
热门标签
热门文章
- 1Docker Hadoop、Spark、Kafka、Zookeeper等集群服务搭建_基于docker搭建hadoop集群+zookeeper+hive
- 2财会女生转行软件测试,年薪20w实现钱多事少离家近_女生干测试好还是会计好呢
- 3JavaScript了解unshift,push在头部尾部添加元素的代码_js 头部push
- 4三、规划控制——车辆横向控制(1)_车辆横向运动控制
- 5强推这款键盘利器(Keychron),这次我彻底入坑了_keychron键盘怎么样
- 6开代理后无法从huggingface加载模型
- 7十月面经:真可惜!拿了小米的offer,字节却惨挂在三面_小米交叉面
- 8【Ubuntu20.04运行Fast-LIO程序】_ubuntu 20.04 fast-lio
- 9Ansible组件说明
- 10linux监控网络情况_liunx监测网络消耗
当前位置: article > 正文
CycleGAN 简介与代码实战_cyclegan代码
作者:小丑西瓜9 | 2024-04-17 22:06:54
赞
踩
cyclegan代码
1.介绍
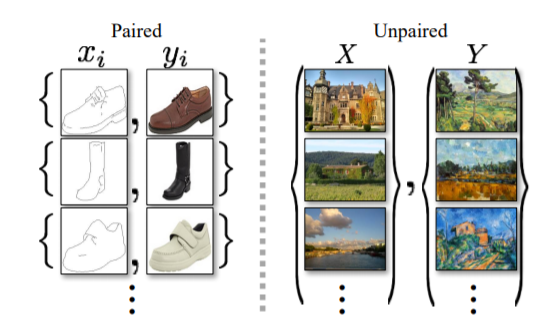
CycleGAN 出自于论文“Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”,其实题目已经把论文的重点给凸显出来了,Unpaired(不成对),Cycle(圈)
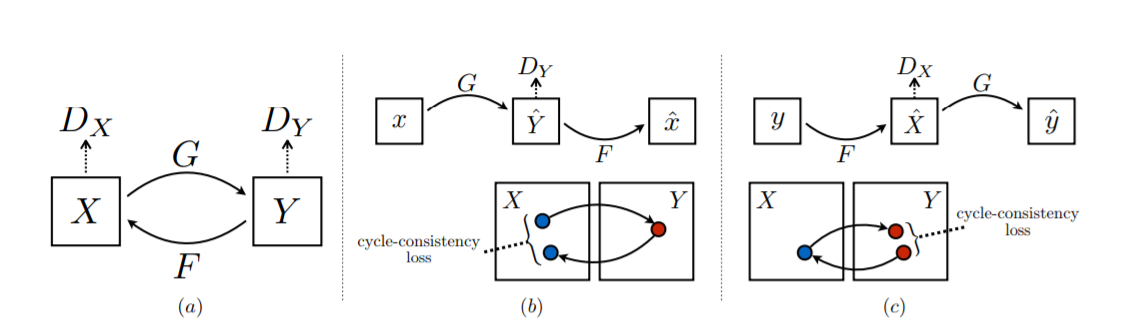
2.模型结构
整个结构就是一个Cycle操作(见图中的a),对于(b)小图,x为输入,y_生成=G(x),x_生成=F(y_生成);对于(c)小图y为输入,x_生成=F(y),y_生成=G(x_生成),其中G和F是生成器,Dx和Dy是判别器。
3.模型特点
总的损失函数为公式(3),公式(2)为L1损失函数,能使得恢复的图片更加接近原图片且相对不模糊(相对于L2损失函数),公式(1)就是常规的gan损失函数。判别器用的是Patch-D(Pix2Pix用的一样),生成器为U-net结构。
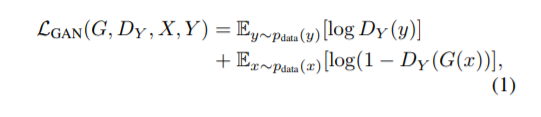


4.代码实现keras
- class CycleGAN():
- def __init__(self):
- # Input shape
- self.img_rows = 128
- self.img_cols = 128
- self.channels = 3
- self.img_shape = (self.img_rows, self.img_cols, self.channels)
-
- # Configure data loader
- self.dataset_name = 'apple2orange'
- self.data_loader = DataLoader(dataset_name=self.dataset_name,
- img_res=(self.img_rows, self.img_cols))
-
-
- # Calculate output shape of D (PatchGAN)
- patch = int(self.img_rows / 2**4)
- self.disc_patch = (patch, patch, 1)
-
- # Number of filters in the first layer of G and D
- self.gf = 32
- self.df = 64
-
- # Loss weights
- self.lambda_cycle = 10.0 # Cycle-consistency loss
- self.lambda_id = 0.1 * self.lambda_cycle # Identity loss
-
- optimizer = Adam(0.0002, 0.5)
-
- # Build and compile the discriminators
- self.d_A = self.build_discriminator()
- self.d_B = self.build_discriminator()
- self.d_A.compile(loss='mse',
- optimizer=optimizer,
- metrics=['accuracy'])
- self.d_B.compile(loss='mse',
- optimizer=optimizer,
- metrics=['accuracy'])
-
- #-------------------------
- # Construct Computational
- # Graph of Generators
- #-------------------------
-
- # Build the generators
- self.g_AB = self.build_generator()
- self.g_BA = self.build_generator()
-
- # Input images from both domains
- img_A = Input(shape=self.img_shape)
- img_B = Input(shape=self.img_shape)
-
- # Translate images to the other domain
- fake_B = self.g_AB(img_A)
- fake_A = self.g_BA(img_B)
- # Translate images back to original domain
- reconstr_A = self.g_BA(fake_B)
- reconstr_B = self.g_AB(fake_A)
- # Identity mapping of images
- img_A_id = self.g_BA(img_A)
- img_B_id = self.g_AB(img_B)
-
- # For the combined model we will only train the generators
- self.d_A.trainable = False
- self.d_B.trainable = False
-
- # Discriminators determines validity of translated images
- valid_A = self.d_A(fake_A)
- valid_B = self.d_B(fake_B)
-
- # Combined model trains generators to fool discriminators
- self.combined = Model(inputs=[img_A, img_B],
- outputs=[ valid_A, valid_B,
- reconstr_A, reconstr_B,
- img_A_id, img_B_id ])
- self.combined.compile(loss=['mse', 'mse',
- 'mae', 'mae',
- 'mae', 'mae'],
- loss_weights=[ 1, 1,
- self.lambda_cycle, self.lambda_cycle,
- self.lambda_id, self.lambda_id ],
- optimizer=optimizer)
-
- def build_generator(self):
- """U-Net Generator"""
-
- def conv2d(layer_input, filters, f_size=4):
- """Layers used during downsampling"""
- d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
- d = LeakyReLU(alpha=0.2)(d)
- d = InstanceNormalization()(d)
- return d
-
- def deconv2d(layer_input, skip_input, filters, f_size=4, dropout_rate=0):
- """Layers used during upsampling"""
- u = UpSampling2D(size=2)(layer_input)
- u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same', activation='relu')(u)
- if dropout_rate:
- u = Dropout(dropout_rate)(u)
- u = InstanceNormalization()(u)
- u = Concatenate()([u, skip_input])
- return u
-
- # Image input
- d0 = Input(shape=self.img_shape)
-
- # Downsampling
- d1 = conv2d(d0, self.gf)
- d2 = conv2d(d1, self.gf*2)
- d3 = conv2d(d2, self.gf*4)
- d4 = conv2d(d3, self.gf*8)
-
- # Upsampling
- u1 = deconv2d(d4, d3, self.gf*4)
- u2 = deconv2d(u1, d2, self.gf*2)
- u3 = deconv2d(u2, d1, self.gf)
-
- u4 = UpSampling2D(size=2)(u3)
- output_img = Conv2D(self.channels, kernel_size=4, strides=1, padding='same', activation='tanh')(u4)
-
- return Model(d0, output_img)
-
- def build_discriminator(self):
-
- def d_layer(layer_input, filters, f_size=4, normalization=True):
- """Discriminator layer"""
- d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
- d = LeakyReLU(alpha=0.2)(d)
- if normalization:
- d = InstanceNormalization()(d)
- return d
-
- img = Input(shape=self.img_shape)
-
- d1 = d_layer(img, self.df, normalization=False)
- d2 = d_layer(d1, self.df*2)
- d3 = d_layer(d2, self.df*4)
- d4 = d_layer(d3, self.df*8)
-
- validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
-
- return Model(img, validity)
-
- def train(self, epochs, batch_size=1, sample_interval=50):
-
- start_time = datetime.datetime.now()
-
- # Adversarial loss ground truths
- valid = np.ones((batch_size,) + self.disc_patch)
- fake = np.zeros((batch_size,) + self.disc_patch)
-
- for epoch in range(epochs):
- for batch_i, (imgs_A, imgs_B) in enumerate(self.data_loader.load_batch(batch_size)):
-
- # ----------------------
- # Train Discriminators
- # ----------------------
-
- # Translate images to opposite domain
- fake_B = self.g_AB.predict(imgs_A)
- fake_A = self.g_BA.predict(imgs_B)
-
- # Train the discriminators (original images = real / translated = Fake)
- dA_loss_real = self.d_A.train_on_batch(imgs_A, valid)
- dA_loss_fake = self.d_A.train_on_batch(fake_A, fake)
- dA_loss = 0.5 * np.add(dA_loss_real, dA_loss_fake)
-
- dB_loss_real = self.d_B.train_on_batch(imgs_B, valid)
- dB_loss_fake = self.d_B.train_on_batch(fake_B, fake)
- dB_loss = 0.5 * np.add(dB_loss_real, dB_loss_fake)
-
- # Total disciminator loss
- d_loss = 0.5 * np.add(dA_loss, dB_loss)
-
-
- # ------------------
- # Train Generators
- # ------------------
-
- # Train the generators
- g_loss = self.combined.train_on_batch([imgs_A, imgs_B],
- [valid, valid,
- imgs_A, imgs_B,
- imgs_A, imgs_B])
-
- elapsed_time = datetime.datetime.now() - start_time
-
- # Plot the progress
- print ("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %3d%%] [G loss: %05f, adv: %05f, recon: %05f, id: %05f] time: %s " \
- % ( epoch, epochs,
- batch_i, self.data_loader.n_batches,
- d_loss[0], 100*d_loss[1],
- g_loss[0],
- np.mean(g_loss[1:3]),
- np.mean(g_loss[3:5]),
- np.mean(g_loss[5:6]),
- elapsed_time))
-
- # If at save interval => save generated image samples
- if batch_i % sample_interval == 0:
- self.sample_images(epoch, batch_i)
-
- def sample_images(self, epoch, batch_i):
- os.makedirs('images/%s' % self.dataset_name, exist_ok=True)
- r, c = 2, 3
-
- imgs_A = self.data_loader.load_data(domain="A", batch_size=1, is_testing=True)
- imgs_B = self.data_loader.load_data(domain="B", batch_size=1, is_testing=True)
-
- # Demo (for GIF)
- #imgs_A = self.data_loader.load_img('datasets/apple2orange/testA/n07740461_1541.jpg')
- #imgs_B = self.data_loader.load_img('datasets/apple2orange/testB/n07749192_4241.jpg')
-
- # Translate images to the other domain
- fake_B = self.g_AB.predict(imgs_A)
- fake_A = self.g_BA.predict(imgs_B)
- # Translate back to original domain
- reconstr_A = self.g_BA.predict(fake_B)
- reconstr_B = self.g_AB.predict(fake_A)
-
- gen_imgs = np.concatenate([imgs_A, fake_B, reconstr_A, imgs_B, fake_A, reconstr_B])
-
- # Rescale images 0 - 1
- gen_imgs = 0.5 * gen_imgs + 0.5
-
- titles = ['Original', 'Translated', 'Reconstructed']
- fig, axs = plt.subplots(r, c)
- cnt = 0
- for i in range(r):
- for j in range(c):
- axs[i,j].imshow(gen_imgs[cnt])
- axs[i, j].set_title(titles[j])
- axs[i,j].axis('off')
- cnt += 1
- fig.savefig("images/%s/%d_%d.png" % (self.dataset_name, epoch, batch_i))
- plt.close()

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/442498
推荐阅读
相关标签

