
- 11.6 Photoshop网格的使用 [Ps教程]_对复制生成的第二个礼物盒执行的是()操作。
- 2linux进程间的7种通信方式全解析及代码示例_linux线程和进程间通信方式
- 3mysql 索引(为什么选择B+ Tree?)
- 4WIN11下连不上车机ADB解决方案1
- 5数据库作业10:第三章课后题_数据库disp和dist
- 6git reset
- 7远程操作手机竟如此简单?掌握这些技巧,事半功倍!_怎么实现手机远程操作手机
- 8YOLOV5 + 双目测距(python)_yolov5双目测距
- 9napi原理和实现-数据包接收-提高网络处理效率技术-poll轮询函数_napi_schedule
- 10未来 Android 开发的从业方向_安卓开有什么方向
模型部署到移动端_飞桨实战笔记:自编写模型如何在服务器和移动端部署
赞
踩

作为深度学习小白一枚,从一开始摸索如何使用深度学习框架,怎么让脚本跑起来,到现在开始逐步读懂论文,看懂模型的网络结构,按照飞桨官方文档进行各种模型训练和部署,整个过程遇到了无数问题。非常感谢飞桨开源社区的大力支持,并热情答复我遇到的各种问题,使得我可以快速上手。特整理本篇学习笔记,以此回馈网友们的无私付出。大家都共享一点点,一起为深度学习的推进添砖加瓦(哈哈,非常正能量,有木有!)
这篇文章详细记录了如何使用百度深度学习平台——飞桨进行SSD目标检测模型的训练、以及如何将模型部署到服务器和移动端。文末给出了笔者认为非常有用的资料链接。
本文的代码基于百度AI Studio官方示例代码,并能够在飞桨 1.7.1上跑通,Python版本是3.7。
SSD模型介绍
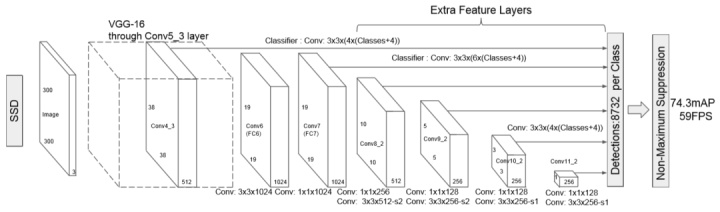
如果你对经典的CNN模型比较熟悉的话,那么SSD也并不难理解。SSD大体上来说是将图片分为6种不同大小的网格,找到目标中心的落点,确定物体的位置。在分成不同网格之后,会在此之上取到不同数目的先验框,对先验框进行回归、分类预测。先验框的数目足够多,几乎能够涵盖整个图片,因此我们可以找到包含物体的很多个先验框,最后进行非极大抑制就能得到正确结果。
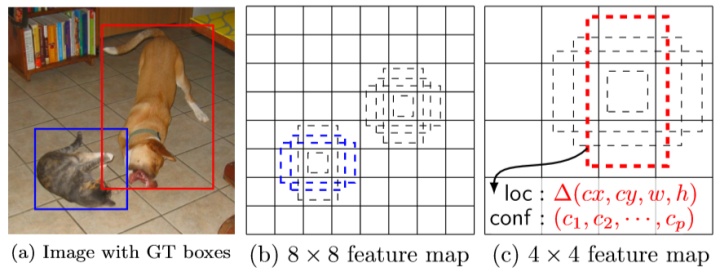
b图就是我们以每个网格为中心,取到的先验框的示例。c图的回归预测找到了目标的位置信息,分类预测确定了物体的类别。a图代表了最终的结果。
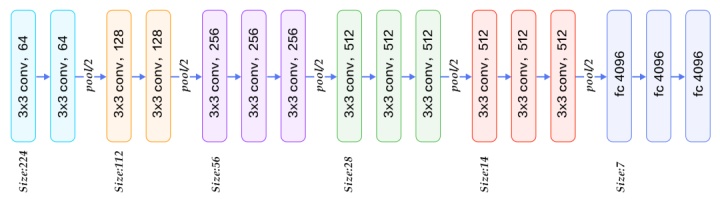
上面的两个图片摘自论文SSD: Single Shot MultiBox Detector,在论文中SSD是插入到VGG-16网络中的。
通过一个表格我们能够知道我们从不同层中得到的先验框尺寸和数目:

总共我们会获得8732个先验框。
MobileNet 与 SSD结合
前面说到我们可以很方便地将SSD插入到不同网络,那么考虑到我们的应用场景,我们可以使用诸如MobileNet网络来减少计算量。
MobileNet将卷积分为Depthwise和Pointwise两部分,减少了计算量,同时不会损失过多的精度。也因此在移动设备和嵌入式设备上面有很好的应用前景。更多关于MobileNet的理论信息大家可以在网上找到,这里不做过多讲述。
百度AI Studio上官方开源了基于SSD的目标检测模型的代码,代码非常好读,并可以直接在线运行,同时提供了训练好的SSD模型。从代码中我们可以看到,飞桨提供了paddle.fluid.layers.multi_box_head在不同Feature Map上面提取先验框、计算回归坐标等,paddle.fluid.layers.ssd_loss计算loss,paddle.fluid.initializer.MSRAInitializer实现以MSRA的方式初始化权重等等。这些API能够减轻我们的工作量,方便代码编写。官方代码还可以导出,在本地Python 3和飞桨 1.7上执行。
服务器部署
下面我们来使用Paddle Serving作为模型即服务后端。随着飞桨框架推出1.7版本,Paddle Serving也登上了舞台。Paddle Serving提出了模型即服务的理念,致力于简化模型部署到服务器操作,甚至一行命令实现模型部署。有了Paddle Serving,可以大大减轻搭建部署环境的负担。

需要注意的是Paddle Serving目前不支持arm64架构,并且对一些依赖包的版本有要求,所以强烈建议使用Docker进行部署。
首先我们pull到Docker 镜像:
- # Run CPU Docker
- docker pull hub.baidubce.com/paddlepaddle/serving:0.2.0
- docker run -p 9292:9292 --name test -dit hub.baidubce.com/paddlepaddle/serving:0.2.0
- docker exec -it test bash
-
- # Run GPU Docker
- nvidia-docker pull hub.baidubce.com/paddlepaddle/serving:0.2.0-gpu
- nvidia-docker run -p 9292:9292 --name test -dit hub.baidubce.com/paddlepaddle/serving:0.2.0-gpu
- nvidia-docker exec -it test bash
进入容器之后,由于官方缩减了镜像的大小,我们需要手动安装需要的依赖包:
python3 -m pip install paddle_serving_server sentencepiece opencv-python pillow -i https://pypi.tuna.tsinghua.edu.cn/simple镜像使用的系统是Centos 7,注意直接运行Python的话指向的是Python 2.7.5,你需要使用python3。(Python 2即将停止维护,pip在后续版本也可能不提供支持)。
Paddle Serving与直接利用模型不同的是,除了需要导出inference model以外还需要生成配置文件,定义Feed和Fetch的内容。如果你非常熟悉保存预测模型的接口,那么这并不是一件难事。从零开始训练一个模型,并应用到Paddle Serving,你可以参考官方的端到端从训练到部署全流程(https://github.com/PaddlePaddle/Serving/blob/develop/doc/TRAIN_TO_SERVICE_CN.md)。
这里我们可以直接利用上文提到的AI Studio的开源项目进行提取,真正的提取代码仅需要两行:
- import paddle_serving_client.io as serving_io
- serving_io.save_model(
- "ssd_model",
- "ssd_client_conf",
- {'image': img},
- {"prediction": box},
- inference_program)
前两行定义了我们的模型和客户端配置文件保存位置,后面的两个dict分别表示feed和fetch的内容,官方文档的例子表示这是我们在训练模型时的输入和输出。这里的img和box即为输入网络的img和网络输出的box,我们看下两个的结构。
- img:
- name: "img"
- type {
- type: LOD_TENSOR
- lod_tensor {
- tensor {
- data_type: FP32
- dims: -1
- dims: 3
- dims: 300
- dims: 300
- }
- lod_level: 0
- }
- }
- persistable: false
- box:
- name: "concat_0.tmp_0"
- type {
- type: LOD_TENSOR
- lod_tensor {
- tensor {
- data_type: FP32
- dims: 1917
- dims: 4
- }
- lod_level: 0
- }
- }
- persistable: false

可以在保存预测模型的时候保存Paddle Serving需要的配置项,或者之后从训练的代码中提取出img和box,进行保存。得到Paddle Serving需要的相关文件之后,利用下面的代码将其部署到服务器上(均在容器内进行,保证生成的模型和客户端配置和服务器脚本在同一目录之下):
- import os
- import sys
- import base64
- import numpy as np
- import importlib
- from paddle_serving_app import ImageReader
- from multiprocessing import freeze_support
- from paddle_serving_server.web_service import WebService
-
-
- class ImageService(WebService):
- def preprocess(self, feed={}, fetch=[]):
- reader = ImageReader(image_shape=[3, 300, 300],
- image_mean=[0.5, 0.5, 0.5],
- image_std=[0.5, 0.5, 0.5])
- feed_batch = []
- for ins in feed:
- if "image" not in ins:
- raise ("feed data error!")
- sample = base64.b64decode(ins["image"])
- img = reader.process_image(sample)
- feed_batch.append({"image": img})
- return feed_batch, fetch
-
-
- image_service = ImageService(name="image")
- image_service.load_model_config("./ssd_model/")
- image_service.prepare_server(
- workdir="./work", port=int(9292), device="cpu")
- image_service.run_server()
- image_service.run_flask()
在代码中先对得到的image进行了resize,然后交给模型处理。这里使用的是CPU进行预测,需要的话可以修改几行代码使其能够在GPU上预测。使用Paddle Serving并不需要安装飞桨,所以不会对服务器造成负担。Paddle Serving内置了数据预处理功能,因此可以直接对图片进行裁剪等操作。
在客户端上,仅仅需要几行代码就能够从服务端获取预测结果:
- import requests
- import base64
- import json
- import time
- import os
- import sys
-
- py_version = sys.version_info[0]
-
-
- def predict(image_path, server):
- if py_version == 2:
- image = base64.b64encode(open(image_path).read())
- else:
- image = base64.b64encode(open(image_path, "rb").read()).decode("utf-8")
- req = json.dumps({"feed": [{"image": image}], "fetch": ["prediction"]})
- r = requests.post(
- server, data=req, headers={"Content-Type": "application/json"}, timeout=60)
- try:
- print(r.json()["result"]["prediction"])
- except ValueError:
- print(r.text)
- return r
-
-
- if __name__ == "__main__":
- server = "http://[ip]:[port]/image/prediction"
- image_list = os.listdir("./images")
- start = time.time()
- for img in image_list:
- image_file = "./images/" + img
- res = predict(image_file, server)
- end = time.time()
- print(end - start)
对图片进行base64编码,发送到服务端,获取结果,非常简洁和方便。在实际部署的过程中,可以在服务端进行反代和鉴权,只需要写一个中间件即可,这也是模型即服务带给大家的便利之处。

我们国内服务端的配置是单核CPU(限制使用时间和频率),算上网络传输和预测的总用时在0.39秒左右,比较快速。返回的数组第一个值代表了对应类别,第二个值代表置信度,后面的值代表坐标比例,实际使用的时候需要设置阈值,放弃可信度较低的值。
移动端部署
移动端部署采用了之前开源的Real-time Object Detector,当时源码中使用的是YOLO v3模型,这里我们将使其适配SSD模型。在端侧部署方面我们使用的是Paddle Lite,这是飞桨系列中的多平台高性能深度学习预测引擎,提供了多平台架构下的预测解决方案,还支持C++/Java/Python等语言。
从上次发文到现在,Paddle Lite已经推出了新的版本,2.3版本对很多东西进行了优化,利用手上的安卓手机(麒麟 810)进行SSD目标检测的用时仅为500ms。这次我们还能够直接使用官方提供的预编译库进行预测,并不需要自己手动编译一次。下载下来之后我们会得到和上次一样的文件,PaddlePredictor.jar和一些so链接库,参考之前的推送文章:如何基于Flutter和Paddle Lite实现实时目标检测,放到相应位置即可。
因为SSD模型的输入和YOLO v3不一样,我们需要对安卓端的Predictor.java进行修改,主要考虑输入的尺寸问题。
- // MainActivity.java L41
- protected long[] inputShape = new long[]{1, 3, 300, 300};
- protected float[] inputMean = new float[]{0.5f, 0.5f, 0.5f};
- protected float[] inputStd = new float[]{0.5f, 0.5f, 0.5f};
-
- // Predictor.java L214
- // Set input shape
- Tensor inputTensor = getInput(0);
- inputTensor.resize(inputShape);
-
- // Predictor.java L258
- inputTensor.setData(inputData);
-
- // Predictor.java L303
- float rawLeft = outputTensor.getFloatData()[i + 2];
- float rawTop = outputTensor.getFloatData()[i + 3];
- float rawRight = outputTensor.getFloatData()[i + 4];
- float rawBottom = outputTensor.getFloatData()[i + 5];
同时我们对于描框的函数进行修改:
- // main.dart L127
- var ratioW = sizeRed.width / 300;
- var ratioH = sizeRed.height / 300;
如果在运行的时候出现了空指针错误,很可能你没有升级到最新的预编译库,jar和so文件均需要更新。由于上次发布源码的时候没有在Gradle脚本中设置自动下载库,所以需要手动放置预测库。

写在最后
从一开始熟悉怎么去使用飞桨深度学习平台,怎么让脚本跑起来,到现在开始逐步读懂论文,了解模型的架构,看官方文档,过程中遇到了不少问题。通过分析飞桨官方图像分类示例,查看和修改源码,输出调试信息,还在飞桨官方QQ群中得到了不少帮助,学到了很多东西,并最终完成了这次实践。非常感谢提供帮助的朋友们。飞桨经过多轮更新,在模型训练和部署上也变得非常简单,相信会吸引越来越多的开发者使用。
参考链接:
- Paddle Serving: https://github.com/PaddlePaddle/Serving
- AI Studio: https://aistudio.baidu.com/
- Paddle Lite: https://github.com/PaddlePaddle/Paddle-Lite
- 如何基于Flutter和Paddle Lite实现实时目标检测: https://mp.weixin.qq.com/s/khxjGW926iUly9uLl8ZQcA
- Real-time Object Detector:https://github.com/KernelErr/realtime-object-detector
如果您加入官方QQ群,您将遇上大批志同道合的深度学习同学。飞桨PaddlePaddle交流3群:703252161。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub:https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle

