
- 1mysql中文问号,没有my.ini,只有my-defaule.ini,查找修改并保存my.ini_my-default.ini和my.ini
- 2VMware 服务器安装银河麒麟Linux详细讲解_esxi装麒麟
- 3uos系统安装教程_统一操作系统UOS个人版安装体验
- 4C# WPF学习总结
- 5Lnton羚通算法算力云平台预防高空坠物,打造天台安全防范监测场景解决方案
- 6nginx是什么以能做什么及其基本概念_口述基础概念,nginx是什么,能做什么,为什么我们需要使用它?
- 7【李宏毅机器学习2020】Basic Concept 基础概念(p4) 学习笔记_basic concept (lab1) - comp6203 intelligent agents
- 8openpyxl 打开大文件很慢_与xlrd相比,使用openpyxl读取Excel文件的速度要慢一些
- 9【C++】STL 容器 - vector 动态数组容器 ⑦ ( 迭代器 iterator 基本原理 | 迭代器 iterator 分类 | 双向迭代器 | 随机访问迭代器|迭代器正向遍历与逆向遍历 )_vector迭代器的作用
- 10开源模型应用落地-qwen1.5-7b-chat与vllm实现推理加速的正确姿势(八)
是换脸还是数字分身
赞
踩
之前给大家分享过很多stable diffusion插件,比如roop,lora等等,这些都可以生成特定面部的图片,比如roop可以换脸,lora可以训练特定面容的模型,但是这些都有一个比较明显的缺点,prompt比较难调,生成出来的照片的光照有时也会不自然,另外就是lora的训练需要比较多的图片,出来的效果也不尽人意。
那么是不是有什么方法可以不需要prompt,然后借助已有的图片去生成更加自然的特定面部的图片呢,包括已有图片的环境光等参数都可以复刻。
今天给大家带来一款生成数字分身的sd插件-----EasyPhoto
EasyPhoto 是一个 Webui UI 插件,用于生成 AI 肖像,可用于训练与某个特定人相关的数字分身。只需要用5到20张人像图片进行训练,当然最好是半身照片并且不戴眼镜(少数图片中的人物戴眼镜也没关系)。训练完成后,就可以在推理部分生成图片。
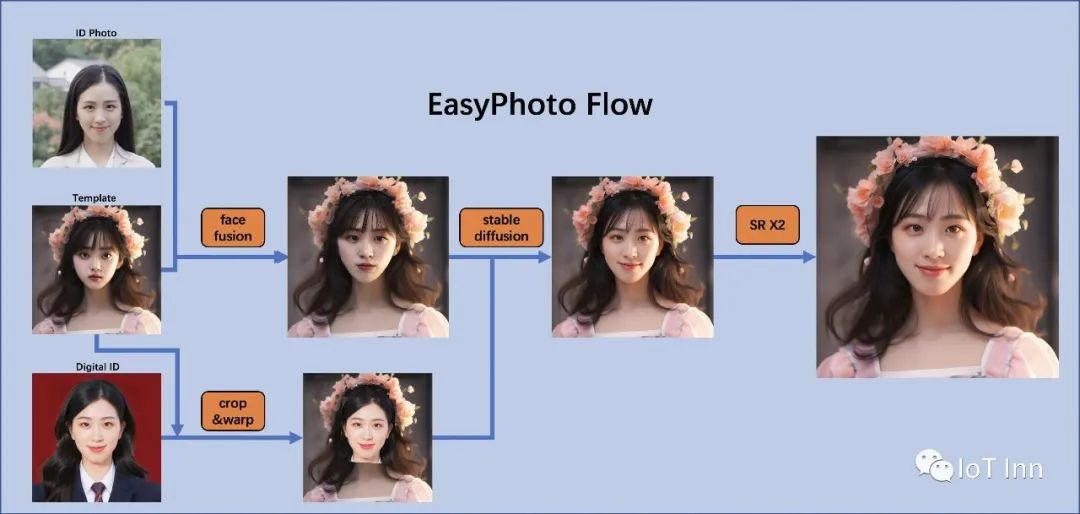
在人工智能肖像领域,我们期望人工智能模型生成的图像是真实且类似于用户的,但是用传统方法引入不真实的光照(例如面部融合或人脸)。为了解决这种不现实的问题,easyphoto引入了稳定扩散模型的图像到图像功能。生成完美的个人肖像由两部分组成:生成场景和用户的数字分身。首先使用预先准备好的模板作为所需的生成场景,然后使用在线训练的人脸 LoRA 模型作为用户的数字分身,这是一种流行的稳定扩散微调模型。然后使用少量的用户图像来训练稳定的用户数字分身,最终在推理过程中根据人脸LoRA模型和预期生成场景来生成个人肖像图像。
那么这个模型需要怎么训练呢?
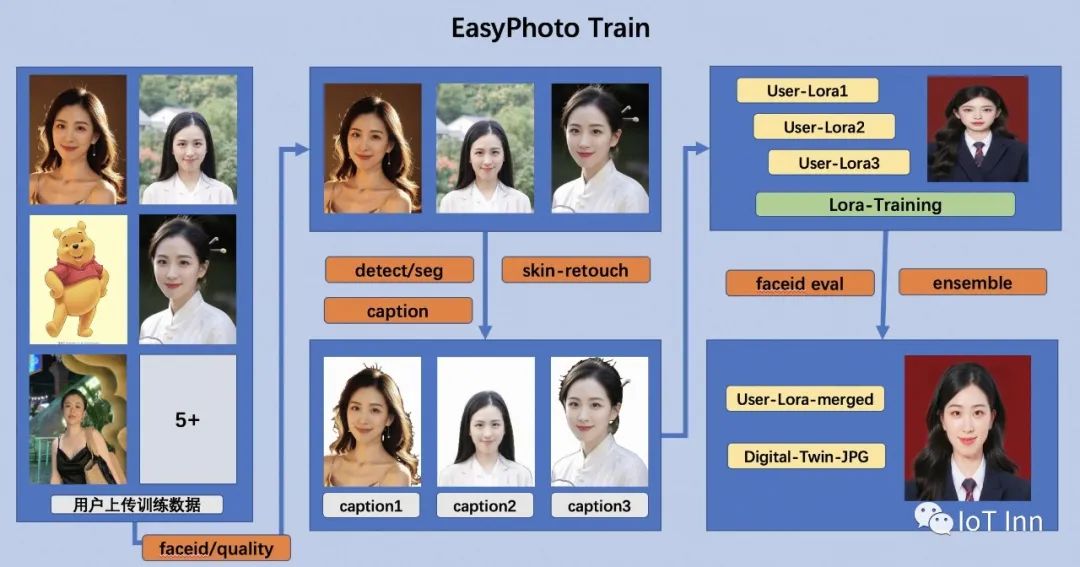
首先,对输入的用户图像进行人脸检测,确定人脸位置后,按照一定的比例截取图像。然后使用显著性检测模型和皮肤美化模型来获得干净的人脸图像,该图像基本上仅由人脸组成。然后,用固定标签标记每个图像。最后,用微调稳定扩散模型以获得用户的数字分身。
在训练过程中,利用模板图像进行实时验证,在训练结束时,计算验证图像与用户图像之间的人脸ID差距,以实现Lora融合,这样就确保了Lora是完美的数字分身用户的。
另外,在验证中选择与用户最相似的图像作为face_id图像,该图像将在Inference中使用。
最后就是推理,主要分为两步:
第一次扩散:首先,对传入的模板图像执行人脸检测,以确定需要修复的掩模来实现稳定的扩散。然后我们将使用模板图像与最佳用户图像进行人脸融合。人脸融合完成后,使用上面的掩模与人脸融合图像进行inpaint(fusion_image)。另外,将训练时得到的最优face_id图像通过仿射变换(replaced_image)贴到模板图像上。然后将在其上应用Controlnets,这里使用带有颜色的canny为fusion_image提取特征,并为replaced_image使用openpose以确保图像的相似性和稳定性。最后使用Stable Diffusion结合用户的数字分割进行生成。
第二次扩散:得到First Diffusion的结果后,将结果与最优的用户图像进行人脸融合,然后再次使用Stable Diffusion与用户的数字分身进行生成。进而生成更高分辨率的图像。
话不多说,我们正式开启体验之旅:
首先打开stable diffusion,然后打开扩展标签-->从网址安装
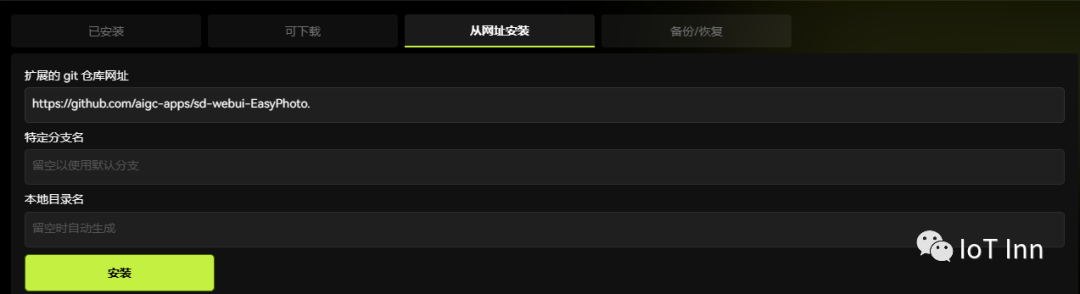
安装完成后,切换到已安装标签,然后点击应用并重新加载前端,这是我们就可以看到easyphoto的标签页
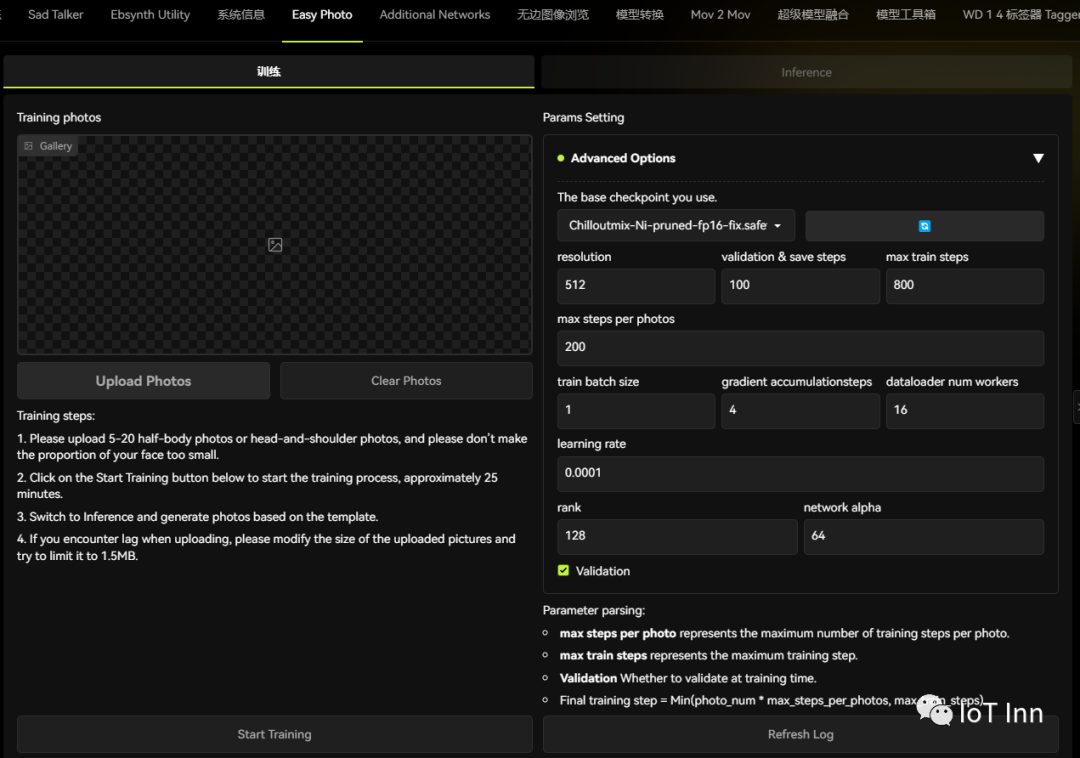
接下来的操作也很简单,选择5张图像上传





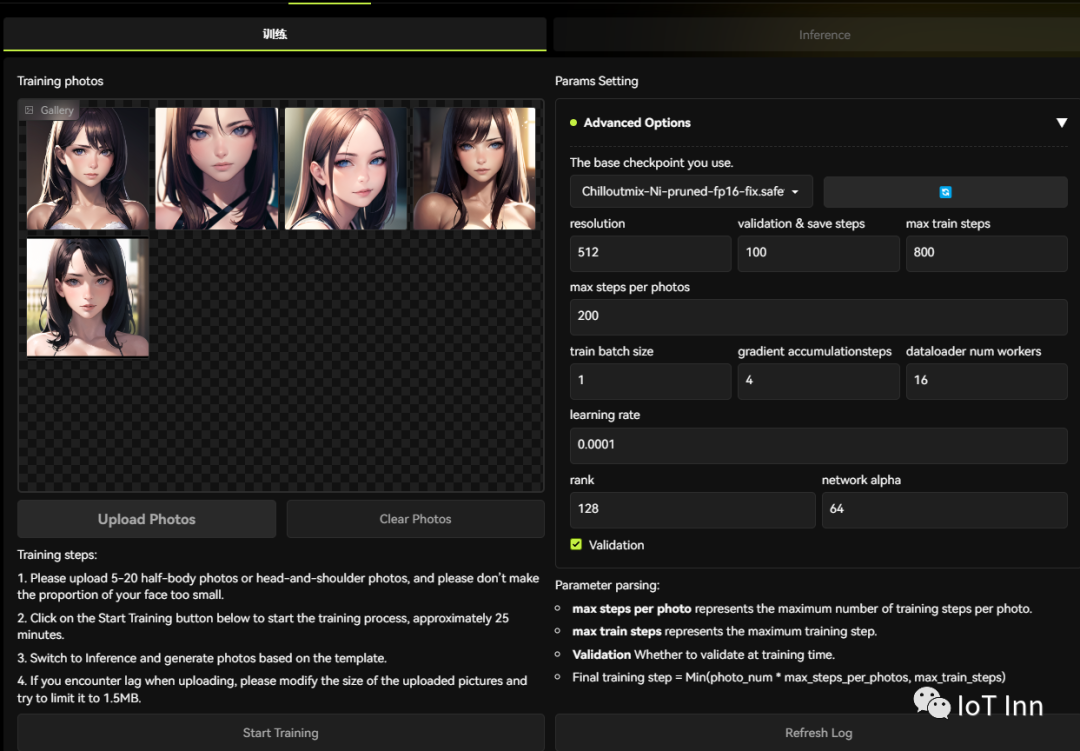
然后点击start training,需要一段时间,我这显卡一般,跑了将近一个小时吧。然后我们切换到inference标签,选择我们之前训练的模型以及提供的一些样图。
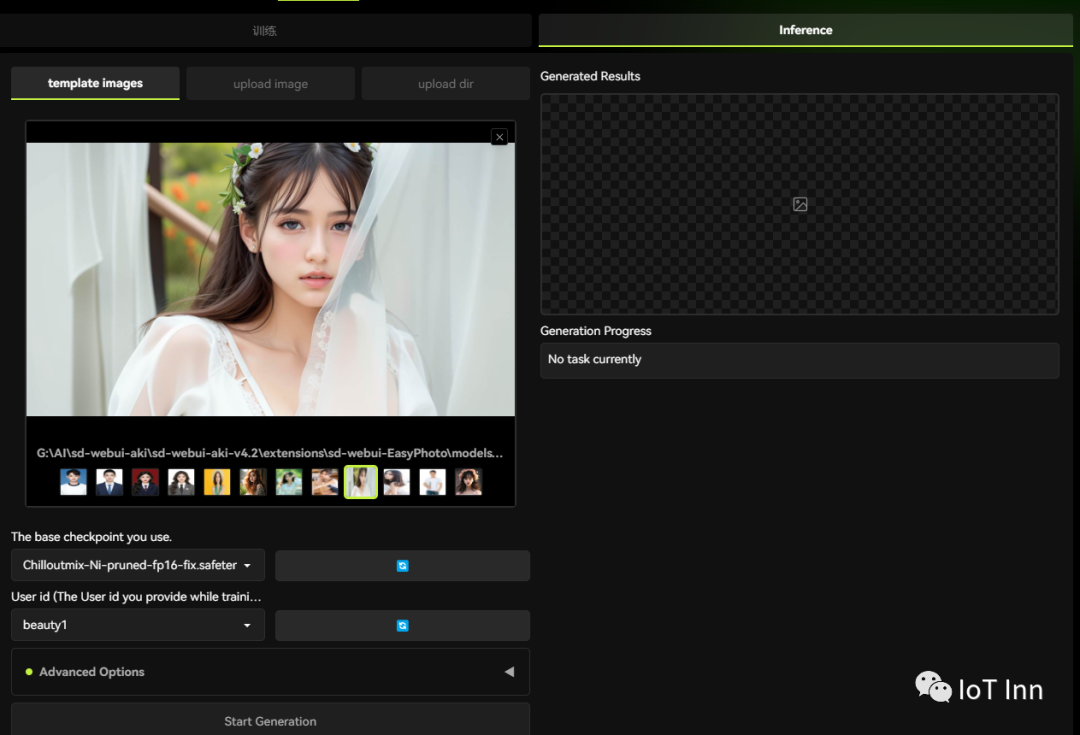
然后点击start generation,最后生成结果如下:

结果还是很惊艳的,人脸完美融合的同时,环境、光照的引入也很自然。相对来说就是速度比较慢,看后台显存也没吃满,可能就是单纯的步骤比较繁琐吧。
感兴趣的小伙伴赶紧来制作自己的数字分身吧

