
热门标签
热门文章
- 1语音识别(ASR):从声音信号中识别和转录文字的技术_asr音频转写
- 2如何在以太坊上存一张图片_怎样把图片记录到以太坊区块
- 3C#调用Python脚本训练并生成AI模型(以Paddle框架为例)_c# ai训练
- 4数据分享|纯净音自然多轮对话数据集——语音大模型_自发风格语音
- 5c语言编译说文件不存在,c – 无法编译代码“启动:程序不存在”
- 6Max retries exceeded with url 解决方案
- 7内存基本知识_存储信息所使用的状态个数为
- 8matlab中矩阵的归一化和标准化处理_matlab 矩阵中每行数据归一化到0-1
- 9【深度学习笔记系列】卷积神经网络(CNN)详解_卷积神经网络的基本结构图
- 10论文阅读记录 DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning(强化学习+知识图谱+路径推理)_nell数据集
当前位置: article > 正文
查漏补缺之(一)—— fasttext与TextCNN_fasttext textcnn
作者:凡人多烦事01 | 2024-04-01 12:06:31
赞
踩
fasttext textcnn
最近查看自己的博客,发现自己居然没有 fasttext与TextCNN的相关博客,正可谓左青龙右白虎王朝马汉在中间,没有这两位怎么能行呢?午休之前安排!
但需要提前说明的是,本篇博客不深入探究Fasttext与TextCNN的细节,只是基于既有知识点进行拓展解释,以期触类旁通。
fastText
fastText的核心思想是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类得到其所属的类别label。
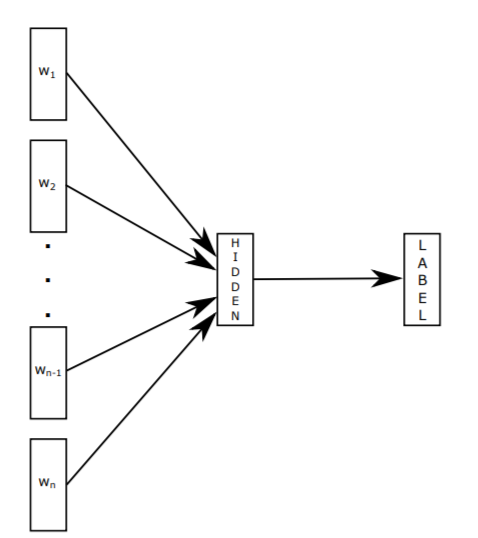
整个过程类似于CBOW,以下是两者的一些区别和联系:
| fastText | CBOW | |
|---|---|---|
| 作用 | 主要用于分类,也可用于词向量训练 | 主要用于训练词向量 |
| 输入 | 表征单个文档的多个单词及字符级n-gram特征,被embedding过 | 目标单词的上下文,被onehot编码过 |
| 过程 | 将一个句子所有词做平均,提取的是句子的特征,利用全部的n-gram去预测指定类别label | 将window_size的上下文词的向量做平均,提取的是上下文词特征,然后根据周围词预测中心词 |
| 输出 | 目标词汇的概率分布 | 文档对应类别的概率分布 |
| 其他 | 有监督学习;使用层次softmax计算文档属于某个类别的概率。 | 无监督学习;使用层次softmax计算中心词出现的概率。 |
字符级n-gram特征的引入以及层次Softmax是fastText中两个重要的技巧,其中字符级的n-gram特征还可以在一定程度上解决OOV的问题。fastText适用与分类类别非常大而且数据集足够多的情况,当分类类别比较小或者数据集比较少的话,很容易过拟合。
想要了解更多可以参见fastText官网进行实践:
TextCNN
基于我们之前对CNN的理解,再来理解TextCNN就很容易了,如果CNN忘了可以回顾:
TextCNN是CNN在文本处理上的应用,可更好地捕捉局部相关性,一张图进行说明:
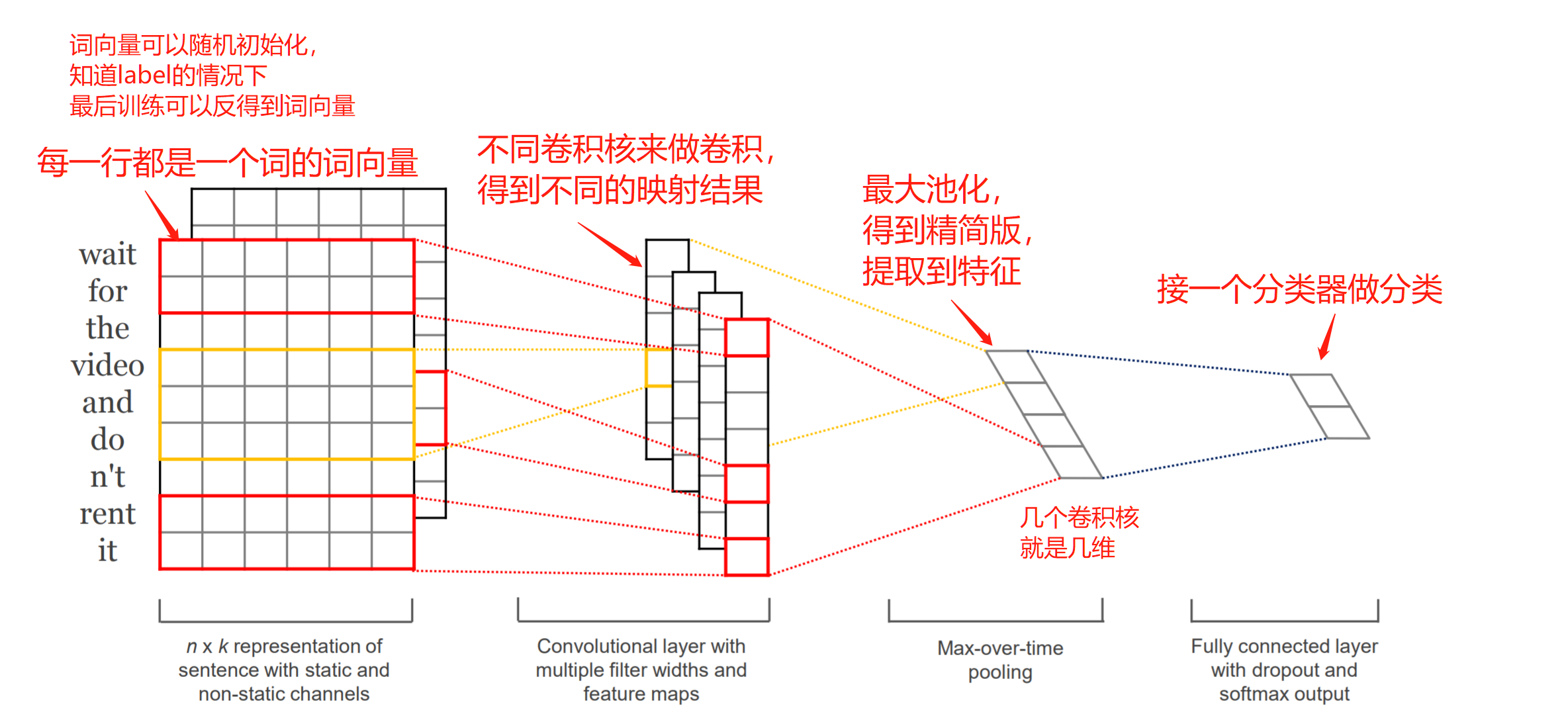
或者想了解更多可以看原论文:
常用选型技巧
- Fasttext(垃圾邮件/主题分类) 特别简单的任务,要求速度
- TextCNN(主题分类/领域识别) 比较简单的任务,类别可能比较多,要求速度
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

