
- 12024最新的,免费的 ChatGPT 网站AI(八个)
- 2【蓝桥杯】第15届蓝桥杯青少组stema选拔赛C++中高级真题答案(20240310)_c++给定两个正整数 n 和 m(1≤n≤m≤1e6),统计 n 到 m 之间(含 n 和 m )每
- 3微信小程序答辩突击第一季,40个往年高频问题详细讲解!_商城小程序毕设答辩问题
- 4Dify学习笔记-入门学习(二)_takatost
- 5Spring Boot的启动器Starter详解_spring-boot-starter-parent spring-boot-starter-aop
- 6mysql排序命中索引_请问下如何在Mysql中where与orderBy后在命中索引?
- 7IDEA连接docker中的mysql(三步完成)(适合已在docker部署好MySQL的小可爱们)_idea连接docker部署的mysql数据库
- 8谁说程序员不懂浪漫?用Python每天自动给女朋友免费发短信_利用python给女朋友发彩信
- 9【Kafka系列 07】Kafka 如何保证消息不丢失_kafka 消息不丢失
- 10在vscode上面进行分支merge的记录
机器学习(四)——逻辑斯蒂回归(Logistic Regression)_逻辑斯谛回归 r
赞
踩
一、算法简介
1.1 概念
Logistic回归是分类方法,它利用的是Sigmoid函数阈值在[0,1]这个特性。Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。其实,Logistic本质上是一个基于条件概率的判别模型(Discriminative Model)。
二、Logistic回归理论推导
2.1 Logistic回归
要想了解Logistic回归,我们必须先看一看Sigmoid函数 ,我们也可以称它为Logistic函数。它的公式如下:
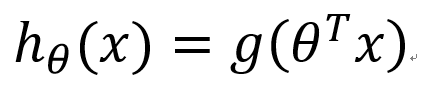

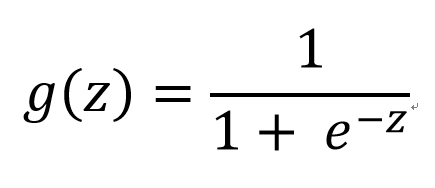
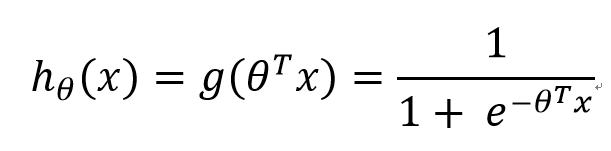
将sigmoid函数展示出来如下:

z是一个矩阵,θ是参数列向量(要求解的),x是样本列向量(给定的数据集)。θ^T表示θ的转置。g(z)函数实现了任意实数到[0,1]的映射,这样我们的数据集([x0,x1,…,xn]),不管是大于1或者小于0,都可以映射到[0,1]区间进行分类。hθ(x)给出了输出为1的概率。比如当hθ(x)=0.7,那么说明有70%的概率输出为1。输出为0的概率是输出为1的补集,也就是30%。
如果我们有合适的参数列向量θ([θ0,θ1,…θn]^T),以及样本列向量x([x0,x1,…,xn]),那么我们对样本x分类就可以通过上述公式计算出一个概率,如果这个概率大于0.5,我们就可以说样本是正样本,否则样本是负样本。
举个例子,对于"垃圾邮件判别问题",对于给定的邮件(样本),我们定义非垃圾邮件为正类,垃圾邮件为负类。我们通过计算出的概率值即可判定邮件是否是垃圾邮件。
2.1.1 参数向量θ
根据sigmoid函数的特性,我们可以做出如下的假设:

式即为在已知样本x和参数θ的情况下,样本x属性正样本(y=1)和负样本(y=0)的条件概率。理想状态下,根据上述公式,求出各个点得概率均为1,也就是完全分类都正确。但是考虑到实际情况没样本点得概率接近于1,其分类效果越好。我们可以把上述两个概率公式合二为一:

合并出来的Loss,我们称之为损失函数(Loss Function)。当y等于1时,(1-y)项(第二项)为0;当y等于0时,y项(第一项)为0。为s了简化问题,我们对整个表达式求对数,(将指数问题对数化是处理数学问题常见的方法):

这个损失函数,是对于一个样本而言的。给定一个样本,我们就可以通过这个损失函数求出样本所属类别的概率,而这个概率越大越好,所以也就是求解这个损失函数的最大值。既然概率出来了,那么最大似然估计也该出场了。假定样本与样本之间相互独立,那么整个样本集生成的概率即为所有样本生成概率的乘积,再将公式对数化,便可得到如下公式:

其中,m为样本的总数,y(i)表示第i个样本的类别,x(i)表示第i个样本,需要注意的是θ是多维向量,x(i)也是多维向量。
综上所述,满足J(θ)的最大的θ值即是我们需要求解的模型。
因为是求最大值,所以我们需要使用梯度上升算法。如果面对的问题是求解使J(θ)最小的θ值,那么我们就需要使用梯度下降算法。面对我们这个问题,如果使J(θ) := -J(θ),那么问题就从求极大值转换成求极小值了,使用的算法就从梯度上升算法变成了梯度下降算法,它们的思想都是相同的,学会其一,就也会了另一个。本文使用梯度上升算法进行求解。
2.2 梯度上升算法
为了说明梯度上升算法,先举个简单的例子:
以下函数为例:


求极值,先求函数的导数:

令导数为0,可求出x=2即取得函数f(x)的极大值。极大值等于f(2)=4。
但是真实环境中的函数不会像上面这么简单,就算求出了函数的导数,也很难精确计算出函数的极值。此时我们就可以用迭代的方法来做。就像爬坡一样,一点一点逼近极值。这种寻找最佳拟合参数的方法,就是最优化算法。爬坡这个动作用数学公式表达即为:

其中,α为步长,也就是学习速率,控制更新的幅度。效果如下图所示:

比如从(0,0)开始,迭代路径就是1->2->3->4->…->n,直到求出的x为函数极大值的近似值,停止迭代。我们可以编写Python3代码,来实现这一过程:
'''函数说明:梯度上升算法测试函数 求函数f(x) = -x^2 + 4x的极大值 Parameters: 无 Returns: 无 Modify: 2021-02-04 ''' def f_prime(x_old): return -2*x_old + 4 def Gradient_Ascent_test(): x_old = -1 #初始值,比x_new小的值 x_new = 0 #梯度上升初始值 alpha = 0.01 #步长 presision = 0.0000001 #精度,也就是更新阈值 while abs(x_new - x_old) > presision: x_old = x_new x_new = x_old + alpha * f_prime(x_old) print(x_new) if __name__ == '__main__': Gradient_Ascent_test()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
运行结果为:1.999995150260194,接近真实极值2。J(θ)这个函数的极值,也可以这么求解。公式可以这么写:

而:

sigmoid函数为:
那么,现在我只要求出J(θ)的偏导,就可以利用梯度上升算法,求解J(θ)的极大值了。
现在开始求J(θ)对θ的偏导:
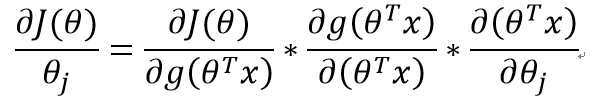
分别对三个部分进行求导:
第一部分:
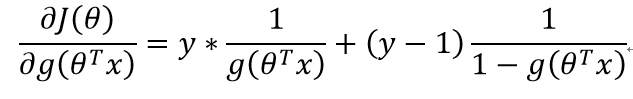
第二部分:
由
可得:
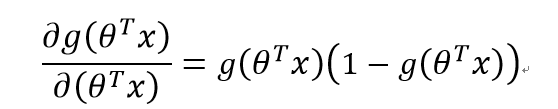
第三部分:
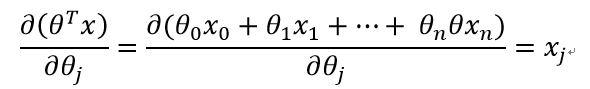
综上所述:

梯度上升迭代公式为:
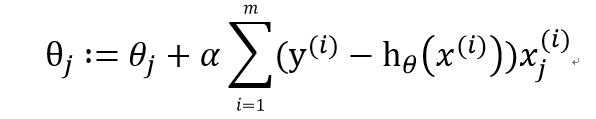
三、实战
3.1 数据预处理
数据集如下所示:

这个数据有两维特征,因此可以将数据在一个二维平面上展示出来。我们可以将第一列数据(X1)看作x轴上的值,第二列数据(X2)看作y轴上的值。而最后一列数据即为分类标签。根据标签的不同,对这些点进行分类。
那么,先让我们编写代码,看下数据集的分布情况:
import matplotlib.pyplot as plt import numpy as np ''' 函数说明:加载数据 Parameters: 无 Returns: dataMat - 数据列表 labelMat - 标签列表 Modify: 2021-02-05 ''' def loadDataSet(): dataMat = [] #创建数据列表 labelMat = [] #创建标签列表 fr = open('testSet.txt') #打开文件 for line in fr.readlines(): lineArr = line.strip().split() dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])]) labelMat.append(int(lineArr[-1])) fr.close() return dataMat,labelMat ''' 函数说明:绘制数据集 Parameters: 无 Returns: 无 Modify: 2021-02-05 ''' def plotDataSet(): dataMat,labelMat = loadDataSet() #加载数据集 dataArr = np.array(dataMat) #将数据由列表转为数组类型 # print(dataArr) n = np.shape(dataMat)[0] #数据个数 xcord1 = [];ycord1 = [] #正样本 xcord2 = [];ycord2 = [] #负样本 for i in range(n): if int(labelMat[i]) == 1: xcord1.append(dataArr[i,1]);ycord1.append(dataArr[i,2]) else: xcord2.append(dataArr[i,1]);ycord2.append(dataArr[i,2]) fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(xcord1,ycord1,s = 20,c='red',marker='s',alpha=.5) ax.scatter(xcord2,ycord2,s = 20,c='green',marker='s',alpha=.5) plt.title('DataSet') plt.xlabel('x');plt.ylabel('y') plt.show() if __name__ == '__main__': plotDataSet()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
运行结果如下:

从上图可以看出数据的分布情况。假设Sigmoid函数的输入记为z,那么z=w0x0 + w1x1 + w2x2,即可将数据分割开。其中,x0为全是1的向量,x1为数据集的第一列数据,x2为数据集的第二列数据。另z=0,则0=w0 + w1x1 + w2x2。横坐标为x1,纵坐标为x2。这个方程未知的参数为w0,w1,w2,也就是我们需要求的回归系数(最优参数)。
3.2 训练算法
3.2.1 梯度上升算法
根据矢量化的公式,编写代码如下:
import matplotlib.pyplot as plt import numpy as np ''' 函数说明:加载数据 Parameters: 无 Returns: dataMat - 数据列表 labelMat - 标签列表 Modify: 2021-02-05 ''' def loadDataSet(): dataMat = [] #创建数据列表 labelMat = [] #创建标签列表 fr = open('testSet.txt') #打开文件 for line in fr.readlines(): lineArr = line.strip().split() dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])]) labelMat.append(int(lineArr[-1])) fr.close() return dataMat,labelMat ''' 函数说明:sigmoid函数 Parameters: inX - 数据 Returns: sigmoid函数 Modify: 2021-02-05 ''' def sigmoid(inX): return 1.0/(1+np.exp(-inX)) ''' 函数说明:梯度上升算法 Parameters: dataMatIn - 数据集 classLabels - 数据标签 Returns: weights.getA() - 求得的权重数组(最优参数) Modify: 2021-02-05 ''' def gradAscent(dataMatIn,classLabels): dataMatrix = np.mat(dataMatIn) #将数据转换成mat格式 labelMat = np.mat(classLabels).transpose() #将标签转换成mat,并进行转置 m, n = np.shape(dataMatrix) #返回dataMatrix的大小 alpha = 0.001 #步长 maxCycles = 500 #最大迭代次数 weights = np.ones((n,1)) for k in range(maxCycles): h = sigmoid(np.dot(dataMatrix,weights)) error = labelMat - h weights = weights + alpha * dataMatrix.transpose() * error print() return weights.getA() ''' 函数说明:绘制数据集 Parameters: weights - 权重参数数组 Returns: 无 Modify: 2021-02-05 ''' def plotBestFit(weights): dataMat,labelMat = loadDataSet() #加载数据集 dataArr = np.array(dataMat) #将数据由列表转为数组类型 # print(dataArr) n = np.shape(dataMat)[0] #数据个数 xcord1 = [];ycord1 = [] #正样本 xcord2 = [];ycord2 = [] #负样本 for i in range(n): if int(labelMat[i]) == 1: xcord1.append(dataArr[i,1]);ycord1.append(dataArr[i,2]) else: xcord2.append(dataArr[i,1]);ycord2.append(dataArr[i,2]) fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(xcord1,ycord1,s = 20,c='red',marker='s',alpha=.5) ax.scatter(xcord2,ycord2,s = 20,c='green',marker='s',alpha=.5) x = np.arange(-3.0,3.0,0.1) y = (-weights[0] - weights[1] * x)/weights[2] ax.plot(x,y) plt.title('BestFit') plt.xlabel('x');plt.ylabel('y') plt.show() if __name__ == '__main__': dataMat,labelMat = loadDataSet() weights = gradAscent(dataMat,labelMat) plotBestFit(weights)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
运行结果如下:

这个分类结果相当不错,从上图可以看出,只分错了几个点而已。但是,尽管例子简单切数据集很小,但是这个方法却需要大量的计算(300次乘法)。因此下面将对改算法稍作改进,从而减少计算量,使其可以应用于大数据集上。
3.2.2 随机梯度上升算法
简而言之就是再每次计算h的时候将全部样本改成随机挑选一个样本进行梯度计算。代码如下;
import matplotlib.pyplot as plt import numpy as np import random ''' 函数说明:加载数据 Parameters: 无 Returns: dataMat - 数据列表 labelMat - 标签列表 Modify: 2021-02-05 ''' def loadDataSet(): dataMat = [] #创建数据列表 labelMat = [] #创建标签列表 fr = open('testSet.txt') #打开文件 for line in fr.readlines(): lineArr = line.strip().split() dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])]) labelMat.append(int(lineArr[-1])) fr.close() return dataMat,labelMat ''' 函数说明:sigmoid函数 Parameters: inX - 数据 Returns: sigmoid函数 Modify: 2021-02-05 ''' def sigmoid(inX): return 1.0/(1+ np.exp(-inX)) ''' 函数说明:梯度上升算法 Parameters: dataMatIn - 数据集 classLabels - 数据标签 Returns: weights.getA() - 求得的权重数组(最优参数) Modify: 2021-02-05 ''' def gradAscent(dataMatrix,classLabels,maxCycles = 150): m, n = np.shape(dataMatrix) #返回dataMatrix的大小 weights = np.ones(n) for k in range(maxCycles): dataIndex = list(range(m)) for i in range(m): alpha = 4 /(1.0 + k + i) + 0.01 rangeIndex = int(random.uniform(0,len(dataIndex))) h = sigmoid(sum(dataMatrix[dataIndex[rangeIndex]] * weights)) error = classLabels[dataIndex[rangeIndex]] - h weights = weights + alpha * dataMatrix[dataIndex[rangeIndex]] * error del(dataIndex[rangeIndex]) return weights ''' 函数说明:绘制数据集 Parameters: weights - 权重参数数组 Returns: 无 Modify: 2021-02-05 ''' def plotBestFit(weights): dataMat,labelMat = loadDataSet() #加载数据集 dataArr = np.array(dataMat) #将数据由列表转为数组类型 n = np.shape(dataMat)[0] #数据个数 xcord1 = [];ycord1 = [] #正样本 xcord2 = [];ycord2 = [] #负样本 for i in range(n): if int(labelMat[i]) == 1: xcord1.append(dataArr[i,1]);ycord1.append(dataArr[i,2]) else: xcord2.append(dataArr[i,1]);ycord2.append(dataArr[i,2]) fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(xcord1,ycord1,s = 20,c='red',marker='s',alpha=.5) ax.scatter(xcord2,ycord2,s = 20,c='green',marker='s',alpha=.5) x = np.arange(-3.0,3.0,0.1) y = (-weights[0] - weights[1] * x)/weights[2] ax.plot(x,y) plt.title('BestFit') plt.xlabel('x');plt.ylabel('y') plt.show() if __name__ == '__main__': dataMat,labelMat = loadDataSet() weights = gradAscent(np.array(dataMat),labelMat) plotBestFit(weights)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
3.2.3 回归系数与迭代次数的关系
可以看到分类效果也是不错的。不过,从这个分类结果中,我们不好看出迭代次数和回归系数的关系,也就不能直观的看到每个回归方法的收敛情况。因此,我们编写程序,绘制出回归系数和迭代次数的关系曲线:
from matplotlib.font_manager import FontProperties import matplotlib.pyplot as plt import numpy as np import random ''' 函数说明:加载数据 Parameters: 无 Returns: dataMat - 数据列表 labelMat - 标签列表 Modify: 2021-02-07 ''' def loadDataSet(): dataMat = [] #创建数据列表 labelMat = [] #创建标签列表 fr = open('testSet.txt') #打开文件 for line in fr.readlines(): lineArr = line.strip().split() dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])]) labelMat.append(int(lineArr[-1])) fr.close() return dataMat,labelMat ''' 函数说明:sigmoid函数 Parameters: inX - 数据 Returns: sigmoid函数 Modify: 2021-02-05 ''' def sigmoid(inX): return 1.0/(1 + np.exp(-inX)) ''' 函数说明:梯度上升算法 Parameters: dataMatIn - 数据集 classLabels - 数据标签 Returns: weights.getA() - 求得的权重数组(最优参数) Modify: 2021-02-05 ''' def gradAscent(dataMatIn,classLabels): dataMatrix = np.mat(dataMatIn) #将数据转换成mat格式矩阵 labelMat = np.mat(classLabels).transpose() #将标签转换成mat,并进行转置 m, n = np.shape(dataMatrix) #返回dataMatrix的大小 alpha = 0.01 #步长 maxCycles = 500 #最大迭代次数 weights = np.ones((n,1)) weights_array = np.array([]) for k in range(maxCycles): h = sigmoid(np.dot(dataMatrix,weights)) error = labelMat - h weights = weights + alpha * dataMatrix.transpose() * error weights_array = np.append(weights_array,weights) weights_array = weights_array.reshape(maxCycles,n) return weights.getA() ,weights_array ''' 函数说明:随机梯度上升算法 Parameters: dataMatIn - 数据集 classLabels - 数据标签 Returns: weights.getA() - 求得的权重数组(最优参数) Modify: 2021-02-05 ''' def stocGradAscent(dataMatrix,classLabels,numIter = 150): dataMatrix=np.array(dataMatrix) m, n = np.shape(dataMatrix) #返回dataMatrix的大小 weights = np.ones(n) #创建一个全为1的矩阵 weights_array = np.array([]) #创建一个空数组 for j in range(numIter): dataIndex = list(range(m)) for i in range(m): alpha = 4 /(1.0 + j + i) + 0.01 randIndex = int(random.uniform(0,len(dataIndex))) h = sigmoid(sum(dataMatrix[dataIndex[randIndex]] * weights)) error = classLabels[dataIndex[randIndex]] - h weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]] weights_array = np.append(weights_array,weights,axis = 0) del(dataIndex[randIndex]) weights_array = weights_array.reshape(numIter*m,n) return weights,weights_array ''' 函数说明:绘制回归系数与迭代次数的关系 Parameters: weights_array1 - 回归系数数组1 weights_array2 - 回归系数数组2 Returns: 无 Modify: 2021-02-07 ''' def plotWeights(weights_array_1,weights_array_2): font = FontProperties(fname = r"c:\Windows\Fonts\SimHei.ttf",size = 14) fig,axs = plt.subplots(nrows=3,ncols=2,sharex=False,sharey=False,figsize=(20,10)) x1 = np.arange(0,len(weights_array_1),1) #绘制W0与迭代次数的关系 axs[0][0].plot(x1,weights_array_1[:,0]) axs0_title_text = axs[0][0].set_title(u'梯度上升算法:回归系数与迭代次数关系',FontProperties=font) axs0_ylabel_text = axs[0][0].set_ylabel(u'W0',FontProperties=font) plt.setp(axs0_title_text,size=20,weight='bold',color='black') plt.setp(axs0_ylabel_text,size=20,weight='bold',color='black') #绘制W1与迭代次数的关系 axs[1][0].plot(x1,weights_array_1[:,1]) axs1_ylabel_text = axs[1][0].set_ylabel(u'W1',FontProperties=font) plt.setp(axs1_ylabel_text,size=20,weight='bold',color='black') #绘制W2与迭代次数的关系 axs[2][0].plot(x1,weights_array_1[:,2]) axs2_xlabel_text = axs[2][0].set_xlabel(u'迭代次数',FontProperties=font) axs2_ylabel_text = axs[2][0].set_ylabel(u'W2',FontProperties=font) plt.setp(axs2_xlabel_text,size=20,weight='bold',color='black') plt.setp(axs2_ylabel_text,size=20,weight='bold',color='black') x2 = np.arange(0,len(weights_array_2),1) #绘制W0与迭代次数的关系 axs[0][1].plot(x2,weights_array_2[:,0]) axs0_title_text = axs[0][1].set_title(u'随机梯度上升算法:回归系数与迭代次数关系',FontProperties=font) axs0_ylabel_text = axs[0][1].set_ylabel(u'W0',FontProperties=font) plt.setp(axs0_title_text,size=20,weight='bold',color='black') plt.setp(axs0_ylabel_text,size=20,weight='bold',color='black') #绘制W1与迭代次数的关系 axs[1][1].plot(x2,weights_array_2[:,1]) axs1_ylabel_text = axs[1][1].set_ylabel(u'W1',FontProperties=font) plt.setp(axs0_ylabel_text,size=20,weight='bold',color='black') #绘制W2与迭代次数的关系 axs[2][1].plot(x2,weights_array_2[:,2]) axs2_xlabel_text = axs[2][1].set_xlabel(u'迭代次数',FontProperties=font) axs2_ylabel_text = axs[2][1].set_ylabel(u'W2',FontProperties=font) plt.setp(axs2_xlabel_text,size=20,weight='bold',color='black') plt.setp(axs2_ylabel_text,size=20,weight='bold',color='black') plt.show() if __name__ == '__main__': dataMat,labelMat = loadDataSet() weights1,weights_array_1 = gradAscent(dataMat,labelMat) weights2,weights_array_2 = stocGradAscent(np.array(dataMat),labelMat) plotWeights(weights_array_1,weights_array_2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165

由于改进的随机梯度上升算法,随机选取样本点,所以每次的运行结果是不同的。但是大体趋势是一样的。我们的随机梯度上升算法收敛效果更好。为什么这么说呢?让我们分析一下。我们一共有100个样本点,改进的随机梯度上升算法迭代次数为150。而上图显示15000次迭代次数的原因是,使用一次样本就更新一下回归系数。因此,迭代150次,相当于更新回归系数150*100=15000次。简而言之,迭代150次,更新1.5万次回归参数。从上图左侧的改进随机梯度上升算法回归效果中可以看出,其实在更新2000次回归系数的时候,已经收敛了。相当于遍历整个数据集20次的时候,回归系数已收敛。训练已完成。
再让我们看看上图左侧的梯度上升算法回归效果,梯度上升算法每次更新回归系数都要遍历整个数据集。从图中可以看出,当迭代次数为300多次的时候,回归系数才收敛。凑个整,就当它在遍历整个数据集300次的时候已经收敛好了。
两边对比可以发现,随机梯度上升算法在遍历数据集的20次就开始收敛,但是梯度上升算法需要遍历数据集300次才开始收敛,由此可见随机梯度上升算法在可以更快更节省计算资源的进行训练。
但是,在数据集较小时,随机梯度上升算法并不那么管用,数据集较小时收敛速度较慢会导致每次遍历数据集后并未得到较好的系数,故在数据当数据集较小时,使用梯度上升算法当数据集较大时,使用的随机梯度上升算法。
四、使用sklearn构建logistic回归分类器
logisitc回归模型在sklearn库中sklearn.linear_model模块中,其中还有很多其他的例如Lasso回归,岭回归等需要我们继续学习。本文使用Logistic回归。
4.1 LogisticRegression
首先看下LogisticRegression函数,一共14个参数:

参数说明:
- **penaity:**惩罚项,str类型,可选参数为l1和l2,默认参数为l2。用于指定惩罚项中的使用规范。newton-cg、sag和lbfgs求解算法只支持L2规范。L1G规范假设的是模型的参数满足拉普拉斯分布,L2假设的模型参数满足高斯分布,所谓的范式就是加上对参数的约束,使得模型更不会过拟合(overfit),但是如果要说是不是加了约束就会好,这个没有人能回答,只能说,加约束的情况下,理论上应该可以获得泛化能力更强的结果。
- **duel:**对偶或原始方法,bool类型,默认为False。对偶方法只用在求解线性多核(liblinear)的L2惩罚项上。当样本数量>样本特征的时候,dual通常设置为False。
- **tol:**停止求解的标准,float类型,默认为1e-4。就是求解到多少的时候停止认为求出最优解。
- **c:**正则化系数λ的倒数,float类型,默认为1.0。必须是正浮点型数。像SVM一样,越小的数值表示越强的正则化。
- **fit_intercept:**是否存在截距或偏差,bool类型,默认为True。
- **intercept_scaling:**仅在正则化项为“liblinear”,且fit_intercept设置为True时有用。float类型,默认为1。
- **class_weight:**用于标示分类模型中各种类型的权重,可以是一个字典或者’balanced’字符串,默认为不输入,也就是不考虑权重,即为None。如果选择输入的话,可以选择balanced让类库自己计算类型权重,或者自己输入各个类型的权重。举个例子,比如对于0,1的二元模型,我们可以定义class_weight={0:0.9,1:0.1},这样类型0的权重为90%,而类型1的权重为10%。如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,样本量越少,则权重越高。当class_weight为balanced时,类权重计算方法如下:n_samples / (n_classes * np.bincount(y))。n_samples为样本数,n_classes为类别数量,np.bincount(y)会输出每个类的样本数,例如y=[1,0,0,1,1],则np.bincount(y)=[2,3]。那么class_weight的具体作用有什么呢?
- 第一种是误分类的代价很高。比如对合法用户和非法用户进行分类,将非法用户分类为合法用户的代价很高,我们宁愿将合法用户分类为非法用户,这时可以人工再甄别,但是却不愿将非法用户分类为合法用户。这时,我们可以适当提高非法用户的权重。
- 第二种是样本是高度失衡的,比如我们有合法用户和非法用户的二元样本数据10000条,里面合法用户有9995条,非法用户只有5条,如果我们不考虑权重,则我们可以将所有的测试集都预测为合法用户,这样预测准确率理论上有99.95%,但是却没有任何意义。这时,我们可以选择balanced,让类库自动提高非法用户样本的权重。提高了某种分类的权重,相比不考虑权重,会有更多的样本分类划分到高权重的类别,从而可以解决上面两类问题。 - **random_state:**随机数种子,int类型,可选参数,默认为无。仅在正则化优化算法为sag,liblinear时有用。
- **solver:**优化算法选择参数,只有五个可选参数,即newton-cg,lbfgs,liblinear,sag,saga。默认为liblinear。solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
- **libinear:**使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- **lbfgs:**拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- **newton-cg:**也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- **sag:**即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
- **saga:**线性收敛的随机优化算法的变种。
- 总结:
- libinear使用于小数据集,而sag和saga适用于大数据集因为速度更快。
- 对于多分类问题,只有newton-cg,sag,saga和lbfgs能够处理多项损失,而liblinear受限于一对剩余(OvR)。啥意思,就是用liblinear的时候,如果是多分类问题,得先把一种类别作为一个类别,剩余的所有类别作为另外一个类别。一次类推,遍历所有类别,进行分类。
- newton-cg,sag和lbfgs这三种优化算法时都需要损失函数的一阶或者二阶连续导数,因此不能用于没有连续导数的L1正则化,只能用于L2正则化。而liblinear和saga通吃L1正则化和L2正则化。
- 同时,sag每次仅仅使用了部分样本进行梯度迭代,所以当样本量少的时候不要选择它,而如果样本量非常大,比如大于10万,sag是第一选择。但是sag不能用于L1正则化,所以当你有大量的样本,又需要L1正则化的话就要自己做取舍了。要么通过对样本采样来降低样本量,要么回到L2正则化。
- 从上面的描述,大家可能觉得,既然newton-cg, lbfgs和sag这么多限制,如果不是大样本,我们选择liblinear不就行了嘛!错,因为liblinear也有自己的弱点!我们知道,逻辑回归有二元逻辑回归和多元逻辑回归。对于多元逻辑回归常见的有one-vs-rest(OvR)和many-vs-many(MvM)两种。而MvM一般比OvR分类相对准确一些。郁闷的是liblinear只支持OvR,不支持MvM,这样如果我们需要相对精确的多元逻辑回归时,就不能选择liblinear了。也意味着如果我们需要相对精确的多元逻辑回归不能使用L1正则化了。 - **max_iter:**算法收敛最大迭代次数,int类型,默认为10。仅在正则化优化算法为newton-cg, sag和lbfgs才有用,算法收敛的最大迭代次数。
- **multi_class:**分类方式选择参数,str类型,可选参数为ovr和multinomial,默认为ovr。ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。
- OvR和MvM有什么不同
- OvR的思想很简单,无论你是多少元逻辑回归,我们都可以看做二元逻辑回归。具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,然后在上面做二元逻辑回归,得到第K类的分类模型。其他类的分类模型获得以此类推。
- 而MvM则相对复杂,这里举MvM的特例one-vs-one(OvO)作讲解。如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,不妨记为T1类和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。我们一共需要T(T-1)/2次分类。
- 可以看出OvR相对简单,但分类效果相对略差(这里指大多数样本分布情况,某些样本分布下OvR可能更好)。而MvM分类相对精确,但是分类速度没有OvR快。如果选择了ovr,则4种损失函数的优化方法liblinear,newton-cg,lbfgs和sag都可以选择。但是如果选择了multinomial,则只能选择newton-cg, lbfgs和sag了。 - **verbose:**日志冗长度,int类型。默认为0。就是不输出训练过程,1的时候偶尔输出结果,大于1,对于每个子模型都输出。
- **warm_start:**热启动参数,bool类型。默认为False。如果为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)。
- **n_jobs:**并行数。int类型,默认为1。1的时候,用CPU的一个内核运行程序,2的时候,用CPU的2个内核运行程序。为-1的时候,用所有CPU的内核运行程序。
4.2 代码编写
from sklearn.linear_model import LogisticRegression """ 函数说明:使用Sklearn构建Logistic回归分类器 Parameters: 无 Returns: 无 Modify: 2021-02-19 """ def colicSklearn(): frTrain = open('horseColicTraining.txt') #打开训练集 frTest = open('horseColicTest.txt') #打开测试集 trainingSet = []; trainingLabels = [] testSet = []; testLabels = [] for line in frTrain.readlines(): currLine = line.strip().split('\t') lineArr = [] for i in range(len(currLine)-1): lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[-1])) for line in frTest.readlines(): currLine = line.strip().split('\t') lineArr =[] for i in range(len(currLine)-1): lineArr.append(float(currLine[i])) testSet.append(lineArr) testLabels.append(float(currLine[-1])) classifier = LogisticRegression(solver='liblinear',max_iter=10).fit(trainingSet, trainingLabels) test_accurcy = classifier.score(testSet, testLabels) * 100 print('正确率:%f%%' % test_accurcy) if __name__ == '__main__': colicSklearn()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
五、总结
5.1 优点
- 实现简单,容易理解和实现
- 计算代价不高,速度快,存储资源低
5.2 缺点
- 容易欠拟合
- 分类精度可能不高
5.3 其他
- Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以由最优化算法完成。
- 要根据数据集的大小灵活选择最优化算法,小的数据集选sag,大的数据集选liblinear。
- 机器学习的一个重要问题就是如何处理确实数据,需要根据实际情况处理。
参考:https://cuijiahua.com/blog/2017/11/ml_6_logistic_1.html
https://cuijiahua.com/blog/2017/11/ml_7_logistic_2.html

