- 1oracle in和exist的区别 not in 和not exist的区别_oracle not in 和 not exists
- 2【转载】用通俗易懂的方式讲解大模型:基于 Langchain 和 ChatChat 部署本地知识库问答系统_我因为用的大模型服务而不是本地运行大模型,所以需要修改\langchain-chatchat\con
- 3ElasticSearch8-使用教程_elasticsearch8教程
- 4GITEA的简单介绍_gitea是免费吗?
- 5Python带你采集4K高清壁纸,超惊艳_python 批量爬取4k高清图片代码
- 6数据结构——顺序表习题解(I)_求含n(n>1)个元素的顺序表l中的最大元素。要求实现顺序表l=(6,5,7,2,9)的最大
- 7Stable Diffusion入侵短视频,华人导演玩得太6,小扎都来请她
- 8全电发票查验真伪只需要上传这三个要素信息_开具全电发票后如何检查上传成功
- 9安装ai直播机器人对接哔哩哔哩Bilibili直播,智能问答,AI Vtuber是一个由ChatterBot驱动的虚拟主播,可以在Bilibili直播中与观众实时互动。_哔哩哔哩直播机器人
- 10一 系统基础----07. NTFS安全权限_ntfs07
高并发场景下,6种方案,保证缓存和数据库的最终一致性!
赞
踩
到底是更新缓存还是删除缓存? 到底是先更新数据库,再删除缓存,还是先删除缓存,再更新数据库?本文主要介绍了在不同场景下保证数据缓存一致性的相关策略。
引言
对于互联网业务来说,传统的直接访问数据库方式,主要通过数据分片、一主多从等方式来扛住读写流量,但随着数据量的积累和流量的激增,仅依赖数据库来承接所有流量,不仅成本高、效率低、而且还伴随着稳定性降低的风险。鉴于大部分业务通常是读多写少(读取频率远远高于更新频率),甚至存在读操作数量高出写操作多个数量级的情况。因此,在架构设计中,常采用增加缓存层来提高系统的响应能力,提升数据读写性能、减少数据库访问压力,从而提升业务的稳定性和访问体验。
根据CAP原理,分布式系统在可用性、一致性和分区容错性上无法兼得,通常由于分区容错无法避免,所以一致性和可用性难以同时成立。对于缓存系统来说,如何保证其数据一致性是一个在应用缓存的同时不得不解决的问题。
需要明确的是,缓存系统的数据一致性通常包括持久化层和缓存层的一致性、以及多级缓存之间的一致性,这里我们仅讨论前者。持久化层和缓存层的一致性问题也通常被称为双写一致性问题,“双写”意为数据既在数据库中保存一份,也在缓存中保存一份。对于一致性来说,包含强一致性和弱一致性,强一致性保证写入后立即可以读取,弱一致性则不保证立即可以读取写入后的值,而是尽可能的保证在经过一定时间后可以读取到,在弱一致性中应用最为广泛的模型则是最终一致性模型,即保证在一定时间之后写入和读取达到一致的状态。对于应用缓存的大部分场景来说,追求的则是最终一致性,少部分对数据一致性要求极高的场景则会追求强一致性。
一、保证最终一致性的策略(Cache Policy)
为了达到最终一致性,针对不同的场景,业界逐步形成了下面这几种应用缓存的策略。
(一)Cache-Aside
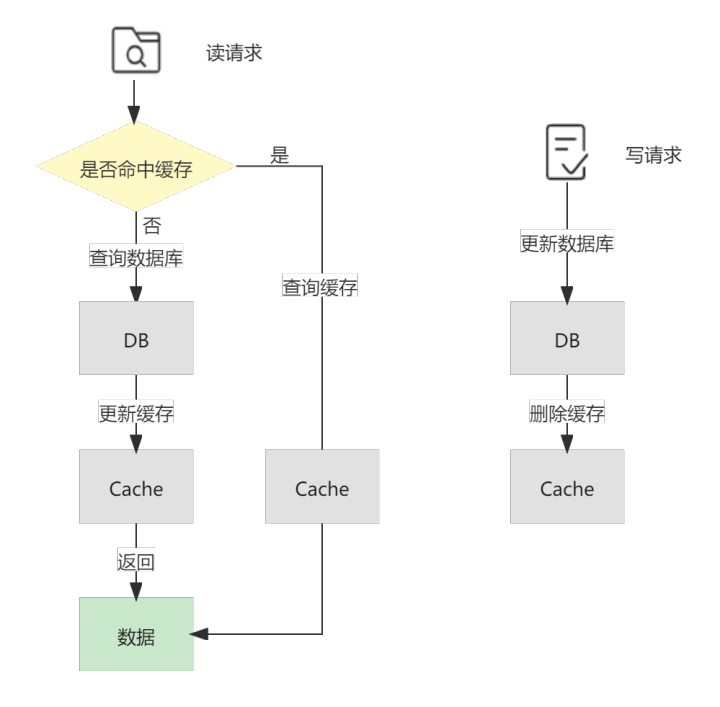
Cache-Aside意为旁路缓存模式,是应用最为广泛的一种缓存策略。下面的图示展示了它的读写流程,来看看它是如何保证最终一致性的。在读请求中,首先请求缓存,若缓存命中(cache hit),则直接返回缓存中的数据;若缓存未命中(cache miss),则查询数据库并将查询结果更新至缓存,然后返回查询出的数据(demand-filled look-aside)。在写请求中,先更新数据库,再删除缓存(write-invalidate)。
-
为什么删除缓存,而不是更新缓存?
在Cache-Aside中,对于读请求的处理比较容易理解,但在写请求中,可能会有读者提出疑问,为什么要删除缓存,而不是更新缓存?站在符合直觉的角度来看,更新缓存是一个容易被理解的方案,但站在性能和安全的角度,更新缓存则可能会导致一些不好的后果。
首先是性能,当该缓存对应的结果需要消耗大量的计算过程才能得到时,比如需要访问多张数据库表并联合计算,那么在写操作中更新缓存的动作将会是一笔不小的开销。同时,当写操作较多时,可能也会存在刚更新的缓存还没有被读取到,又再次被更新的情况(这常被称为缓存扰动),显然,这样的更新是白白消耗机器性能的,会导致缓存利用率不高。而等到读请求未命中缓存时再去更新,也符合懒加载的思路,需要时再进行计算。删除缓存的操作不仅是幂等的,可以在发生异常时重试,而且写-删除和读-更新在语义上更加对称。
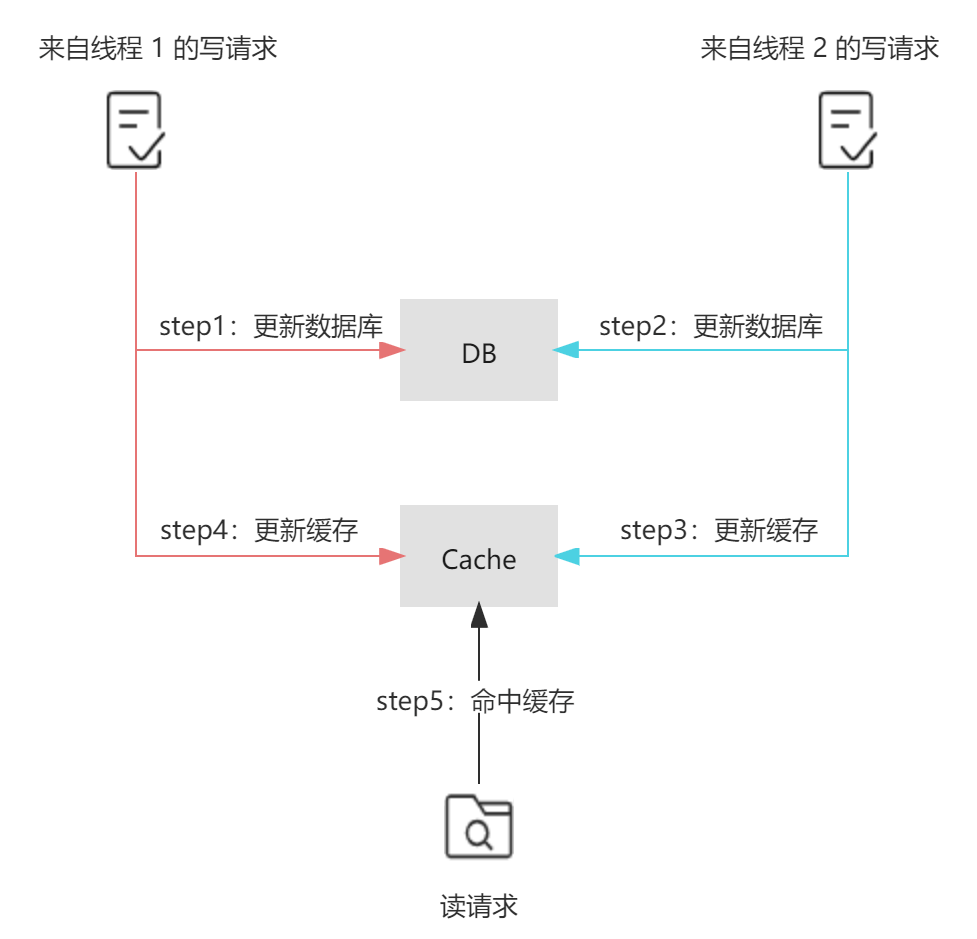
其次是安全,在并发场景下,在写请求中更新缓存可能会引发数据的不一致问题。参考下面的图示,若存在两个来自不同线程的写请求,首先来自线程1的写请求更新了数据库(step1),接着来自线程2的写请求再次更新了数据库(step3),但由于网络延迟等原因,线程1可能会晚于线程2更新缓存(step4晚于step3),那么这样便会导致最终写入数据库的结果是来自线程2的新值,写入缓存的结果是来自线程1的旧值,即缓存落后于数据库,此时再有读请求命中缓存(step5),读取到的便是旧值。