
- 1OpenAI 为 GPT-3.5 Turbo 推出微调功能 (fine-tuning)_fine-tuning openai's gpt 3.5 for langchain agents
- 2华为鸿蒙系统支持什么手机_什么样的手机可以刷鸿蒙系统?看看你的手机支持吗?...
- 3安卓连接java_从零学习安卓自动化(java+appium方向):手机连接Appium(二)
- 4基于FPGA的UDP协议栈设计第四章_UDP层设计
- 5yolov5训练高精度非机动车驾驶检测_非机动车数据集
- 6modelsim仿真验证后,修改代码,不用重新关闭打开的调试技巧_modelsim仿真改原文件后
- 7【证明】对极几何:本质矩阵内在性质_本质矩阵的内在性质
- 8Unity开发(六) Prefab加载自动化管理引用计数管理器_unity assetbundle 和 gameobject的 引用计数
- 9怎么样去处理样本不平衡问题 | (文后分享大量检测+分割框架)
- 10【无人机综合题】+题解
Stable Diffusion 3技术报告流出,Sora构架再立大功!生图圈开源暴打Midjourney和DALL·E 3?
赞
踩
Stability AI在发布了Stable Diffusion 3之后,今天公布了详细的技术报告。
论文深入分析了Stable Diffusion 3的核心技术——改进版的Diffusion模型和一个基于DiT的文生图全新架构!

报告地址:
https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf
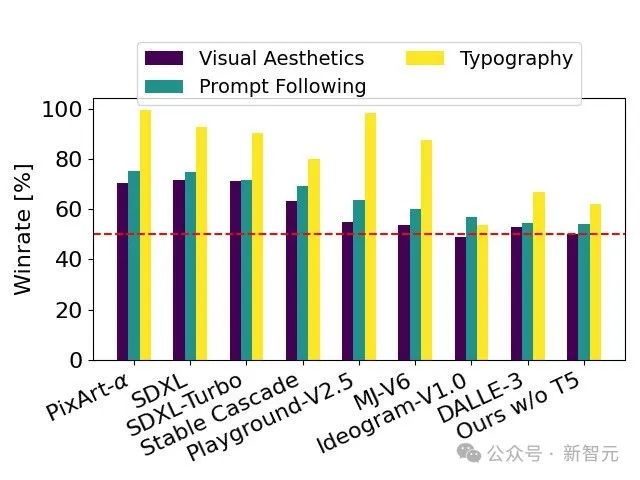
通过人类评价测试,Stable Diffusion 3在字体设计和对提示的精准响应方面,超过了DALL·E 3、Midjourney v6和Ideogram v1。
Stability AI新开发的多模态扩散Transformer(MMDiT)架构,采用了分别针对图像和语言表示的独立权重集,与SD 3的早期版本相比,显著提升了对文本的理解和文字的拼写能力。

性能评估
在人类反馈的基础之上,技术报告将SD 3于大量开源模型SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α,以及闭源模型DALL·E 3、Midjourney v6 和 Ideogram v1进行了详细的对比评估。
评估员根据与给定提示的一致性、文本的清晰度以及图像的整体美观度选择了每个模型的最佳输出:

测试结果显示,无论是在遵循提示的准确性、文本的清晰呈现还是图像的视觉美感方面,Stable Diffusion 3都达到或超过了当前文生图生成技术的最高水平。
完全没有针对硬件进行过优化的SD 3模型具有8B参数,能够在24GB显存的RTX 4090消费级GPU上运行,并且在使用50个采样步骤的情况下,生成1024x1024分辨率的图像需耗时34秒。
此外,Stable Diffusion 3在发布时将提供多个版本,参数范围从8亿到80亿,从而能以进一步降低使用的硬件门槛。

架构细节曝光
在文生图的过程中,模型需同时处理文本和图像这两种不同的信息。所以作者将这个新框架称之为MMDiT。
在文本到图像生成的过程中,模型需同时处理文本和图像这两种不同的信息类型。这就是作者将这种新技术称为MMDiT(多模态Diffusion Transformer的简称)的原因。
与Stable Diffusion之前的版本一样,SD 3采用了预训练模型来提取适合的文本和图像的表达形式。
具体而言,他们利用了三种不同的文本编码器——两个CLIP模型和一个T5 ——来处理文本信息,同时使用了一个更为先进的自编码模型来处理图像信息。
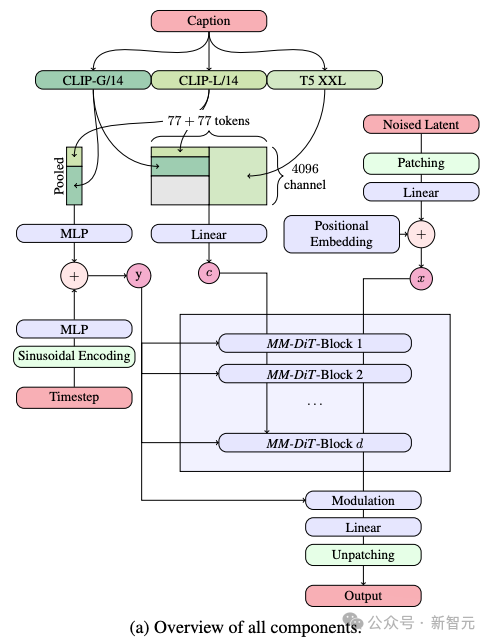
SD 3的架构是在Diffusion Transformer(DiT)的基础上建立的。由于文本和图像信息的差异,SD 3为这两种信息各自设置了独立的权重。
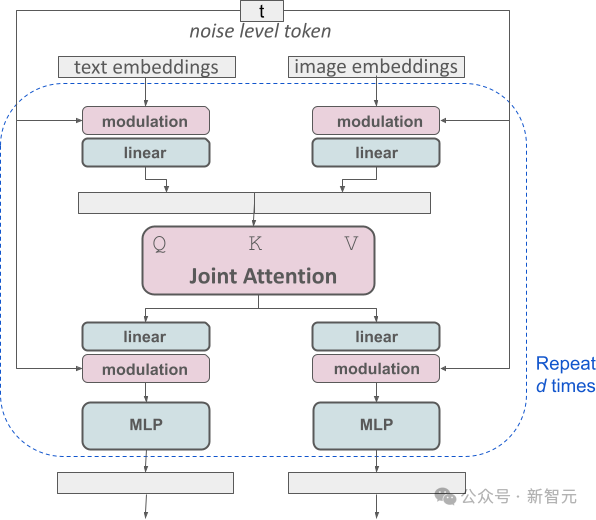
这种设计相当于为每种信息类型配备了两个独立的Transformer,但在执行注意力机制时,会将两种信息的数据序列合并,这样就可以在各自的领域内独立工作的同时,能保持够相互参考和融合。
通过这种独特的构架,图像和文本信息之间可以相互流动和交互,从而在生成的结果中提高对内容的整体理解和视觉表现。
而且,这种架构未来还可以轻松扩展到其他包括视频在内的多种模态。

得益于SD 3在遵循提示方面的进步,模型能够精确生成集中于多种不同主题和特性的图像,同时在图像风格上也保持了极高的灵活性。

通过重赋权法改进Rectified Flow
除了推出的全新Diffusion Transformer构架之外,SD 3对于Diffusion模型也进行了重大的改进。
SD 3采用了Rectified Flow(RF)策略,将训练数据和噪声沿着直线轨迹连接起来。
这种方法让模型的推理路径更加直接,因此可以通过更少的步骤完成样本的生成。
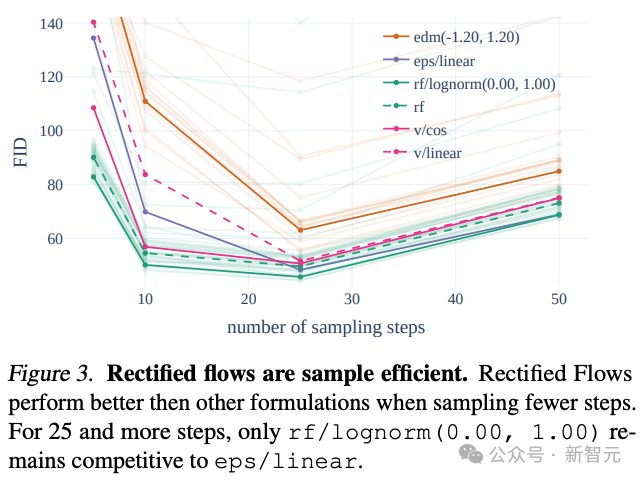
作者在训练流程中引入了一种创新的轨迹采样计划,特别增加了对轨迹中间部分的权重,这些部分的预测任务更具挑战性。
通过与其他60种扩散轨迹(例如 LDM、EDM 和 ADM)进行比较,作者发现尽管之前的RF方法在少步骤采样中表现更佳,但随着采样步骤增多,性能会慢慢下降。
为了避免这种情况的出现,作者提出的加权RF方法,就能够持续提升模型性能。
扩展RF Transformer模型
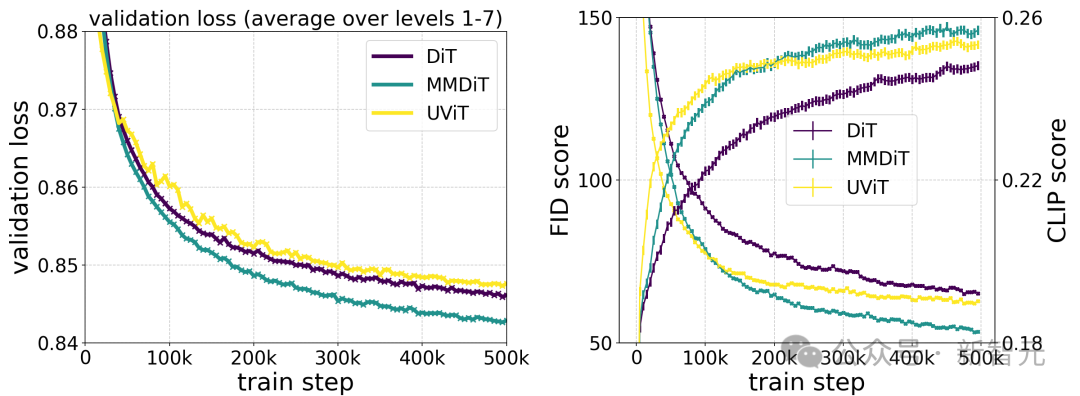
Stability AI训练了多个不同规模的模型,从 15 个模块、450M参数到38个模块、8B参数,发现模型大小和训练步骤都能平滑地降低验证损失。
为了验证这是否意味着模型输出有实质性的改进,他们还评估了自动图像对齐指标和人类偏好评分。
结果表明,这些评估指标与验证损失强相关,说明验证损失是衡量模型整体性能的有效指标。
此外,这种扩展趋势没有达到饱和点,让我们对未来能够进一步提升模型性能持乐观态度。
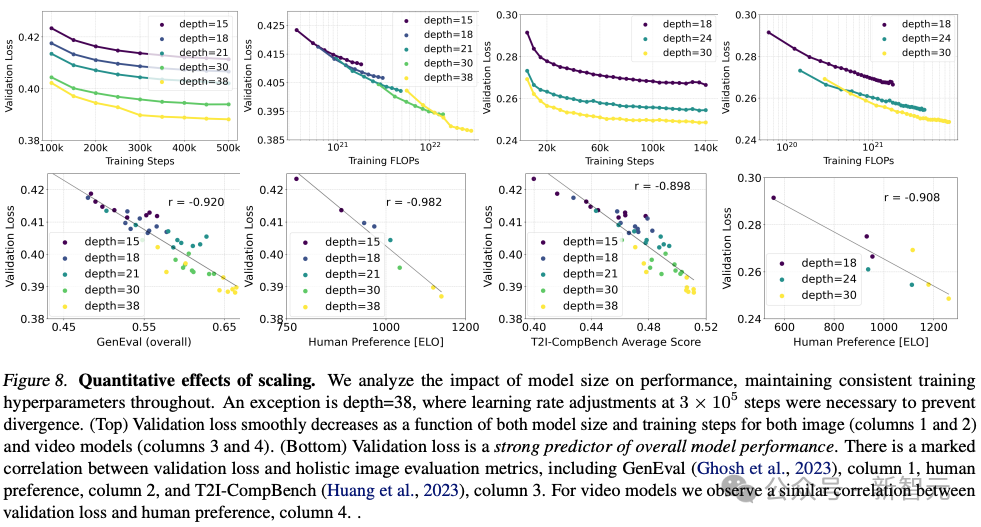
作者在256 *256像素分辨率下,在4096的批大小下,用不同参数数对模型进行了500k步训练。

上图说明了长时间训练较大模型对样本质量的影响。
上表显示了GenEval的结果。当使用作者提出的训练方法并提高训练图像的分辨率时,最大的模型在大多数类别中都表现出色,在总分上超过了 DALL·E 3。
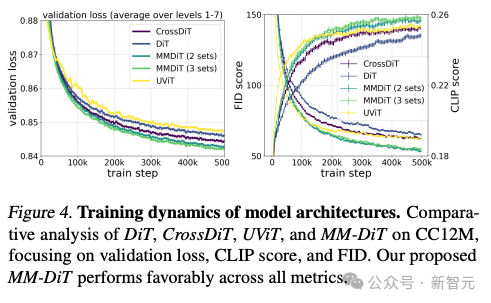
根据作者对不同构架模型的测试对比,MMDiT效果非常好,超过了DiT,Cross DiT,UViT,MM-DiT。
灵活的文本编码器
通过在推理阶段去除占用大量内存的4.7B参数的T5文本编码器,SD 3的内存需求得到了大幅降低,而性能损失微乎其微。
去除这个文本编码器不会影响图像的视觉美感(不使用T5的胜率为 50%),只会略微降低文本的准确遵循能力(胜率为46%)。
然而,为了充分发挥SD 3在生成文字的能力,作者还是建议使用T5编码器。
因为作者发现在没有它的情况下,排版生成文字的性能会有更大的下降(胜率为 38%)。

网友热议
网友们对Stability AI不断撩拨用户但是不让用的行为显得有些不耐烦了,纷纷催促赶快上线让大家使用。
看了技术报考后,网友说看来现在生图圈子要成第一个开源碾压闭源的赛道了!
参考资料:
https://stability.ai/news/stable-diffusion-3-research-paper
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除


