
- 1深度学习框架的发展历程_csdn zomi酱
- 2微信小程序--自定义slider组件
- 3X 进制减法 — 蓝桥杯E题_最低数位为二进制,第二数位为十进制,第三数位为八进制,则 x进制数 321 转换为十进
- 4《Clock Domain Crossing》 翻译与理解(4)快时钟到慢时钟数据传输_快时钟采样慢时钟
- 5Claude3 AI系列重磅推出:引领多模态智能时代的前沿技术,超越GPT-4
- 6【JavaSE】Java练习—方法 _Java SE_public static void main(string[] args) { scanner a
- 7could not publish server configuration for tomcat at localhost
- 8Mac下升级ruby至最新版本_brew 更新ruby
- 9Web服务模拟器——wiremock_wiremockserver
- 10CNN目标检测(一):Faster RCNN详解
语音识别ASR技术通识_讯飞asr识别 通讯录
赞
踩
上午看了一篇文章:
语音识别的痛点在哪,从交互到精准识别如何做? | 硬创公开课
感觉没看懂,下午就看到了团长精心总结的这篇ASR技术通识。给个大大的��!
语音识别(Automatic Speech Recognition),一般简称ASR;是将声音转化为文字的过程,相当于人类的耳朵。
语音识别原理流程:“输入——编码——解码——输出”
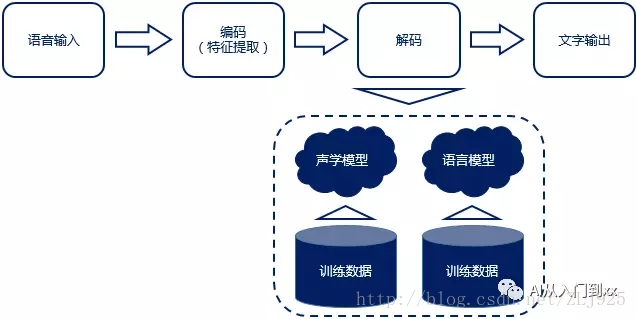
1、语音识别,大体可分为“传统”识别方式与“端到端”识别方式,其主要差异就体现在声学模型上。
“传统”方式的声学模型一般采用隐马尔可夫模型(HMM),而“端到端”方式一般采用深度神经网络(DNN)。
更多编码、解码等技术细节,感兴趣的同学可看《CUI三部曲之语音识别——机器如何听懂你的话?》
语音识别的应用,就这么简单?不是的,在实际场景,有很多种异常情况,都会导致语音识别的效果大打折扣,比如距离太远了不行,发音不标准不行,环境嘈杂不行,想打断也不行,等等。所以,还需要有各种解决方案来配合。
2、远场语音识别(Farfield Voice Recognition)
远场语音识别,简称远场识别,口语中可更简化为“远场”。下面主要说3个概念:
语音激活检测、语音唤醒、以及麦克风阵列。
1)语音激活检测(voice active detection,VAD)
A)需求背景:在近场识别场景,比如使用语音输入法时,用户可以用手按着语音按键说话,结束之后松开,由于近场情况下信噪比(signal to noise ratio, SNR))比较高,信号清晰,简单算法也能做到有效可靠。
但远场识别场景下,用户不能用手接触设备,这时噪声比较大,SNR下降剧烈,必须使用VAD了。
B)定义:判断什么时候有语音什么时候没有语音(静音)。
后续的语音信号处理或是语音识别都是在VAD截取出来的有效语音片段上进行的。
2)语音唤醒 (voice trigger,VT)
A)需求背景:在近场识别时,用户可以点击按钮后直接说话,但是远场识别时,需要在VAD检测到人声之后,进行语音唤醒,相当于叫这个AI(机器人)的名字,引起ta的注意,比如苹果的“Hey Siri”,Google的“OK Google”,亚马逊Echo的“Alexa”等。
B)定义:可以理解为喊名字,引起听者的注意。
VT判断是唤醒(激活)词,那后续的语音就应该进行识别了;否则,不进行识别。
C)难点:语音识别,不论远场还是进场,都是在云端进行,但是语音唤醒基本是在(设备)本地进行的,要求更高——
C.1)唤醒响应时间。据傅盛说,世界上所有的音箱,除了Echo和他们做的小雅智能音箱能达到1.5秒之外,其他的都在3秒以上。
C.2)功耗要低。iphone 4s出现Siri,但直到iphone 6s之后才允许不接电源的情况下直接喊“hey Siri”进行语音唤醒。这是因为有6s上有一颗专门进行语音激活的低功耗芯片,当然算法和硬件要进行配合,算法也要进行优化。
C.3)唤醒效果。喊它的时候它不答应这叫做漏报,没喊它的时候它跳出来讲话叫做误报。漏报和误报这2个指标,是此消彼长的,比如,如果唤醒词的字数很长,当然误报少,但是漏报会多;如果唤醒词的字数很短,漏报少了,但误报会多,特别如果大半夜的突然唱歌或讲故事,会特别吓人的……
C.4)唤醒词。技术上要求,一般最少3个音节。比如“OK google”和“Alexa”有四个音节,“hey Siri”有三个音节;国内的智能音箱,比如小雅,唤醒词是“小雅小雅”,而不能用“小雅”。
注:一般产品经理或行业交流时,直接说汉语“语音唤醒”,而英文缩写“VT”,技术人员可能用得多些。
3)麦克风阵列(Microphone Array)
A)需求背景:在会议室、户外、商场等各种复杂环境下,会有噪音、混响、人声干扰、回声等各种问题。特别是远场环境,要求拾音麦克风的灵敏度高,这样才能在较远的距离下获得有效的音频振幅,同时近场环境下又不能爆音(振幅超过最大量化精度)。另外,家庭环境中的墙壁反射形成的混响对语音质量也有不可忽视的影响。
B)定义:由一定数目的声学传感器(一般是麦克风)组成,用来对声场的空间特性进行采样并处理的系统。

C)能干什么
a)语音增强(Speech Enhancement):当语音信号被各种各样的噪声(包括语音)干扰甚至淹没后,从含噪声的语音信号中提取出纯净语音的过程。
b)声源定位(Source Localization):使用麦克风阵列来计算目标说话人的角度和距离,从而实现对目标说话人的跟踪以及后续的语音定向拾取。
c)去混响(Dereverberation):声波在室内传播时,要被墙壁、天花板、地板等障碍物形成反射声,并和直达声形成叠加,这种现象称为混响。

d)声源信号提取/分离:声源信号的提取就是从多个声音信号中提取出目标信号,声源信号分离技术则是需要将多个混合声音全部提取出来。

D)分类
a)按阵列形状分:线性、环形、球形麦克风。
在原理上,三者并无太大区别,只是由于空间构型不同,导致它们可分辨的空间范围也不同。
比如,在声源定位上,线性阵列只有一维信息,只能分辨180度;
环形阵列是平面阵列,有两维信息,能分辨360度;
球性阵列是立体三维空间阵列,有三维信息,能区分360度方位角和180度俯仰角。
b)按麦克风个数分:单麦、双麦、多麦
麦克风的个数越多,对说话人的定位精度越高,在嘈杂环境下的拾音质量越高;
但如果交互距离不是很远,或者在一般室内的安静环境下,5麦和8麦的定位效果差异不是很大。
傅盛说,全行业能做“6+1”麦克风阵列(环形对称分布6颗,圆心中间有1颗)的公司可能不超过两三家,包括猎户星空(以前行业内叫猎豹机器人)在内。而Google Home目前采用的是2mic的设计。
E)问题
a)距离太远时(比如10m、20m),录制信号的信噪比会很低,算法处理难度很大;
b)对于便携设备来说,受设备尺寸以及功耗的限制,麦克风的个数不能太多,阵列尺寸也不能太大。——分布式麦克风阵列技术则是解决当前问题的一个可能途径。
c)麦克风阵列技术仍然还有很大的提升空间,尤其是背景噪声很大的环境里,如家里开电视、开空调、开电扇,或者是在汽车里面等等。
整体来说,远场语音识别时,需要前后端结合去完成。
一方面在前端使用麦克风阵列硬件,通过声源定位及自适应波束形成做语音增强,在前端完成远场拾音,并解决噪声、混响、回声等带来的影响。
另一方面,由于近场、远场的语音信号,在声学上有一定的规律差异,所以在后端的语音识别上,还需要结合基于大数据训练、针对远场环境的声学模型,才能较好解决识别率的问题。
4)全双工(Full-Duplex)
A)需求背景:在传统的语音唤醒方案中,是一次唤醒后,进行语音识别和交互,交互完成再进入待唤醒状态。但是在实际人与人的交流中,人是可以与多人对话的,而且支持被其他人插入和打断。
B)定义:
单工:a和b说话,b只能听a说
半双工:参考对讲机,A:能不能听到我说话,over;B:可以可以,over
全双工:参考打电话,A:哎,老王啊!balabala……;B:balabala……
C)包含feature
人声检测、智能断句、拒识(无效的语音和无关说话内容)和回声消除(Echo Cancelling,在播放的同时可以拾音)
特别说下回声消除的需求背景:近场环境下,播放音乐或是语音播报的时候可以按键停止这些,但远场环境下,远端扬声器播放的音乐会回传给近端麦克风,此时就需要有效的回声消除算法来抑制远端信号的干扰。
5)纠错
A)需求背景:做了以上硬件、算法优化后,语音识别就会OK了吗?还不够。因为还会因为同音字(词)等各种异常情况,导致识别出来的文字有偏差,这时,就需要做“纠错”了。
B)用户主动纠错。
比如用户语音说“我们今天,不对,明天晚上吃啥?”,经过云端的自然语言理解过程,可以直接显示用户真正希望的结果“我们明天晚上吃啥”。

C)根据场景/功能领域不同,AI来主动纠错。这里,根据纠错目标数据的来源,可以进一步划分为3种:
a)本地为主。
比如,打电话功能。我们一位联合创始人名字叫郭家,如果说“打电话给guo jia时”,一般语音识别默认出现的肯定是“国家”,但(手机)本地会有通讯录,所以可以根据拼音,优先在通讯录中寻找更匹配(相似度较高)的名字——郭家。就显示为“打电话给郭家”。
b)本地+云端。
比如,音乐功能。用户说,“我想听XX(歌曲名称)”时,可以优先在本地的音乐库中去找相似度较高的歌曲名称,然后到云端曲库去找,最后再合在一起(排序)。
我们之前实际测试中发现过的“纠错例子”包括:
夜半小夜曲—>月半小夜曲
让我轻轻地告诉你—>让我轻轻的告诉你
他说—>她说
望凝眉—>枉凝眉
一听要幸福—>一定要幸福
苦啥—>哭砂
鸽子是个传说—>哥只是个传说
c)云端为主。
比如地图功能,由于POI(Point of Interest,兴趣点,指地理位置数据)数据量太大,直接到云端搜索可能更方便(除非是“家”、“公司”等个性化场景)。比如,用户说“从武汉火车站到东福”,可以被纠正为“从武汉火车站到东湖”。
二、当前技术边界
各家公司在宣传时,会说语音识别率达到了97%,甚至98%,但那一般是需要用户在安静环境下,近距离、慢慢的、认真清晰发音;而在一些实际场景,很可能还不够好的,比如——
1、比如在大家都认为相对容易做的翻译场景,其实也还没完全可用,台上演示是一回事,普通用户使用是另一回事;特别是在一些垂直行业,领域知识很容易出错;另外,还可详见《怼一怼那些假机器同传》
2、车载
大概3、4年前,我们内部做过针对车载场景的语言助手demo,拿到真实场景内去验证,结果发现,车内语音识别效果非常不理想。而且直到今年,我曾经面试过一位做车内语音交互系统的产品经理,发现他们的验收方其实也没有特别严格的测试,因为大家都知道,那样怎么也通过不了。。。
车内语音识别的难点很多,除了多人说话的干扰,还有胎噪、风噪,以及经常处于离线情况。
据说有的公司专门在做车内降噪,还有些公司想通过智能硬件来解决,至少目前好像还没有哪个产品解决好了这个问题,并且获得了用户的口碑称赞的。
3、家庭场景,由于相对安静和可控,如果远场做好了,还是有希望的。
4、中英文混合。
特别在听歌场景,用户说想听某首英文歌时,很容易识别错误的。这方面,只有傅盛的小雅音箱据说做了很多优化,有待用户检验。
总之,ASR是目前AI领域,相对最接近商用成熟的技术,但还是需要用户可以配合AI在特定场景下使用。这是不是问题呢?是问题,但其实不影响我们做产品demo和初步的产品化工作,所以反而是我们AI产品经理的发挥机会。
三、瓶颈和机会
1、远场语音识别,是最近2年的重要竞争领域。因为家庭(音箱)等场景有可能做好、在被催熟。
2、更好的机会在垂直细分领域,比如方言(方言识别能够支持40多种,而百度有20多种)、特定人群的声学匹配方案(儿童)
附:相关资料
1、文章
1)《傅盛:人工智能的破局点是技术和产品结合 | 猎户星空发布小雅语音》t.cn/Ro61HkJ
2)《语音识别的痛点在哪,从交互到精准识别如何做?》t.cn/RKFhkUy
3)《自然的语音交互——麦克风阵列》t.cn/RcjwjH9
4)(偏技术)《语音识别的技术原理是什么?》t.cn/RxkIccJ
5)(偏技术)《语音识别如何处理汉字中的「同音字」现象?》t.cn/RKDhxIT
6)(偏技术)《如何构建中英文混合的语音识别模型?》t.cn/RKDh9DD
2、书籍
网上有人推荐《解析深度学习:语音识别实践》by @俞栋 ;语音识别工具包是 kaldi。
以上内容,来自饭团“AI产品经理大本营”,点击这里可关注:http://fantuan.guokr.net/groups/219/ (如果遇到支付问题,请先关注饭团的官方微信服务号“fantuan-app”)
作者:黄钊hanniman,图灵机器人-人才战略官,前腾讯产品经理,5年AI实战经验,8年互联网背景,微信公众号/知乎/在行ID“hanniman”,饭团“AI产品经理大本营”,分享人工智能相关原创干货,200页PPT《人工智能产品经理的新起点》被业内广泛好评,下载量1万+。

