
- 1开题报告:基于java的高校固定资产管理系统设计与实现_高校固定资产管理系统开题报告
- 22023 Java 面试题精选40道,包含答案_2023java面试题
- 3做人做事系列必读_做人贵在恰当好处,进退有度,合适的表达,智慧的沉默。
- 4FPGA开发流程以及Vivado的使用(一)_vivado compiler 打开fpga模型
- 5oracle canvas does not allow drawing,SynGdiPlus.pas
- 6Transformers Pipeline: NLP任务的全面指南_transformers.pipeline
- 7Java中对集合进行排序的两种方法_java集合排序
- 8Finetuning vs. Prompting:大语言模型两种使用方式
- 9NodeJS常见报错_the node.js path can contain
- 10FPGA实现SPI接口(2)--SPI接口芯片的实际使用
阿里电话面试_rwnd cwnd swnd关系
赞
踩
TCP 协议如何保证可靠传输
转自:
一、综述
1、确认和重传:接收方收到报文就会确认,发送方发送一段时间后没有收到确认就重传。
2、数据校验
3、数据合理分片和排序:
UDP:IP数据报大于1500字节,大于MTU.这个时候发送方IP层就需要分片(fragmentation).把数据报分成若干片,使每一片都小于MTU.而接收方IP层则需要进行数据报的重组.这样就会多做许多事情,而更严重的是,由于UDP的特性,当某一片数据传送中丢失时,接收方便无法重组数据报.将导致丢弃整个UDP数据报.
tcp会按MTU合理分片,接收方会缓存未按序到达的数据,重新排序后再交给应用层。
4、流量控制:当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。
5、拥塞控制:当网络拥塞时,减少数据的发送。
二、滑动窗口
上面笼统地说了tcp保证可靠传输的机制,下面说说如何用滑动窗口来实现。
为什么要使用滑动窗口
因为发送端希望在收到确认前,继续发送其它报文段。比如说在收到0号报文的确认前还发出了1-3号的报文,这样提高了信道的利用率。但可以想想,0-4发出去后可能要重传,所以需要一个缓冲区维护这些报文,所以就有了窗口。
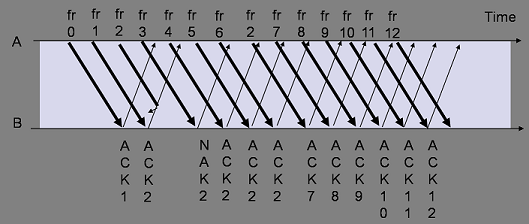
RTT:往返时间。
窗口是什么
接收窗口:

“接收窗口”大小取决于应用(比如说tomcat:8080端口的监听进程)、系统、硬件的限制。图中,接收窗口是31~50,大小为20。
在接收窗口中,黑色的表示已收到的数据,白色的表示未收到的数据。
当收到窗口左边的数据,如27,则丢弃,因为这部分已经交付给主机;
当收到窗口左边的数据,如52,则丢弃,因为还没轮到它;
当收到已收到的窗口中的数据,如32,丢弃;
当收到未收到的窗口中的数据,如35,缓存在窗口中。
发送窗口:

发送窗口的大小swnd=min(rwnd,cwnd)。rwnd是接收窗口,cwnd用于拥塞控制,暂时可以理解为swnd= rwnd =20。
图中分为四个区段,其中P1到P3是发送窗口。
tips:发送窗口以字节为单位。为了方便画图,图中展示得像以报文为单位一样。但这不影响理解。
三、重传和确认
什么时候发确认:这是一个复杂的策略。我们这里先简单地认为每收到一个报文就发一个确认。
怎么确认(累计确认):
情况1:发送ack=31(为什么这个也要发,这个确认可以用于后面的拥塞控制)

情况2:发送ack=34,并把接收窗口左边缘设置成34,右边缘设置成53

累计确认的好处:情况1中ack=31比描述收到32和33简单;坏处:可能要重传已经接收的数据。
发送方收到确认时怎么处理:
情况1:收到ack=31,什么都不做,或者说继续发送可用窗口中的内容,如42~50
情况2:收到ack=34,发送窗口窗口的左边缘设置成34,右边缘设置成53
什么时候重传:因为每个报文都有超时计数器,超时才重传。超时重传时间的选择也是一个策略。
tcp缓存和窗口的关系:窗口是缓存的一部分。
发送缓存=发送窗口+ P3右边的一部分
接收缓存=接收窗口+部分已确认但主机还没处理完的数据。
四、流量控制
一图流,简单来说就是接收方处理不过来的时候,就把窗口缩小,并把窗口值告诉发送端。

当窗口值为0,而接受方把窗口值恢复(比如ACK=1,ack=601,rwnd=200),但确认丢失,进入相互等待的死锁局面。所以如果窗口值为0,发送端就会开启一个持续计数器,每个一段时间询问一下接收方。
五、拥塞控制
swnd=min(rwnd,cwnd),cwnd就是拥塞窗口大小。
慢开始和拥塞避免

ssthresh:处理拥塞时参照的一个参数。例子中初始值为16,后来变为12。
当cwnd> ssthresh,cwnd以慢开始的方法指数增长;
当cwnd< ssthresh,cwnd以拥塞避免的方法线性增长。
值得注意的几个点
1上图是cwnd随传输轮次的变化,每过一个RTT就算一轮。
2超时就可以认为是拥塞了
快重传和快恢复:上一个算法的加强版
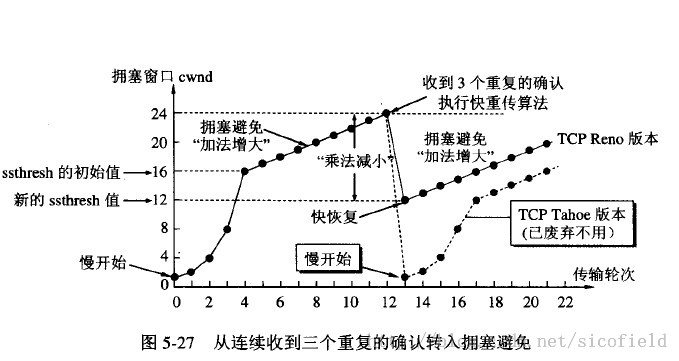
快重传:收到3个同样的确认就立刻重传,不等到超时;
快恢复:cwnd不是从1重新开始。
Python解释器和编译器的区别:
转自:http://blog.csdn.net/touzani/article/details/1625760
为了让更多的人能够从本质上理解编译器和解释器的区别,我杜撰了一个小故事
来福与旺财的养牛场
来福和旺财有一个养 牛场。本来养牛不是一件太难的事情,但是偏偏他俩养的牛都有特别的怪癖。奶牛阿圆只吃切成圆形的牧草,而奶牛阿方和阿三(印度来的?)分别只吃切成正方形 和三角形的牧草。如果来福和旺财拿不和奶牛性格的草去喂食,阿X们不但不产奶而且还会鄙视来福和旺财。
于是来福和旺财分别有了自己的主意
来福的方案:
来福发明了三套大型碾碎机:圆圆碾碎机,方方碾碎机和三三碾碎机。每天收割了牧草,就分别放到这三套机器里碾碎给三头奶牛吃。但是一旦被碾碎了,这堆草就只能给某一头牛吃了。很明显阿方是不会吃给阿圆准备的草的。而且来福每天都要操作这三台机器,觉得比较麻烦。
旺财的方案:
旺财在考察了来福的方案后,发现每天操作三台机器真的很麻烦,而且有时有的牛吃不完,有的牛不够吃时,还不能在奶牛之间调配碾碎了的牧草。所以旺财有了不同的想法:口罩型碾碎机。
就像在图上看到的,旺财给每头奶牛装配了一台口罩碾碎机,所以三头牛完全可以在一个槽里吃草了,在吃之前口罩会自动把牧草碾碎成适合该牛食用的类型。旺财就轻松了,他每天只需要割割草就行了。
但是旺财被鄙视了???
是的,被来福鄙视了。来福观察后发现,旺财的口罩碾碎机的效率很低(因为比较小嘛)。阿圆食量大,吃来福的圆圆碾碎机的食物一个小时就饱了,但是戴着口罩吃的时候要吃十个小时!所以来福认为旺财的口罩碾碎机虽然省事,但只能喂喂小牛,完全不适合食量大的牛。
旺财也觉得这样做有问题,但他不想回到来福方案上,他改进了口罩方案:牧草预切割机。
呵呵,看到预切割做了什么吗?它把牧草割得小了一些,所以需要口罩碾碎机做的事情就少多了。(当然口罩碾碎机也要作适当改进适合预切割后的牧草,所以图上用蓝色表示)阿圆以前用口罩不是要吃十个小时吗,现在两三个小时就可以了。
编译器与解释器
好的,谢谢你有耐心看到这里,经过上面那个不太恰当的例子,相信你已经相当的糊涂了。那么我们试着回到技术方面来。
在上面的例子中
牧草 = 我们的各种编程语言,C/C++/C#, Java, Pascal, PHP, Python, Perl, Java Script等等
切割机 = 各种编译器
奶牛 = 各种CPU(不要告诉我Intel和AMD哦),比如x86,ARM,MIPS等等
那你应该知道了为什么奶牛会有吃不同形状牧草的嗜好了,这个奇怪的比喻是为了表示不同的CPU接受的不同的机器语言。
对应上面的奶牛图,编译器的图是这样的
源代码被编译成机器码,在CPU上运行。
而解释器是这样的
用解释器很方便,只需要直接“运行”就好了,不用像C那样有编译链接的工序。
为什么说这些语言是跨平台的?因为你写了程序以后,如果这个平台上有这种语言的解释器,只需要拿到这个平台上直接运行就可以了。你可以理解为:解释器是在“一边编译,一边运行”,它只是把以前程序员手工做的编译过程放在了运行程序的时候进行。
为什么我们一般说解释器的效率比较低?你也可以想象的是,一段程序在解释器中运行时可能会被编译多次,因为每次运行到这段程序时,都会重新编译一次,这样的开销是很大的。
所以诞生了Java,C#这样的预编译语言:
在运行之前,需要手动把源代码编译成中间代码(Java里叫字节码),然后在解释器中执行。
这种架构避免了上面纯解释器中编译源代码的开销,所以相对会有效率一些。
但 是我不能骗你们,其实我画在纯解释器中的Python,Perl,PHP可能都不会是真的纯解释执行的,这样实在是太没有效率。Python在运行时会生 成pyc的二进制临时文件,看起来很像是预编译的结果。只有JavaScript这种真的不会写得太长的语言(Ajax请原谅我)才会采用纯解释的运行方 式。
总结:
口述反转单链表:
转自:http://blog.csdn.net/hyqsong/article/details/49429859
思路一:从原链表的头部一个一个取节点并插入到新链表的头部
思路二:每次都将原第一个结点之后的那个结点放在新的表头后面。
第一次:把第一个结点1后边的结点2放到新表头后面,变成2,1,3,4,5
第二次:把第一个结点1后边的结点3放到新表头后面,变成3,2,1,4,5
……
直到: 第一个结点1,后边没有结点为止。
思路三:第三种方法跟第二种方法差不多,第二种方法是将后面的结点向前移动到头结点的后面,第三种方法是将前面的结点移动到原来的最后一个结点的后面,思路跟第二种方法差不多,就不贴代码了。

