
- 1php8.0安装拓展amqp_宝塔 php8.0安装rabbitmq扩展
- 2福布斯2024年十大AI趋势预测:颠覆性创新与挑战即将到来(中文概要版)_2024年十大科技趋势
- 3联邦学习后门攻击总结(2019-2022)_联邦学习无目标攻击
- 4AI程序员崛起:人类程序员的未来何去何从?_人工智能时代下程序员何去何从
- 5Appium环境搭建超详细教程
- 6Pytorch~ubuntu20.04搭建_ubuntu20.04下安装pytorch
- 7【网络】传输层TCP协议 | 三次握手 | 四次挥手_tcp报文和tcp伪首部
- 8because it is a JDK dynamic proxy that implements问题 看这一篇就够了_because it is a jdk dynamic proxy that implements:
- 9无锡VALSE 2023感悟收获(NLP方向)_valse2023汇报ppt
- 10安全架构设计理论与实践相关知识总结
冯仕堃:预训练模型哪家强?百度知识增强大模型探索实践!
赞
踩

作者 | 冯仕堃 百度 主任架构师
来源 | DataFunTalk
导读:近年来,预训练语言模型在自然语言处理领域发展迅速,并获得广泛应用。本文将介绍百度基于知识增强的语义理解ERNIE的实践探索,主要内容包括首个知识增强大模型ERNIE 3.0,以及在语言生成、跨模态理解、多语言理解等方向取得的技术突破,最后分享基于ERNIE的百度应用实践。
具体将从以下几方面展开:
语义理解技术简介
ERNIE技术原理
ERNIE最新进展
ERNIE应用实践
01
语义理解技术简介
我们从语义理解技术开始,了解它的挑战、实现、演变,以及在预训练时代下的发展历程。首先我们来看看语言理解任务的挑战。
1. 语义理解任务的挑战

“我们这边快完了”这几个字从字面来看是一模一样的,但是它们背后的语义是不一样的。如上图的右侧所示,我们能看到的只是表征人类认知符号的语言的一小部分,但它背后其实蕴含了对这个真实世界的映射(认知)。语言有很大的复杂性和多样性,只有对它背后的语义知识有更好的理解,才能处理好后续更多的语言理解任务。
2. 语义理解任务的实现
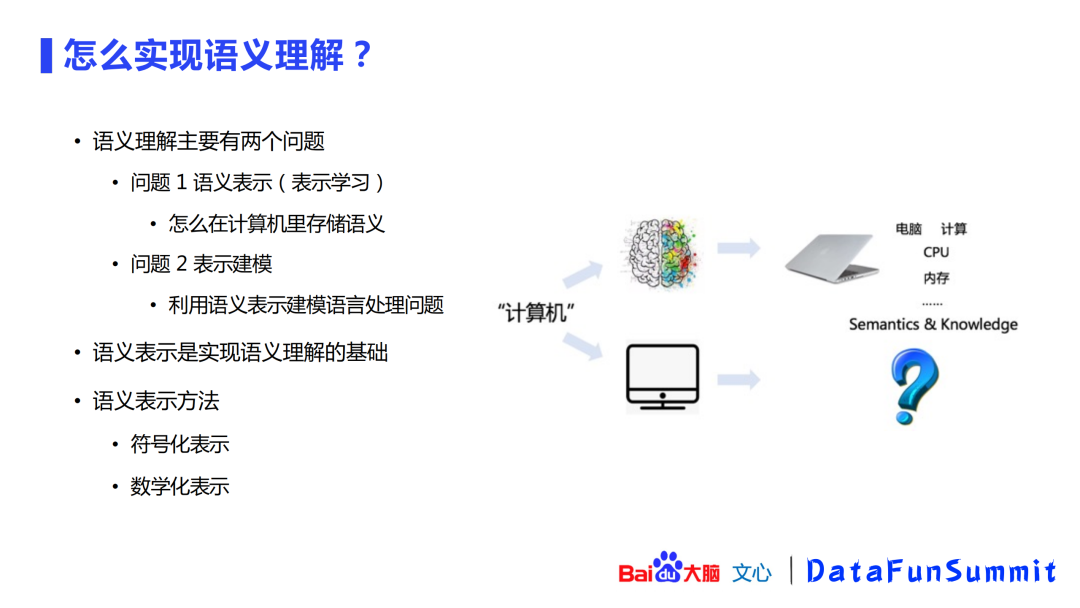
可以把语义理解归纳成两个问题:
如何进行语义表示
如何对表示进行建模
其中语义表示是最重要的,它是实现语义理解的基础。语义表示在发展过程中产生了两大类方法:
符号化表示(形式化表示)
数学化表示
3. 语义理解任务的演变
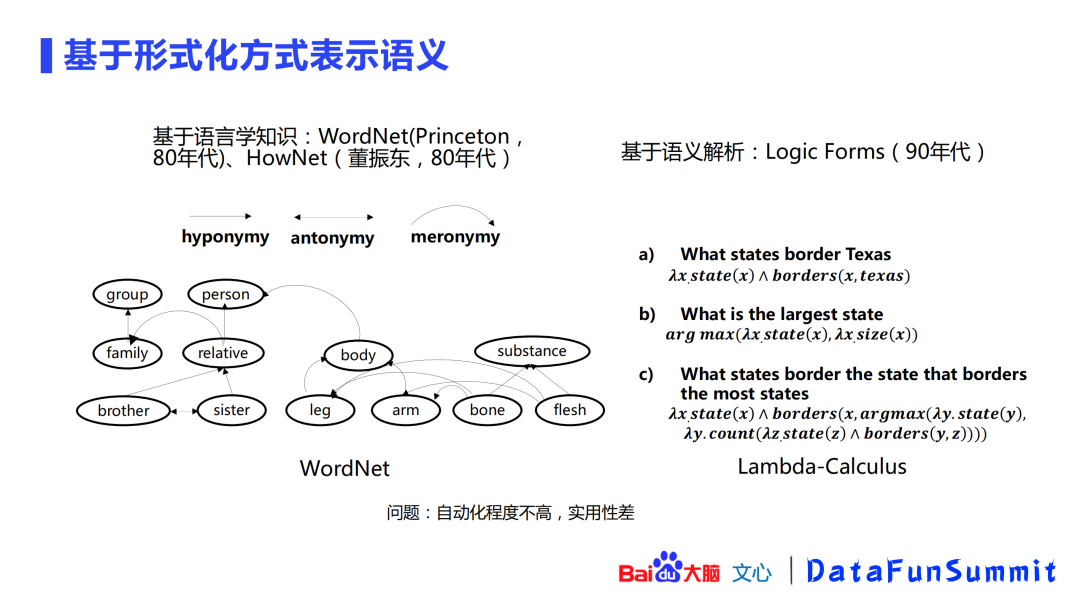
基于形式化的表示方法可以追溯到80年代基于语言学知识的WordNet、HowNet方法,以及90年代基于语义解析的Logic Forms。这类方法的问题在于,基本都要靠人工来处理,自动化程度不高,在实际应用中的效果也比较差。

后来出现了基于统计的方法,即使用one-hot表示对词进行稀疏(sparse)的编码,这种方式的问题在于:两个不同的词在表示后的两个向量间距离接近于0,不能很好的把语义相近的词进行聚合。为了解决这个问题,1954年Harris提出一个假设:如果两个词的上下文比较接近,那这两个词的语义就会比较相近。基于这一点,百度使用了基于语言共现的统计表示方法来对词语进行向量表示。如利用搜索引擎得到词语“计算机”相关的top10文本,统计文本中的TF-IDF等特征值,得到相关词的权重,排序后取top-k个词语,使用这top-k个词及其权重来对“计算机”进行向量表示。
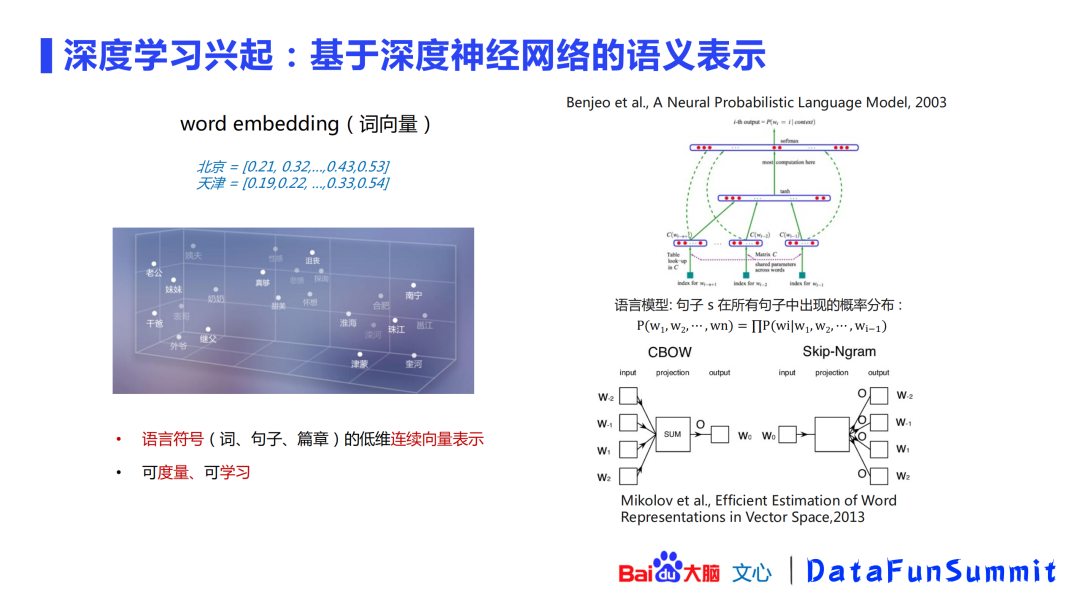
随着深度学习的发展,出现了word2vec这类稠密(dense)的深度学习语义表示方法。这类方法的优点在于:一是它是一种稠密表示,二是学习过程中考虑上下文,能将类似的词语在向量空间中尽可能的表示在一起。
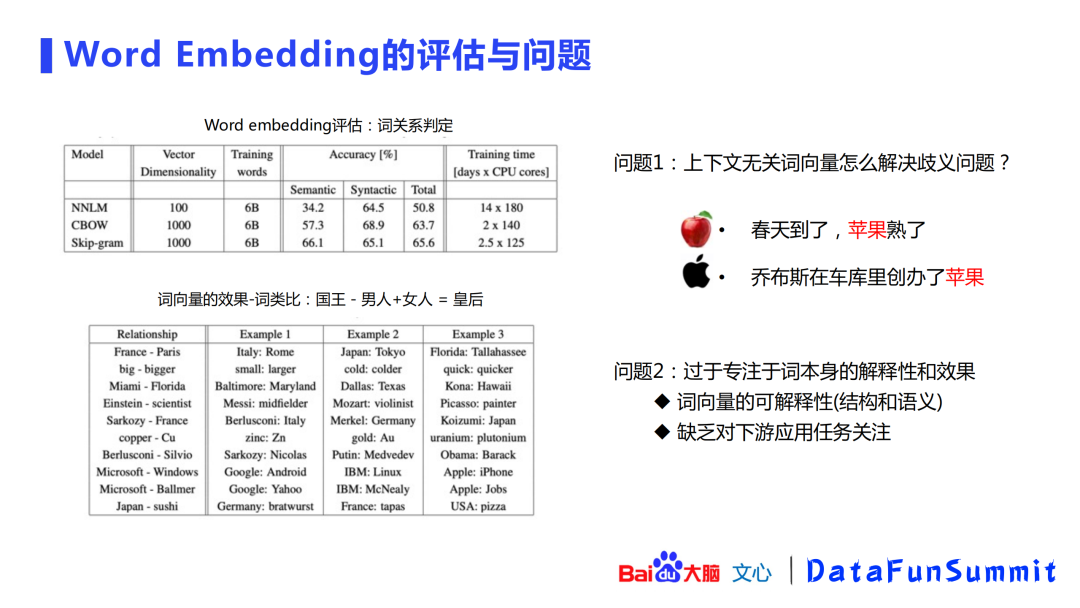
在方法提出的当时(2012年),该方法在词类比的效果上是比较惊艳的,如“国王-男人+女人=皇后”的例子。但是由于上下文无关且embedding方式是静态的,这类方法比较难解决歧义问题,如“苹果”在不同语境里的语义是不一样的。该方法过于关注词本身的可解释性,缺乏对下游应用任务的关注。
4. 预训练时代下的语义理解技术
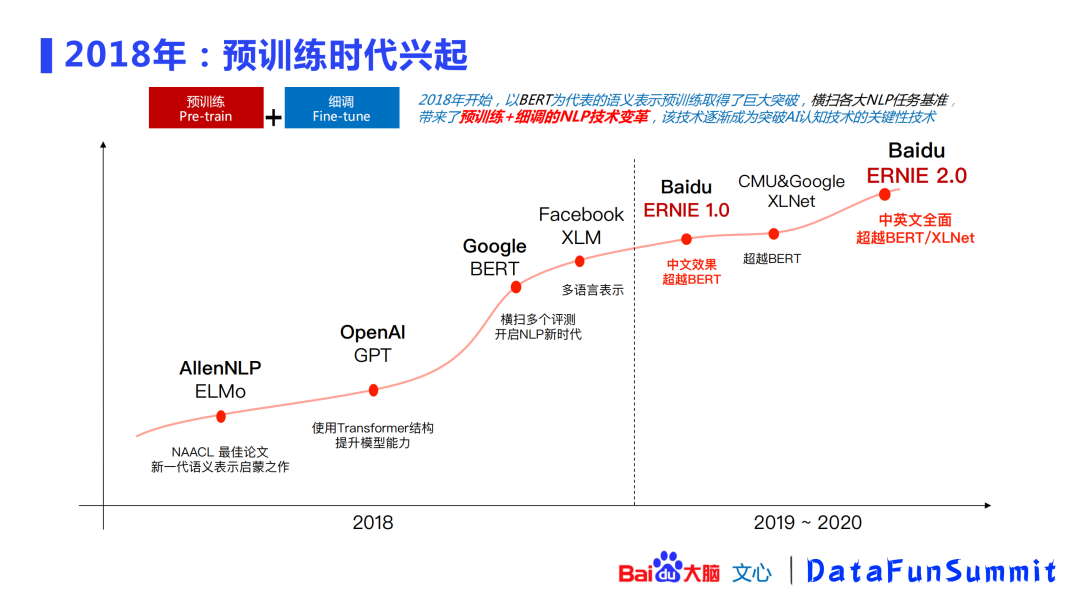
2018年有一系列的经典文章发表,掀起了预训练时代语义理解新范式的革新,这种范式主要是从ELMo、GPT、BERT发展起来的一种“预训练+微调”的范式,它取得了巨大的突破,横扫了GLUE上多个NLP测评,带来了新的技术变革。
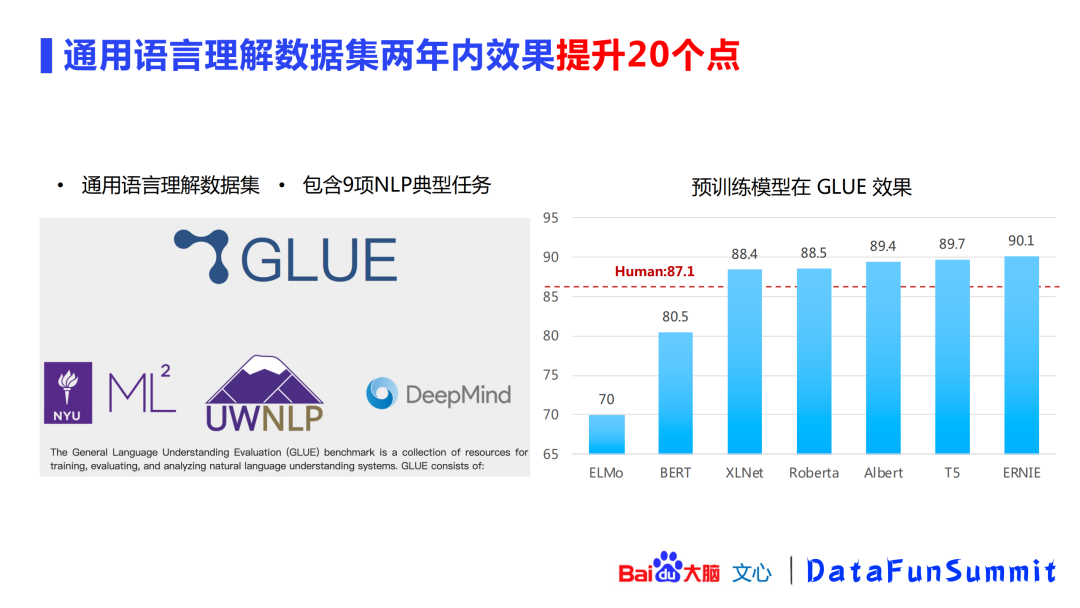
下面来了解一下基于这种预训练方法在近两年内提升的效果。首先GLUE是一个通用语言理解的数据集,包含9项NLP典型任务。从右侧图中可以看出,从最开始的70%提升到了90%,一共提升了20个点,这个提升是非常显著的。
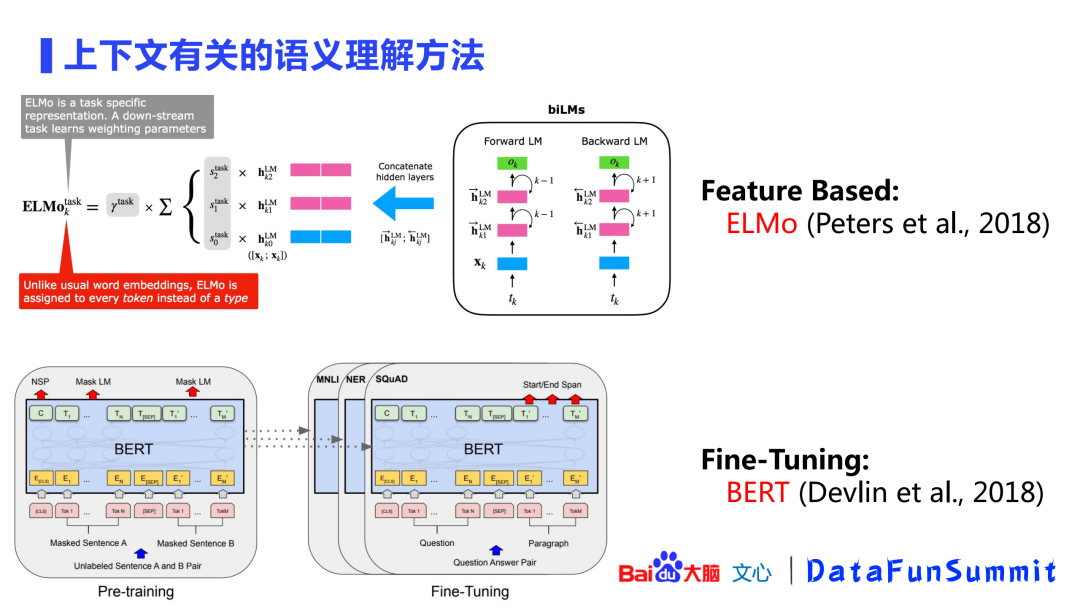
图中展示了两个经典的上下文有关的语义理解方法:
ELMo:2018年提出的ELMo以feature-based(基于特征)方式对文本进行语义理解。ELMo的作者首先使用双向LSTM(BiLSTM)从语料中预训练了一个模型,文本会先通过这个预训练语言模型得到一个表示并拼接起来,然后再进入下游任务进行微调。它的梯度在拼接时被切断了,所以不会回传到之前的双向LSTM模型中,所以这是一个feature-based的方法。
BERT:同年(2018年),ELMo很快被BERT取代。BERT也提出了“预训练+微调”的方式,并且在微调时允许下游任务的lose回传到预训练中的transformer里面,这种方式比ELMo的效果更好。
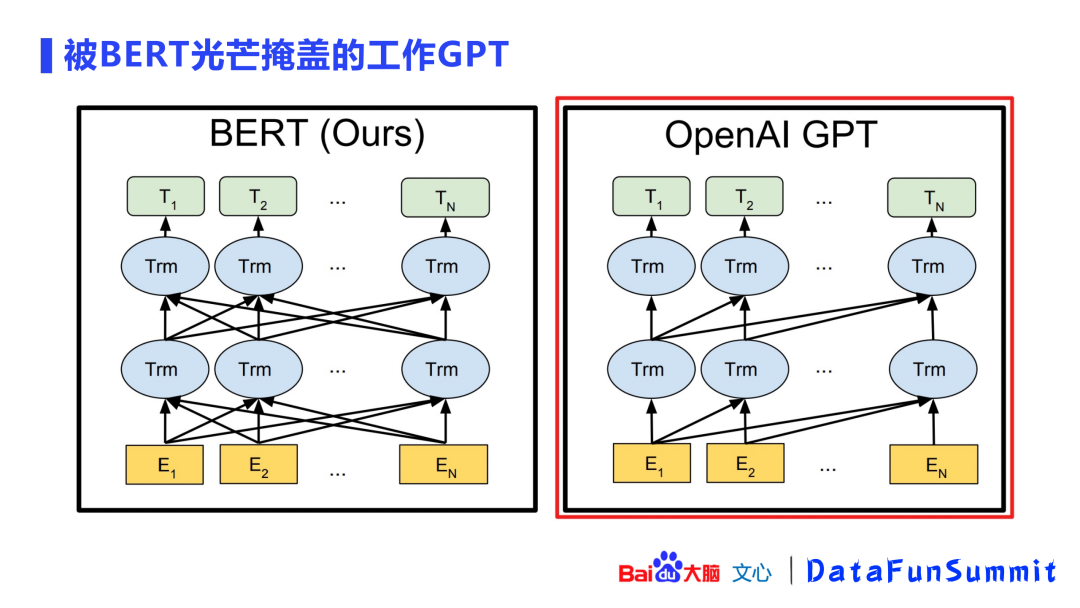
此外,还有一个不容忽视的工作:GPT。GPT与BERT最大的区别在于:GPT是一个单向的语言模型。如上图所示,E2这个token能看到的感受野,即attention位置的只能往前追溯,而不可以往后,但是BERT可以往后。

虽然GPT的效果没有BERT好,但是OpenAI希望通过“大算力”+“大数据”+“大模型”的方式创造“奇迹”。OpenAI训练了一个1700亿参数的超大规模预训练模型,发现该模型除了语义理解以外,还能做小样本学习(few-shot learning),可以广泛的处理各类任务。在训练模型的时候并不知道这个模型要用于什么任务,并且任务也不需要提供微调的数据。如GPT-3可以用于搜索引擎中的QA问答,用户提出问题以后,GTP-3可以直接生成回答。图中列举了十几个GPT-3号称可以解决的问题,给我们展示了通用AI的一条可能可行的路径。

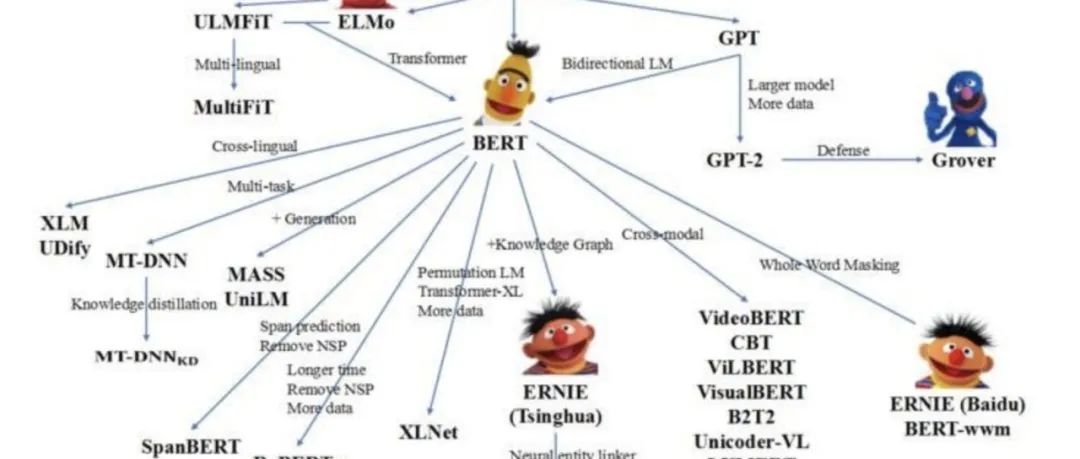
上图展示了一系列BERT之后的预训练工作。在预训练语言模型分类中,可以分为:
单向LM(语言模型):GPT、GPT-2、GPT-3
双向LM:BERT、Roberta
端到端LM:T5、MASS
持续学习(continuallearning)+知识增强(knowledge):ERNIE、ERNIE 2.0、ERNIE 3.0
基于这些基础模型,学术界做了下列扩展:
多语言模型:XLM、InfoXLM、ERNIE-M
多模态模型:VideoBERT、UNITER、ERNIE-ViL
模型压缩:MiniLM、TinyBERT、ERNIE-Tiny
还有一些基于特定任务的预训练模型:
相似度任务:SentenceBERT、ERNIE-Sim
生成任务:UniLM、MASS、ERNIE-Gen
领域模型:BioBERT、SciBERT、ERNIE-Health/Law/Financial
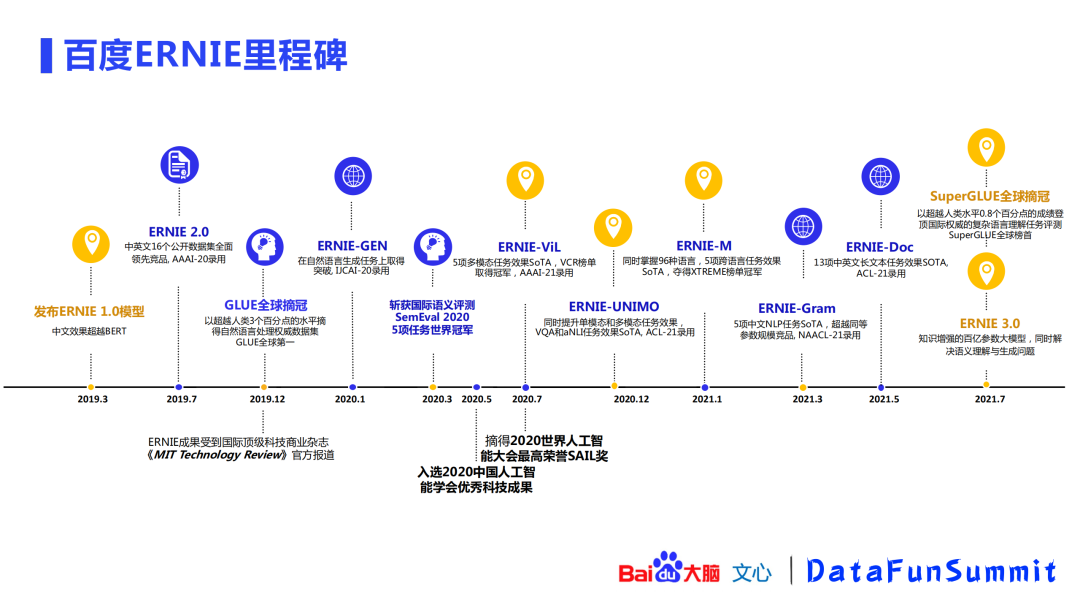
百度在2019年3月提出了ERNIE 1.0模型,在同年7月提出了ERNIE 2.0模型,并在12月刷新了GLUE榜单,并被《MIT Technology Review》官方报道。之后,百度在模型扩展方面及特定任务模型方面都进行了深耕,如ERNIE-GEN、ERNIE-ViL、ERNIE-UNIMO、ERNIE-M、ERNIE-Gram、ERNIE-Doc等模型,这些模型也都取得了SOTA成绩。在比赛方面,百度斩获了SemEval2020的5项任务冠军,并入选了2020中国人工智能学会优秀科技成果,也获得了2020世界人工智能大会最高荣誉SAIL奖。2021年7月,百度发布了基于知识增强的百亿参数大模型ERNIE 3.0,解决了语义理解与生成问题,并在SuperGLUE任务测评中获得全球第一。

以上是百度ERNIE的获奖情况。
02
ERNIE技术原理
下面将进入第二部分--介绍ERNIE的技术原理。
1. ERNIE背景技术介绍

首先我们来对BERT的技术原理进行简单的剖析。BERT的基本模型还是Transformer模型,它的预训练任务是完形填空和上下句预测。这里的完形填空是简单的15%的随机的字的掩码,模型需要去预测被掩码的字是什么。但是这种方法存在着一个问题:它只学习到了局部的语言信号,缺乏对句子全局建模,难以学到词、短语、实体的完整语义。
2. ERNIE 1.0

由此,百度在2019年提出了知识融合的思路。ERNIE(Enhanced Representation throughkNowledge IntEgration)指基于知识融合(knowledge masking)的新一代语义表示模型。ERNIE在做masking的时候,是以knowledge masking的方式,对词、短语、实体的完整语义进行masking的。
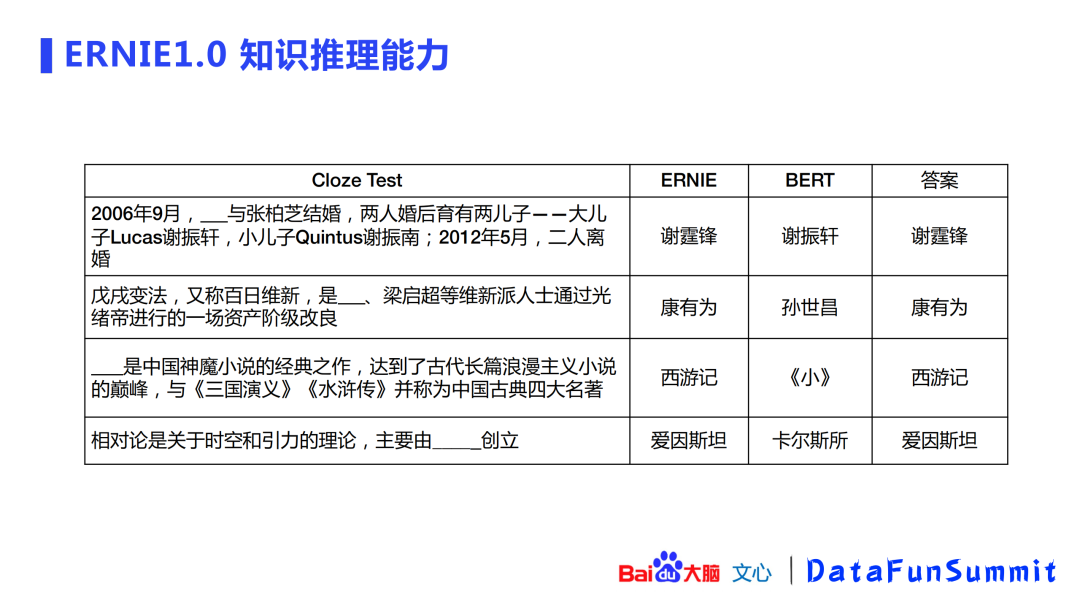
实验发现,ERNIE比BERT具有更好的知识推理能力。

在ERNIE 1.0的基础上,百度尝试用更多的知识来得到更好的模型。如通过构建多个层次的任务,来挖掘语料中的词法、结构、语义的潜在知识,并且还要在学习新知识的时候不遗忘旧知识。
3. ERNIE 2.0
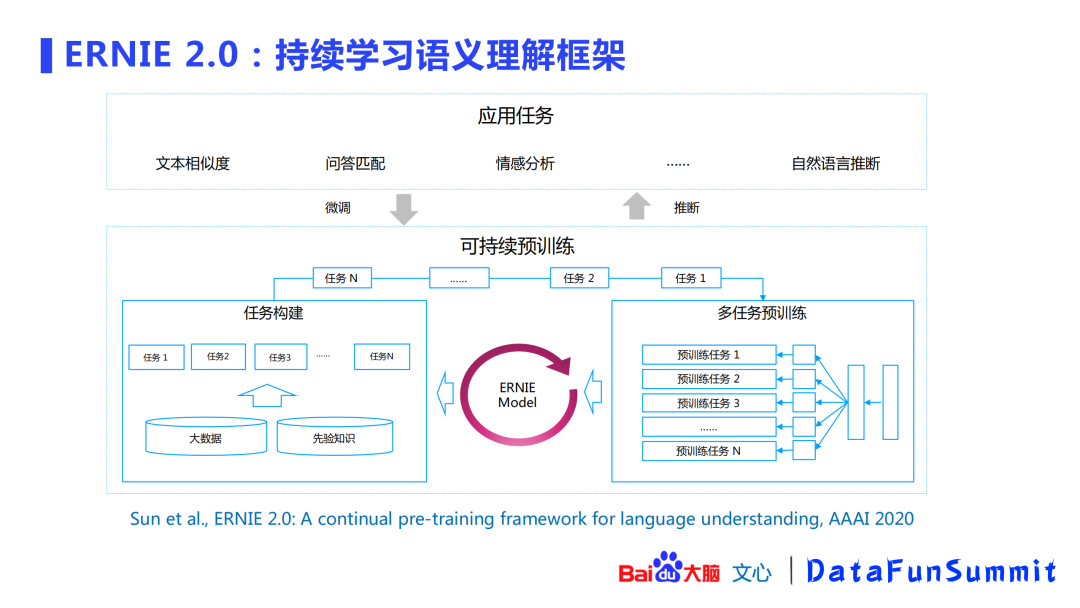
在ERNIE 2.0,百度提出了持续学习的语义理解框架。在大数据和先验知识的基础上,构建了句法、语法、语义相关的一系列任务,这些任务会在框架内持续的训练学习,更新整个ERNIE模型,从而对下游任务有一个更好的理解。
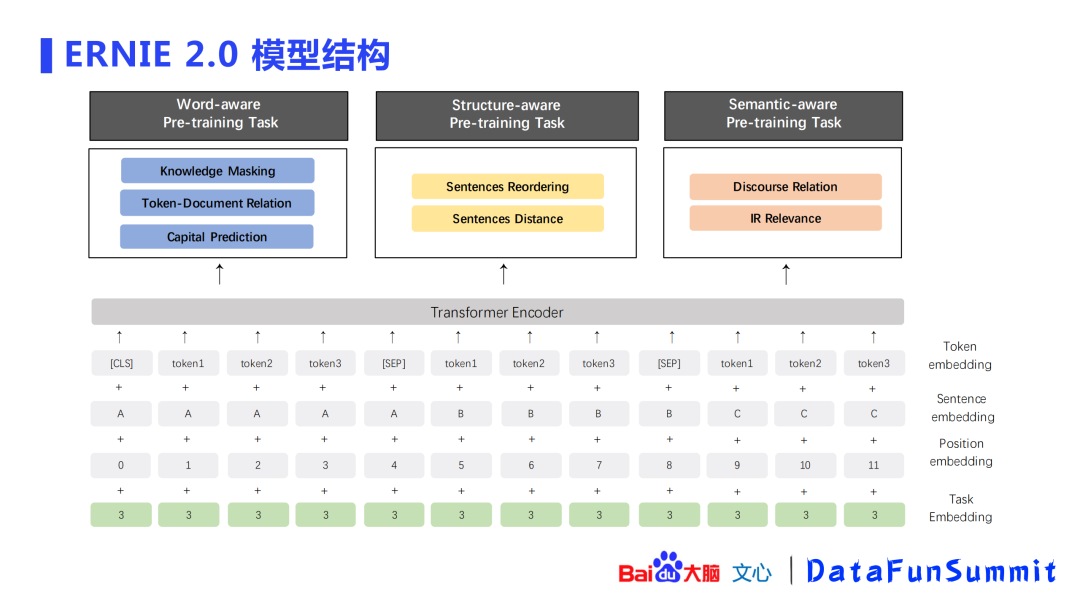
ERNIE的框架也是基于Transformer,基于这个框架,百度构建了三大体系的预训练任务(pre-training task):词感知(word-aware)、结构感知(structure-aware)、语义感知(semantic-aware)。
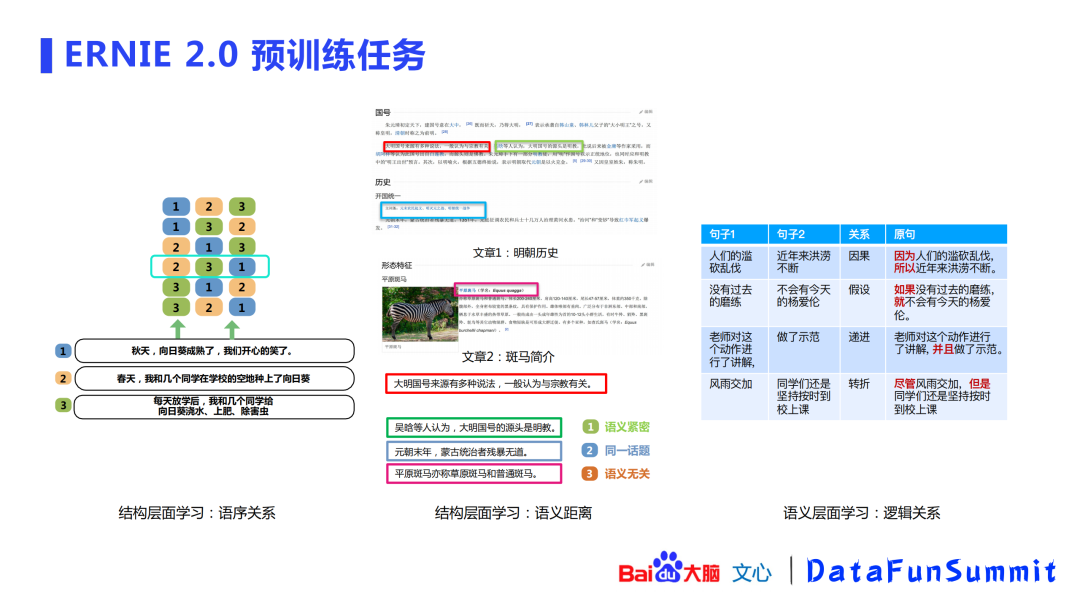
上图(左)展示了结构层面的语序关系:需要让ERNIE模型知道“春天播种,夏天浇水,秋天收获”的逻辑,这样模型才能更好的“理解”文本含义,故设计了文本语序的预测任务。
中间图片展示了结构层面的语义关系:百度从大规模语料中设计了“语义距离”的任务:
语义紧密:一篇文章中相邻的两个句子,可以认为是语义紧密。
同一话题:属于同一篇文章的两个句子,可以认为是同一话题。
语义无关:两个句子在不同文章中,可以认为是语义无关。
上图(右)展示了语义层面的逻辑关系,这些关系(因果、假设、递进、转折等)是通过无监督的方式从大规模语料中获取的,希望ERNIE能从中学习到一些逻辑知识。
03
ERNIE最新进展
接下来将介绍ERNIE 3.0的最新进展。
1. ERNIE 3.0成长路径
ERNIE 3.0的定位为知识增强的大模型。模型都是在不断持续学习的,ERNIE 2.0也在不断进行版本迭代,每一个迭代都比之前有更好的提升。
在ERNIE 3.0时代业界出现了一些大模型,这些大模型有两个共同点:一是仅仅只是读更多的文字,比如扩大语料,这是模型增长的前提;二是很多大模型都是使用auto-regressive(自回归)方式进行的,GPT、盘古这些都使用了这种方式。百度ERNIE希望除了从更多更优质的文本中学习以外,还希望模型能从知识图谱学习到世界知识,这个世界知识能够更好的促进下游任务,除了文本生成以外,还希望能保留模型的理解能力。
2. ERNIE 3.0整体框架
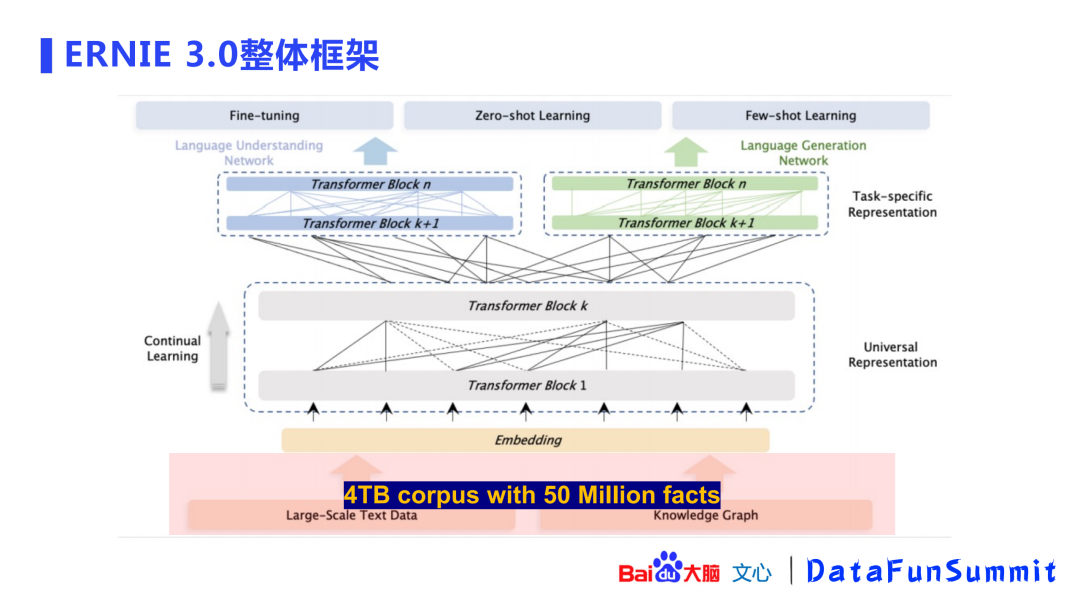
ERNIE 3.0的整体框架显示:模型除了使用大规模语料外,还引入了百度知识图谱(包含5千万事实),共包含4TB语料。
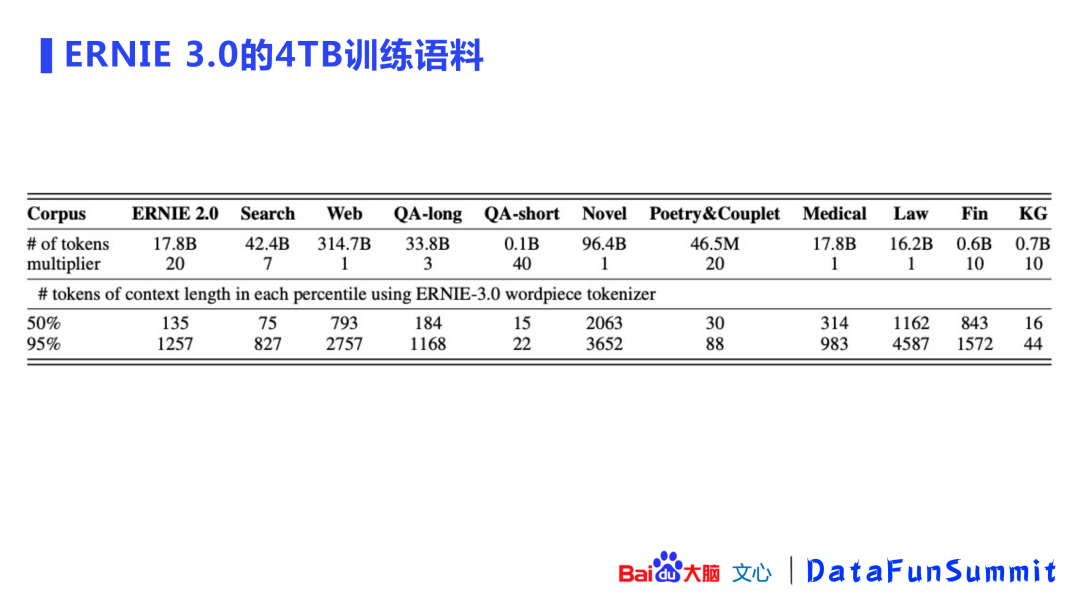
上图展示了ERNIE 3.0 4TB语料的来源,除了ERNIE 2.0中的对话、百科、wiki等语料之外,还加入了百度自有的搜索数据、互联网的web数据、QA问答的长文本/短文本,以及小说、诗歌、对联、医疗/法律/金融等领域数据,最后还引入了知识图谱的数据,并对优质数据进行了加权以便更好的引入这些数据。
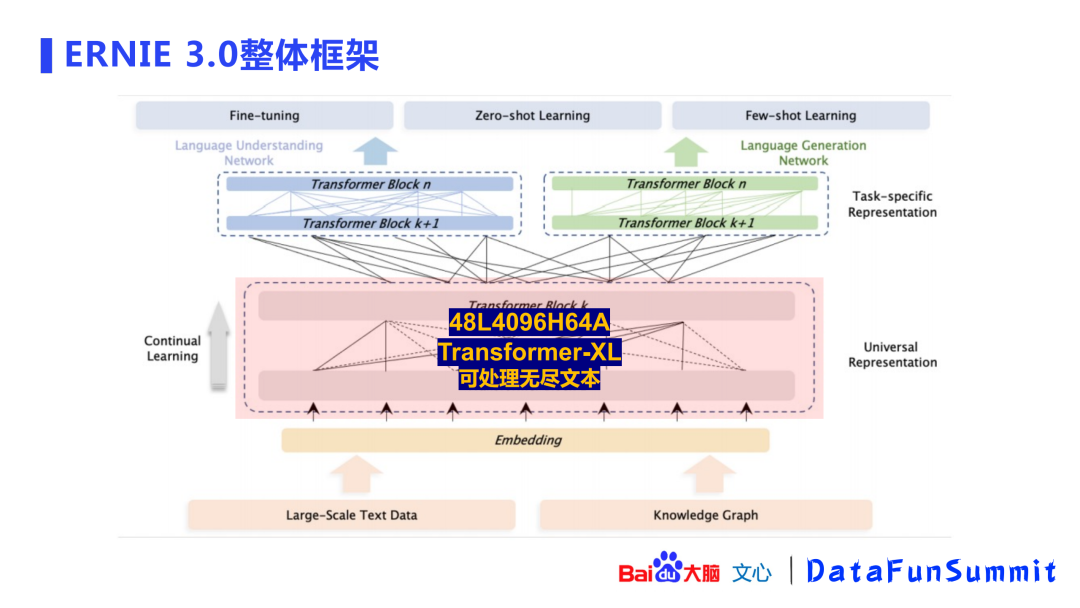
在准备好语料之后,ERNIE建立了一个持续学习的框架,该框架基于Transformer-XL模型。之所以使用Transformer-XL结构,是因为该结构可以处理无尽文本。GPT-3中只能处理2048长度的文本,Transformer-XL中采用了片段递归(segment-level recurrence)机制使其可以处理基本无穷的文本。模型使用了一个深层(48层)网络,4096的hidden size,64头的attention。
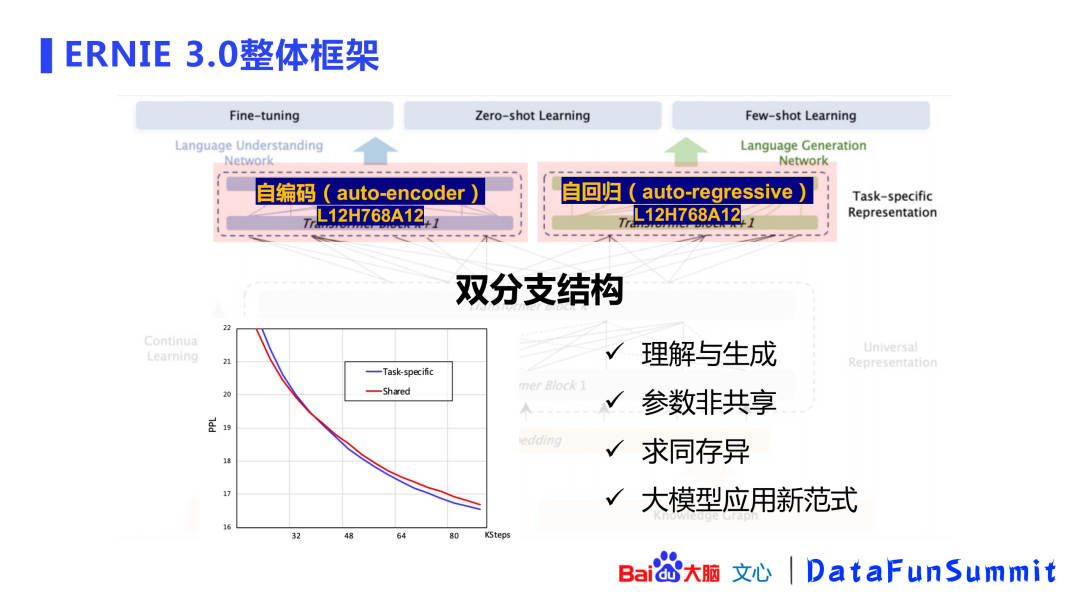
这个模型会产出一个双分支结构的面向任务的表示(task-specific representation)。ERNIE的初衷是在一个模型内能完成理解和生成两个任务,理解任务使用了自编码的方式,生成任务使用了自回归的方式。两个任务模型的参数是非共享的(参数非共享的方式具有更好的效果)。百度在小规模语料上做了验证,非共享方式取得了更低的PPL,并且后面的曲线是逐渐扩大的,即优势逐渐扩大。这是一种求同存异的模式,“同”在于做了一个universal representation,“异”在于双分支结构。自编码和自回归的模型参数为L12H768A12(网络深度为12,768 hidden size,12头attention),这是ERNIE-based的模型,百度希望通过这个模型给业界带来大模型的应用新范式。
Universal representation是一个非常庞大接近百亿规模的模型,在中小企业是比较难应用的。如何让这些企业也能使用大模型呢?可以通过百度提供表示(representation)传输到用户,用户可以使用小的模型进行微调(fine-tuning),只更新上层小模型的参数,不会影响大模型,即可以使用比较少的资源获取大模型的能力。
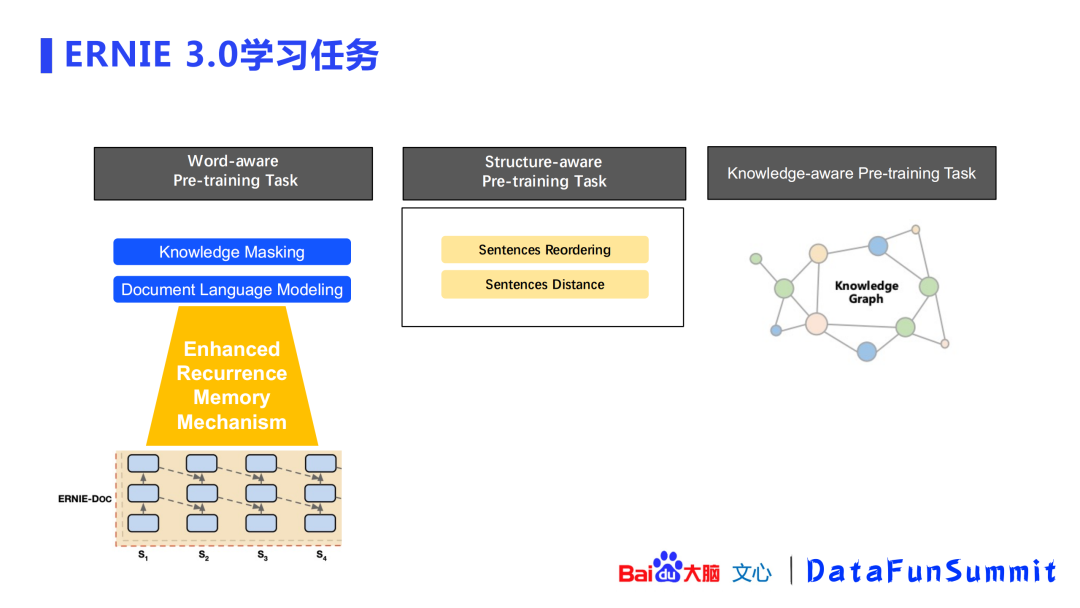
上图展示了ERNIE 3.0的学习任务,共分为3部分:
词感知(word-aware)预训练任务:沿用ERNIE 1.0的知识掩码(knowledgemasking);新增了文档语言建模 (document language modeling),采取了增强自循环记忆机制(enhancedrecurrence memory mechanism,可自行查看ERNIE-doc相关论文)来增加模型的感受野。
结构感知(structure-aware)预训练任务:语义重组(semantic reordering)、语义距离(semantic distance)。
知识感知(knowledge-aware)预训练任务:是一个文本与知识平行的预训练方法。
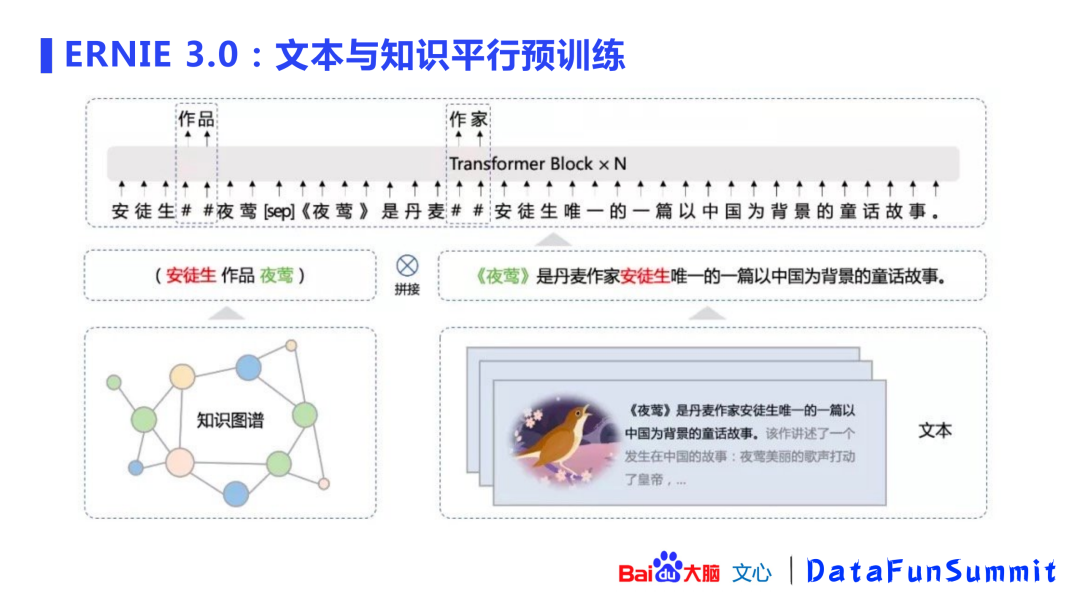
对于一段文本,会利用知识图谱进行实体链接(entity linking),得到句子的SPO(Subject-Predicate-Object,实体关系对),并与原始文本进行拼接(concat),再使用拼接文本进行下游的knowledge masking任务(ERNIE 1.0)。这种方式在知识类任务以及信息抽取中都有比较显著的收益。
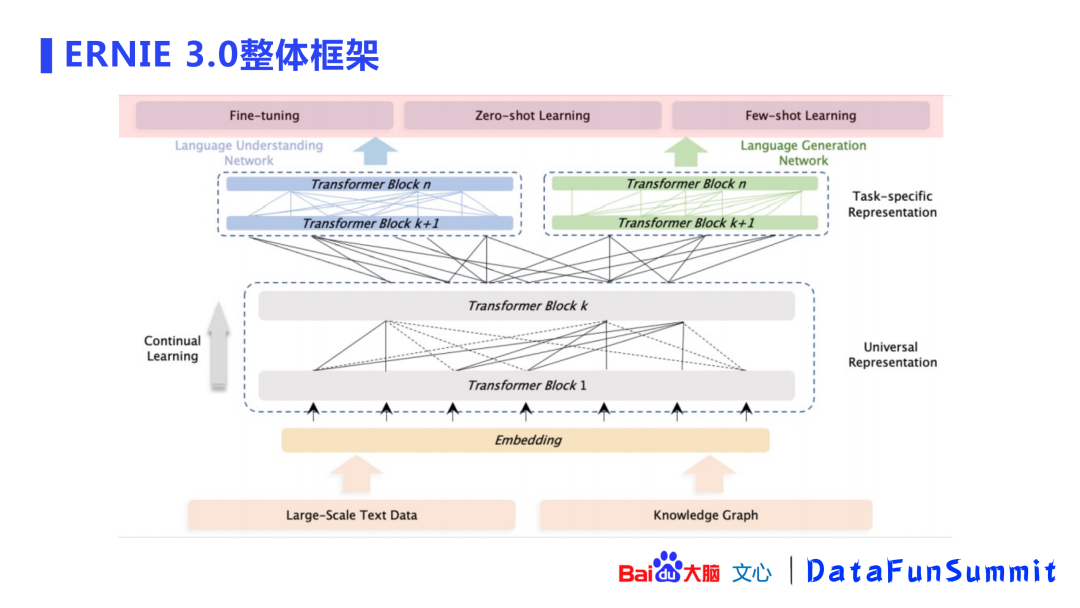
在双分支结构之后,可以做很多任务包括:微调(fine-tuning)、零次学习(zero-shot learning)以及小样本学习(few-shot learning)。
以上即是ERNIE 3.0的整体框架。
3. ERNIE 3.0的训练
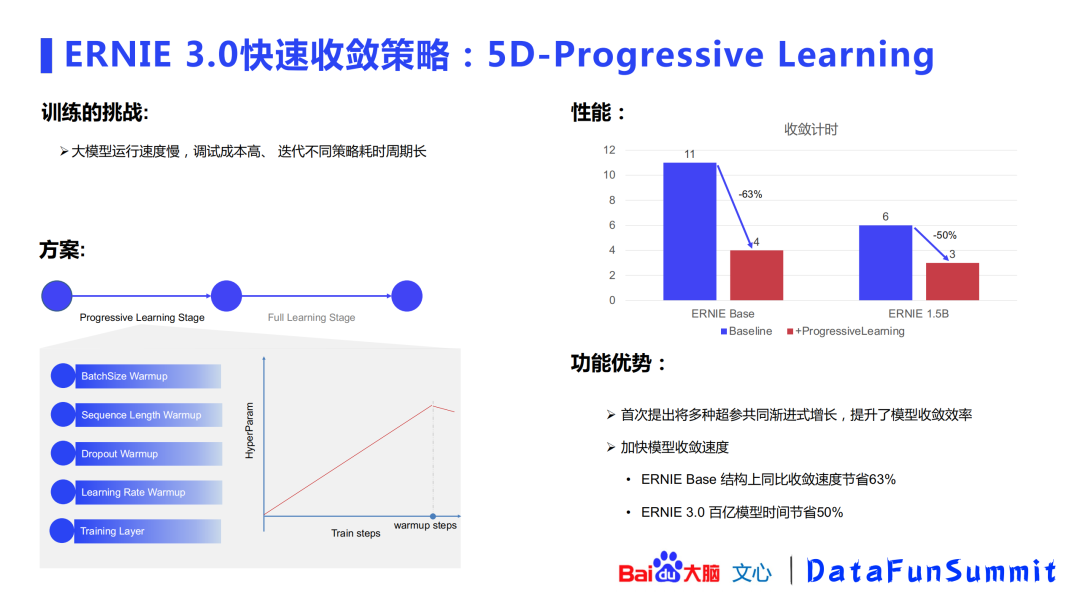
有了框架之后,该如何训练?大模型的训练面临着很多挑战:运行速度慢、调试成本高、迭代不同策略耗时周期长等。针对这些问题,百度提出了5D-progressive learning的概念:将batch size、sequence length、dropout、learning rate、training layer等5个元素进行共同渐进式增长,通过小数据验证发现该方式同比收敛速度节省63%(在百亿模型上可节省50%时间)。
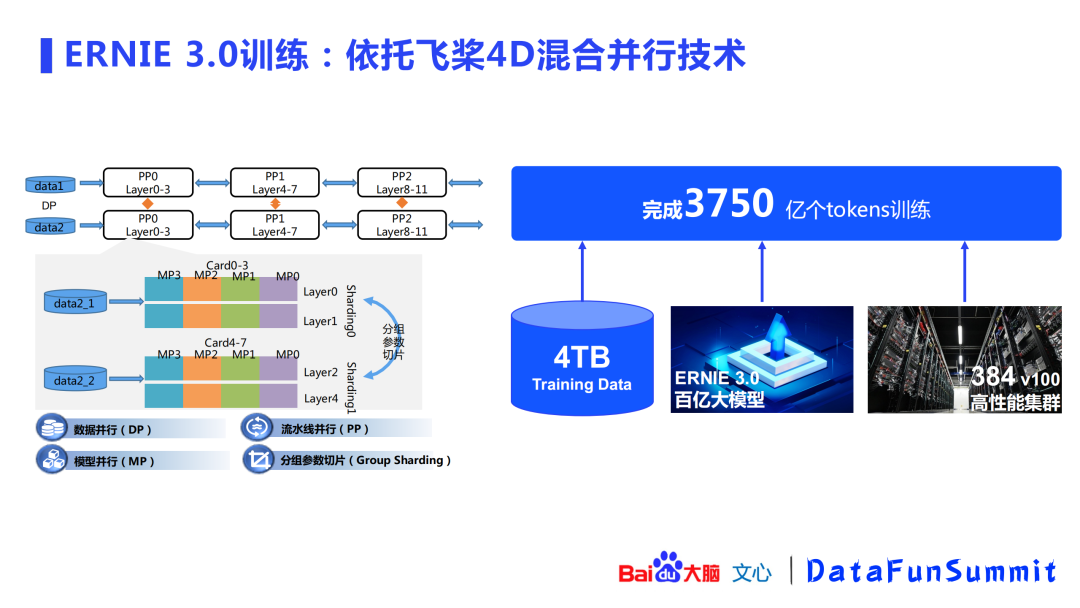
大模型的训练需要依赖很多分布式技术,ERNIE 3.0的训练即依托于百度飞桨的4D混合并行技术。4D混合并行技术包括:数据并行、流水线并行、模型并行以及最后的分组参数切片(group sharding)。(这套技术是为千亿模型准备的,ERNIE 3.0的定位为百亿模型,使用数据并行和分组参数切片即可。)其中分组参数切片避免了多机之间的通信,可以取得较大的提升效果。最终,基于4TB的训练数据,结合ERNIE 3.0百亿参数大模型,在384个V100组成的高性能集群上完成了3750亿个tokens的训练。
4. ERNIE 3.0性能评估
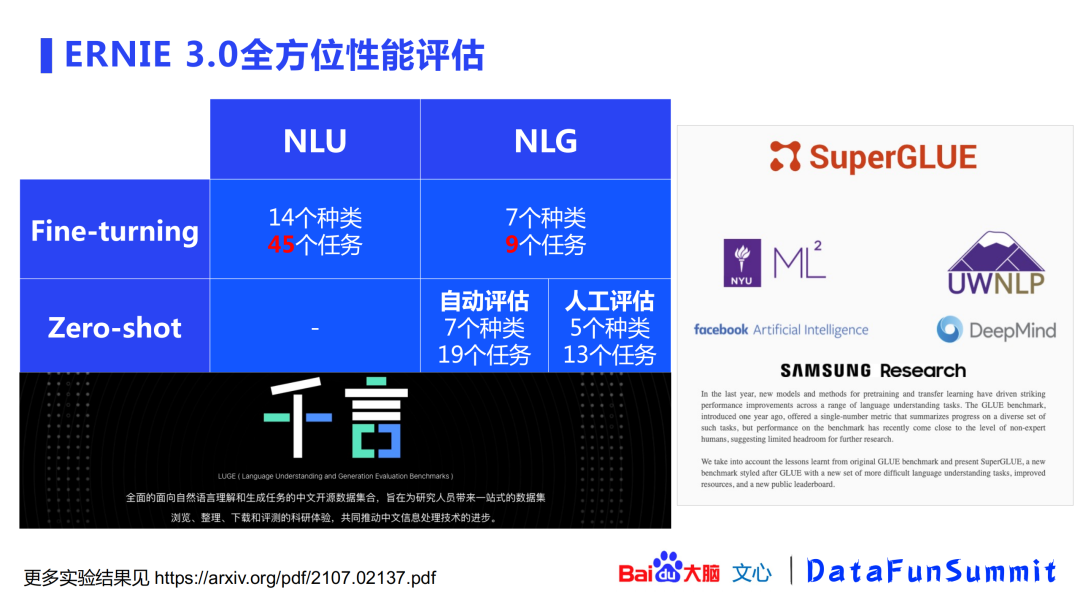
上图展示了对完成训练以后模型的全方位性能评估,主要分为NLU和NLG、微调(fine-tuning)和零次(zero-shot)两个纬度,同时也在中文“千言”数据集(全面的面向自然语言理解与生成任务的数据集)和英文superGLUE数据集上进行验证。
微调(fine-tuning)层面:在NLU方向共找了14个种类共45个任务进行验证,NLG方面涵盖了7个种类的共9个任务。
零次(zero-shot)层面:在NLG方向,主要利用深层分支对7个种类的共19个任务进行了自动评估。此外,还对模型进行了人工效果评估(包括5个种类的共13个任务)。
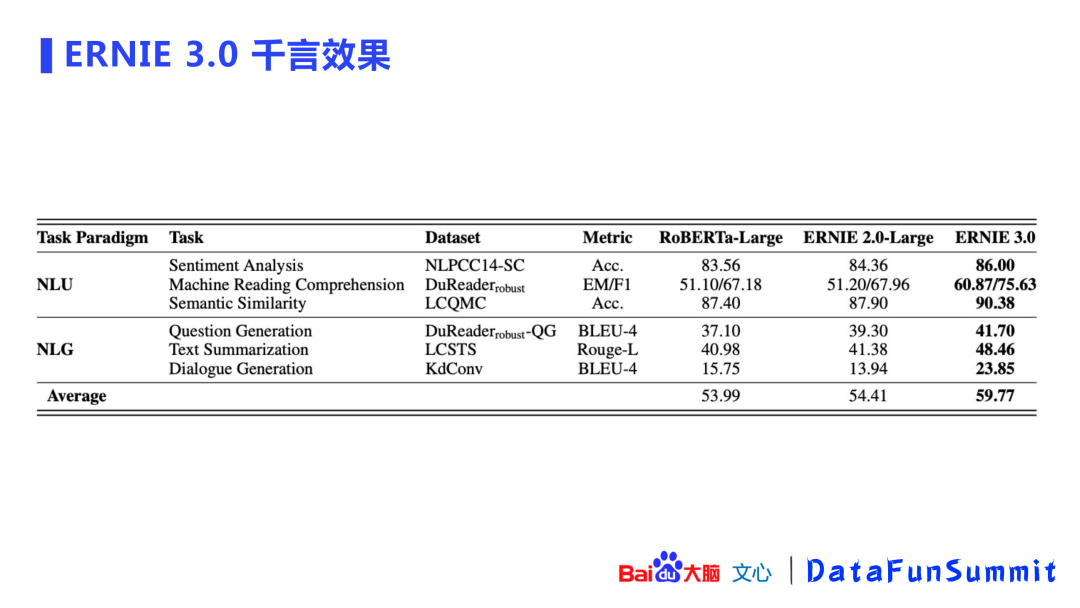
上图展示了模型在“千言”数据集上的效果(覆盖了NLU和NLG共六个数据集),ERNIE 3.0的提升效果也是非常明显的。

上图展示了ERNIE 3.0 在fine-tuning的21个种类共54个任务(NLG和NLU)上都刷新了SOTA。其中在超过50%的数据集上都有几个百分点的提升。
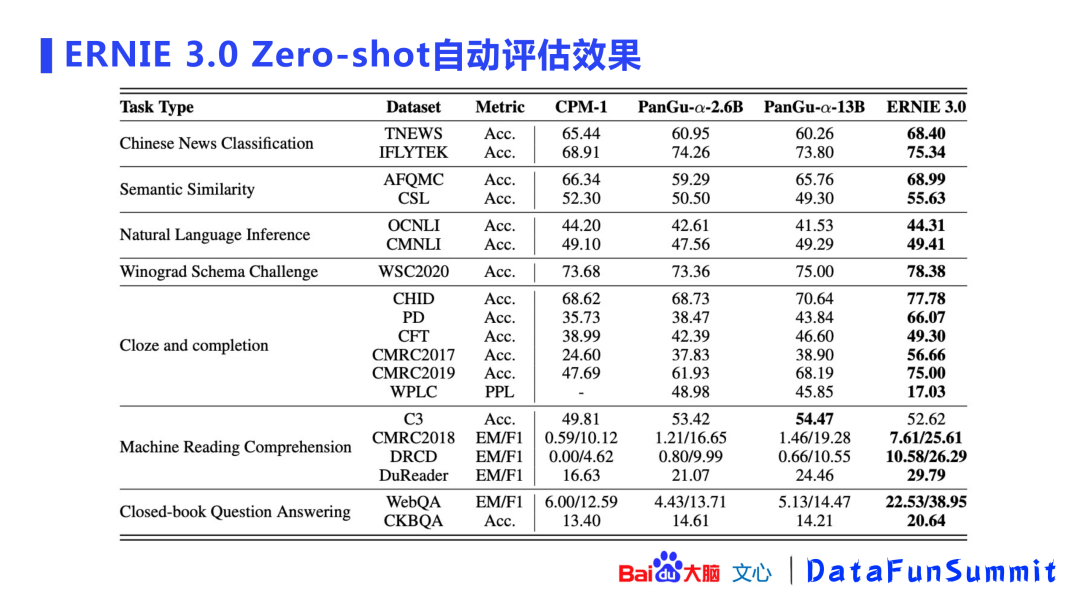
上图展示了ERNIE 3.0 零次学习的自动评估结果。对比的对象主要包括CPM、盘古等业界大模型,ERNIE 3.0也保持了领先的优势,最大可以提升几十个百分点。
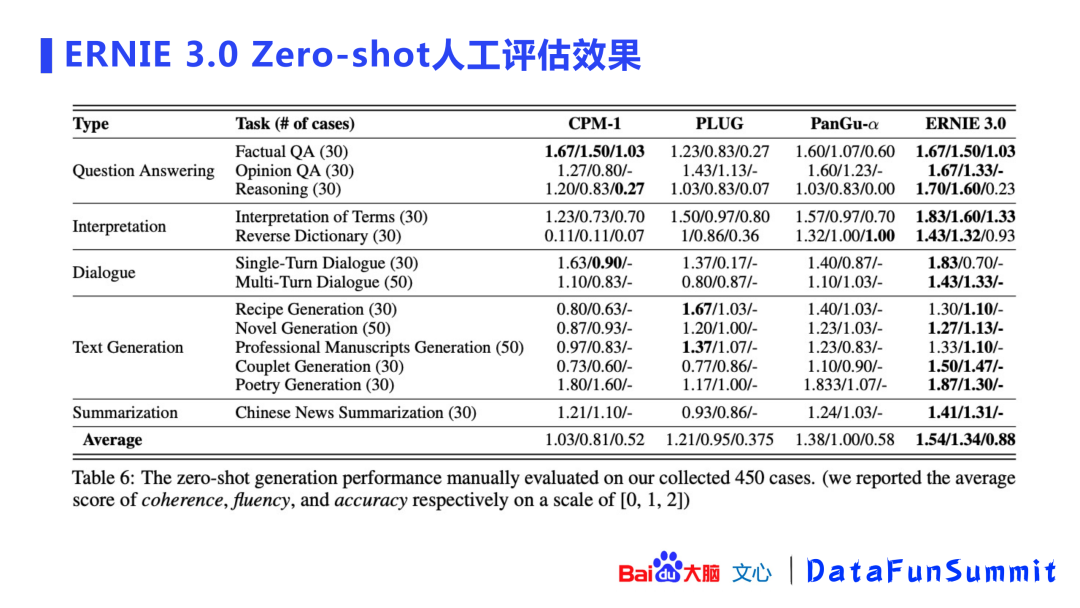
在ERNIE 3.0 零次学习的人工评估方面:共准备了450个case进行盲评,主要对生成内容的相关性、内容流畅度以及内容准确性3个方面进行评分(分数为0,1,2)。评估结果显示ERNIE 3.0非常有优势。
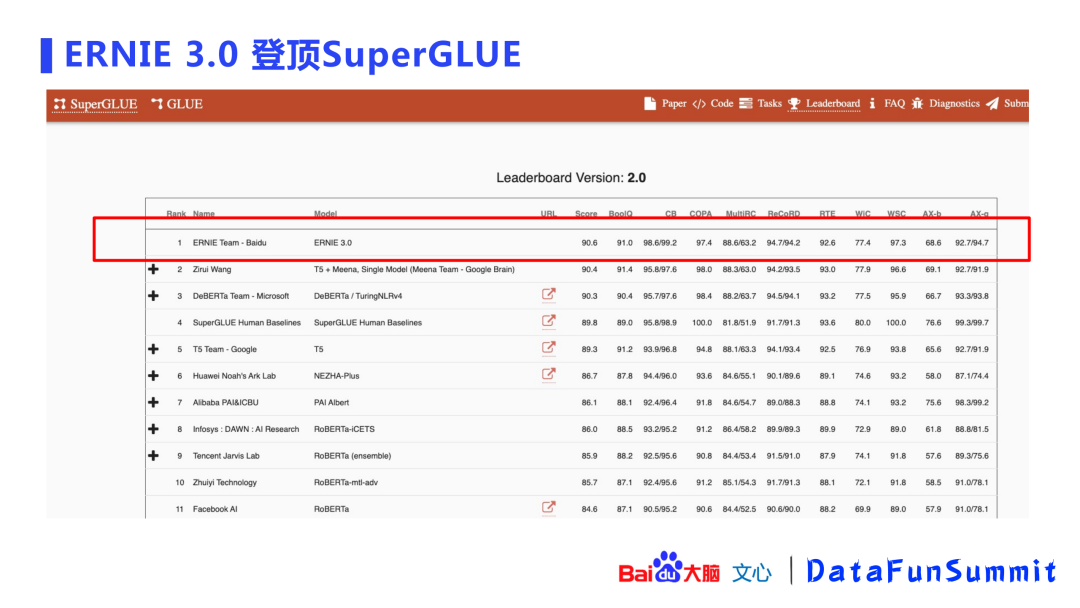
ERNIE 3.0在英文数据集(superGLUE)上登顶了榜单,力压T5、Meena、DeBERTa等模型。
5. ERNIE 3.0效果展示
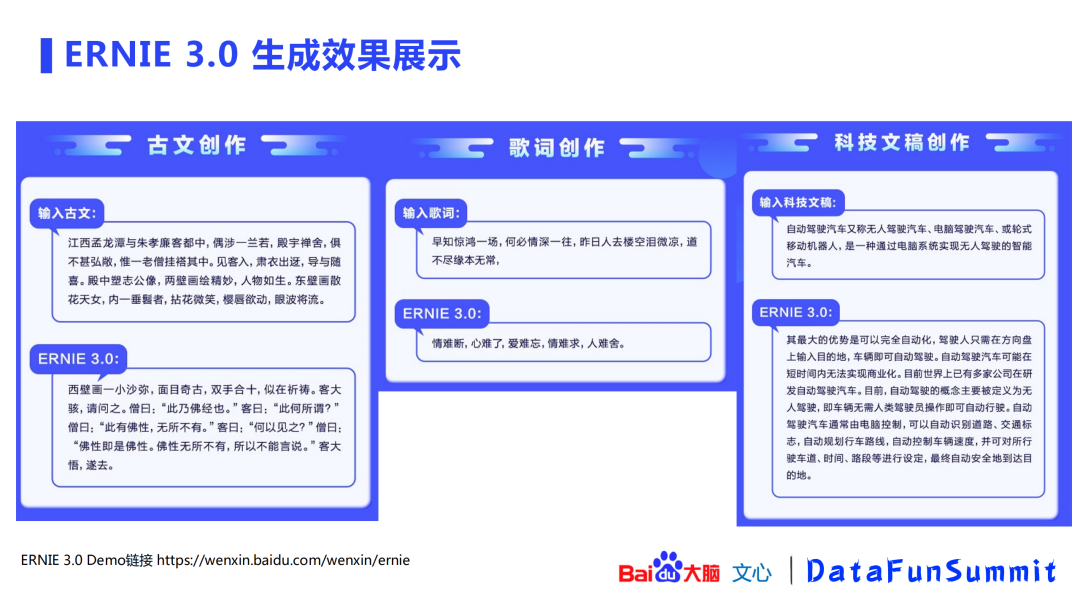
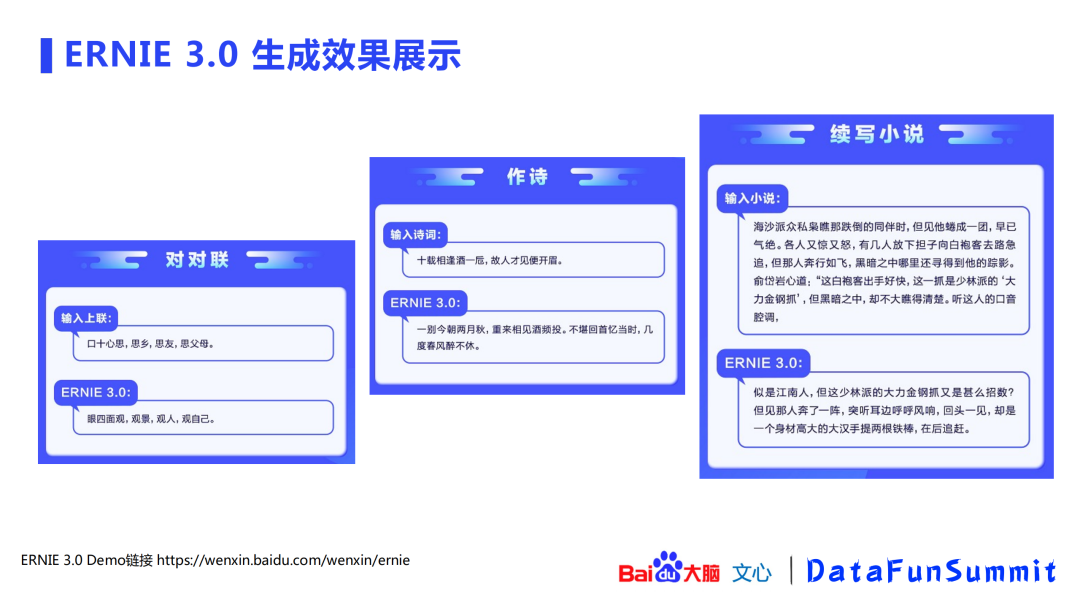
以上两图展示了ERNIE 3.0的生成效果,包括古文、歌词、科技文稿创作,对对联、作诗、续写小说等。

ERNIE 3.0引入了知识图谱的数据,上图展示了ERNIE 3.0对知识的掌握情况(掌握多跳知识)。
04
ERNIE应用实践
下面将介绍ERNIE的应用实践,这些实践都是基于文心ERNIE语义理解平台进行的。
1. 文心ERNIE工业应用效果
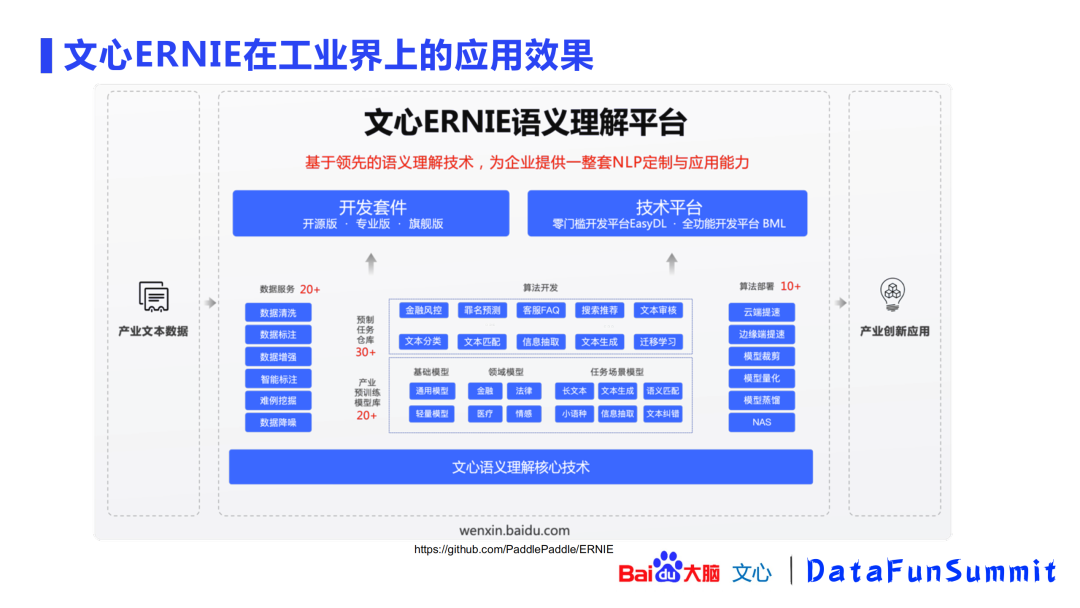
上图为文心ERNIE语义理解平台的整体示意图。平台的底座依赖于ERNIE 1.0、2.0、3.0等核心技术,包含了数据服务、算法开发、算法部署等各方面的功能,通过开发套件(开源版、专业版、旗舰版)和技术平台(EasyDL、BML)的方式对外输出。
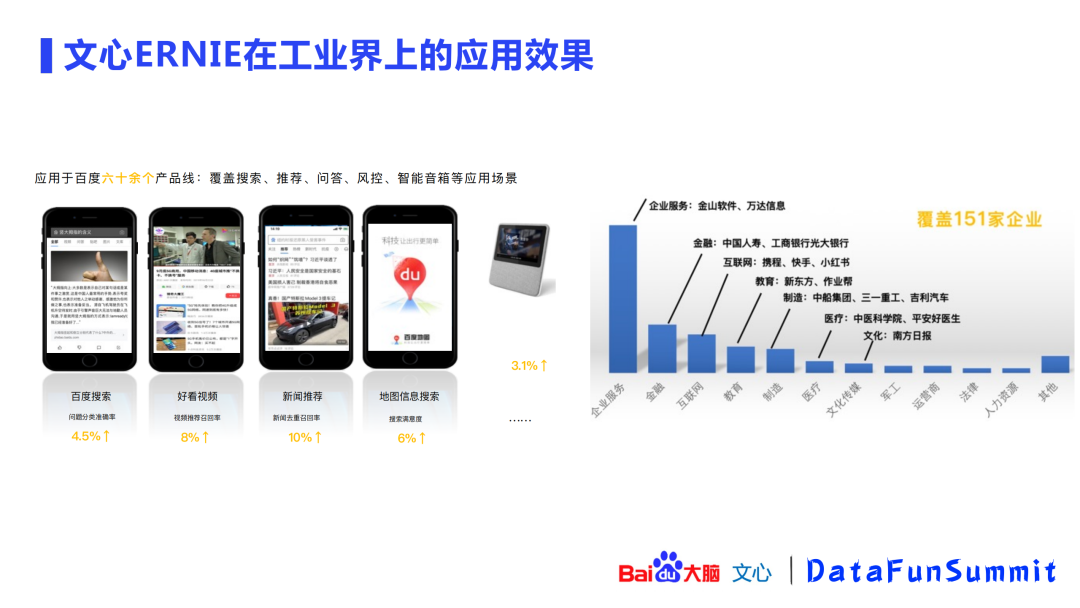
文心平台在工业界的应用效果:百度内部60个以上的产品线都有应用,覆盖搜索、推荐、问答、风控、智能音箱等应用;ToB方面,也覆盖了151家企业。
2. 文心ERNIE助力产业智能化发展

文心平台累计支持了4万开发者,覆盖了金融、通信、教育、电商等一系列垂直领域/行业。
3. 文心ERNIE案例介绍
下面将通过4个案例来讲解文心平台的具体应用:
案例1: 搜索深度问答
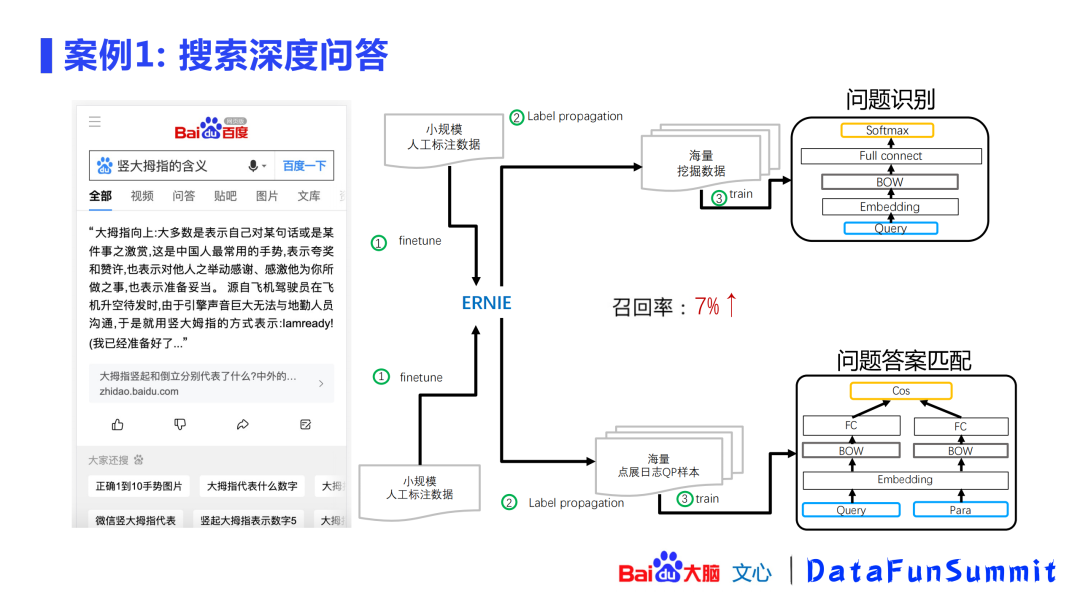
搜索深度问答是指在搜索框中输入一个query,然后在网页库中将答案放到top1的位置。这个过程共分为两个部分:问题识别和问题答案匹配。针对响应时间的严苛要求,会将ERNIE大模型的能力迁移到小模型上,如问题识别会迁移到BOW,问题答案匹配会迁移到simnet,这种方式在召回率上得到了7%的显著提升。
案例2: 视频推荐
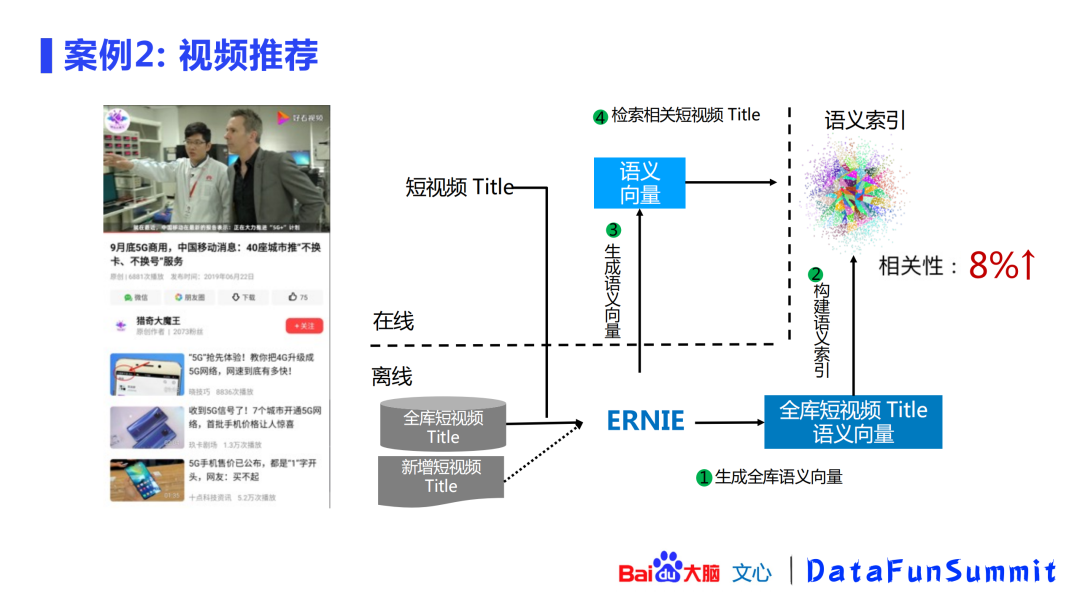
这个案例展示了ERNIE在语义索引上的应用:用ERNIE对短视频的title进行建库,当新的query出现时会先通过ERNIE生成语义向量,再进行在线语义检索,实时返回与query相关的视频推荐,这种方式在相关性上得到了8%的提升。
案例3: 文档智能分类
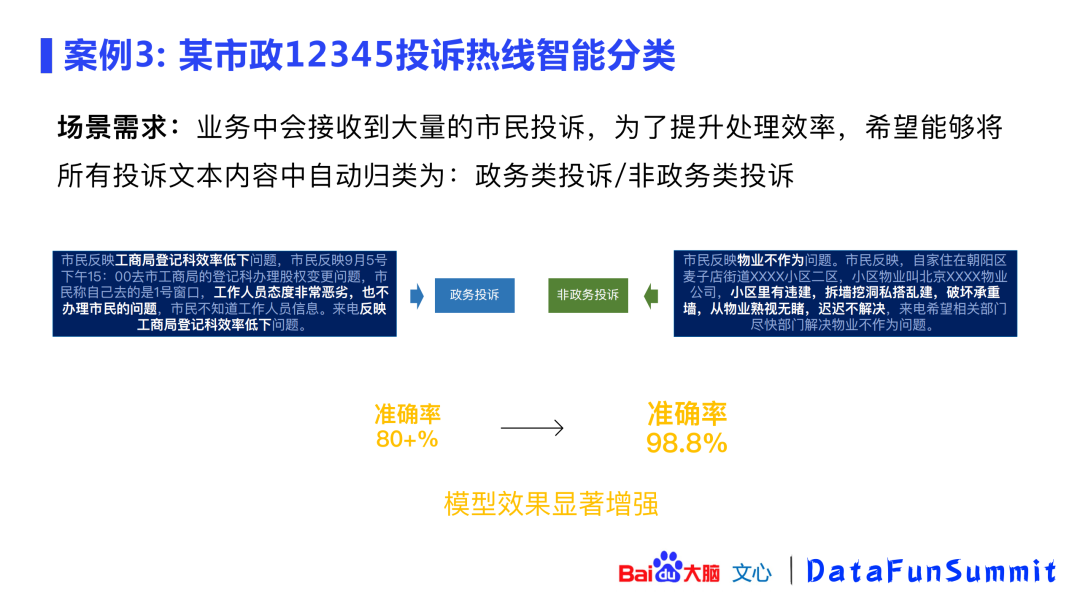
应用ERNIE进行文档智能分类:对政务投诉和非政务投诉进行分类。使用ERNIE后,使得准确率从80%提升到98.8%。
案例4: 阿兹海默症早期诊断

阿兹海默症早期诊断的传统方案是进行PET扫描(昂贵、稀缺)和脑脊液测试(创伤、痛苦)。让患者口述一句话,将其中的文本及语音停顿信息放入ERNIE模型进行分类。实验发现,ERNIE语义增强模型比BERT会有更好的效果。
05
精彩问答
Q:ERNIE 3.0的推理速度如何?QPS大概是多少?
A:QPS取决于硬件速度以及优化手段。文心平台(https://wenxin.baidu.com)有ERNIE 3.0的demo演示,要求30s内返回生成的结果,实际可能几秒就能获得结果。
Q:案例1中问答任务效果提升前的base模型是什么?
A:这个案例中的任务是比较早期的(2019年),其中的base模型是simnet,该模型是百度在语义理解任务上最初的尝试,模型也是基于大数据进行训练的。基于simnet框架,通过知识蒸馏的方式将ERNIE加入到模型中,来提升模型的整体召回率。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

- END -



在做算法工程师的道路上,你掌握了什么概念或技术使你感觉自我提升突飞猛进?
EMNLP 2021 | 百度:多语言预训练模型ERNIE-M



