
- 1【数据结构】循环队列的实现
- 2完美掌握MySQL登录方法]MySQL登录教程
- 3【前端】微信小程序,同名图片缓存问题,增加图片后缀动态参数值解决_微信小程序 怎么清除 图片缓存
- 4Centos7安装PostgreSQL12_centos7.9 安装 postgres12
- 5[转]C/C++中产生随机数(rand,srand用法)
- 6axios连接多个服务器以及跨域代理的配置_axios.create baseurl配置不同代理
- 7mysql常用语句之DQL:查询语句_mysql dql关键字
- 8mysql如何将数据库导出到excel表格_mysql数据库表结构导出到Excel中
- 9开发第一个Java程序_编写第一个java程序
- 10Bert输入与输出
CNN网络的故障诊断(轴承的多故障类型分类+Python代码)_python故障诊断卷积神经网络代码
赞
踩
1、背景知识:卷积神经网络
卷积神经网络作为深度学习的经典算法之一,凭借局部连接和权值共享的优点,有效地降低了传统神经网络的复杂度。卷积神经网络结构由输入层、卷积层、池化层、全连接层和输出层等构成。
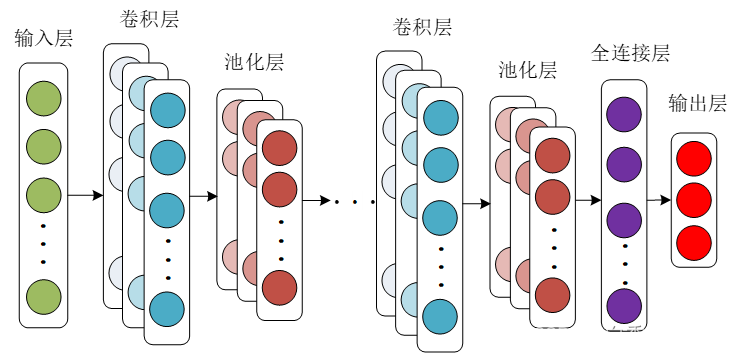
图 卷积神经网络
卷积层采用多组卷积核与输入层进行卷积运算,从输入层的原始数据中提取出新的特征信息。
池化层通过缩小卷积层提取出的特征信息的大小,挖掘提取特征的深度信息,实现特征信息的降维。
全连接层在卷积网络中充当着“分类器”的作用,将全连接层全部神经元学到的目标对象特征,映射到目标对象的标记空间,实现分类的目的。
2.数据集:轴承数据集
数据集为通过ADAMS仿真,做了四种轴承故障数据集。四种故障类型为磨损、点蚀、断齿、正常,仿真数据为6000点的振动信号。
训练集:数据集为同一工况下采集的真实轴承振动数据。
测试集: 数据集为对应工况及结构数据,仿真出来的轴承仿真数据。
下图为仿真数据图和真实数据图。
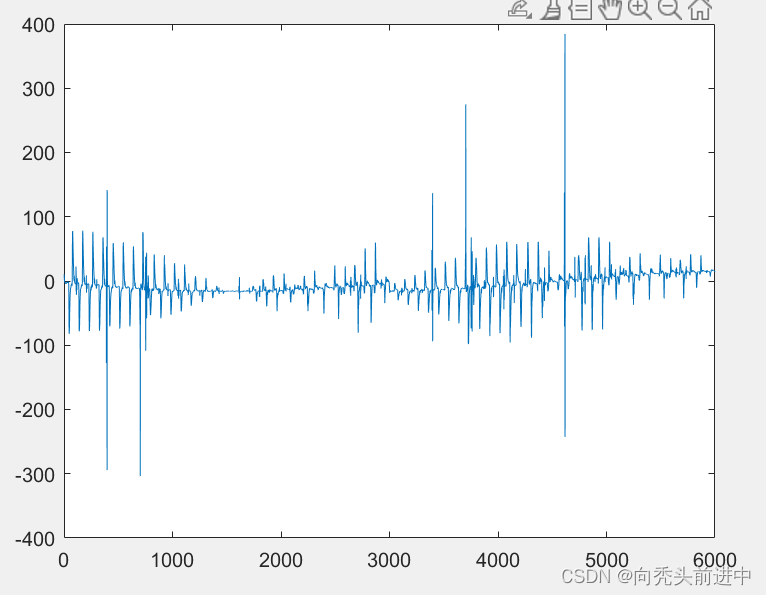

图 轴承振动数据(左为仿真数据,右为真实数据)
注释:该数据的数据集幅值在仿真输出时进行了数据对齐。所以仿真数据和真实数据的幅值相互近似。
数据集数目:训练集为720组(每种故障数目为180组),测试集为180组(每种故障类型为45组)。
3、卷积神经网络构建
3.1 数据库加载
- from tensorflow.keras.layers import Dense, Conv1D, BatchNormalization, MaxPooling1D, Activation, Flatten,Dropout
- from tensorflow.keras.models import Sequential
- import numpy as np
- import tensorflow as tf
- from sklearn.manifold import TSNE
- import matplotlib.pyplot as plt
- import scipy.io as scio
- plt.rcParams['font.sans-serif'] = ['kaiti']
- plt.rcParams['axes.unicode_minus'] = False
- import pandas as pd
3.2加载mat的轴承数据集
- # 确保结果尽可能重现
- from numpy.random import seed
- seed(1)
- tf.random.set_seed(1)
-
- # 测试集验证集划分比例
- # 加载mat数据集
- dataFile = r'E:\matlab程序\data.mat'
-
- data = scio.loadmat(dataFile)
-
-
- #训练集
- x_train = data['train_data']
- y_train= data['train_label']
-
- x_test =data['test_data']
- y_test =data['test_label']
-
-
- x_train, x_test = x_train[:,:,np.newaxis], x_test[:,:,np.newaxis]
- y_train = np.array(y_train, dtype='float64')
- y_test = np.array(y_test, dtype='float64')
-
-
- print(x_train.shape)
- print(x_test.shape)
- print(y_train.shape)
- print(y_test.shape)

3.3 模型构架及T-SNE可视化的代码
- # 实例化序贯模型
- model = Sequential()
- # 搭建输入层,第一层卷积。
- model.add(Conv1D(filters=32, kernel_size=16, strides=1, padding='same', input_shape=(6000,1)))
- model.add(BatchNormalization())
- model.add(Activation('relu'))
- model.add(MaxPooling1D(pool_size=2,strides=1,padding='valid'))
-
- # 第二层卷积
- model.add(Conv1D(filters=32, kernel_size=3, strides=1, padding='same'))
- model.add(BatchNormalization())
- model.add(Activation('relu'))
- model.add(MaxPooling1D(pool_size=2,strides=1, padding='valid'))
-
- # 从卷积到全连接需要展平
- model.add(Flatten())
- # 添加全连接层
- model.add(Dense(units=128))
- model.add(Dense(units=64))
- model.add(Dense(units=32))
- model.add(Dense(units=16))
- model.add(Dense(units=8))
- # 增加输出层
- model.add(Dense(units=4, activation='softmax'))
-
-
- # 查看定义的模型
- model.summary()
-
- # 编译模型 评价函数和损失函数相似,不过评价函数的结果不会用于训练过程中
- model.compile(optimizer='Adam', loss='categorical_crossentropy',
- metrics=['acc'])
-
- # 该模型的最优参数为:训练迭代次数10次,训练批次为16,同时规定了随机种子数.
- # 开始模型训练
- history=model.fit(x_train, y_train,
- batch_size=4,
- epochs=20,
- verbose=1,
- shuffle=True)
-
- #测试集的x_test
- predict= model.predict(x_test, batch_size=32, verbose=1,)
-
- test_label = np.argmax(y_test,axis=-1) #将one-hot标签转为一维标签
-
- predict_label = np.argmax(predict,axis=-1) #将one-hot标签转为一维标签
- print(predict_label.shape)
- print(test_label.shape)
-
-
-
- #评估精确度
- import numpy as np
- predicitons = (test_label == predict_label)
- acc1 = np.sum(predicitons == True) / len(predict_label)
- print(acc1)
-
-
-
-
- #混淆矩阵可视化
- import matplotlib.pyplot as plt
- from sklearn.metrics import confusion_matrix
-
- def cm_plot(original_label, predict_label, pic=None):
- cm = confusion_matrix(original_label, predict_label) # 由原标签和预测标签生成混淆矩阵
- plt.matshow(cm,cmap=plt.cm.Blues) # 画混淆矩阵,配色风格使用cm.Blues
- plt.colorbar() # 颜色标签
- for x in range(len(cm)):
- for y in range(len(cm)):
- plt.annotate(cm[x, y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
- # annotate主要在图形中添加注释
- # 第一个参数添加注释
- # 第二个参数是注释的内容
- # xy设置箭头尖的坐标
- # horizontalalignment水平对齐
- # verticalalignment垂直对齐
- # 其余常用参数如下:
- # xytext设置注释内容显示的起始位置
- # arrowprops 用来设置箭头
- # facecolor 设置箭头的颜色
- # headlength 箭头的头的长度
- # headwidth 箭头的宽度
- # width 箭身的宽度
- plt.ylabel('真实标签') # 坐标轴标签
- plt.xlabel('预测标签') # 坐标轴标签
- plt.title('混淆矩阵')
- if pic is not None:
- plt.savefig(str(pic) + '.jpg')
- plt.show()
-
- cm_plot(test_label,predict_label,pic=None)#
-
-
-
- # # # 创建一个绘图窗口
- plt.figure()
- acc = history.history['acc']
- loss = history.history['loss']
-
-
- epochs = range(len(acc))
-
- plt.plot(epochs, acc,'r*-', linewidth=2.5, alpha = 0.8, label='训练集准确率') # 'bo'为画蓝色圆点,不连线
- plt.title('训练集准确率')
- plt.legend() # 绘制图例,默认在右上角
- plt.figure()
- plt.plot(epochs, loss,'r*-',linewidth=2.5, alpha = 0.8, label='训练集损失率')
- plt.title('训练集损失率')
- plt.legend()
- plt.show()
-
- # # #输出训练历史数据 loss acc
- print(loss)
- print(acc)
- pd.DataFrame(history.history).to_csv('training_log4.csv', index=False)
-
-
-
- # # -------------------------------获取模型最后一层的数据--------------------------------
- # # 获取model.add(layers.Flatten())数据
- def create_truncated_model(trained_model):
- model = Sequential()
- # 搭建输入层,第一层卷积。
- model.add(Conv1D(filters=32, kernel_size=16, strides=1, padding='same', input_shape=(6000, 1)))
- model.add(BatchNormalization())
- model.add(Activation('relu'))
- model.add(MaxPooling1D(pool_size=2, strides=1, padding='valid'))
-
- # 第二层卷积
- model.add(Conv1D(filters=32, kernel_size=3, strides=1, padding='same'))
- model.add(BatchNormalization())
- model.add(Activation('relu'))
- model.add(MaxPooling1D(pool_size=2, strides=1, padding='valid'))
-
- # 从卷积到全连接需要展平
- model.add(Flatten())
- # 添加全连接层
- model.add(Dense(units=128))
- model.add(Dense(units=64))
- model.add(Dense(units=32))
- model.add(Dense(units=16))
- model.add(Dense(units=8))
- # 增加输出层
- model.add(Dense(units=4, activation='softmax'))
-
- for i, layer in enumerate(model.layers):
- layer.set_weights(trained_model.layers[i].get_weights())
- model.compile(optimizer='Adam',
- loss='categorical_crossentropy',
- metrics=['acc'])
- return model
-
- truncated_model = create_truncated_model(model)
- hidden_features = truncated_model.predict(x_test)
- print(hidden_features.shape)
- color_map = y_test.argmax(axis=-1) #将one-hot标签转为一维标签
-
- #-------------------------------tSNE降维分析--------------------------------
- tsne = TSNE(n_components=2, init='pca',verbose = 1,random_state=0)
- tsne_results = tsne.fit_transform(hidden_features)
- print(tsne_results.shape)
-
- marker1 = ["^", "o", "+", "*", ]
- #-------------------------------可视化--------------------------------
- for cl in range(4):# 总的类别
- indices = np.where(color_map==cl)
- indices = indices[0]
- plt.scatter(tsne_results[indices,0], tsne_results[indices, 1],s=30, marker=marker1[cl], label=cl)
- plt.legend(loc=1,bbox_to_anchor=(1, 1.03))
- #plt.axis('off')
- plt.show()
3.4 训练结果可视化
训练集的损失率和精确度
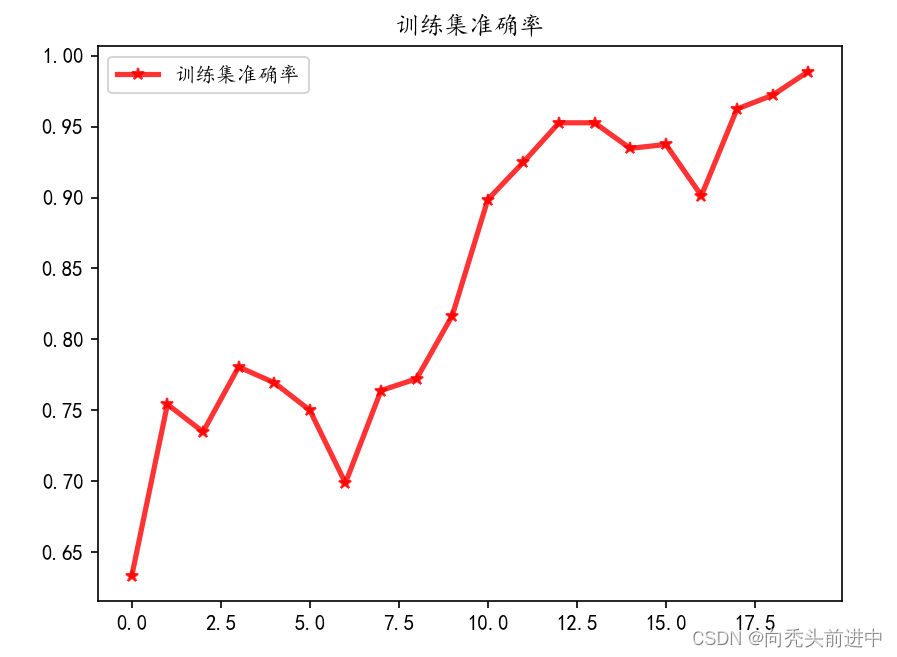
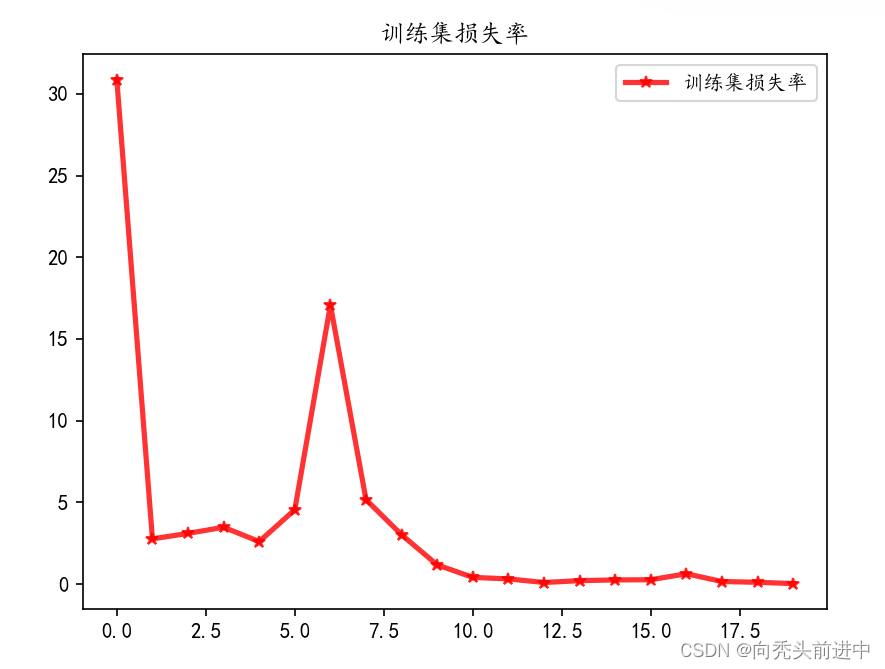
图 训练集的损失率和精确度
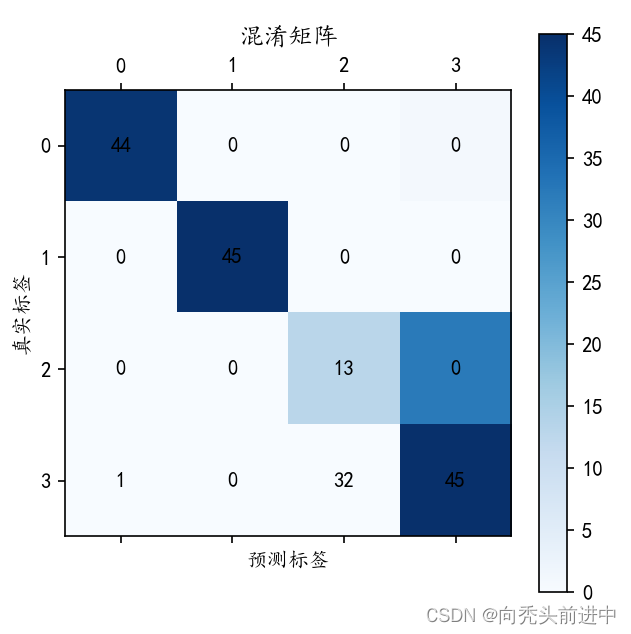
图 混淆矩阵
4、结果分析
注释:因为设置仿真时,仿真故障的磨损和点蚀的差异性设计的不太明显。该数据集对于磨损和点蚀的差异性就不明显。所以测试集中,第三种(磨损)和第四种(点蚀)故障类型的故障诊断效果不太明显。
其实是根本分不开,我也跟纠结。
失败原因:主要有两部分
1、我认为训练集应该采用更高质量的仿真数据,可以有效得避免真实数据中的不同噪声信号相互混淆干扰。但是真实数据是对真实故障的对应映射,包含了最真实的故障信息;仿真数据不具备该方面的优势,仿真可能无法一一映射完整的故障信号。
2、该CNN模型的抗噪能力不太行,我设计模型没有考虑到有效的抗噪措施,进一步对模型的抗噪能力进行提升,可能是对故障诊断效果有效得提升。
所以就不放T-SNE的聚类图啦!!!(聚类效果太辣鸡啦!)

