
- 1如何找到人生方向—请收好:测试工程师的十年职业规划_测试工程师 10年职业规划
- 2esp-12f单片机无线控制无刷电机,解锁BLHeli_S电调电机保护,BLHeli_S电调建立Keil工程。
- 3以下对python程序缩进格式描述错误的是_以下对Python 程序缩进格式描述错误的是()...
- 4数据关联分析_超网络分析关联关系
- 5Python网络爬虫之WMI:深入探索Windows管理接口(学习WMI,看这一篇就够了)_python wmi
- 6大厂面试八股文——数据结构_数据结构八股文
- 7git clone 用户名密码_git入门教程
- 8网络安全工具大全_wi-fi penetration tool
- 9华为OD机试真题 Java 实现【MVP争夺战】【2023Q1 100分】,附详细解题思路_在星球争霸篮球赛对抗赛中java 实现
- 10内网渗透—隧道搭建&SPP与NPS内网穿透_spp代理上线cs
程序员必须了解的消息队列之王-Kafka_kafka消息队列使用
赞
踩
1. Kafka概述
1.1 定义
Kafka 是由 Apache 软件基金会开发的一个开源流处理平台。
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
1.2 消息队列
1.2.1 传统消息队列的应用场景
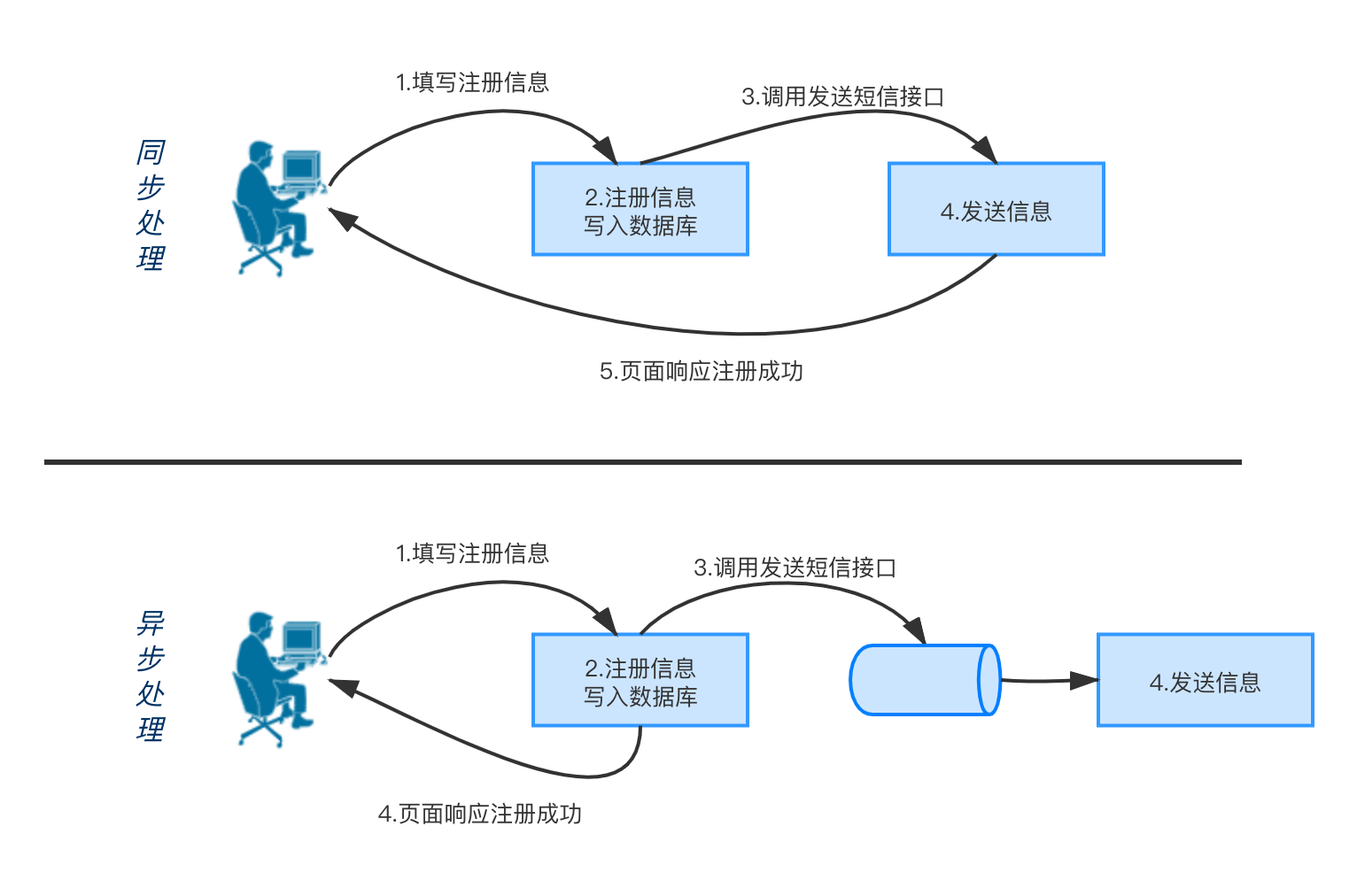
1.2.2 为什么需要消息队列
-
解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 -
冗余:消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。 -
扩展性: 因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。 -
灵活性 & 峰值处理能力: 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。 如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 -
可恢复性:系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 -
顺序保证:在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka 保证一个 Partition 内的消息的有序性) -
缓冲:有助于控制和优化数据流经过系统的速度, 解决生产消息和消费消息的处理速度不一致的情况。 -
异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
1.2.3 消息队列的两种模式
-
点对点模式(一对一,消费者主动拉取数据,收到后消息清除)
消息生产者生产消息发送到 Queue 中,然后消费者从 Queue 中取出并且消费消息。 消息被消费以后,queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。 Queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
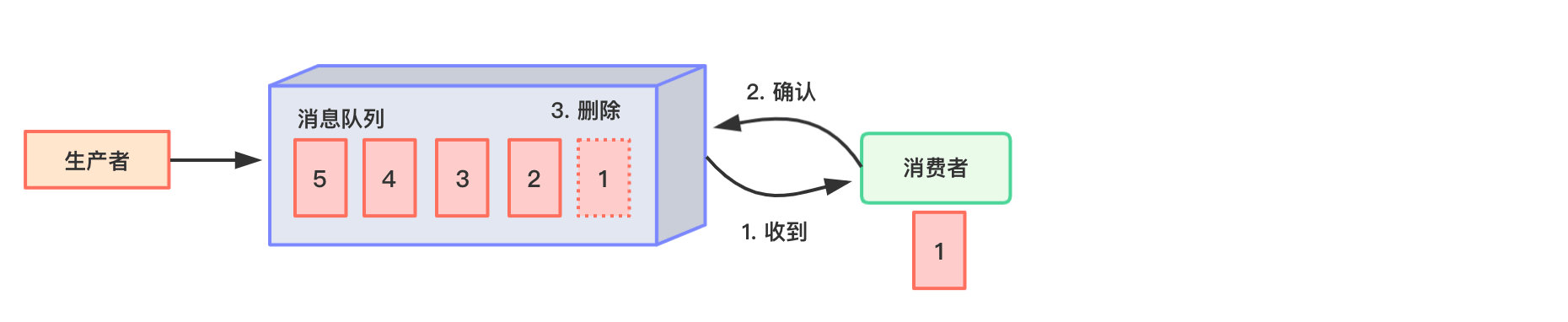
-
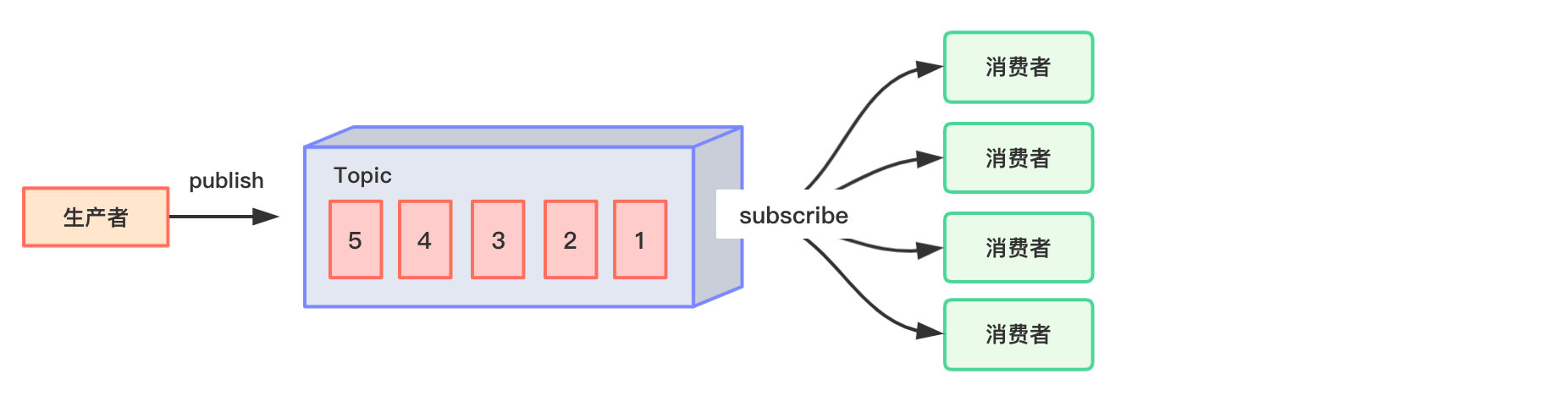
发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
1.3 Kafka 基础架构图
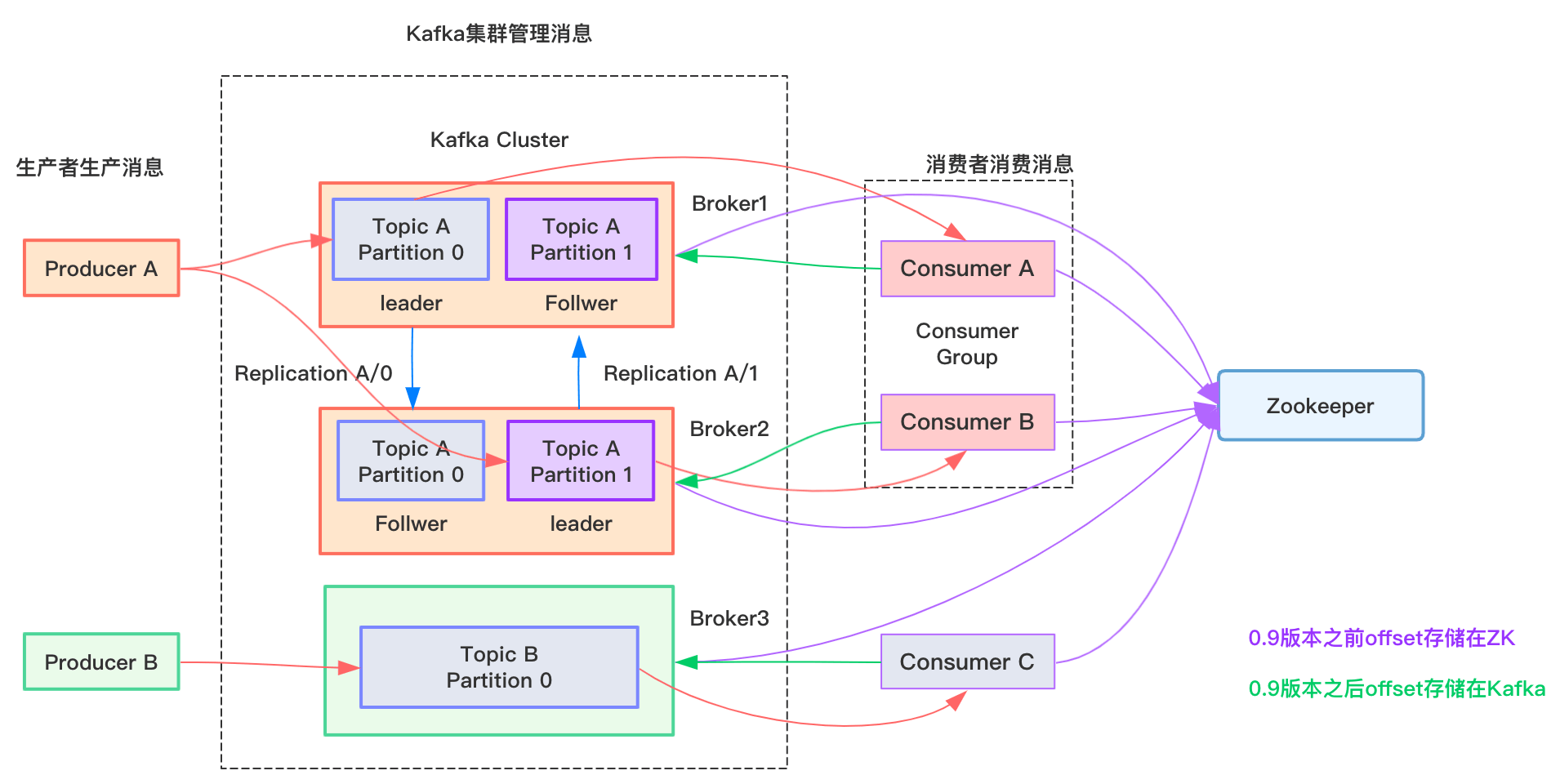
-
Producer :消息生产者,就是向 kafka broker 发消息的客户端; -
Consumer :消息消费者,向 kafka broker 取消息的客户端; -
Consumer Group (CG):消费者组,由多个 consumer 组成。 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。 -
Broker :一台 kafka 服务器就是一个 broker(虽然多个 Broker 进程能够运行在同一台机器上,但更常见的做法是将不同的 Broker 分散运行在不同的机器上)。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic; -
Topic :可以理解为一个队列,Kafka 的消息通过 Topics(主题) 进行分类,生产者和消费者面向的都是一个 topic; -
Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上, 一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列; partition 中的每条消息都会被分配一个有序的 id( offset)。 kafka 只保证按一个 partition 中的顺序将消息发给 consumer,不保证一个 topic 的整体(多个 partition 间)的顺序; -
Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本, 一个 leader 和若干个 follower; -
leader:每个分区多个副本的“主”, 生产者发送数据的对象,以及消费者消费数据的对象都是 leader; -
follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 follower; -
offset: kafka 的存储文件都是按照 offset.kafka来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就是 00000000000.kafka。
2. Hello Kafka
2.1 动起手来
2.2 基本概念(官方介绍翻译)
Kafka 是一个分布式的流处理平台。是支持分区的(partition)、多副本的(replica),基于 ZooKeeper 协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于 hadoop 的批处理系统、低延迟的实时系统、storm/Spark 流式处理引擎,web/nginx 日志、访问日志,消息服务等等
有三个关键能力
-
它可以让你发布和订阅记录流。在这方面,它类似于一个消息队列或企业消息系统 -
它可以让你持久化收到的记录流,从而具有容错能力 -
它可以让你处理收到的记录流
应用于两大类应用
-
构建实时的流数据管道,可靠地获取系统和应用程序之间的数据。 -
构建实时流的应用程序,对数据流进行转换或反应。
想要了解 Kafka 如何具有这些能力,首先,明确几个概念:
-
Kafka 作为一个集群运行在一个或多个服务器上 -
Kafka 集群存储的消息是以主题(topics)为类别记录的 -
每个消息记录包含一个键,一个值和时间戳
Kafka有五个核心API:
-
Producer API 允许应用程序发布记录流至一个或多个 Kafka 的话题(Topics)
-
Consumer API 允许应用程序订阅一个或多个主题,并处理这些主题接收到的记录流
-
Streams API 允许应用程序充当流处理器(stream processor),从一个或多个主题获取输入流,并生产一个输出流至一个或多个的主题,能够有效地变换输入流为输出流
-
Connector API 允许构建和运行可重用的生产者或消费者,能够把 Kafka 主题连接到现有的应用程序或数据系统。例如,一个连接到关系数据库的连接器(connector)可能会获取每个表的变化
-
Admin API 允许管理和检查主题、brokes 和其他 Kafka 对象。(这个是新版本才有的)
Kafka 的客户端和服务器之间的通信是靠一个简单的,高性能的,与语言无关的 TCP 协议完成的。这个协议有不同的版本,并保持向后兼容旧版本。Kafka 不光提供了一个 Java 客户端,还有许多语言版本的客户端。
主题和日志
主题是同一类别的消息记录(record)的集合。Kafka 的主题支持多用户订阅,也就是说,一个主题可以有零个,一个或多个消费者订阅写入的数据。对于每个主题,Kafka 集群都会维护一个分区日志,如下所示:
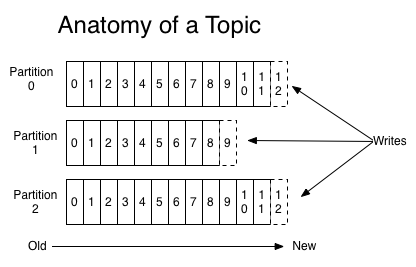
每个分区是一个有序的,不可变的消息序列,新的消息不断追加到 partition 的末尾。在每个 partition 中,每条消息都会被分配一个顺序的唯一标识,这个标识被称为 offset,即偏移量。kafka 不能保证全局有序,只能保证分区内有序 。
Kafka 集群保留所有发布的记录,不管这个记录有没有被消费过,Kafka 提供可配置的保留策略去删除旧数据(还有一种策略根据分区大小删除数据)。例如,如果将保留策略设置为两天,在数据发布后两天,它可用于消费,之后它将被丢弃以腾出空间。Kafka 的性能跟存储的数据量的大小无关(会持久化到硬盘), 所以将数据存储很长一段时间是没有问题的。
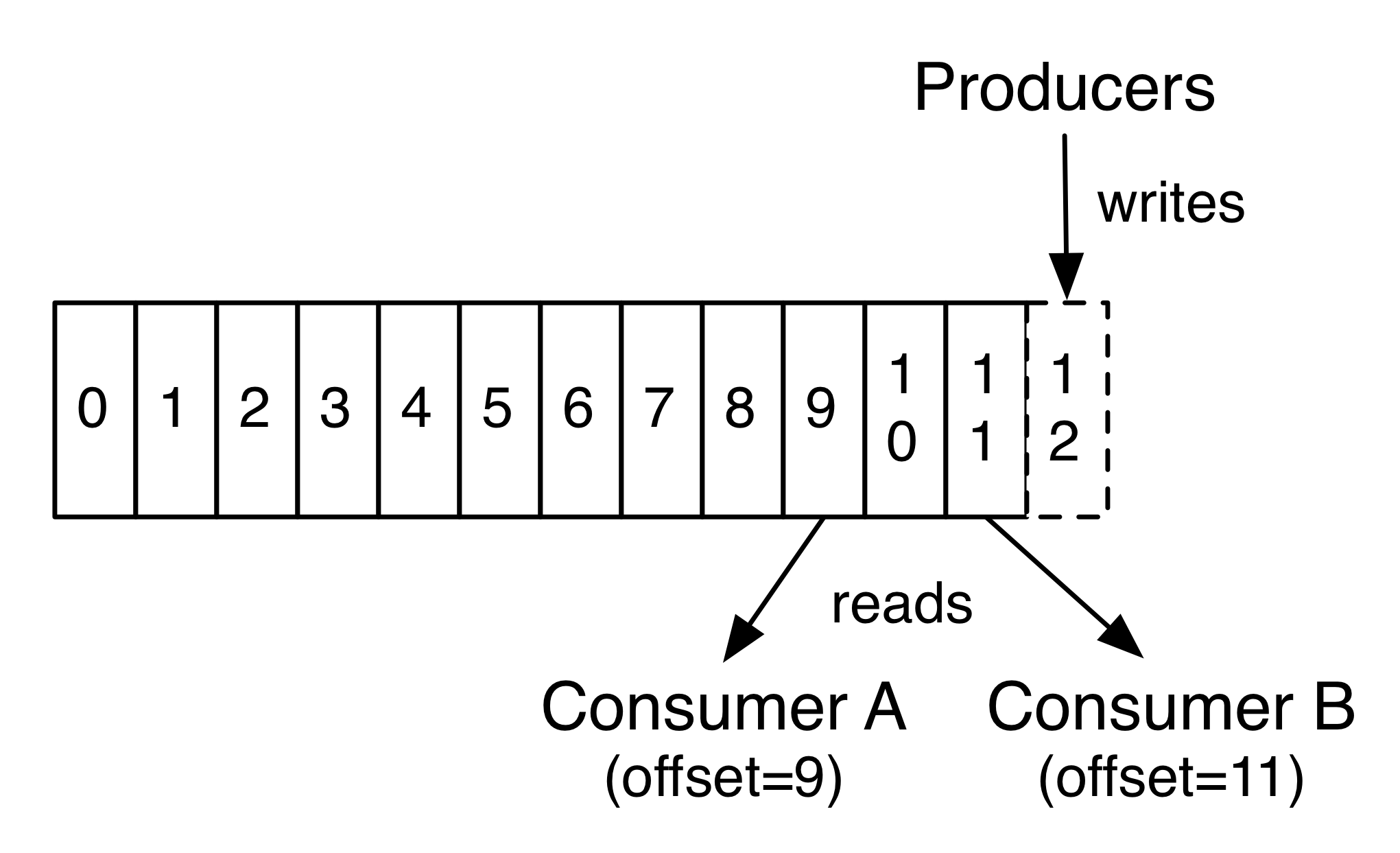
事实上,在单个消费者层面上,每个消费者保存的唯一的元数据就是它所消费的数据日志文件的偏移量。偏移量是由消费者来控制的,通常情况下,消费者会在读取记录时线性的提高其偏移量。不过由于偏移量是由消费者控制,所以消费者可以将偏移量设置到任何位置,比如设置到以前的位置对数据进行重复消费,或者设置到最新位置来跳过一些数据。
分布式
日志的分区会跨服务器的分布在 Kafka 集群中,每个服务器会共享分区进行数据请求的处理。每个分区可以配置一定数量的副本分区提供容错能力。
每个分区都有一个服务器充当“leader”和零个或多个服务器充当“followers”。 leader 处理所有的读取和写入分区的请求,而 followers 被动的从领导者拷贝数据。如果 leader 失败了,followers 之一将自动成为新的领导者。每个服务器可能充当一些分区的 leader 和其他分区的 follower,所以 Kafka 集群内的负载会比较均衡。
生产者
生产者发布数据到他们所选择的主题。生产者负责选择把记录分配到主题中的哪个分区。这可以使用轮询算法( round-robin)进行简单地平衡负载,也可以根据一些更复杂的语义分区算法(比如基于记录一些键值)来完成。
消费者
消费者以消费群(consumer group )的名称来标识自己,每个发布到主题的消息都会发送给订阅了这个主题的消费群里面的一个消费者的一个实例。消费者的实例可以在单独的进程或单独的机器上。
如果所有的消费者实例都属于相同的消费群,那么记录将有效地被均衡到每个消费者实例。
如果所有的消费者实例有不同的消费群,那么每个消息将被广播到所有的消费者进程。
这是 kafka 用来实现一个 topic 消息的广播(发给所有的 consumer) 和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 CG。 topic 的消息会复制 (不是真的复制,是概念上的)到所有的 CG,但每个 partion 只会把消息发给该 CG 中的一 个 consumer。如果需要实现广播,只要每个 consumer 有一个独立的 CG 就可以了。要实现单播只要所有的 consumer 在同一个 CG。用 CG 还可以将 consumer 进行自由的分组而不需要多次发送消息到不同的 topic;
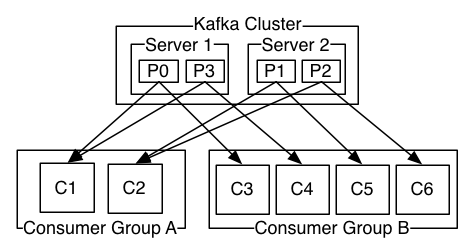
举个栗子:
如上图所示,一个两个节点的 Kafka 集群上拥有一个四个 partition(P0-P3)的 topic。有两个消费者组都在消费这个 topic 中的数据,消费者组 A 有两个消费者实例,消费者组 B 有四个消费者实例。
从图中我们可以看到,在同一个消费者组中,每个消费者实例可以消费多个分区,但是每个分区最多只能被消费者组中的一个实例消费。也就是说,如果有一个 4 个分区的主题,那么消费者组中最多只能有 4 个消费者实例去消费,多出来的都不会被分配到分区。其实这也很好理解,如果允许两个消费者实例同时消费同一个分区,那么就无法记录这个分区被这个消费者组消费的 offset 了。如果在消费者组中动态的上线或下线消费者,那么 Kafka 集群会自动调整分区与消费者实例间的对应关系。
Kafka消费群的实现方式是通过分割日志的分区,分给每个 Consumer 实例,使每个实例在任何时间点的都可以“公平分享”独占的分区。维持消费群中的成员关系的这个过程是通过 Kafka 动态协议处理。如果新的实例加入该组,他将接管该组的其他成员的一些分区;如果一个实例死亡,其分区将被分配到剩余的实例。
Kafka 只保证一个分区内的消息有序,不能保证一个主题的不同分区之间的消息有序。分区的消息有序与依靠主键进行数据分区的能力相结合足以满足大多数应用的要求。但是,如果你想要保证所有的消息都绝对有序可以只为一个主题分配一个分区,虽然这将意味着每个消费群同时只能有一个消费进程在消费。
保证
Kafka 提供了以下一些高级别的保证:
-
由生产者发送到一个特定的主题分区的消息将被以他们被发送的顺序来追加。也就是说,如果一个消息 M1 和消息 M2 都来自同一个生产者,M1 先发,那么 M1 将有一个低于 M2 的偏移,会更早在日志中出现。 -
消费者看到的记录排序就是记录被存储在日志中的顺序。 -
对于副本因子 N 的主题,我们将承受最多 N-1 次服务器故障切换而不会损失任何的已经保存的记录。
2.3 Kafka的使用场景
消息
Kafka 被当作传统消息中间件的替代品。消息中间件的使用原因有多种(从数据生产者解耦处理,缓存未处理的消息等)。与大多数消息系统相比,Kafka 具有更好的吞吐量,内置的分区,多副本和容错功能,这使其成为大规模消息处理应用程序的良好解决方案。
网站行为跟踪
Kafka 的初衷就是能够将用户行为跟踪管道重构为一组实时发布-订阅数据源。这意味着网站活动(页面浏览量,搜索或其他用户行为)将被发布到中心主题,这些中心主题是每个用户行为类型对应一个主题的。这些数据源可被订阅者获取并用于一系列的场景,包括实时处理,实时监控和加载到 Hadoop 或离线数据仓库系统中进行离线处理和报告。用户行为跟踪通常会产生巨大的数据量,因为用户每个页面的浏览都会生成许多行为活动消息。
测量
Kafka 通常用于监测数据的处理。这涉及从分布式应用程序聚集统计数据,生产出集中的运行数据源 feeds(以便订阅)。
日志聚合
许多人用 Kafka 作为日志聚合解决方案的替代品。日志聚合通常从服务器收集物理日志文件,并将它们集中放置(可能是文件服务器或HDFS),以便后续处理。kafka 抽象出文件的细节,并将日志或事件数据作为消息流清晰地抽象出来。这为低时延的处理提供支持,而且更容易支持多个数据源和分布式的数据消费。相比集中式的日志处理系统(如 Scribe 或 Flume),Kafka 性能同样出色,而且因为副本备份提供了更强的可靠性保证和更低的端到端延迟。
流处理
Kafka 的流数据管道在处理数据的时候包含多个阶段,其中原始输入数据从 Kafka 主题被消费然后汇总,加工,或转化成新主题用于进一步的消费或后续处理。例如,用于推荐新闻文章的数据流处理管道可能从 RSS 源抓取文章内容,并将其发布到“文章”主题; 进一步的处理可能是标准化或删除重复数据,然后发布处理过的文章内容到一个新的主题, 最后的处理阶段可能会尝试推荐这个内容给用户。这种处理管道根据各个主题创建实时数据流图。从版本 0.10.0.0 开始,Apache Kafka 加入了轻量级的但功能强大的流处理库 Kafka Streams,Kafka Streams 支持如上所述的数据处理。除了Kafka Streams,可以选择的开源流处理工具包括 Apache Storm and Apache Samza。
事件源
事件源是一种应用程序设计风格,是按照时间顺序记录的状态变化的序列。Kafka 的非常强大的存储日志数据的能力使它成为构建这种应用程序的极好的后端选择。
提交日志
Kafka 可以为分布式系统提供一种外部提交日志(commit-log)服务。日志有助于节点之间复制数据,并作为一种数据重新同步机制用来恢复故障节点的数据。Kafka 的 log compaction 功能有助于支持这种用法。Kafka 在这种用法中类似于 Apache BookKeeper 项目。
本文由 mdnice 多平台发布

