
- 1linux内核 fault-injection_linux ras故障注入
- 2计算机科学数学理论浅谈_请谈谈你对“计算机科学中的数学”的理解或认知。
- 3解决! 华为鸿蒙安装Google Play,GMS三件套,设备未获得Play保护机制认证。(越过谷歌play保护机制认证,解除Google play保护机制弹窗)_此设备未获得play保护机制认证
- 4数学建模方法——SPSS主成分分析法_数学模型重要性排序
- 5gitlab提交代码失败,提示这是一个受保护的分支_remote: gitlab: you are not allowed to push code t
- 6阿里云SLB负载均衡配置方法(云起实验室)_slb负载均衡权重范围
- 7java conversion_java.util.UnknownFormatConversionException: Conversion = ''';
- 8docker-compose 中 volumes、environment、privileged、network_mode的使用_docker-compose privileged
- 9设置ssh免密登录出现问题:/usr/bin/ssh-copy-id: ERROR: ssh: connect to host : Connection timed out
- 10穿越迷雾:AI写作的深度探索与未来展望
池化层(pooling)
赞
踩
目录
一、池化层

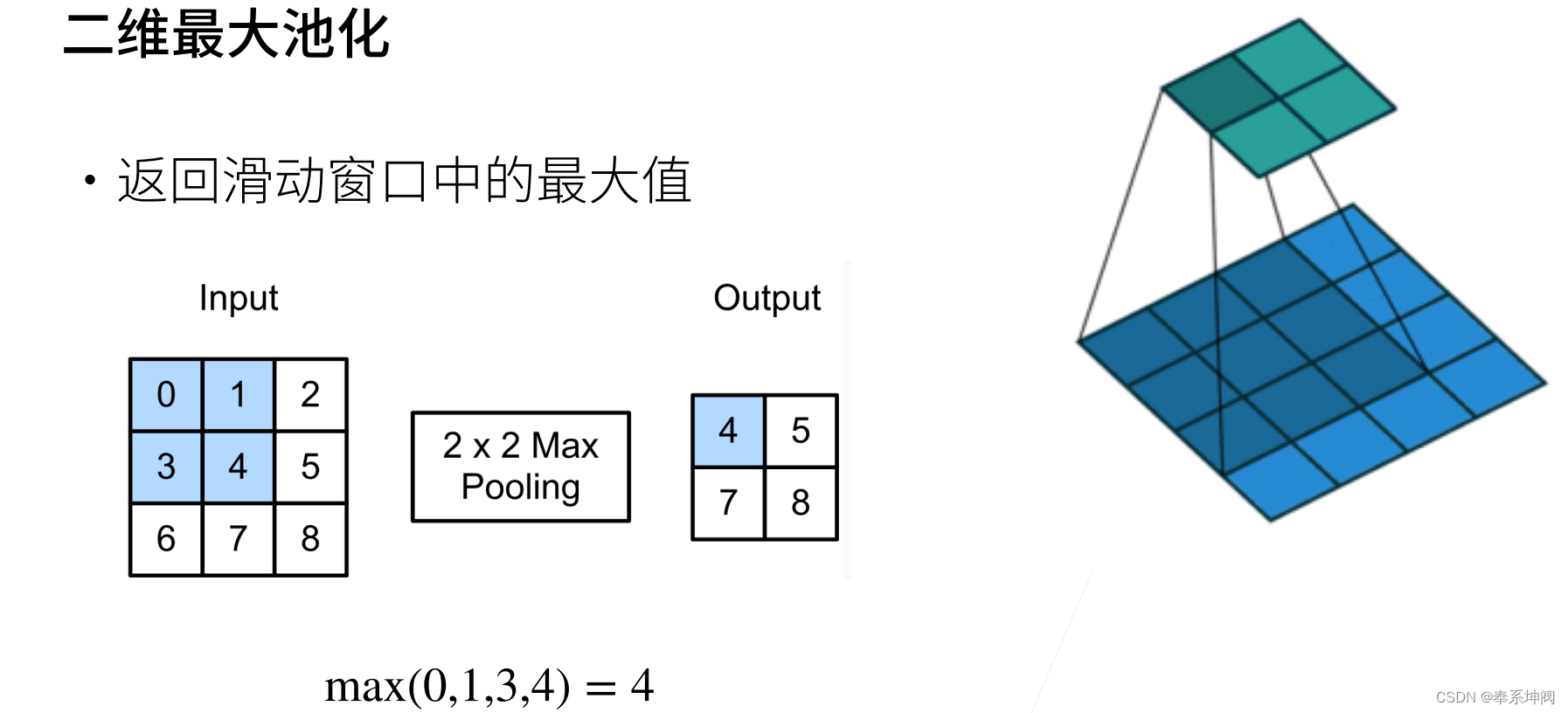
1、最大池化层


2、平均池化层

3、总结
- 池化层返回窗口中最大或平均值
- 环节卷积层对位置的敏感性
- 同样有窗口大小、填充和步幅作为超参数
二、代码实现
通常当我们处理图像时,我们希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着我们在神经网络中层叠的上升,每个神经元对其敏感的感受野(输入)就越大。
而我们的机器学习任务通常会跟全局图像的问题有关(例如,“图像是否包含一只猫呢?”),所以我们最后一层的神经元应该对整个输入的全局敏感。通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有优势保留在中间层。
1、最大池化与平均池化
在下面的代码中的`pool2d`函数,我们实现池化层的前向传播。然而,这里我们没有卷积核,输出为输入中每个区域的最大值或平均值。
- import torch
- from torch import nn
- from d2l import torch as d2l
- def pool2d(X, pool_size, mode='max'):
- p_h, p_w = pool_size # 池化核的尺寸
- Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)) # 由输入尺寸核池化核的尺寸得到输出的尺寸
- for i in range(Y.shape[0]):
- for j in range(Y.shape[1]):
- if mode == 'max': # 最大池化
- Y[i, j] = X[i: i + p_h, j: j + p_w].max()
- elif mode == 'avg': # 平均池化
- Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
- return Y
我们可以构建下图中的输入张量`X`,验证二维最大汇聚层的输出。
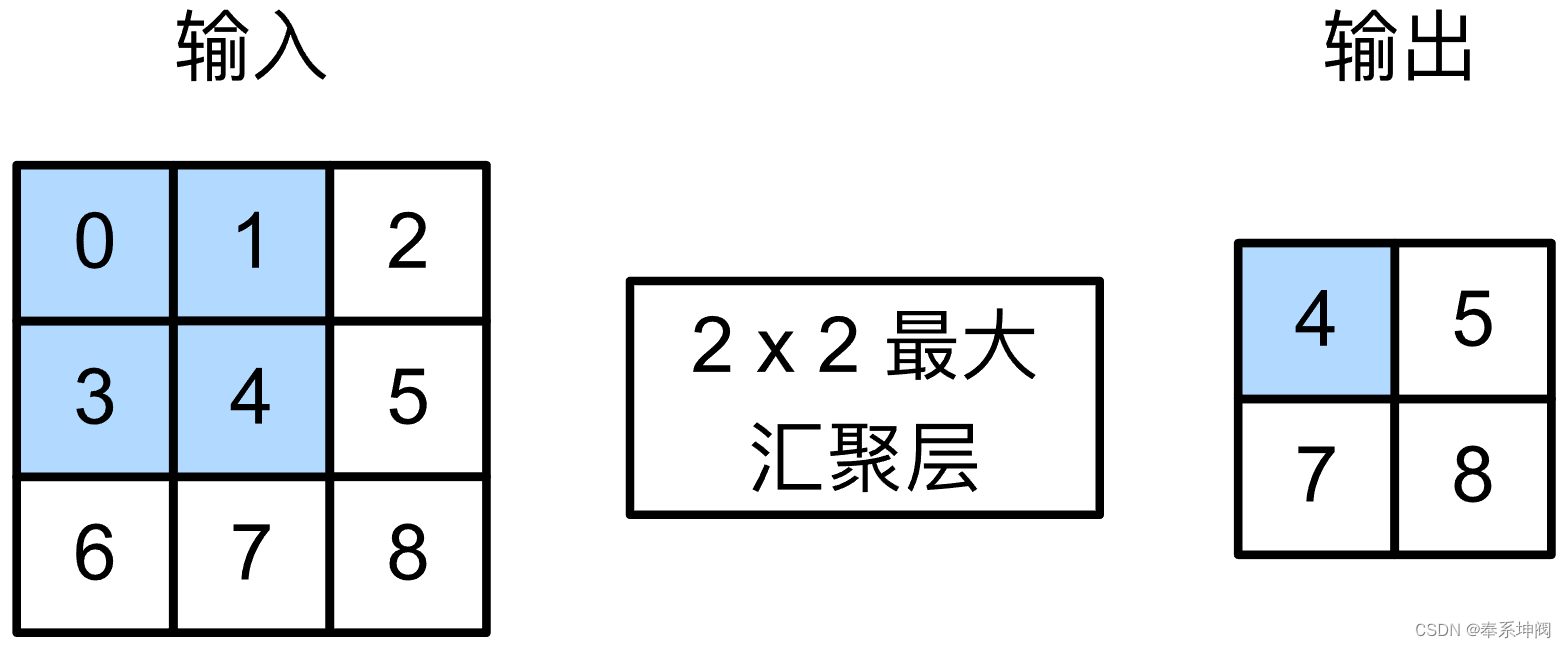
- X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
- pool2d(X, (2, 2))
- tensor([[4., 5.],
- [7., 8.]])
此外,我们还可以验证平均汇聚层。
pool2d(X, (2, 2), 'avg')- tensor([[2., 3.],
- [5., 6.]])
2、填充和步幅(padding和strides)
与卷积层一样,池化层也可以改变输出形状,我们可以通过填充和步幅以获得所需的输出形状。下面,我们用深度学习框架中内置的二维最大池化层,来演示池化层中填充和步幅的使用。我们首先构造了一个输入张量`X`,它有四个维度,其中样本数和通道数都是1。
- X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4)) # (样本数, 通道数, 高, 宽)
- print(X)
- tensor([[[[ 0., 1., 2., 3.],
- [ 4., 5., 6., 7.],
- [ 8., 9., 10., 11.],
- [12., 13., 14., 15.]]]])
默认情况下,深度学习框架中的步幅与池化窗口的大小相同。因此,如果我们使用形状为`(3, 3)`的汇聚窗口,那么默认情况下,我们得到的步幅形状为`(3, 3)`。
- pool2d = nn.MaxPool2d(3) # 使用形状为(3, 3)的池化窗口,于是默认使用步幅形状为(3, 3)
- pool2d(X)
tensor([[[[10.]]]])填充和步幅可以手动设定。
- pool2d = nn.MaxPool2d(3, padding=1, stride=2)
- pool2d(X)
- tensor([[[[ 5., 7.],
- [13., 15.]]]])
当然,我们可以设定一个任意大小的矩形汇聚窗口,并分别设定填充和步幅的高度和宽度。
- pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
- pool2d(X)
- tensor([[[[ 5., 7.],
- [13., 15.]]]])
3、多个通道
在处理多通道输入数据时,池化层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总。这意味着池化层的输出通道数与输入通道数相同。下面,我们将在通道维度上连结张量`X`和`X + 1`,以构建具有2个通道的输入。
- X = torch.cat((X, X + 1), 1) # 在通道维度叠加,因此是1
- print(X)
- print(X.shape)
- tensor([[[[ 0., 1., 2., 3.],
- [ 4., 5., 6., 7.],
- [ 8., 9., 10., 11.],
- [12., 13., 14., 15.]],
-
- [[ 1., 2., 3., 4.],
- [ 5., 6., 7., 8.],
- [ 9., 10., 11., 12.],
- [13., 14., 15., 16.]]]])
- torch.Size([1, 2, 4, 4])
如下所示,池化后输出通道的数量仍然是2。
- pool2d = nn.MaxPool2d(3, padding=1, stride=2)
- print(pool2d(X))
- print(X.shape)
- tensor([[[[ 5., 7.],
- [13., 15.]],
-
- [[ 6., 8.],
- [14., 16.]]]])
- torch.Size([1, 2, 4, 4])
4、总结
- 最大池化层会输出该窗口内的最大值,平均池化层会输出该窗口内的平均值。
- 池化层的主要优点之一是减轻卷积层对位置的过度敏感。
- 我们可以指定池化层的填充和步幅。
- 使用最大池化层以及大于1的步幅,可减少空间维度(如高度和宽度)。
- 池化层的输出通道数与输入通道数相同。



