
热门标签
热门文章
- 1微信小程序获取当前日期时间_微信小程序获取当前时间
- 2零基础学python:超详细的入门教程!_python入门教程(非常详细)
- 3Retail_HikariCP - Exception during pool initialization_hikaricp - exception during pool initialization.
- 4目标检测新SOTA:YOLOv9 问世,新架构让传统卷积重焕生机
- 5计算机知识体系图谱总结_计算机科学课程体系的核心内容图表
- 6零基础C/C++开发到底要学什么?_c++软件开发需要学什么
- 7Selenium浏览器自动化测试框架详解
- 8python 绘制混淆矩阵( confusion matrix)_imshow confusion matrix
- 9vue.js毕业设计,基于vue.js前后端分离图书购物商城系统(H5移动项目) 开题报告_基于vue的网上商城开题报告关键问题
- 10计算机毕业设计选题基于Uniapp+springboot助农管理系统App[源码+文档+答疑+远程
当前位置: article > 正文
爬取房天下新房、二手房房源数据(scrapy-redis分布式爬虫)_爬虫抓取房天下
作者:小丑西瓜9 | 2024-03-05 17:04:18
赞
踩
爬虫抓取房天下
前言
该项目基于Scrapy-Redis框架实现分布式爬虫。其中,我使用了自身电脑(win10)作为redis服务器, WSL虚拟机和一台mac作为爬虫服务器,从而实现分布式爬虫。
环境搭建
- 开发环境:Win10(WSL-Ubuntu、VBox-Ubuntu) + PyCharm(VSCode) + Cmder + XShell
- scrapy-redis分布式爬虫需要安装scrapy-redis包
- WSL环境的搭建可参考我写的博文:打造Win10+WSL开发环境【图文】
- 打开终端,转到项目目录输入以下命令,即可快速整理出环境所需包
pip freeze -r requirements
- 将该项目发送到Slave端,虚拟机建议使用XShell或者配置好的的共享文件夹,在爬虫服务器上安装环境所需包
pip install -r requirements.txt
注意点
关于房天下的爬虫网络上有很多,但是实际运行后,会有一些问题。比如,目前房天下的城市房源页面加入了广告页,这是爬取过程中不需要的数据,如果不处理,会直接报错,停止爬虫运行。

因此,该项目中针对运行过程中遇到的问题进行了代码的优化。
改造成分布式爬虫
- 首先安装scrapy-redis
- 将爬虫的类从 scrapy.Spider 变成 scrapy_redis.spiders.RedisSpider
- 将爬虫中的start_urls删掉。增加一个redis_key=“xxx”。这个redis_key是为了以后在redis中控制爬虫启动的。爬虫的第一个url,就是在redis中通过这个发送出去的

- 更改scrapy的配置文件,将爬虫的去重交由redis完成,并将结果存储至redis
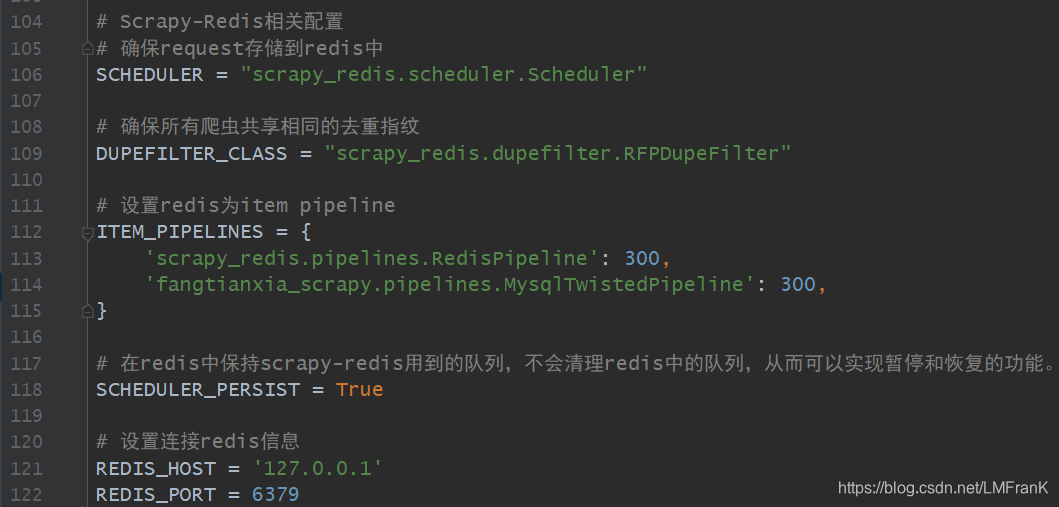
如果redis服务器需求密码,应添加REDIS_PASSWORD='your password’项,这里提供另外一种方式,一行命令即可,即REDIS_URL:
REDIS_URL=‘redis://:password@ip:port’
运行爬虫:
- 在爬虫服务器上,进入爬虫文件所在的路径,然后输入命令:
scrapy runspider 爬虫名
不再是scrapy crawl 爬虫名
- 在Redis服务器上,推入一个开始的url链接:
redis-cli> lpush [redis_key] start_url
开始爬取
NOTE:
- 如果设置了LOG_FILE,那么爬虫报错时,终端只会出现:
Unhandled error in Deferred

此时,应进入.log文档内查看错误
- 查看防火墙是否阻挡连接,redis设置远程连接时,应注释掉redis.conf里的"bind 127.0.0.1"字段
源代码
具体的项目可以在我的github上查看,欢迎指正
下面展示几个主要的代码
- spider.py
# -*- coding: utf-8 -*- import scrapy import re from fangtianxia_scrapy.items import NewHouseItem, EsfHouseItem from scrapy_redis.spiders import RedisSpider class FangSpider(RedisSpider): name = 'fang' allowed_domains = ['fang.com'] # start_urls = ['https://www.fang.com/SoufunFamily.htm'] redis_key = 'fang:start_urls' def parse(self, response): trs = response.xpath('//div[@class="outCont"]//tr') province = None for tr in trs: tds = tr.xpath('.//td[not(@class)]') province_td = tds[0] province_text = province_td.xpath('.//text()').get() province_text = re.sub(r'\s', '', province_text) if province_text: province = province_text # 不爬取海外城市的房源 if province == '其它': continue city_td = tds[1] city_links = city_td.xpath('.//a') for city_link in city_links: city = city_link.xpath('.//text()').get() # 台湾url地址与其他不同 if '台湾' in city: continue # 北京二手房页面会重定向至本地,还未解决该问题 if '北京' in city: continue city_url = city_link.xpath('.//@href').get() city_text = re.findall('.*//(.*).*.fang', city_url)[0] # 构建新房的url链接 newhouse_url = 'https://' + city_text + '.newhouse.fang.com/house/s/' # 构建二手房的url链接 esf_url = 'https://' + city_text + '.esf.fang.com' yield scrapy.Request( url=newhouse_url, callback=self.parse_newhouse, meta={'info': (province, city)} ) yield scrapy.Request( url=esf_url, callback=self.parse_esf, meta={'info': (province, city)} ) def parse_newhouse(self, response): # 新房 province, city = response.meta.get('info') lis = response.xpath('//div[contains(@class,"nl_con clearfix")]/ul/li') for li in lis: name_text = li.xpath('.//div[@class="nlcd_name"]/a/text()').get() name = name_text.strip() # 页面中插入了广告页li,需要剔除 if name: house_type_list = li.xpath('.//div[contains(@class, "house_type")]/a/text()').getall() house_type_list = list(map(lambda x: re.sub(r'/s', '', x), house_type_list)) house_type = ','.join(list(filter(lambda x: x.endswith('居'), house_type_list))) area_text = ''.join(li.xpath('.//div[contains(@class, "house_type")]/text()').getall()) area = re.sub(r'\s|-|/', '', area_text) address = li.xpath('.//div[@class="address"]/a/@title').get() district_text = ''.join(li.xpath('.//div[@class="address"]/a//text()').getall()) try: district = re.search(r'.*\[(.+)\].*', district_text).group(1) except: district = 'None' sale = li.xpath('.//div[contains(@class, "fangyuan")]/span/text()').get() price = "".join(li.xpath(".//div[@class='nhouse_price']//text()").getall()) price = re.sub(r"\s|广告", "", price) detail_url_text = li.xpath('.//div[@class="nlc_img"]/a/@href').get() detail_url = response.urljoin(detail_url_text) item = NewHouseItem(province=province, city=city, name=name, house_type=house_type, area=area, address=address, district=district, sale=sale, price=price, detail_url=detail_url) yield item next_url = response.xpath('//div[@class="page"]//a[class="next"]/@href').get() if next_url: yield scrapy.Request(url=response.urljoin(next_url), callback=self.parse_newhouse, meta={'info': (province, city)}) def parse_esf(self, response): # 二手房 province, city = response.meta.get('info') dls = response.xpath('//div[@class="shop_list shop_list_4"]/dl') for dl in dls: item = EsfHouseItem(province=province, city=city) name = dl.xpath('.//span[@class="tit_shop"]/text()').get() # 页面中插入了广告页li,需要剔除 if name: infos = dl.xpath('.//p[@class="tel_shop"]/text()').getall() infos = list(map(lambda x: re.sub(r"\s", "", x), infos)) for info in infos: if "厅" in info: item["house_type"] = info elif '㎡' in info: item["area"] = info elif '层' in info: item["floor"] = info elif '向' in info: item["orientation"] = info elif '年建' in info: item["year"] = re.sub("年建", "", info) item["address"] = dl.xpath('.//p[@class="add_shop"]/span/text()').get() item["total_price"] = "".join(dl.xpath(".//span[@class='red']//text()").getall()) item["unit_price"] = dl.xpath(".//dd[@class='price_right']/span[2]/text()").get() item["detail_url"] = response.urljoin(dl.xpath(".//h4[@class='clearfix']/a/@href").get()) item["name"] = name # 以下五个字段大概率会缺失,存入mysql会报错,因此加入判断 if 'house_type' not in item: item["house_type"] = '/' elif 'area' not in item: item["area"] = '/' elif 'floor' not in item: item["floor"] = '/' elif 'orientation' not in item: item["orientation"] = '/' elif 'year' not in item: item["year"] = '/' yield item next_url = response.xpath('//div[@class="page_al"]/p/a/@href').get() if next_url: yield scrapy.Request(url=response.urljoin(next_url), callback=self.parse_esf, meta={'info': (province, city)})

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class NewHouseItem(scrapy.Item): province = scrapy.Field() city = scrapy.Field() name = scrapy.Field() house_type = scrapy.Field() area = scrapy.Field() address = scrapy.Field() district = scrapy.Field() sale = scrapy.Field() price = scrapy.Field() detail_url = scrapy.Field() class EsfHouseItem(scrapy.Item): province = scrapy.Field() city = scrapy.Field() name = scrapy.Field() house_type = scrapy.Field() area = scrapy.Field() floor = scrapy.Field() orientation = scrapy.Field() year = scrapy.Field() address = scrapy.Field() total_price = scrapy.Field() unit_price = scrapy.Field() detail_url = scrapy.Field()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- middlewares.py
主要是随机请求头
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware import random class RotateUserAgentMiddleware(UserAgentMiddleware): # for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 " "(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 " "(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 " "(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 " "(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 " "(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 " "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] def process_request(self, request, spider): ua = random.choice(self.user_agent_list) if ua: # 显示当前使用的useragent # print("********Current UserAgent:%s************" % ua) # 记录 spider.logger.info('Current UserAgent: ' + ua) request.headers['User-Agent'] = ua
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- pipelines.py
这里提供两种pipeline:存储为json文件和利用twisted框架异步存储数据到mysql
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.exporters import JsonLinesItemExporter from fangtianxia_scrapy.items import NewHouseItem, EsfHouseItem from twisted.enterprise import adbapi import pymysql class FangTianXiaScrapyPipeline(object): def __init__(self): self.newhouse_fp = open('newhouse.json', 'ab') self.esfhouse_fp = open('esfhouse.json', 'ab') self.newhouse_exporter = JsonLinesItemExporter(self.newhouse_fp, ensure_ascii=False) self.esfhouse_exporter = JsonLinesItemExporter(self.esfhouse_fp, ensure_ascii=False) def process_item(self, item, spider): if isinstance(item, NewHouseItem): self.newhouse_exporter.export_item(item) elif isinstance(item, EsfHouseItem): self.esfhouse_exporter.export_item(item) return item def close_spider(self, spider): self.newhouse_fp.close() self.esfhouse_fp.close() class MysqlTwistedPipeline(object): def __init__(self, dbpool): self.dbpool = dbpool @classmethod def from_settings(cls, settings): db_params = dict( host=settings['MYSQL_HOST'], database=settings['MYSQL_database'], user=settings['MYSQL_USER'], passwd=settings['MYSQL_PASSWORD'], port=settings['MYSQL_PORT'], charset='utf8mb4', use_unicode=True, cursorclass=pymysql.cursors.DictCursor ) dbpool = adbapi.ConnectionPool('pymysql', **db_params) return cls(dbpool) def process_item(self, item, spider): query = self.dbpool.runInteraction(self.do_insert, item) query.addErrback(self.handle_error, item, spider) return item def handle_error(self, failure, item, spider): print(failure) def do_insert(self, cursor, item): if isinstance(item, NewHouseItem): insert_sql = """insert into fangtianxia.newhouse(province, city, name, house_type, area, address, district, sale, price, detail_url) Values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s);""" cursor.execute(insert_sql, ( item['province'], item['city'], item['name'], item['house_type'], item['area'], item['address'], item['district'], item['sale'], item['price'], item['detail_url'])) elif isinstance(item, EsfHouseItem): insert_sql = """insert into fangtianxia.esfhouse(province, city, name, house_type, area, floor, orientation, year, address, total_price, unit_price, detail_url) Values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);""" cursor.execute(insert_sql, ( item['province'], item['city'], item['name'], item['house_type'], item['area'], item['floor'], item['orientation'], item['year'], item['address'], item['total_price'], item['unit_price'], item['detail_url']))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- settings.py
# -*- coding: utf-8 -*- # Scrapy settings for fangtianxia_scrapy project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'fangtianxia_scrapy' SPIDER_MODULES = ['fangtianxia_scrapy.spiders'] NEWSPIDER_MODULE = 'fangtianxia_scrapy.spiders' MYSQL_USER = 'root' MYSQL_PASSWORD = 'password' MYSQL_DATABASE = 'fangtianxia' MYSQL_HOST = 'localhost' MYSQL_PORT = 3306 # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'fangtianxia_scrapy (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = False LOG_FILE = 'scrapy.log' # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'fangtianxia_scrapy.middlewares.FangtianxiaScrapySpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { # 'fangtianxia_scrapy.middlewares.FangtianxiaScrapyDownloaderMiddleware': 543, 'fangtianxia_scrapy.middlewares.RotateUserAgentMiddleware': 543, } # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html # ITEM_PIPELINES = { # 'fangtianxia_scrapy.pipelines.FangTianXiaScrapyPipeline': 300, # 'fangtianxia_scrapy.pipelines.MysqlTwistedPipeline': 300, # } # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' # Scrapy-Redis相关配置 # 确保request存储到redis中 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 确保所有爬虫共享相同的去重指纹 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 设置redis为item pipeline ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 300, 'fangtianxia_scrapy.pipelines.MysqlTwistedPipeline': 300, } # 在redis中保持scrapy-redis用到的队列,不会清理redis中的队列,从而可以实现暂停和恢复的功能。 SCHEDULER_PERSIST = True # 设置连接redis信息 REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 REDIS_PASSWORD = 'password'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
小结
分布式爬虫的速度非常快,而且即使一个slave因为反爬等问题挂掉了,也不影响整体运行。后续会尝试加入BloomFilter等方式优化爬虫。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/192561
推荐阅读
相关标签

