
- 1klipper源码分析--概括_klipper点击细分
- 2如何理解移动侦测录像与人体红外感应_无线摄像头人体感应录像和移动侦测是不是需要在app付费?
- 3微信小程序开发笔记 基础篇①——微信小程序navigationBarTitleText导航栏标题设置
- 4十大排序算法(冒泡排序、插入排序、选择排序、希尔排序、堆排序、快排、归并排序、桶排序、计数排序、基数排序)
- 5【Python】Python3网络爬虫实战-3、数据库的安装:MySQL、MongoDB、Redis_python 安装 mysql mongo
- 6centos远程mc服务器,Centos7 下最最最简单的部署 MC 服务器超轻松学废
- 7【python】在 Python 中定义空变量和数据结构_python 创建空变量
- 8谷歌(google)全球网址_谷歌网址是多少
- 9500W级联式AC-DC模拟电源方案(PFC+LLC)_ncp1654应用实例500w
- 10有趣实用,盘点 GitHub 上标星最多的 5 个机器学习项目!
opencv-人脸识别_使用opencv进行人脸识别的三种方法
赞
踩
人脸识别即程序对输入的图像进行判别是否有人脸,并识别出有人脸的图像所对应的人。即我们常说的人脸识别一般包含了人脸检测和人脸识别两部分。下面对其在opencv中的相应模块进行分别介绍。
在opencv官网中,有许多推荐人脸在线数据集:http://face-rec.org/databases/,如果需要可以自行下载。
一:人脸检测
在人脸检测中,其主要任务是构造能够区分包含人脸实例和不包含人脸实例的分类器,
二:基本原理
opencv中提供了三种训练好的级联分类器。级联分类器顾名思义即通过不同的特征进行一步步筛选,最终得出所属的分类,它将一个复杂的分类问题拆解为一个个简单的分类问题,随着级联条件的判断,能够一步步筛出大量的负样本,极大的提升了后面分类的速度。下面其做简要介绍:
2.1:Haar级联分类器
haar级联分类器的发展历史暂不做介绍。它主要是将像素划分为很多模块,然后求相邻模块之间的差值以反映图像的灰度变化。最终相关人员将haar特征划分为了:4个边特征,8个线特征,2个中心点特征以及1个对角线特征。
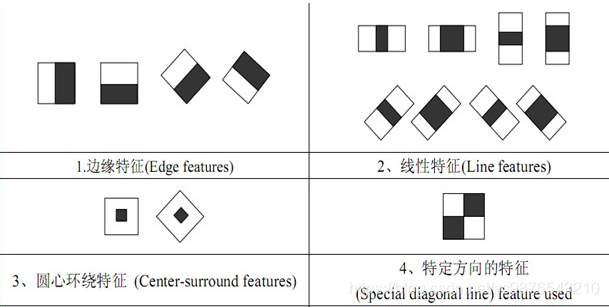
opencv中除了haar外还提供了Hog特征和LBP算法的级联分类器,Hog级联分类器主要用于行人检测。LBP算法在后面LBPH人脸识别部分做相应介绍。
级联分类器的使用:在opencv根目录下的opencv_createsamples.exe和opencv_traincascade.exe这两个可以用来训练级联分类器的文件,但自行训练比较耗时。opencv中提供了训练好的级联分类器供用户使用,在相应的haarcascades、hogcascades、lbpcascades文件夹中分别存放着Haar、HOG、LBP级联分类器,,它们以.xml的文件形式存放在opencv的源文件中,不同的.xml文件可以检测不同的类型,如:眼睛、眼镜、正面人脸、鼻子等等。
加载级联分类器的语法格式为:
object=cv2.CascadeClassifier(filename)
其中filename为分类器的路径和名称
- 1
- 2
在使用级联分类器的时候可以通过下面的一些方法去获取需要的级联分类器.xml文件:
1:在安装opencv的目录下查找xml文件
2:直接在网络上找到相应的.xml文件,下载并使用。
- 1
- 2
2.1.1:函数介绍
在opencv中,人脸检测使用的是cv2.CascadeClassifier.detectMultiScale()函数,它可以检测出图中的所有人脸,该函数由分类器对象调用:
objects=cv2.CascadeClassifier.detectMultiScale(image,scaleFactor,minNeighbors,flags,minSize,maxSize)
image:待检测图片,通常为灰度图。
scaleFactor:表示在前后两次的扫描中,搜索窗口的缩放比例。
minNeighbors:表示构成检测目标的相邻矩形的最小个数,默认情况下,该值为3,即有3个以上的检测标记存在时才认为人脸存在。该值越大,检测的准确率就越高,但同时无法被检测到的人脸就越多。
flags:该参数通常被省略,在使用低版本的opencv(1.0X版本)可能被设置为CV_HAAR_DO_CANNY_PRUNING,表示使用canny边缘检测器来拒绝一些区域。
minSize:目标的最小尺寸,小于这个尺寸的目标被忽略。
maxSize:返回值,目标对象的矩形框向量组。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
########opencv中人脸检测的具体实现###########
import cv2 dir=r"F:\my_project\opencv\face_recognize" image=cv2.imread(r"F:\my_project\opencv\img\30.jpg") #加载分类器模型 faceCascade=cv2.CascadeClassifier(r"F:\my_project\opencv\haarcascade_frontalface_default.xml") gray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY) faces=faceCascade.detectMultiScale( gray, scaleFactor=1.15, minNeighbors=5, minSize=(5,5) ) #逐个标注人脸 for (x,y,w,h) in faces: cv2.rectangle(image,(x,y),(x+w,y+h),(0,255,0),2) cv2.imshow("dect",image) cv2.waitKey() cv2.destroyAllWindows() =>人脸向量组: [[417 89 31 31] [343 93 28 28] [262 95 29 29] [135 98 28 28] [499 98 27 27] [199 100 29 29]] =>发现6个人脸!

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

2.2:LBPH人脸识别
人脸识别就是要找一个模型可以简介且具有差异性的方式反应特征,它先将当前人脸采用与检测相同的方法提取特征,再从已有特征集中找出当前特征的最近邻样本,从而得到当前样本的标签。
在opencv中有三种人脸识别方式,分别为LBPH、EigenFishface、Fisherfaces方法。下面只对LBPH做简要介绍。
LBPH(局部二值模式直方图)模型是基于LBP(局部二值模式)算法。LBP最早被用作纹理描述,因图像局部纹理特征表达效果出众而得到广泛应用。
由于在此更多的是介绍应用,若需对原理进行进一步了解可以查看:https://blog.csdn.net/heli200482128/article/details/79204008
2.2.1:LBPH函数介绍
在opencv中,可以用cv2.face.LBPHFaceRecognizer_create()函数生成LBPH实例模型,用cv2.face_FaceRecognizer.train()函数完成训练,用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
1:cv2.face.LBPHFaceRecognizer_create()函数
retval=recognizer=cv2.face.LBPHFaceRecognizer_create(radius, neighbors, grid_x, grid_y, threshold)
radius:半径值,默认为1
neighbors:邻域点的个数,默认采用8邻域
grid_x:将LBP特征图划分为一个个单元格时,每个单元格在水平方向上的像素个数,该参数值默认为8,即将LBP特征图像在行方向上以8个像素为单位分组。
grid_y:将LBP特征图划分为一个个单元格时,每个单元格在垂直方向上的像素值,该参数值默认为8,即将LBP特征图像在列方向上以8个像素为单位分组。
threshold:在预测时使用,如果大于该阈值,就认为没有识别到任何目标对象。
以上全部参数均为可选参数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2:cv2.face.LBPHFaceRecognizer.train()函数
None=cv2.face.LBPHFaceRecognizer.train(src,labels)
src:训练图像,用来学习的人脸图像
labels:标签,人脸图像所对应的标签
该函数没有返回值
- 1
- 2
- 3
- 4
3:cv2.face_FaceRecognizer.predict()函数
该函数对一个待测人脸图像进行判断,寻找与当前图像距离最近的人脸图像,与那个人脸图像最近,就将当前待测图像标注为其对应的标签。当然,如果待测图像与所有人脸图像的距离都大于cv2.face.LBPHFaceRecognizer_create()函数中的指定的阈值,则没有找到对应的结果,即无法识别当前人脸。
label,confidence=recognizer.predict(src)
src:需要识别的人脸图片
label:返回的识别结果标签
confidence:返回的置信度评分,置信度评分用来衡量识别结果与原有模型之间的距离,0表示完全匹配,通常小于50的值可以接受,大于80的则认为差别较大。
- 1
- 2
- 3
- 4
#####################人脸识别案例#########################
(1):如下图所示,在根目录下有三个存放不同人脸的文件

(2):在上述每个文件中又有下面两个不同名字的文件,其中origin_image为人的全身照或半身照,在此可以不管,face_image为人的面部图,在此为训练数据。
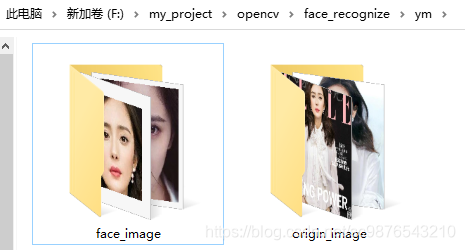
(3):在每个face_image文件中的图像如下:

(4):其中测试图像如下:

import cv2 import os import numpy as np dir = r"F:\my_project\opencv\face_recognize" images=[] labels=[] label_index=0 for person_name in os.listdir(dir): for image_name in os.listdir(os.path.join(dir,person_name,"face_image")): images.append(cv2.imread(os.path.join(dir,person_name,"face_image",image_name),cv2.IMREAD_GRAYSCALE)) labels.append(label_index) print("{0}对应的标签为:{1}".format(person_name,label_index)) label_index += 1 recognizer=cv2.face.LBPHFaceRecognizer_create() recognizer.train(images,np.array(labels)) predict_image=cv2.imread(r"predict_image=cv2.imread(r"F:\my_project\opencv\8.jpg",cv2.IMREAD_GRAYSCALE)",cv2.IMREAD_GRAYSCALE) label,confidence=recognizer.predict(predict_image) print("label=:",label) print("confidence=:",confidence)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
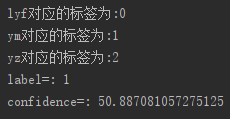
结果如上图所示,预测的标签为1,即对应着的人为:ym,其置信度评分为50.89。
2.3:EigenFaces人脸识别
EigenFaces通常也被称为特征脸,它使用主成分分析法PCA将高维的人脸数据处理为低维数据后再进行数据分析和处理,获取识别结果。
2.3.1 基本原理
在此不做相关介绍,如需要请自行查阅相关资料。
2.3.2 函数介绍
opencv通过函数cv2.face.EigenFaceRecognizer_create()生成特征脸识别器实例模型,然后应用cv2.face_FaceRecognizer.train()函数完成训练,最后用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
1:retval=cv2.face.EigenFaceRecognizer_create(num_components, threshold)
num_components:在PCA中要保留的分量个数,该参数通常要根据输入数据来具体决定,一般来说80个分量就足够了
threshold:进行人脸识别时所采用的阈值。
以上两个参数都是可选参数
- 1
- 2
- 3
2:None=cv2.face_FaceRecognizer.train(src,labels)
src:训练图像,用来学习的人脸图像
labels:人来图像所对应的标签
该函数无返回值
- 1
- 2
- 3
3:label,confidence=cv2.face_FaceRecognizer.predict(src)
src:需要识别的人脸图像
label:返回的识别结果标签
confidence:置信度评分,用来衡量识别结果与原有模型之间的距离,0表示完全匹配,,该参数一般在0-20000之间,只要低于5000,都认为是相当可靠的识别结果。
- 1
- 2
- 3
2.3.3 案例介绍
训练数据与LBPH函数案例中的一致,如ym文件夹与yz、lyf文件夹的子文件夹face_image中:


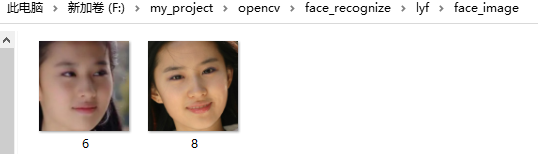
如下图所示,在target中有yz与ym两张图片。
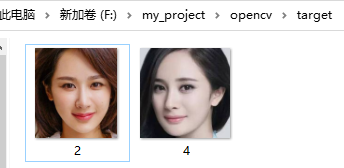
import cv2 import os import numpy as np dir = r"F:\my_project\opencv\face_recognize" images=[] labels=[] label_index=0 for person_name in os.listdir(dir): for image_name in os.listdir(os.path.join(dir,person_name,"face_image")): #所有训练数据与测试数据需要一致 images.append(cv2.resize(cv2.imread(os.path.join(dir,person_name,"face_image",image_name),cv2.IMREAD_GRAYSCALE),(600,600))) labels.append(label_index) print("{0}对应的标签为:{1}".format(person_name,label_index)) label_index += 1 recognizer=cv2.face.EigenFaceRecognizer_create() recognizer.train(images,np.array(labels)) predict_image_1=cv2.resize(cv2.imread(r"F:\my_project\opencv\target\2.png",cv2.IMREAD_GRAYSCALE),(600,600)) predict_image_2=cv2.resize(cv2.imread(r"F:\my_project\opencv\target\4.png",cv2.IMREAD_GRAYSCALE),(600,600)) label_1,confidence_1=recognizer.predict(predict_image_1) label_2,confidence_2=recognizer.predict(predict_image_2) print("目标图片2.png(yz)的测试结果为:label_1={0},confidence_1={1}".format(label_1,confidence_1)) print("目标图片4.png(ym)的测试结果为:label_2={0},confidence_2={1}".format(label_2,confidence_2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

从结果可知,图片2.png预测错误,仔细观察训练图片与测试图片,特征相差确实比较大,图片4.png预测正确。但两张图片的置信度都不高(confidence比较大),即模型对测试图片的最终识别结果的把握程度不高。
2.4:Fisherfaces人脸识别
PCA方法是EigenFaces方法的核心,它找到了最大化数据总方差特征的线性组合,但它的缺点在于操作过程中会损失许多的特征信息,在一些情况下,如果损失的信息正好是关键信息就会导致无法正确的分类。Fisherfaces采用的是LDA(线性判别分析)实现人脸识别。
2.4.1:基本原理
线性判别分析在对特征降维的同时会考虑类别信息。即在线性判别分析时,首先将训练样本集投影到一条直线A上,让投影点满足:同类间的点尽可能近,异类间的点尽可能远。做完投影后,将待测样本投影在直线A上,根据投影点的位置判定样本的类别即可。整个过程就是要找到这条最优的投影线。
2.4.2:函数介绍
opencv通过函数cv2.face.FisherFaceRecognizer_create()生成Fisherfaces识别器实例模型,然后应用cv2.face_FaceRecognizer.train()函数完成训练,最后用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
1:retval=cv2.face.FisherFaceRecognizer_create(num_components, threshold)
num_components:使用Fisherfaces准则进行线性判别分析时保留的成分数量,可以采用默认值"0",让函数自动设置适合的成分数量。
threshold:进行识别时所用的阈值,如果最近的距离比设定的阈值threshold大,函数会返回"-1".
以上两个参数都是可选参数
- 1
- 2
- 3
2:None=cv2.face_FaceRecognizer.train(src,labels)
src:训练图像,即用来训练的人脸图像。
labels:人脸图像所对应的标签。
该函数没有返回值。
- 1
- 2
- 3
3:label,confidence=cv2.face_FaceRecognizer.predict(src)
src:需要识别的人脸图像
label:返回的识别结果的标签
confidence:置信度评分,衡量识别结果与原有模型之间的距离,0表示完全匹配,该值通常在0-2000之间,低于5000
则认为识别结果相当可靠,该评分值的范围与EigenFaces方法的评分范围一致,与LBPH不同。
- 1
- 2
- 3
- 4
2.4.3:案例介绍
下面用我非常敬佩爱戴的三位人物:袁老、钱老、邓公作为案例列举。
训练数据如下:

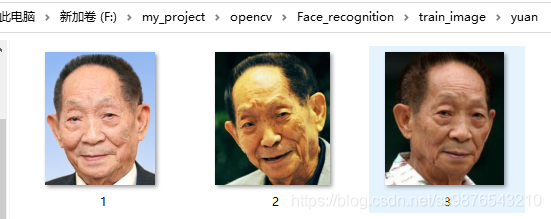

测试数据如下:

import cv2 import os import numpy as np dir = r"F:\my_project\opencv\Face_recognition\train_image" images=[] labels=[] label_index=0 for person_name in os.listdir(dir): for image_name in os.listdir(os.path.join(dir,person_name)): images.append(cv2.resize(cv2.imread(os.path.join(dir,person_name,image_name),cv2.IMREAD_GRAYSCALE),(600,600))) labels.append(label_index) print("{0}对应的标签为:{1}".format(person_name,label_index)) label_index += 1 #该人脸识别模型需要所有输入输出的图片尺寸一致 recognizer=cv2.face.FisherFaceRecognizer_create() recognizer.train(images,np.array(labels)) predict_image_1=cv2.resize(cv2.imread(r"F:\my_project\opencv\Face_recognition\test_image\deng.png",cv2.IMREAD_GRAYSCALE),(600,600)) predict_image_2=cv2.resize(cv2.imread(r"F:\my_project\opencv\Face_recognition\test_image\yuan.png",cv2.IMREAD_GRAYSCALE),(600,600)) predict_image_3=cv2.resize(cv2.imread(r"F:\my_project\opencv\Face_recognition\test_image\qian.png",cv2.IMREAD_GRAYSCALE),(600,600)) label_1,confidence_1=recognizer.predict(predict_image_1) label_2,confidence_2=recognizer.predict(predict_image_2) label_3,confidence_3=recognizer.predict(predict_image_3) print("目标图片deng.png的测试结果为:label_1={0},confidence_1={1}".format(label_1,confidence_1)) print("目标图片yuan.png的测试结果为:label_2={0},confidence_2={1}".format(label_2,confidence_2)) print("目标图片qian.png的测试结果为:label_3={0},confidence_3={1}".format(label_3,confidence_3))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
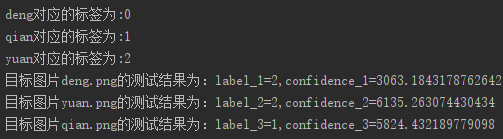
由上可知,模型经过训练袁老、钱老都能识别正确,但邓公识别错误(经过检测,邓公的测试图和训练图有较大差异,如果需要识别更加准确,可能需要添加更多邓公的图片到训练集中)。

