
- 1rabbitMq动态创建和监听队列_rabbitmq动态创建队列
- 2简易登录页面实现_一个简单的登录界面网页代码
- 3三色球问题_三色球问题 rgb分别代表红色,绿色,蓝色球。 输入 给定一串字符串
- 4删除有序数组中的重复项(C Language)
- 5毕业设计 基于Stm32的智能药箱系统
- 6MYSQL性能调优: 对聚簇索引和非聚簇索引的认识_聚簇索引的调整
- 7uniapp使用sqlite_uniapp 关闭sqlite
- 8Could not open client transport with JDBC Uri: jdbc:hive2://cdh-master:10000/default: null
- 9uniapp引入uview不成功,报错未注册did you register the component correctly? For recursive components,_引入了uview还报错[vue warn]:
- did you re - 10密码学 | 椭圆曲线 ECC 密码学入门(一)
windows10系统通过docker搭建hadoop大数据集群(包括hive,zookeeperkafka,spark)_docker desktop hive
赞
踩
1、百度云下载自己搭建的hadoop_spark_master.tar和hadoop_spark_slaver.tar,分别为hadoop的master镜像和slaver镜像。
2、docker加载镜像:
docker load -i C:\Users\hasee\Desktop\hadoop_spark_master.tar
docker load -i C:\Users\hasee\Desktop\hadoop_spark_slaver.tar

3、给镜像重打个标签
docker tag 99e7e1c1bb85 hadoop_spark_slaver:1.0
docker tag ab6805768617 hadoop_spark_master:1.0

4、启动master节点
docker run --privileged -dti -m 3G --memory-swap 4G --name hadoop1 --hostname hadoop1 --add-host hadoop1:172.17.0.2 --add-host hadoop2:172.17.0.3 --add-host hadoop3:172.17.0.4 -p 221:22 -p 50070:50070 -p 8088:8088 -p 8080:8080 -p 28081:8081 -p 18080:18080 -p 4040:4040 -p 50030:50030 hadoop_spark_master:1.0 /usr/sbin/init
22端口映射到宿主机的221端口,用于ssh;
50070端口映射到宿主机的50070端口,用于hdfs;
8088端口映射到宿主机的8088端口,用于yarn;
8080端口映射到宿主机的8080端口,用于spark
报错:D:\software_setup\docker\Docker Toolbox\docker.exe: Error response from daemon: cgroups: cannot find cgroup mount destination: unknown.
解决办法:
docker-machine.exe ssh default
sudo mkdir /sys/fs/cgroup/systemd
sudo mount -t cgroup -o none,name=systemd cgroup /sys/fs/cgroup/systemd
5、启动第一个slaver节点
docker run --privileged -dti -m 2G --memory-swap 3G --name hadoop2 --hostname hadoop2 --add-host hadoop1:172.17.0.2 --add-host hadoop2:172.17.0.3 --add-host hadoop3:172.17.0.4 -p 222:22 -p 28082:8081 hadoop_spark_slaver:1.0 /usr/sbin/init
22端口映射到宿主机的222端口,用于ssh;
6、启动第二个slaver节点
docker run --privileged -dti -m 2G --memory-swap 3G --name hadoop3 --hostname hadoop3 --add-host hadoop1:172.17.0.2 --add-host hadoop2:172.17.0.3 --add-host hadoop3:172.17.0.4 -p 223:22 -p 28082:8081 hadoop_spark_slaver:1.0 /usr/sbin/init
22端口映射到宿主机的223端口,用于ssh;

7、secure crt连接三台服务器,ip分别是172.17.0.2;172.17.0.3;172.17.0.4,ssh端口分别是221;222;223,用户名和密码都是root/hadoop
8、启动hadoop
格式化namenode:hadoop namenode -format
启动hdfs和yarn:start-all.sh
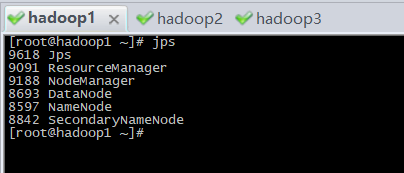
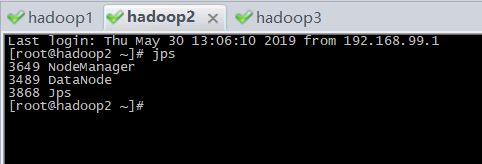
9、启动zookeeper
由于两台slaver节点由同一个镜像生成,需要将第2个从节点hadoop3的配置文件修改:
vi /usr/local/zk/data/myid
将1改成2
分别到三台机器上启动zk:zkServer.sh start
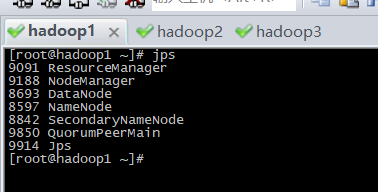
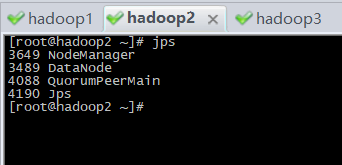
查看zk的状态:zkServer.sh status
其中一个为leader,两个为follower。
10、启动kafka
修改hadoop3的配置文件:vi /usr/local/kafka/config/server.properties
broker.id=1修改为broker.id=2
分别到三台机器上启动kafka:cd /usr/local/kafka/
nohup bin/kafka-server-start.sh config/server.properties &

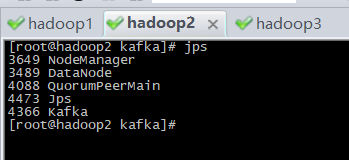
11、启动spark
只需要在hadoop1机器上执行: cd /usr/local/spark/sbin
./start-all.sh

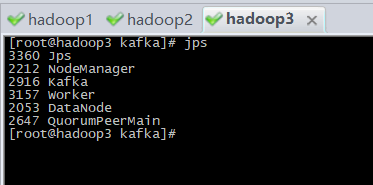
查看spark-shell:执行spark-shell

12、hive包已经在镜像中,无需操作。
检查hive:hadoop1中输入hive

13、浏览器查看hdfs、yarn、spark的ui界面



14、docker的hadoop集群状态
docker终端输入:docker stats

总结:至此,基于docker的hadoop集群搭建完成,主要是为了学习spark,文章中有错误之处欢迎补充。由于镜像文件较大,稍后在评论处给出百度云的连接。

