
- 1[译] 第九天:TextBlob - 发现字里行间的情感
- 2[Node] Node.js 包管理工具详解npm yarn cnpm npx pnpm_nodejs pnpm
- 3【Flutter】Flutter 中 sqflite 的基本使用_flutter sqflite
- 4【FPGA】Quartus项目工程创建以及联合Modelsim进行仿真(FPGA项目创建与仿真)_modelsim和quartus联合仿真
- 5数据库sql语句的exists总结
- 6基于遗传算法的模糊PID控制器整定(Matlab代码实现)_遗传算法pid整定matlab
- 7C语言经典面试题之深入解析字符串拷贝的sprintf、strcpy和memcpy使用与区别_strcpy sprintf
- 8Flink CDC 基于Oracle log archiving 实时同步Oracle表到Mysql_flink cdc oracle
- 9vue2和vue3浏览器兼容性对比
- 10一站式低代码开发平台iVX初探_android 低代码平台
用python爬过这些网站,才敢说自己会爬虫!_python爬虫网址
赞
踩
前言
微信、知乎、新浪等主流网站的模拟登陆爬取方法。
网络上有形形色色的网站,不同类型的网站爬虫策略不同,难易程度也不一样。从是否需要登陆这方面来说,一些简单网站不需要登陆就可以爬,比如之前爬过的猫眼电影、东方财富网等。有一些网站需要先登陆才能爬,比如知乎、微信等。这类网站在模拟登陆时需要处理验证码、js 加密参数这些问题,爬取难度会大很多。费很大力气登陆进去后才能爬取想要的内容,很花时间。
(文末送读者福利)
是不是一定要自己动手去实现每一个网站的模拟登陆方法呢,从效率上来讲,其实大可不必,已经有前人替我们造好轮子了。
最近发现一个神库,汇总了数十个主流网站的模拟登陆方法:
知乎
微信网页版登录并获取好友列表
Bilibili
无需身份验证即可抓取Twitter前端API
微博网页版
QQZone
CSDN
淘宝
Baidu
果壳
JingDong 模拟登录
163mail
拉钩
豆瓣
Baidu2
猎聘网
Github
爬取图虫相应的图片
网易云音乐
糗事百科
这些网站基本采用的是直接登录或者 selenium+webdriver 方式。每一个网站都有完整的模拟登陆代码,拿来就可以用到自己的爬虫中。
下面我们来测试一下。
先说说很难爬的「知乎」,假如我们想爬取知乎主页的 HTML 内容,就必须要先登陆才能爬,不然看不到这个界面。下面来简单梳理一下流程。
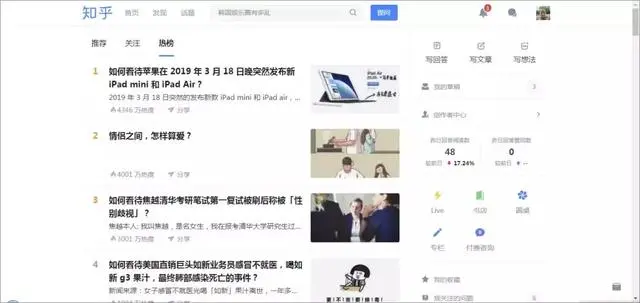
Python爬虫:爬过这些网站,才敢说自己会爬虫!
Python爬虫:爬过这些网站,才敢说自己会爬虫!
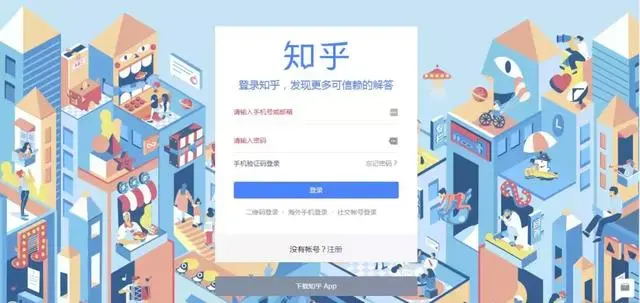
知乎需要手机号才能注册登陆。为了方便测试,可以随便找个手机号,手机号到哪儿去找呢,两个神网站保护你的隐私 这篇文章里介绍了一个免费电话号码网站,用上面的手机号可以成功注册。
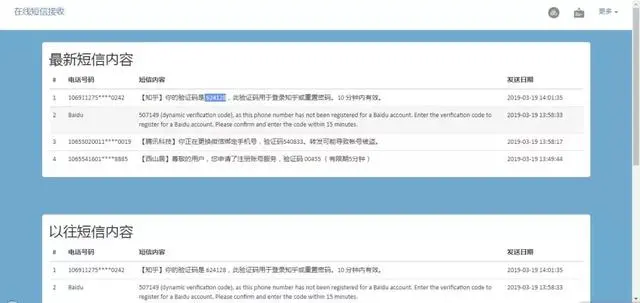
Python爬虫:爬过这些网站,才敢说自己会爬虫!
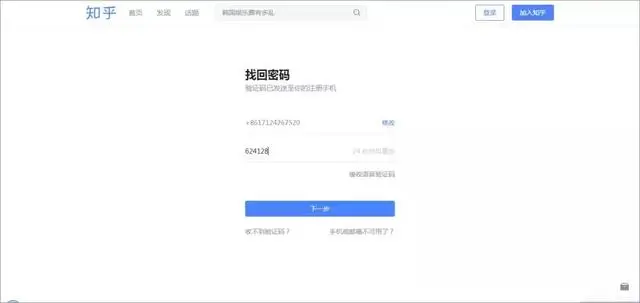
Python爬虫:爬过这些网站,才敢说自己会爬虫!
顺利登录后就可以进入主页了。
下面,我们用这个库提供的代码来模拟登陆,输出主页 HTML 内容作测试。操作很简单,只需要输入手机号、密码和验证码就可以了。
Python爬虫:爬过这些网站,才敢说自己会爬虫!
成功登陆后,接下来就可以做一些有意思的事了。比如曾有人爬取所有知乎账号的信息,分析了知乎用户群体画像。
是不是有点意思。
再来看看微信。用上面的微信代码可以把全部微信好友信息爬取下来,比如:昵称、性别、地域、个性签名。接着可以分析一下你的朋友圈是什么样的,应该会很有趣。
Python爬虫:爬过这些网站,才敢说自己会爬虫!
还可以爬 B 站:

Python爬虫:爬过这些网站,才敢说自己会爬虫!
还可以爬链家租房信息:

Python爬虫:爬过这些网站,才敢说自己会爬虫!
读者福利:知道你对Python感兴趣,便准备了这套python学习资料,
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python永久使用安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

