
热门标签
热门文章
- 1在Docker中部署GreatSQL并构建MGR集群_docker-compose在三个虚机节点上部署mgr
- 2微信支付回调多次_微信支付回调频率
- 3最完整的ubuntu安装nvidia显卡驱动教程,亲测避坑!
- 4AI特训一:为什么要学习AI
- 5Win10 LTSB/LTSC安装微软商店/Microsoft store_win10ltsb powershell应用
- 6对比了最常见的几家开源OCR框架,我发现了最好的开源模型_ocr大模型
- 7app微信支付 php回调接口,App微信支付之php后台接口详解
- 8STM32HAL库学习笔记三——GPIO的HAL库编程_stm32 hal库 引脚模式
- 9为你的目标检测添加GUI可视化(Python)_pythongui实现监控图形化界面
- 10Caused by: java.lang.ClassNotFoundException常见异常解决方法
当前位置: article > 正文
(四)优化函数,学习速率与反向传播算法--九五小庞
作者:小丑西瓜9 | 2024-03-03 14:22:41
赞
踩
(四)优化函数,学习速率与反向传播算法--九五小庞
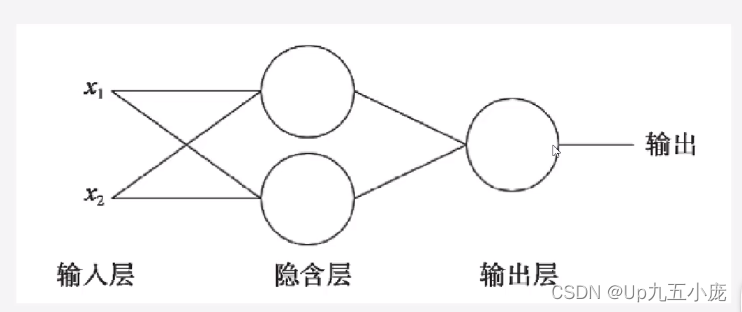
多层感知器
梯度下降算法
- 梯度的输出向量表明了在每个位置损失函数增长最快的方向,可将它视为表示了在函数的每个位置向那个方向移动函数值可以增长。

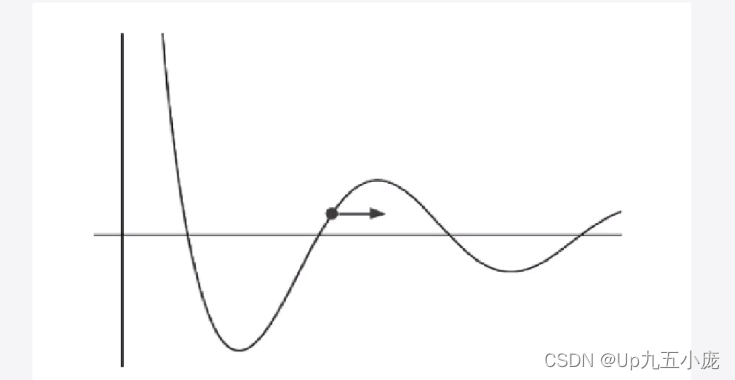
- 曲线对应于损失函数。点表示权值的当前值,即现在所在的位置。
- 梯度用箭头表示,表明为了增加损失,需要向右移动。此外,箭头的长度概念化地表示了如果在对应的方向移动,函数值能够增长多少。如果向着梯度的反方向移动,则损失函数的值会相应减少。
学习速率
- 梯度就是表明损失函数相对参数的变化率,对梯度进行缩放的参数被称为学习速率(learning rate)或可称之为步长
- 学习速率是一种超参数或对模型的一种手工可配置的设置,需要为它指定正确的值。如果学习速率太小,则找到损失函数极小值点时可能需要许多轮迭代;如果太大,则算法可能会“跳过”极小值点并且因为周期性的“跳跃”而永远无法找到极小值点。
- 在具体实践中,可通过查看损失函数值随时间变化曲线,来判断学习速率的选取是否合适
- 合适的学习速率,损失函数随时间下降,直到一个底部,不合适的学习速率,损失函数可能会发生震荡
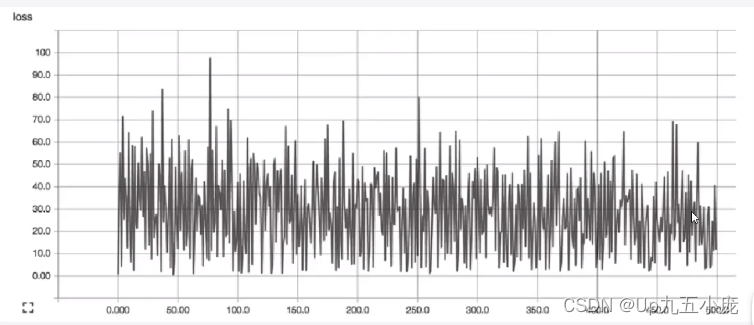
学习速率选取原则
- 在调整学习速率时,既要使其足够小,保证不至于发生超调,也要保证它足够大,以使损失函数能够尽快下降,从而可通过较少次数的迭代更快的完成学习
反向传播算法
- 反向传播算法是一种高效计算数据流图中梯度的技术,每一层的导数都是后一层的导数与前一层输出之积,这正是链式法则的奇妙之处,误差反向传播算法利用的正是这一特点。
- 前馈时,从输入开始,逐一计算每个隐含层的输出,直到输出层。
- 然后开始计算导数,并从输出层经各隐含层逐一反向传播。为了减少计算量,还需对所有已完成计算的元素进行复用。这便是反向传播算法名称的由来。
常见的优化函数
- 优化器(optimizer)是编译模型的所需要的两个参数之一。
- 可以先实例化一个优化器对象,然后将它传入model.compile(),或者你可以通过名称来调用优化器。在后一种情况下,将使用优化器的默认参数。
SGD:随机梯度下降优化器
- 随机梯度下降优化器SGD和min-batch是同一个意思,抽取m个小批量(独立同分布)样本,通过计算他们平梯度均值。
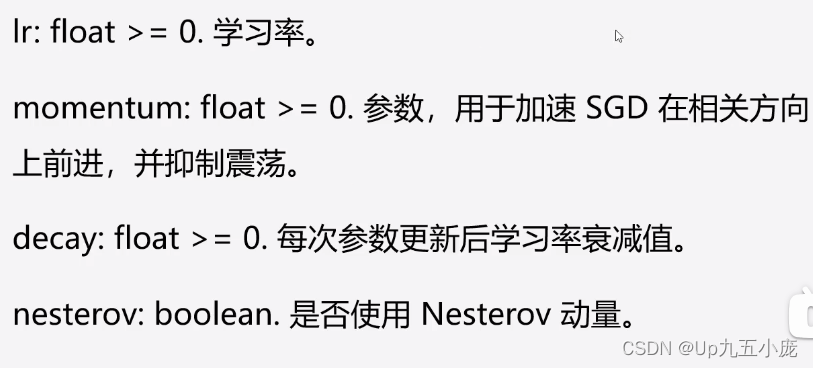
SGD参数
RMSprop:网络优化算法
- 经验上,RMSprop被证明有效且使用的深度学习网络优化算法
- RMSprop增加了一个衰减系数来控制历史信息的获取多少,RMSprop会对学习率进行衰减。
- 建议使用优化器的默认参数(除了学习率lr,它可以被自由调节)
- 这个优化器你通常是训练循环神经网络RNN的不错选择。
Adam:Momentum+RMSprop
- Adam算法可以看做是修正后的Momentum+RMSprop算法
- Adam通常被认为对超参数选择相当鲁棒
- 学习率建议为0.0001
- Adam是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代的更新神经网络权重。
- Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/184881
推荐阅读
相关标签

