篇幅来介绍Zynq UltraScale+ MPSoC的PL部分,但是MPSoC实际上是一个以处理器为核心的系统,PL只是它的一个外设。MPSoC系列的亮点在于它包含了完整的ARM处理器系统,且处理器系统中集成了内存控制器和大量的外设,使Cortex-A53处理器可以完全独立于可编程逻辑单元。而且实际上在MPSoC中,PL和PS两部分的供电电路是独立的,这样PS或PL部分不被使用的话就可以被断电。
在前面我们介绍SOPC时提到过,FPGA可以用来搭建嵌入式处理器,像Xilinx的MicroBlaze处理器或者Altera的Nios II处理器。像这种使用FPGA的可编程逻辑资源搭建的处理器我们称之为“软核”处理器,它的优势在于处理器的数量以及实现方式的灵活性。
而MPSoC中集成的是一颗“硬核”处理器,它是硅芯片上专用且经过优化的硬件电路,硬核处理器的优势是它可以获得相对较高的性能。另外,MPSoC中的硬件处理器和软核处理器并不冲突,我们完全可以使用PL的逻辑资源搭建一个Microblaze软核处理器,来和ARM硬核处理器协同工作。
MPSoC处理器系统集成了Arm Cortex-A53和Arm Cortex-R5F内核处理器,并且像EG、EV器件还集成了图像处理单元,再加上丰富的外设接口,可以说MPSoC的PS端是一个非常优秀的片上系统。那么接下来我们一起来了解一下Zynq UltraScale+ MPSoC的PS端。
首先我们先来看一下Zynq UltraScale+ MPSoC PS端的结构框图(这里以EV器件为例),如下图所示:
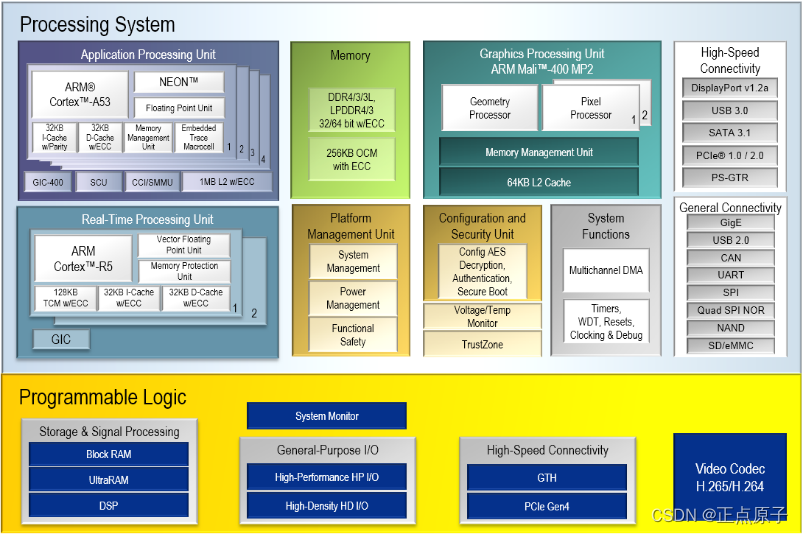
图 1.4.1 PS端结构框图
从上面的结构图中可以很清楚的看到MPSoC的结构,它分为PS和PL两部分。在PS部分中它主要由Arm Cortex-A53(APU共4个核)、Arm Cortex-R5F(RPU共两个核)以及Arm Mali-400 MP2(GPU)三种内核处理器构成,并且还包括DDR控制单元、平台管理单元、高速外设控制器以及普通外设控制器等外设组成。下面我们来详细的讲解一下每个部分的功能。
- APU(Application Processing Unit)
APU主要是由两个或者四个ARM处理器核组成的,Cortex-A53核心是基于Arm-v8A架构的32位/64位应用程序处理器,拥有极佳的性能/功率比,每一个Cortex-A53核心拥有32KB指令和数据L1缓存,具有奇偶校验、ECC保护、NEON SIMD引擎、单精度和双精度浮点单元。除了这些模块,APU还有一个snoop控制单元以及一个带ECC保护的1MB L2缓存,这样的设计可以更好的提高系统级的性能。该APU还具有内置的中断控制器支持虚拟中断。它的结构框图如下所示:
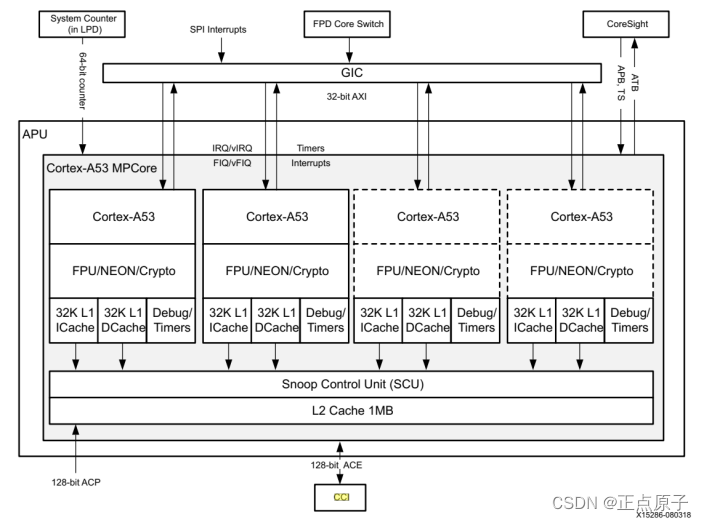
图 1.4.2 APU内核框图
2) RPU(Real-Time Processing Unit)
PS中的RPU包含一个双核Arm Cortex-R5F 处理器,Cortex-R5F是32位实时处理器,它是基于Arm-v7R架构的处理器内核。每个Cortex-R5F核都有32KB的指令和数据缓存(L1),除了L1缓存,每个Cortex-R5F核心还具有128KB的紧耦合内存(TCM)接口,用于实时单周期访问。RPU还有一个专用的中断控制器。两个RPU既可工作在独立模式,也可以工作在同步模式。在独立模式中两个处理器都是独立运行的;在同步模式下,它们彼此并行运行,逻辑资源也会综合到一起,并且TCM资源也整合成256KB。RPU还可以通过AXI-4端口与PS端的LPD区域进行通信或者与PL端进行低延迟通信。支持实时DEBUG和信号跟踪,每个内核还具有一个嵌入式跟踪宏单元(ETM)方便Arm内核调试。
Cortex-R5处理器是用于深度嵌入式实时系统的CPU,它采用了Thumb-2技术以获得最佳的代码密度和处理吞吐量,它还具有一个算术逻辑单元(ALU),为了更加有效地利用其他资源(例如寄存器资源),算术逻辑单元会执行有限的双重指令。Cortex-R5处理器会通过重新启动和加载多个指令来保持较低的中断延迟,并且还会使用一个专用的外围端口来实现对中断控制器的低延迟访问。处理器具有紧密耦合内存(TCM)端口,用于低延迟和确定性地访问本地RAM。错误检查和纠正功能(ECC)是用于Cortex-R5 处理器端口和 Level 1 (L1) 存储器的,这样可以提高系统的可靠性和准确性。Cortex-R5处理器的结构框图如下所示:
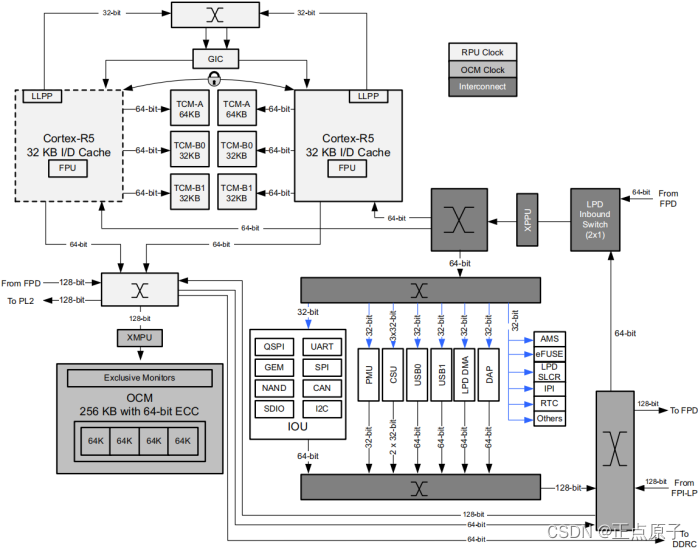
图 1.4.3 Cortex-R5处理器框图
3) GPU(Graphics Processing Unit)
GPU是基于Arm Mali - 400 MP2硬件加速器的2D和3D图形子系统。它由一个几何图形处理器(GP)、两个像素处理器(PP)、64KB L2缓存控制器(L2)、针对GP和每个PP的独立内存管理单元(MMU)以及128位AXI总线接口构成。Arm Mali-400 MP2 作为PS专用的图形处理器它可以支持2D和3D图形加速,最高分辨率为1080p,对于3D图形它能够支持OpenGL ES 1.1 and 2.0规范而对于2D的矢量图形它只能支持Open VG 1.1标准。它的几何处理器(GP)和2个像素处理器会并行地执行贴图渲染操作。它为GP和像素处理器提供了专用的内存管理单元,支持4 KB的页面大小。
GPU还有64KB的二级(L2)只读缓存,它支持4X和16X全场景抗锯齿(FSAA)功能。它有内置的硬件纹理解压缩,允许纹理在图形硬件中保持压缩(ETC格式),并在运行中解压所需的样本。它还支持在不消耗额外带宽的情况下有效地混合多个硬件层,它的像素填充率为200万像素/秒/MHz,三角形填充率为0.1Mvertex/秒/MHz。GPU支持广泛的纹理格式为RGBA 8888、565、1556以及YUV格式,对于功率敏感的应用,GPU支持对每个GP、像素处理器和L2缓存的时钟和功率进行门控。在功率门控过程中,GPU不消耗任何静态或动态功率;在时钟门控过程中,它只消耗静态电源。
4) DDR Memory Controller
DDR存储控制器通过六个AXI数据接口和一个AXI控制接口连接到MPSoC的其余部分,其中一条数据路径连接到实时处理单元(RPU),两条数据路径连接到缓存相干互连(CCI-400),其他的在DisplayPort控制器、FPD、DMA和编程逻辑(PL) 上多路复用。在6个接口中,5个是128位宽,而第6个接口(绑定到RPU)是64位宽。DDR子系统支持DDR3、DDR3L、LPDDR3、DDR4和LPDDR4,它可以通过AXI总线接口接收来自6个应用主机端口的读写请求,这些请求在内部排队访问DRAM设备。存储器控制器在DDR PHY接口上向PHY模块发出命令,PHY模块从DRAM中读取和写入数据。DDR Memory Controller的结构如下图所示:
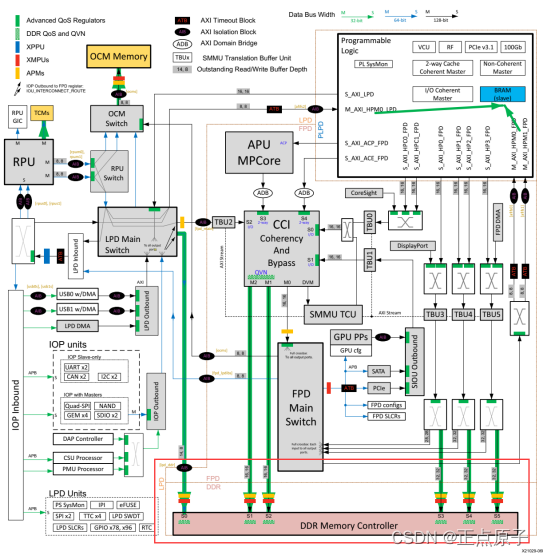
图 1.4.4 DDR Memory Controller
5) PMU(Platform Management Unit)
Zynq UltraScale+ MPSoC包括一个专用的用户可编程处理器,用于电源、错误管理的平台测量单元(PMU)处理器,以及用于功能安全应用的可选软件测试库(STL)。由于PMU的结构和配置相当复杂这里我们只简要列出他的功能,更加详细的介绍大家可以参考Xilinx官方文档ug1085。
PMU的功能如下:
1、使用系统监视器检查电源水平,以确保CSU和LP域的其余部分正常运行。
2、初始化pll的默认配置和他们潜在的旁路。
3、触发和排序必要的扫描和MBIST。
4、捕获并发出错误信号,错误ID可以通过JTAG读取。
5、释放复位到CSU。
6、在应用程序和实时处理器处于睡眠状态时充当它们的委托,并在接收到它们的唤醒请求之后对他们进行开机和重启。
7、在任何时候维护系统电源状态。
8、处理不同块的上电、下电、复位、内存内置自修复(MBISR)、MBIST和扫描归零所需的低级事件序列。
9、在休眠模式下管理系统,并基于各种触发机制唤醒系统。
10、PS-level错误捕获。
6)High-Speed Connect
Zynq UltraScale+ MPSoC的PS端集成了5个高速外设,分别是DP控制器、USB3.0控制器、SATA3.1控制器、PCIE 1.0/2.0控制器以及PS-GTR收发器。下面我们来分别介绍一下这几个高速控制器。
1、DP接口(DisplayPort控制器):Zynq UltraScale+ MPSoC的PS端集成了DisplayPort控制器,它可以从内存(非实时输入)或(实时输入)可编程逻辑(PL)中获取数据,并将这些数据处理过后通过DisplayPort源控制器块输出到外部显示设备或PL(实时输出)上。DisplayPort控制器由DMA、缓冲区管理器、显示渲染块、音频混音块、DisplayPort源控制器以及PS-GTR模块组成,它可以支持超高清(UHD)视频,因此DP接口常用来做视频图像传输的接口。
2、USB3.0:USB 3.0控制器由两个独立的DRD (dual-role device)控制器组成,两者都可以单独配置为在任何给定时间作为主机或从机设备工作。USB 3.0 DRD控制器通过高级的可扩展AXI从接口,可以为系统软件提供一个可扩展的主控制器接口(xHCI)。控制器中有一个内部的DMA引擎,它利用AXI主接口来传输数据。三个双端口RAM的配置可以实现RX数据FIFO、TX数据FIFO和描述符/寄存器缓存功能,AXI主端口与协议层可以通过缓冲区管理单元访问不同的RAM。
3、SATA3.1:SATA控制器是一种高性能双端口主机控制器,具有AHCI兼容的命令层,该命令层对使用端口乘法器的系统来说,具有支持基于本地命令队列和帧信息结构(FIS)交换的高级功能。SATA使用ATA/ATAPI命令集,但是通过不同的导线可以实现与SATA第1代、第2代或第3代相对应的1.5、3.0或6.0 Gb/sec的速率进行串行通信。串行数据采用8B/10B编码,确保数据模式中有足够的转换以确保直流平衡(这里的转换指数据的0/1转换,关于直流平衡的知识大家可以自行了解或者看我们HDMI相关的视频,其中有涉及),并使时钟数据恢复电路能够从输入数据模式中提取时钟。
4、PCIe 1.0/2.0控制器:MPSoC集成了一个PCIe通信控制器,用于实现PCIe的通信,它包含AXI-PCIe桥和DMA组件,AXI-PCIe桥主要是为PCIe和AXI提供高性能桥接。模块示意图如下所示:
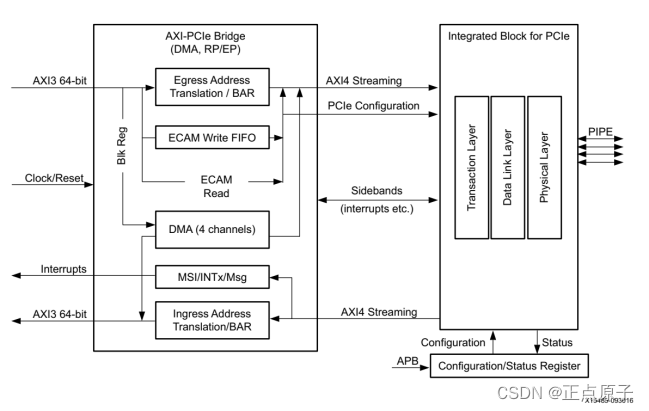
图 1.4.5 PCIe控制器框图
从上图中可以看到控制器由两个子模块组成,其中PCIe桥的主要功能除了将PCIe协议与AXI协议相互转换外还可以转换入口/出口地址,为DMA和Root Port/Endpoint (RP/EP)模式切换提供特定的服务。
5、PS-GTR收发器:千兆GTR收发器为串行输入输出单元(SIOU)的外围设备、媒体访问控制器(mac)以及它们的高速通信链路提供专用的I/O。Zynq UltraScale+ MPSoC共有四个可编程高速收发器,可以支持数据速率高达6gb /s的子层协议。
7)普通外设控制器
Zynq UltraScale+ MPSoC的PS端除了集成的高速通信外设之外,还有一些普通的低速外设,其中包括GigE、USB2.0、CAN、UART、SPI、Quad SPI NOR、NAND以及SD/eMMC等外设控制器。关于这些常见的外设控制器这里就不再一一讲解了,这些外设我们在后面的学习中大多数都会用到,大家可以在后面的实战篇中学习到这些内容。
8)PS-PL AXI接口
MPSoC将高性能ARM Cotex-A系列处理器与高性能FPGA在单芯片内紧密结合,为设计带来了如减小体积和功耗、降低设计风险,增加设计灵活性等诸多优点。在将不同工艺特征的处理器与FPGA融合在一个芯片上之后,片内处理器与FPGA之间的互联通路就成了MPSoC芯片设计的重中之重。如果Cotex-A53与FPGA之间的数据交互成为瓶颈,那么处理器与FPGA结合的性能优势就不能发挥出来。
Xilinx从Spartan-6和Virtex-6系列开始使用AXI协议来连接IP核。在7系列、Zynq-7000和Zynq UltraScale+ MPSoC器件中,Xilinx在IP核中继续使用AXI协议。AXI的英文全称是Advanced eXtensible Interface,即高级可扩展接口,它是ARM公司所提出的AMBA(Advanced Microcontroller Bus Architecture)协议的一部分。
AXI协议是一种高性能、高带宽、低延迟的片内总线,具有如下特点:
1、总线的地址/控制和数据通道是分离的;
2、支持不对齐的数据传输;
3、支持突发传输,突发传输过程中只需要首地址;
4、具有分离的读/写数据通道;
5、支持显著传输访问和乱序访问;
6、更加容易进行时序收敛。
在数字电路中只能传输二进制数0和1,因此可能需要一组信号才能高效地传输信息,这一组信号就组成了接口。AXI4协议支持以下三种类型的接口:
1、AXI4:高性能存储映射接口。
2、AXI4-Lite:简化版的AXI4接口,用于较少数据量的存储映射通信。
3、AXI4-Stream:用于高速数据流传输,非存储映射接口。
在这里我们首先解释一下存储映射(Meamory Map)这一概念。如果一个协议是存储映射的,那么主机所发出的会话(无论读或写)就会标明一个地址。这个地址对应于系统存储空间中的一个地址,表明是针对该存储空间的读写操作。
AXI4协议支持突发传输,主要用于处理器访问存储器等需要指定地址的高速数据传输场景。AXI-Lite为外设提供单个数据传输,主要用于访问一些低速外设中的寄存器。而AXI-Stream接口则像FIFO一样,数据传输时不需要地址,在主从设备之间直接连续读写数据,主要用于如视频、高速AD、PCIe、DMA接口等需要高速数据传输的场合。
在PS和PL之间的主要连接是通过一组12个AXI接口,每个接口有多个通道组成。这些形成了PS内部的互联以及与PL的连接,如下图所示:
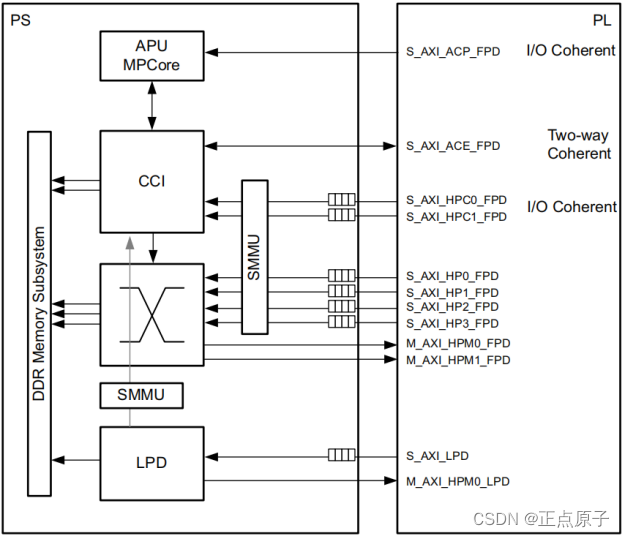
图 1.4.6 PS与PL 的AXI互联
我们将上图中的接口总结如下所示:
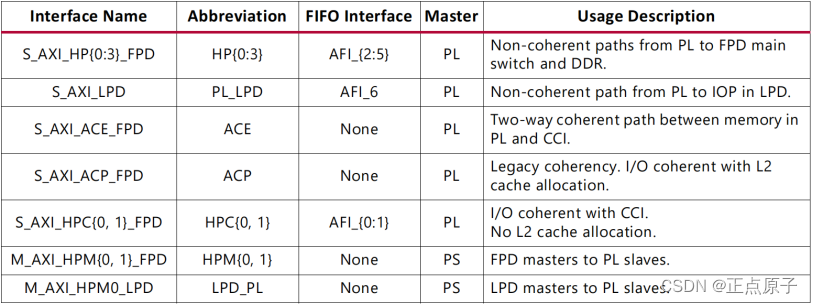
图 1.4.7 PS与PL的AXI接口
上图给出了每个接口的简述,标出了主机是PL还是PS(按照惯例,主机是控制总线并发起会话的,而从机是做响应的)。需要注意的是,接口命名的第一个字母表示的是PS的角色,也就是说,第一个字母 “M” 表示 PS 是主机,而第一个字母“S”表示 PS 是从机。
S_AXI_HP{0:3}_FPD/S_AXI_HPC{0,1}_FPD:六个PL侧高性能(High Performance)AXI主接口连接到PS侧的FPD(Full-power domain),主要用于访问DDR内存,进行大量数据的传输,如摄像头图像数据等。所有的六个高性能AXI主接口都经过了PS中的SMMU(System Memory Management Unit),SMMU能够使用物理和虚拟地址转换。其中一致性S_AXI_HPC接口连接到了CCI(Cache-coherent interconnect),可以访问L1和L2 Cache,也正是连接到了CCI,所以在访问DDR控制器时,相比于S_AXI_HP接口来说,延时会较大。
S_AXI_LPD:主机PL连接至从机PS侧LPD(Low-power domain)的高性能AXI接口,它能够低延时地访问OCM(On-chip Memory)和TCM(Tightly-coupled Memory)。
S_AXI_ACE_FPD:主机PL与从机PS中的CCI相连接,它能够支持PS和PL中的硬件块之间的完全一致性(双向)。该接口使用的是ACE(AXI coherency extension)协议,与AXI接口相比,ACE协议使用了五个额外的通道,三个通道用于监听,两个用于应答。
S_AXI_ACP_FPD:该接口实现了PL和PS之间的低延时访问,PL端可以直接访问APU的L1和L2 Cache以及DDR内存。
M_AXI_HPM{0,1}_FPD:该高性能接口由主机PS侧FPD连接至从机PL,可以用于CPU、 DMA、PCIe等传输大量数据到PL。
M_AXI_HPM0_LPD:该高性能接口由主机PS侧LPD连接至从机PL,该接口适合于为PS中的LPD主机(例如LP-DMA)提供对PL中的存储器的访问,也经常用于配置 PL 端的寄存器。
上面的每条总线都是由一组信号组成的,这些总线上的会话是根据AXI4总线协议进行通信的。有关AXI4协议更详细的内容,我们将在后续的章节进行介绍。
到这里关于Zynq UltraScale+ MPSoC芯片的PS端内容就讲解完了,更多的内容大家可以参考Xilinx官方文档ug1085进行学习。

