
热门标签
热门文章
- 1利用pscp和psftp工具,在windows和linux之间传输文件
- 2蓝桥杯之十六进制与十进制互转简化(c++代码实现)_c++蓝桥杯十六进制转十进制
- 3mac启动skywalking报错
- 4mysql 索引(为什么选择B+ Tree?)
- 5又封神了,Rust 构建开源 Pingora 框架,每天处理超过 1 万亿个请求,Nginx 慢慢消亡!
- 6uniapp Android原生插件开发和离线打包调试看这篇就够了!(保姆级手把手教学)_原生插件 sdk 插件编译失败
- 7RedHat 6.4 RHCS GFS2安装
- 8vmware安装安卓9.0测试_虚拟机安装安卓9
- 9【C++】计算点到线段的最短距离_计算两个线段之间的最小距离 c++
- 10基于STM32单片机智能RFID超市收银系统设计DIY23-210
当前位置: article > 正文
数据科学与大数据分析项目练习-3将Apriori算法应用于R中提供的“Groceries”数据集
作者:小丑西瓜9 | 2024-03-22 09:33:42
赞
踩
数据科学与大数据分析项目练习-3将Apriori算法应用于R中提供的“Groceries”数据集
我们需要安装arules and arulesViz包。
项目要求:
生成频繁项目集满足下面条件:
– The minimum support threshold as 0.02
– The minimum length of the itemsets as 1
– The maximum length of the itemsets as 10
生成的关联规则满足下面条件:
– The minimum support threshold as 0.001
– The minimum confidence threshold as 0.6
Project Start
# 下载并加载相关的包(可能需要梯子)
install.packages('arules')
install.packages('arulesViz')
library('arules')
library('arulesViz')
- 1
- 2
- 3
- 4
- 5
# 读取并展示“Groceries”包
data(Groceries)
Groceries
summary(Groceries)
class(Groceries)
- 1
- 2
- 3
- 4
- 5

可以看到这个“Groceries”包一共有9835行和169列。
# 展示前20个grocery labels
Groceries@itemInfo[1:20,]
# 显示第10至20的transactions
apply(Groceries@data[,10:20], 2,
function(r) paste(Groceries@itemInfo[r,"labels"], collapse=", ")
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

接下来是生成频繁项目集
参数的设置按照要求
# frequent 1-itemsets itemsets <- apriori(Groceries, parameter=list(minlen=1, maxlen=1, support=0.02, target="frequent itemsets")) summary(itemsets) inspect(head(sort(itemsets, by = "support"), 10)) # frequent 2-itemsets itemsets <- apriori(Groceries, parameter=list(minlen=2, maxlen=2, support=0.02, target="frequent itemsets")) summary(itemsets) inspect(head(sort(itemsets, by ="support"),10)) # frequent 3-itemsets itemsets <- apriori(Groceries, parameter=list(minlen=3, maxlen=3, support=0.02, target="frequent itemsets")) inspect(sort(itemsets, by ="support")) # frequent 4-itemsets itemsets <- apriori(Groceries, parameter=list(minlen=4, maxlen=4, support=0.02, target="frequent itemsets")) inspect(sort(itemsets, by ="support"))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
生成的频繁项目集结果如下:
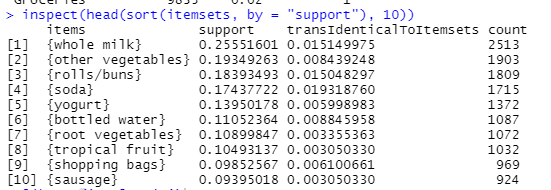

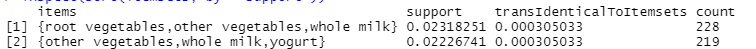

规则生成和可视化
rules <- apriori(Groceries, parameter=list(support=0.001,
confidence=0.6, target = "rules"))
summary(rules)
plot(rules)
plot(rules@quality)
- 1
- 2
- 3
- 4
- 5

# 显示rules与最高lift scores
inspect(head(sort(rules, by="lift"), 10))
- 1
- 2

筛选出置信度大于0.9的rules
confidentRules <- rules[quality(rules)$confidence > 0.9]
confidentRules
plot(confidentRules, method="matrix", measure=c("lift", "confidence"), control=list(recorder=TRUE))
- 1
- 2
- 3
- 4

一个127个,之后polt成为matrix得到

# 选择lift最高的5项规则
highLiftRules <- head(sort(rules, by="lift"), 5)
plot(highLiftRules, method="graph", control=list(type="items"))
- 1
- 2
- 3
得到图片如下所示。
从图中我们可以得到买火腿的基本上都会购买加工芝士,买爆米花或者soda饮料的很大概率会购买咸味小吃。

参考书目
- Data Science and Big Data Analytics: Discovering, Analyzing, Visualizing and Presenting Data, EMC Education Services, John Wiley & Sons, 27 Jan. 2015
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/286929
推荐阅读
相关标签

