
- 1人工智能下一个前沿:可解释性_可解释、可通用的下一代人工智能方法
- 2「mac版」支持flash的浏览器,谷歌浏览器Chrome、火狐浏览器Firefox_谷歌浏览器mac玩flash
- 3CSS3 timing-function 贝塞尔曲线_linear 贝塞尔曲线 function
- 4【Android Gradle 插件】Android Studio 工程 Gradle 构建流程 ( settings.gradle 构建脚本分析 | 根目录下 build.gradle 分析 )_android studio gradle插件
- 5湖北大学计算机考入清华,697分考入清华却退学,襄阳学霸高考二刷699分!一心入行人工智能...
- 6Android模拟器的检测_emulatordetector: dfpsdk:
- 7解决Android Studio不能运行Java main方法的问题_androidstudio configurations no main class special
- 8每日总结_总结每天
- 9硬核课程全网首发!高级人工智能:多模态大模型LLM与AIGC前沿技术实战
- 10机器学习从理论到实践(常见算法)_机器学习理论与实践
NLP - TextRank_textrank的优点?
赞
踩
用处:提取关键词、文本摘要
优点:运算简单,计算速度快。
无监督学习。
思想来源于 PageRank
从入链和出链来看待网页。
沦为 Mihaicea 《TextRank》
公式:
TextRank
类似于PageRank的思想,
将文本中的语法单元视作图中的节点,如果两个语法单元存在一定语法关系(例如共现),则这两个语法单元在图中就会有一条边相互连接。
通过一定的迭代次数,最终不同的节点会有不同的权重,权重高的语法单元可以作为关键词。
参考论文:Rada Mihalcea的《TextRank:Bring Order into texts》
节点的权重不仅依赖于它的入度结点,还依赖于这些入度结点的权重,入度结点越多,入度结点的权重越大,说明这个结点的权重越高;
图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。
TextRank迭代计算公式为:
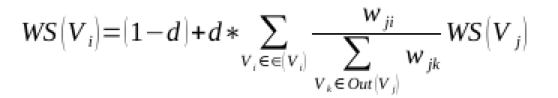
其中, d 为阻尼系数, 取值范围为 0 到 1,代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。
使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛。
即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
算法通用流程:
应用到关键短语抽取:
- 预处理,首先进行分词和词性标注,将单个word作为结点添加到图中;
- 设置语法过滤器,将通过语法过滤器的词汇添加到图中;出现在一个窗口中的词汇之间相互形成一条边;
- 基于上述公式,迭代直至收敛;一般迭代20-30次,迭代阈值设置为0.0001;
- 根据顶点的分数降序排列,并输出指定个数的词汇作为可能的关键词;
- 后处理,如果两个词汇在文本中前后连接,那么就将这两个词汇连接在一起,作为关键短语;
其中,TextRank是为TextRank算法抽取关键词所定义的类。
类在初始化时,默认加载了分词函数和词性标注函数 tokenizer = postokenizer = jieba.posseg.dt、停用词表stop_words = self.STOP_WORDS.copy()、词性过滤集合 pos_filt = frozenset(('ns', 'n', 'vn', 'v')),窗口 span = 5,((“ns”, “n”, “vn”, “v”))表示词性为地名、名词、动名词、动词。
首先定义一个无向有权图,然后对句子进行分词;
依次遍历分词结果,如果某个词i满足过滤条件(词性在词性过滤集合中,并且词的长度大于等于2,并且词不是停用词),然后将这个词之后窗口长度为5范围内的词j(这些词也需要满足过滤条件),将它们两两(词i和词j)作为key,出现的次数作为value,添加到共现词典中;
然后,依次遍历共现词典,将词典中的每个元素,key = (词i,词j),value = 词i和词j出现的次数,其中词i,词j作为一条边起始点和终止点,共现的次数作为边的权重,添加到之前定义的无向有权图中。
然后对这个无向有权图进行迭代运算textrank算法,最终经过若干次迭代后,算法收敛,每个词都对应一个指标值;
如果设置了权重标志位,则根据指标值值对无向有权图中的词进行降序排序,最后输出topK个词作为关键词;
def textrank(self, sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'), withFlag=False): self.pos_filt = frozenset(allowPOS) # 定义无向有权图 g = UndirectWeightedGraph() # 定义共现词典 cm = defaultdict(int) # 分词 words = tuple(self.tokenizer.cut(sentence)) # 依次遍历每个词 for i, wp in enumerate(words): # 词i 满足过滤条件 if self.pairfilter(wp): # 依次遍历词i 之后窗口范围内的词 for j in xrange(i + 1, i + self.span): # 词j 不能超出整个句子 if j >= len(words): break # 词j不满足过滤条件,则跳过 if not self.pairfilter(words[j]): continue # 将词i和词j作为key,出现的次数作为value,添加到共现词典中 if allowPOS and withFlag: cm[(wp, words[j])] += 1 else: cm[(wp.word, words[j].word)] += 1 # 依次遍历共现词典的每个元素,将词i,词j作为一条边起始点和终止点,共现的次数作为边的权重 for terms, w in cm.items(): g.addEdge(terms[0], terms[1], w) # 运行textrank算法 nodes_rank = g.rank() # 根据指标值进行排序 if withWeight: tags = sorted(nodes_rank.items(), key=itemgetter(1), reverse=True) else: tags = sorted(nodes_rank, key=nodes_rank.__getitem__, reverse=True) # 输出topK个词作为关键词 if topK: return tags[:topK] else: return tags

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
其中,无向有权图的的定义及实现是在 UndirectWeightedGraph 类中实现的。
根据 UndirectWeightedGraph 类的初始化函数__init__,可以发现,所谓的无向有权图就是一个词典,词典的key是后续要添加的词,词典的value,则是一个由(起始点,终止点,边的权重)构成的三元组所组成的列表,表示以这个词作为起始点的所有的边。
无向有权图添加边的操作 是在addEdge函数中完成的。
因为是无向图,所以我们需要依次将start作为起始点,end作为终止点,然后再将start作为终止点,end作为起始点,这两条边的权重是相同的。
def addEdge(self, start, end, weight):
# use a tuple (start, end, weight) instead of a Edge object
self.graph[start].append((start, end, weight))
self.graph[end].append((end, start, weight))
- 1
- 2
- 3
- 4
执行textrank算法迭代是在rank函数中完成的。
首先对每个结点赋予相同的权重,以及计算出该结点的所有出度的次数之和;
然后迭代若干次,以确保得到稳定的结果;
在每一次迭代中,依次遍历每个结点;对于结点n,首先根据无向有权图得到结点n的所有入度结点(对于无向有权图,入度结点与出度结点是相同的,都是与结点n相连的结点)
在前面我们已经计算出这个入度结点的所有出度的次数,
它对于 结点n的权值的贡献 = 它本身的权值 * 它与结点n的共现次数 / 这个结点的所有出度的次数
将各个入度结点得到的权值相加,再乘以一定的阻尼系数,即可得到结点n的权值;
迭代完成后,对权值进行归一化,并返回各个结点及其对应的权值。
def rank(self): ws = defaultdict(float) outSum = defaultdict(float) wsdef = 1.0 / (len(self.graph) or 1.0) # 初始化各个结点的权值 # 统计各个结点的出度的次数之和 for n, out in self.graph.items(): ws[n] = wsdef outSum[n] = sum((e[2] for e in out), 0.0) # this line for build stable iteration sorted_keys = sorted(self.graph.keys()) # 遍历若干次 for x in xrange(10): # 10 iters # 遍历各个结点 for n in sorted_keys: s = 0 # 遍历结点的入度结点 for e in self.graph[n]: # 将这些入度结点贡献后的权值相加 # 贡献率 = 入度结点与结点n的共现次数 / 入度结点的所有出度的次数 s += e[2] / outSum[e[1]] * ws[e[1]] # 更新结点n的权值 ws[n] = (1 - self.d) + self.d * s (min_rank, max_rank) = (sys.float_info[0], sys.float_info[3]) # 获取权值的最大值和最小值 for w in itervalues(ws): if w < min_rank: min_rank = w if w > max_rank: max_rank = w # 对权值进行归一化 for n, w in ws.items(): # to unify the weights, don't *100. ws[n] = (w - min_rank / 10.0) / (max_rank - min_rank / 10.0) return ws
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
TextRank 提取关键词
#-*- coding=utf8 -*-
from jieba import analyse
# 引入TextRank关键词抽取接口
textrank = analyse.textrank # 原始文本
text = "非常线程是程序执行时的最小单位,它是进程的一个执行流,\ 是CPU调度和分派的基本单位,一个进程可以由很多个线程组成,\ 线程间共享进程的所有资源,每个线程有自己的堆栈和局部变量。\ 线程由CPU独立调度执行,在多CPU环境下就允许多个线程同时运行。\ 同样多线程也可以实现并发操作,每个请求分配一个线程来处理。"
print ("\nkeywords by textrank:") # 基于TextRank算法进行关键词抽取
keywords = textrank(text, topK=10, withWeight=True, allowPOS=('ns', 'n')) # 指定参数; 获得了词和权重
# 输出抽取出的关键词 f
words=[keyword for keyword,w in keywords if w>0.2]
print (' '.join(words) + "\n")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

