
- 1职业发展能力图谱_职业教育专业能力图谱
- 2sparksql异常总结_org.apache.hadoop.hive.serde2.lazy.lazysimpleserde
- 3蓝桥杯经验分享_蓝桥杯比赛有多少题目
- 4vue+springboot实现文件上传和下载_el-upload上传springboot
- 5Elasticsearch之导入导出_elasticsearch数据导入导出
- 65款免费且出色的ai智能ppt制作软件,值得拥有!_aippt 有免费吗
- 7快乐学Python,数据分析之获取数据方法【公开数据或爬虫】_数据分析如何抓取数据
- 82020-12-07_english bruce lin博客
- 9RVC使用指南(三)-对象管理_rvc确认vmdk
- 10如何发挥人的长处(卓有成效的管理者)_德鲁克组织如何发挥和利用人的长处
业务交互网关洪峰应对之道_par eden space
赞
踩
前言
在日常工作中相信大家都会遇到数据洪峰这样的场景,例如电商平台搞活动时,大量的请求集中在一小段时间内,此时对系统造成的压力远超平常,如果不事先做好相应的防范措施,系统将极有可能崩溃、不可用。
业务背景
我们的应用系统每天都会产生大量的业务数据(可以简单理解为商品、订单等),有很多与我们合作的 外部平台 需要 订阅 这些数据,此时我们内部存在一个 数据推送平台 负责将我们系统内部数据推送至外部合作伙伴,数据链路如下:
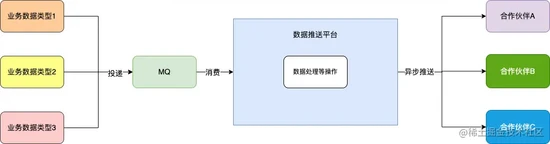
内部业务系统投递 不同类型的业务数据 至 MQ , 数据推送平台 通过消费 MQ 消息,进行一系列处理后采用 异步 的方式将数据推送至不同的合作伙伴 。
技术背景
方案选择
一般应对高并发场景常见的三板斧就是 缓存 、 熔断(降级) 、 限流 :
缓存 常用于高 QPS 的业务场景,显然不太适用这种数据推送的情况。
熔断(降级) 一般应用于调用下游服务失败,防止雪崩效应的场景。 数据推送平台 相对独立,不存在内部服务调用的情况;但是 外部的合作伙伴 确实存在服务可用性的问题,经常出现各种情况导致数据推送异常,因此是可以针对出现异常的外部合作伙伴采用 熔断(降级) 的处理。
限流 就是当高并发或者瞬时高并发时,为了保证系统的稳定性、可用性,系统以牺牲部分请求为代价或者延迟处理请求为代价,保证系统整体服务可用,该种方案与我们的业务场景极为契合。
熔断(降级) 确实可以解决部分外部平台偶发性不可用导致我们的系统资源被占用问题,但无法解决我们数据洪峰场景带来的根本性问题: 系统资源的有限性 ,因此数据推送平台选择了 限流 来应对数据洪峰的场景。
方案应用
限流的具体方案有很多,常见的有 令牌桶方式 、 漏桶方式 、 计数器方式 ,其中 计数器方式 按照实现方式又可以细分为 AtomicInteger 、 Semaphore 、 线程池 等,本次我们选择计数器的方式。
在数据推送时,如果采用同步推送的方式,推送效率将会因 MQ 消费者线程数量(默认设置20)受到极大的限制,如果采用线程池的方式而线程池的大小也不便设置(因为每个消息体的大小差异极大,从 1K 到 5M 不等)。
结合上诉因素,同时与 外部合作伙伴 对接时绝大部分场景都是采用 HTTP 的传输协议,最终推送时采用 Apache 的 HttpAsyncClient (内部基于 Reactor 模型) 异步模式 执行网络请求, Callback 回调的方式来获取推送结果。 将业务数据类型作为限流维度,根据在当前应用实例中正在推送的数量进行限流。
例如手机相关的商品数据业务类型为 PRODUCT_PHONE, 默认每种业务类型的 限流数设为 50 ,当 单台应用实例内存中 该种业务类型 正在推送 的数据量达到 50 后,该业务类型的数据从第 51 条开始都将会被拒绝,直到 正在推送 的数据量降至 50 以下。针对被拒绝的消息返给 MQ 稍后消费的状态, MQ 将会间歇性消费重试。
伪代码如下:
//该业务类型在当前节点的流量
Integer flowCount = BizFlowLimitUtil.get(data.getBizType());
//该种业务类型对应的限流
Integer overload = BizFlowLimitUtil.getOverloadOrDefault(data.getBizType(), this.defaultLimit);
if (flowCount >= overload) {
throw new OverloadException("业务类型:" + data.getBizType() + "负载过高,阈值:" + overload + ",当前负载值:" + flowCount);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
数据推送平台内增加了业务限流的一环:
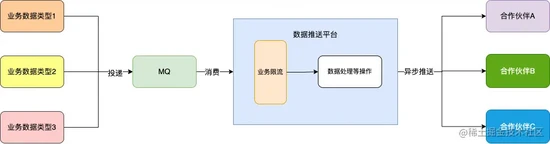
可能存在的问题
按照上述的方案,系统应对数据洪峰的 所需最大资源 = 业务类型种数 * 限流数 ,而随着业务的扩张, 业务类型种数 也在不断的增加, 所需最大资源 也会不断的增加,然而服务实例的资源始终是有限。在该种情况下,只根据业务数据类型的数据量来进行限流,效果将会逐渐变得不理想,极端场景下甚至可能出现服务崩溃的情况。
压力测试
当然以上方案存在的问题只是我们的一个设想,我们进行压测来观察推送系统的整体情况。
资源配置
应用实例数量:1
实例配置:1核2G
jvm参数:
-Xmx1g -Xms1g -Xmn512m -XX:SurvivorRatio=10 -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSMaxAbortablePrecleanTime=5000 -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly -XX:+ExplicitGCInvokesConcurrent -XX:ParallelGCThreads=2 -Xloggc:/opt/modules/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/modules/java.hpro
- 1
数据指标及工具选择
在压测时我们通常会关注 cpu 、 内存 、 网络io 、 数据库 等多项数据指标,在不考虑 网络io 、 数据库 等外部中间件因素的情况下, cpu 、 内存 是我们观察系统稳定性最为直观的数据指标。
Arthas 是 Alibaba 开源的 JAVA 诊断工具,具体使用可阅读官方文档: arthas.aliyun.com/doc/。我们使用 Arthas 来对服务进行观测,登录服务器打开控

