
热门标签
热门文章
- 1Windows中缺少mfc140.dll文件解决方法_mfc140.dll丢失的解决方法
- 2eb8000软件怎样上传_威纶通触摸屏 如何上传程序 到电脑需要怎么处理
- 3深度学习环境安装之显卡驱动程序安装_跑深度模型需要显卡驱动选择什么下载类型
- 4软件2.0(Software 2.0),懂AI的软件
- 5cv python_python里面cv是什么意思
- 6java 手动提交事务_spring手动提交处理事务
- 7【HarmonyOS】hdc 环境变量设置_hdc环境变量配置
- 8《Spring Cloud 与Docker 微服务架构实战》笔记摘要与PDF电子书分享_spring cloud与docker书籍电子版
- 9基于Vue+SpringBoot+MySQL实现个人博客系统_springboot+vue+mysql
- 10从零开始学定位 --- 使用kaist数据集进行LIO-SAM建图_lio-sam李太白
当前位置: article > 正文
使用jieba测试分词并且增加自定义字典_jieba如何添加自定义词典
作者:小丑西瓜9 | 2024-03-15 17:54:35
赞
踩
jieba如何添加自定义词典
1、github下载源码
https://github.com/fxsjy/jieba
也可以直接用pip安装
pip install jieba
- 1
2、拷贝测试代码测试
稍微修改了下文件路径方面的代码,路径如下

import time import sys sys.path.append("../") import jieba jieba.initialize() # 输入需要分词的文件路径 url = "test/data/zrbzdz.txt" content = open(url,"r",encoding='utf-8-sig').read() t1 = time.time() words = "/ ".join(jieba.cut(content)) t2 = time.time() tm_cost = t2-t1 # 输出分词后的文件路径 log_f = open("test/data/output/1.log","wb") log_f.write(words.encode('utf-8')) log_f.close() print('cost ' + str(tm_cost)) print('speed %s bytes/second' % (len(content)/tm_cost))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这边测试了5万多条标准地名地址数据

速度还是挺快的,大概只要13秒

结果肯定有些地方是不如人意的,毕竟是地名地址数据,看这里就有问题了

下一步添加自定义字典
3、添加自定义字典
如果用单个添加,感觉不太方便,用load_userdict方法添加,如果数据量大的话,又太慢,所以直接添加到结巴分词自身词库"dict.txt"当中。
github源码路径在这里
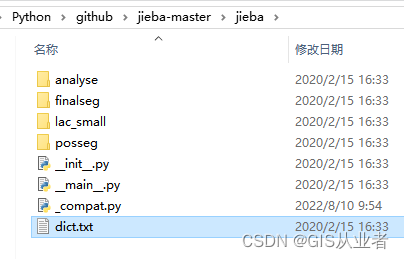
python安装路径在这里
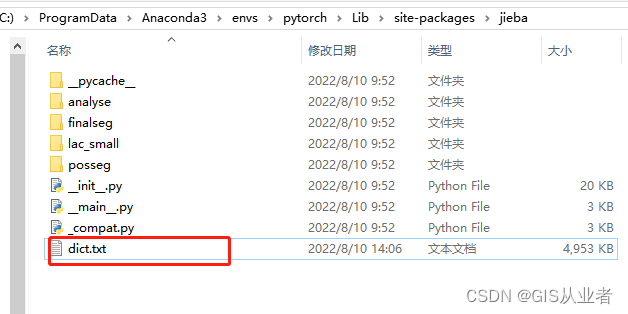
(1)、打开把自己的字典添加进去就行,注意格式
词 词频 词性
我这边词频和词性大概写的
福基岗村 3 n
- 1
(2)、添加后保存
(3)、删除jieba.cache
每次执行脚本,会提示加载的jieba.cache路径,我们先把它删除

(4)、重新执行脚本
脚本没变,结果变了,说明我们自定义的字典起作用了,有其它词数据可以一直加进去

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/243409
推荐阅读
相关标签

