
- 1Web安全-文件包含漏洞_jsp远程文件包含
- 2AI文案助手,让创作轻松又高效
- 3快要圣诞节啦,快去给小伙伴们分享漂亮的圣诞树吧_pycharm圣诞树
- 4基于微信小程序的电影票务系统_基于微信小程序的电影售票系统的主要内容是什么
- 5GAN之父NIPS 2016演讲现场直击:全方位解读生成对抗网络的原理及未来(附PPT)
- 6微信小程序适配iphoneX,XR,12及以上,获取底部安全区域_小程序底部适配 苹果手机型号
- 7【PHP代码注入】PHP语言常见可注入函数以及PHP代码注入漏洞的利用实例
- 8现代工程仿真CAE技术介绍
- 9ArcGIS字段按照条件批量赋值_gis批量邻近赋值
- 10面试题_x times - software engineer
NLP | textCNN &textRNN 图文详解及代码_textrcnn
赞
踩
textCNN &textRNN主要是做文本分类(Text Classification)。
文本分类是自然语言处理的一项基本任务,试图推断给定文本(句子、文档等)的标签或标签集。
文本分类的应用非常广泛,比如:
- 垃圾邮件分类:2分类问题判断邮件是否为垃圾邮件
- 情感分析:2分类问题:判断文本情感是正面还是负面;多分类问题:确定文本情感属于哪种类型{非常消极、消极、中性、积极、非常积极}。
- 新闻主题分类:确定一条新闻属于哪个类别,如财经、体育、娱乐等。根据类别标签的数量,可以是两个类别,也可以是多个类别。
- 自动问答系统中的问题分类
- 社区问答系统中的问题分类:多标签多分类(一段文字多分类,文字可能有多个标签),如知乎看山杯
- 让AI做法官:基于案例事实描述文本的精细分类(多分类)和法律分类(多标签、多分类)
- 判断新闻是否是机器人写的:2类
1.textCNN
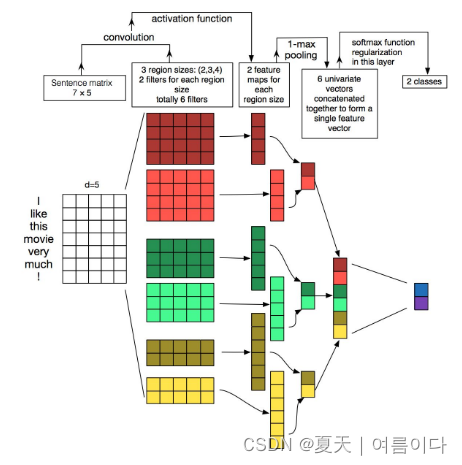
在 TextCNN 中,过滤器扫描句子并确定它们的上下文含义。
TextCNN的进程如下:
1. 接收词嵌入向量作为输入
2. 通过过滤器和词嵌入向量的卷积操作创建特征图
3. 通过激活函数将特征图映射到激活图
4. 通过最大池化每个激活图进行连接
5. concat 将向量作为全连接层的输入,分类
1.1TextCNN的优势
在掌握句子上下文意义的过程中收集信息→提高运算速度
在分类问题上 优于 RNN(在 TextCNN 中,嵌入维度和过滤器的水平大小必须相同。)
1.2.TextCNN的实现
- 下面是filter size为2时,通过input和filter的卷积运算形成feature map的过程。
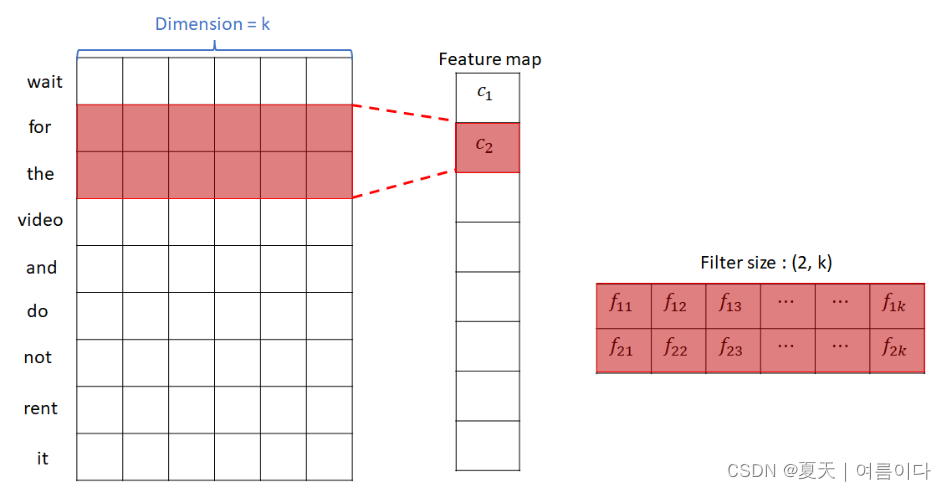
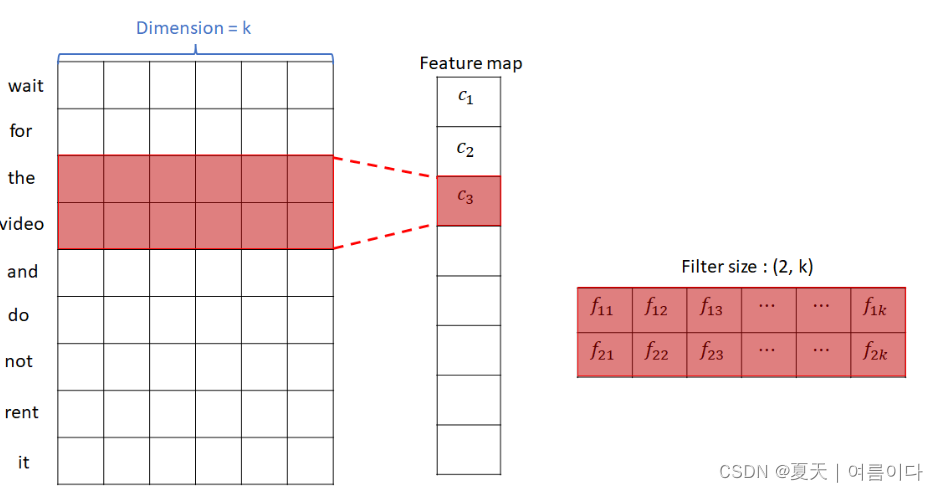
下面是filter size为3时通过input和filter的卷积操作形成feature map的过程。
通过上述过程,形成了特征图和激活图。
在本文中,使用三种过滤器尺寸进行了实验:2、3 和 4。
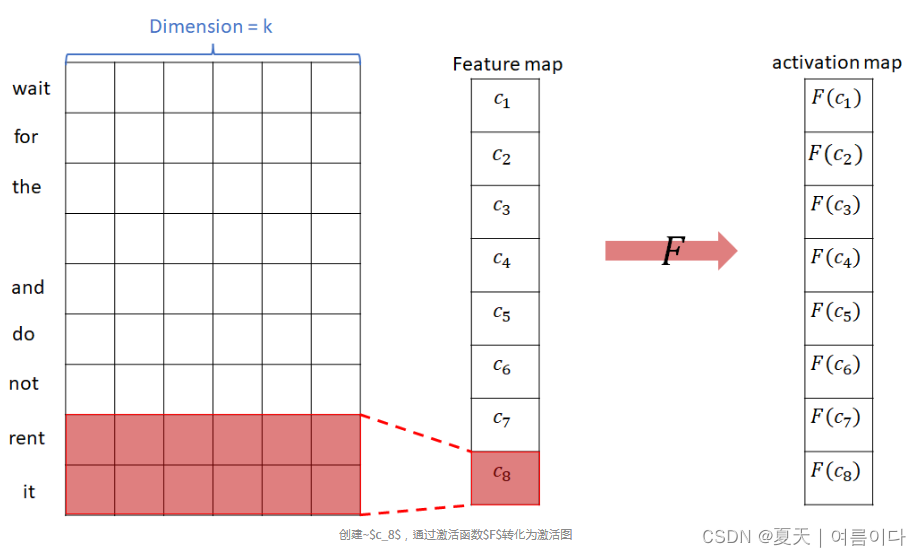
- 接下来,我们看一下激活图中max pooling的过程。
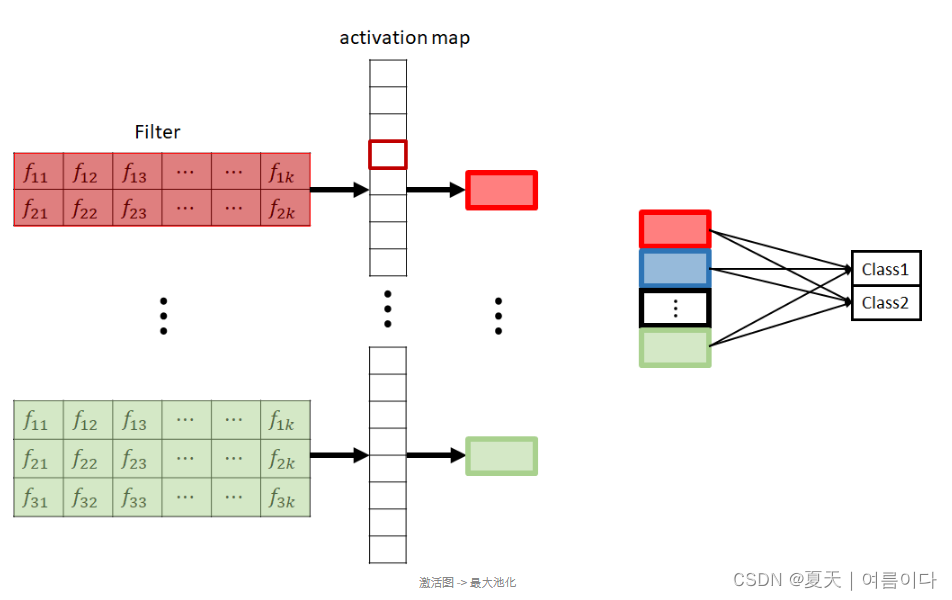
如上图所示,在最大池化过程中,为每个激活图选择并提取最大值。
在图中,表示了一个过滤器,但使用多个过滤器会创建多个激活图。
例如,如果使用 10 个大小为 2 的过滤器(10 个通道)、10 个大小为 3 的过滤器(10 个通道)和 10 个大小为 4 的过滤器(10 个通道)进行卷积操作,则每个过滤器 10 个,即总共创建了 30 个特征图和激活图。
假设已经创建了 30 个激活图,可以进行最大池化以获得 30 个最大值。
输入这里得到的30个最大值作为全连接层的输入后,继续分类。流程如下
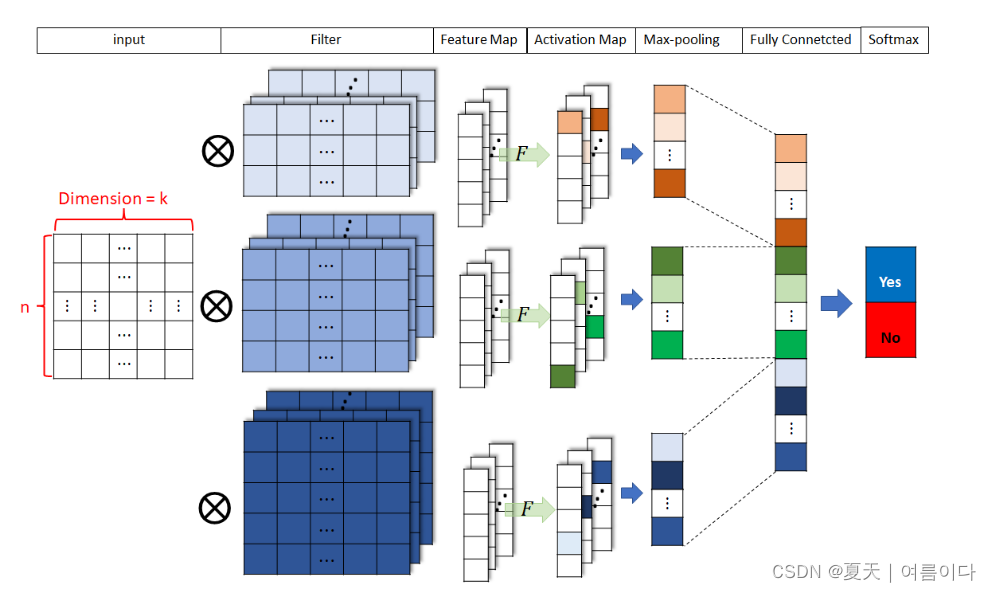
1. 词嵌入输入
2.过滤和卷积操作
3.特征图
4.激活(特征图)→激活图
5. 最大池化
6. 全连接层
7.分类
1.3.实现代码
2.textRNN
2.1.textRNN原理
在一些自然语言处理任务中,在处理序列的时候,我们一般会用到循环神经网络RNN,尤其是它的一些变种,比如LSTM(比较常用)、GRU。当然,我们也可以将 RNN 应用于文本分类任务。
这里的文本可以是一个句子,一个文档(短文本,几个句子)或者一个章节(长文本),所以每个文本的长度是不同的。在对文本进行分类时,我们一般会指定一个固定的输入序列/文本长度:长度可以是最长的文本/序列的长度,其他所有的文本/序列都必须填满才能达到这个长度;这个长度也可以是训练集中所有文本/序列长度的平均值。在这种情况下,太长的文本/序列需要被截断,而那些太短的则被填充。总之,为了使训练集中的所有文本/序列具有相同的长度,除了上面提到的设置,长度还可以是任何其他合理的值。在测试的时候,你还需要对测试集中的文本/序列做同样的事情。
假设训练集中所有文本/序列的长度统一为n,我们需要对文本进行分割,并使用词嵌入来获得每个词的固定维向量表示。对于每个输入的文本/序列,我们可以在RNN的每个时间步输入文本中一个词的向量表示,计算当前时间步的隐藏状态,然后将其用于当前时间步的输出和将其传递给下一个时间步和下一个词的词向量作为RNN单元的输入,然后计算RNN在下一个时间步的隐藏状态,如此重复……直到处理输入文本中的每个单词,由于输入文本的长度为n,所以要经过n个时间步。
基于RNN的文本分类模型非常灵活,具有多种结构。接下来,我们主要介绍两种典型的结构。
2.1.textRNN网络结构
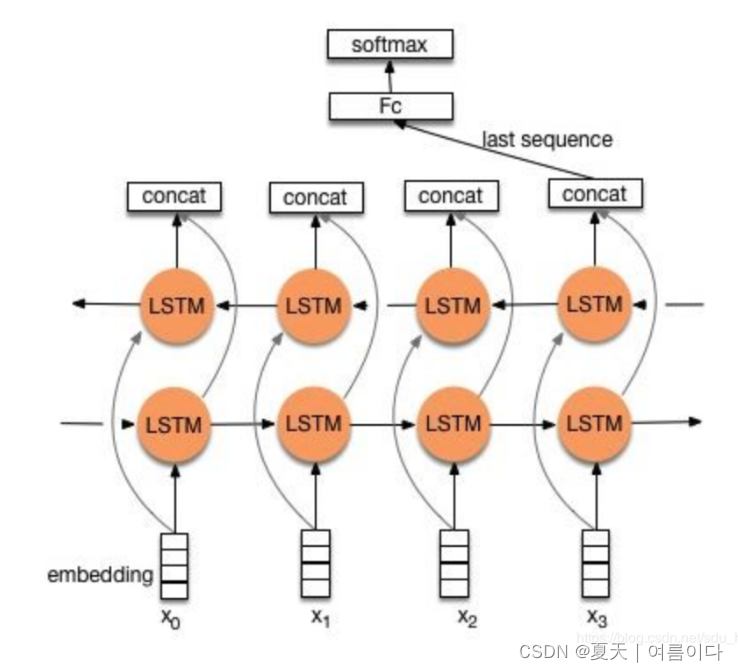
在Tensorflow中,堆叠两个或多个 LSTM 层
Keras 循环层有两种可用模式,由return_sequences构造函数参数控制:
-
如果
False它只返回每个输入序列的最后一个输出(形状为 (batch_size, output_features) 的 2D 张量)。这是默认值,在以前的模型中使用。 -
如果
True返回每个时间步的完整连续输出序列(形状为 3D 张量(batch_size, timesteps, output_features))。
以下是信息流的样子return_sequences=True:
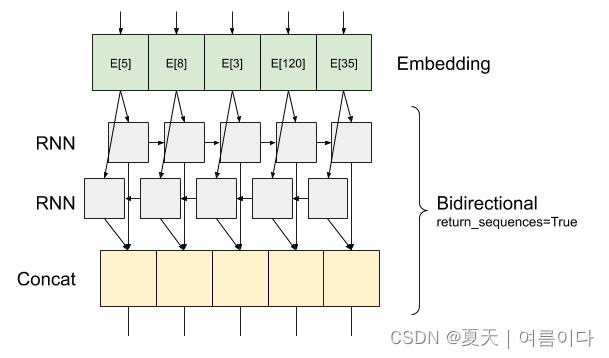
RNN使用with的有趣return_sequences=True之处在于,输出仍然有 3 轴,就像输入一样,因此可以将其传递给另一个 RNN 层。
结构:降维->双向lstm -> concat输出->平均 -> softmax
代码可参考【4】
参考文献
【2】The network structure and code implementation of textRNN & textCNN! - Karatos
【3】https://www.tensorflow.org/text/tutorials/text_classification_rnn?hl=zh-cn
- texcnn全名 ...
赞
踩

