
- 1Redis缓存详解(黑马-未完结)_redis缓存介绍
- 2人脸识别示例解析(三)——微笑识别解析_面部识别 如何微笑
- 3渗透测试快速稳定远控软件,高级渗透测试第八季-demo即是远控
- 4基于java相亲交友系统的设计与实现论文_基于java的社交网站设计与实现
- 5文献学习-20-基于学习的视觉应变融合,用于手眼连续体机器人姿态估计与控制
- 6代码随想录-二分查找题目分析
- 7基于React Hooks的简单全局状态共享实现方案
- 8把数据从mysql导入到hdfs中_mysql to hdfs full
- 9淘宝人生2的AIGC技术应用——虚拟人写真算法技术方案
- 10MKS SERVO28C 闭环步进电机 使用说明_闭环步进电机怎么使用
AI近十年盘点:纵览AI发展历程,探寻AI未来走向_2015到2024年的ai发展
赞
踩
编者按:当我们回顾过去十年的人工智能发展历程时,可以看到一场现在还正在进行的变革,对我们的工作方式、商业运营模式和人际交往行为都产生了深远的影响。从2013年的AlexNet到变分自编码器,再到最近的生成式大模型,人工智能技术不断出现的突破性进展推动着整个领域的蓬勃发展。
本文将为您深度解读这些关键性技术突破,并且对人工智能未来的发展趋势进行展望。不论您是从事AI行业的开发者或研究人员,还是对最新AI技术发展充满好奇心的大众读者,我们热切期盼本篇文章能够为您提供一定的帮助。
让我们共同探索、拥抱人工智能吧!
以下是译文,Enjoy!
作者 | Thomas A Dorfer
编译 | 岳扬
目录
- 01 2013年:AlexNet与变分自编码
- 02 2014年:生成式对抗网络
- 03 2015年:ResNets和NLP领域的突破性进展
- 04 2016年:AlphaGo
- 05 2017年:Transformer架构和语言模型
- 06 2018年:GPT-1、BERT和图神经网络
- 07 2019年:GPT-2和改进的生成模型
- 08 2020年:GPT-3和自监督学习
- 09 2021年:AlphaFold 2、DALL-E和GitHub Copilot
- 10 2022年:ChatGPT 和 Stable Diffusion
- 11 2023年:LLMs和Bots
- 12 回顾过去&展望未来
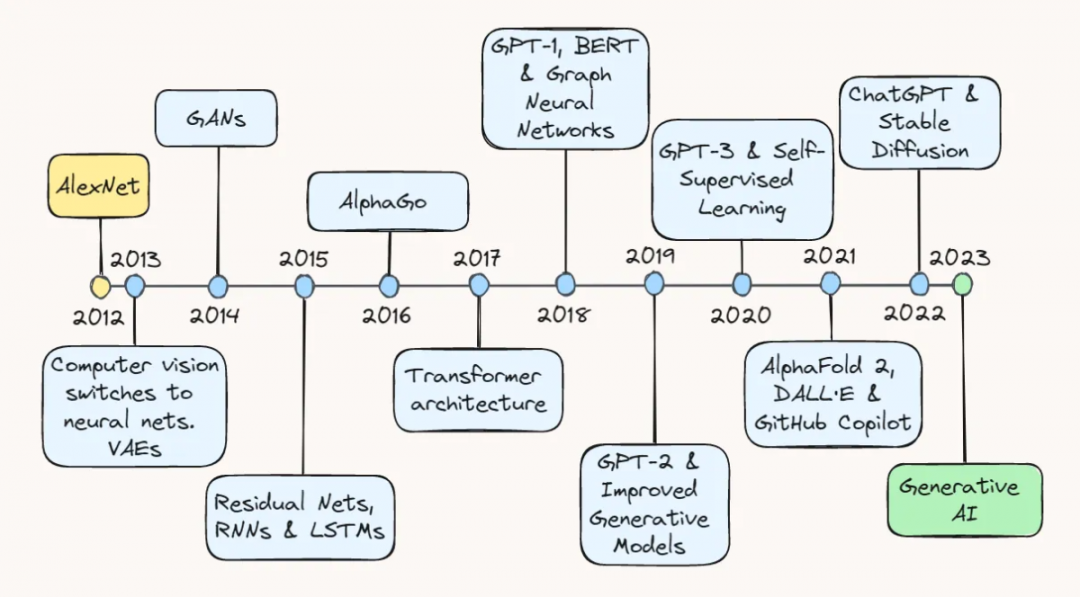
Image by the Author.
过去的十年对于人工智能领域来说是一个令人激动的阶段。从对深度学习潜力的初步探索到整个领域的爆炸性发展,如今该领域的应用已经包括电子商务的推荐系统、自动驾驶汽车的物体检测以及生成式模型(创建逼真的图像和连贯的文本等)等内容。
在这篇文章中,我们将漫步在记忆的长河中,重温让我们走到今天的一些关键性技术突破。 无论您是资深的人工智能从业者还是仅仅对该领域的最新发展感兴趣,本文都将为您全面介绍那些促使人工智能(AI)成为家喻户晓的词语的技术进展。
01 2013年:AlexNet与变分自编码器
2013年被大家认为是深度学习走向成熟的一年,这源于计算机视觉领域出现的重大进步。根据杰弗里·辛顿(Geoffrey Hinton)最近的一次采访[1],到了2013年, “几乎所有的计算机视觉研究都已经转向神经网络” 。这股热潮主要是由一年前(2012年)图像识别领域一个相当令人惊讶的突破所推动的。
在2012年9月,一种深度卷积神经网络(CNN)AlexNet[2]在ImageNet大规模视觉识别竞赛(ILSVRC)中取得了破纪录的成绩,证明了深度学习在图像识别任务中的潜力。它的Top-5 错误率[3]为15.3%,比其最接近的竞争对手低10.9%。
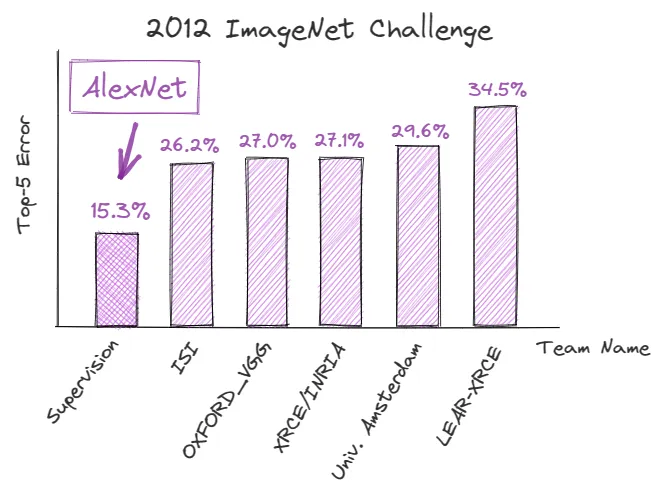
Image by the Author.
这一成功背后的技术改进极大地促进了人工智能的发展,并且极大地改变了人们对深度学习的看法。
首先,AlexNET的作者采用了一个由五个卷积层(convolutional layers)和三个全连接线性层(fully-connected linear layers)组成的deep CNN——该网络架构当时被许多人认为是不实用的。此外,由于网络的深度产生了大量参数,训练是在两个图形处理单元(GPUs)上并行进行的,证明了在大型数据集上进行快速训练的能力。通过使用更高效的修正线性单元(Rectified Linear Unit,ReLU)[4],传统的激活函数(如sigmoid和tanh)被替换,更进一步缩短了训练时间。
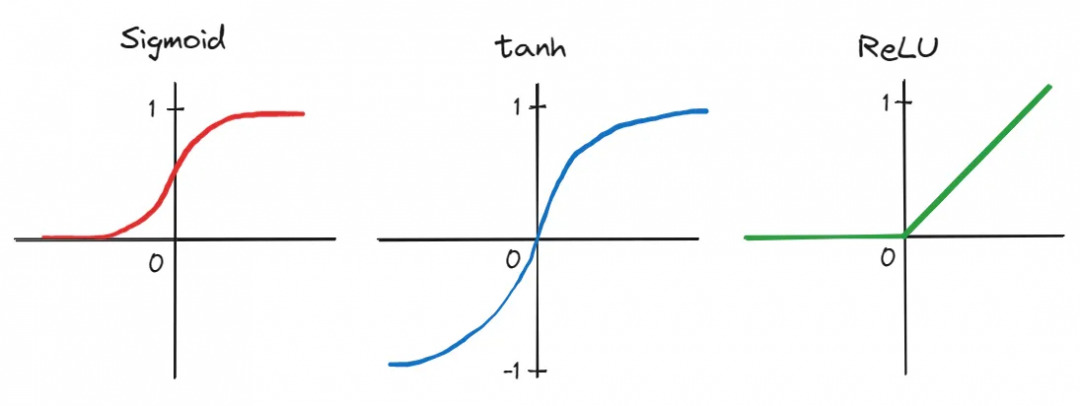
Image by the Author.
这些技术进展共同推动了AlexNet的成功,使其成为人工智能历史上的一个转折点,并引发学术界和科技界对深度学习的兴趣激增。因此,许多人认为2013年是深度学习真正开始起飞的一座分水岭。
同样也发生在2013年的(尽管有点被AlexNet的浩大声势所掩盖)是变分自编码器(或被称为VAEs[5])的发展——生成式模型可以学习表达(represent)和生成数据(如图像和声音)。它们通过学习输入数据在低维空间(称为隐空间(latent space))的压缩表示来工作。这使它们能够通过从已学习的隐空间中进行采样生成新的数据。后来,VAEs被认为开辟了新的生成模型(generative modeling)和数据生成途径,并在艺术、设计和游戏等领域得到应用。
02 2014年:生成式对抗网络
这之后第二年,即2014年6月,Ian Goodfellow及其同事提出了生成式对抗网络(GANs)[6],这是深度学习领域又一个重大的进展。
GANs是一种神经网络,能够生成与训练集相似的新数据样本。本质上是同时训练两个网络:(1)有一个生成器网络生成虚假的或合成的样本,(2)另一个鉴别器网络评估它们的真实性。这种训练是在一种类似于游戏的设定中进行的,生成器试图创造能够欺骗鉴别器的样本,而鉴别器则试图正确地识别出虚假的样本。
在当时,GANs代表一种强大而新颖的数据生成工具,不仅可用于生成图像和视频,还可用于音乐和艺术领域。GANs展示了在不依赖于显式标签(explicit labels)的情况下生成高质量数据样本的可能性,这一可能性为无监督学习的进展做出了较大的贡献,而之前这个领域被广泛认为是相对欠发展且具有挑战性的。
03 2015年:ResNets和NLP领域的突破性进展
2015年,人工智能领域在计算机视觉和自然语言处理(NLP)方面都取得了相当大的进展。
Kaiming He及其同事发表了一篇名为 《Deep Residual Learning for Image Recognition》 的论文[7],提出了残差神经网络(ResNets) 的概念。此架构通过添加捷径使信息更容易地在网络中流动。与常规神经网络每一层将上一层的输出作为输入不同,在ResNet中,会添加额外的残差连接(residual connections),跳过一层或多层并直接连接到网络中更深的层。
因此,ResNets能够解决梯度消失(vanishing gradients) [8]问题,从而使训练更深的神经网络成为可能。如此又导致处理图像分类和物体识别任务的显著进步。
大约在同一时间,研究人员在循环神经网络(RNNs) [9]和长短期记忆(LSTM) [10]模型的开发方面也取得了相当大的进展。尽管这些模型自20世纪90年代以来就已经存在,但是它们直到2015年左右才开始引起一定的关注,主要是由于以下因素:
(1)2015年时可用于训练的数据集更大、更多样化;
(2)计算能力和硬件的改进,可训练更深层次、更复杂的模型;
(3)从这些模型出现到2015年的这段时间中所进行的模型改进,如更复杂的门控机制(gating mechanisms)。
因此,这些架构使语言模型能够更好地理解文本的语境和含义,从而在语言翻译、文本生成和情感分析等任务中得到了极大的改进。当时RNNs和LSTMs的成功为我们今天所见到的大语言模型(LLMs)的开发铺平了道路。
04 2016年:AlphaGo
1997年,加里·卡斯帕罗夫(Garry Kasparov)被IBM的深蓝(Deep Blue)打败之后,人类和机器之间的另一场比赛于2016年掀起了轩然大波:谷歌的AlphaGo击败了围棋世界冠军李世石。

Photo by Elena Popova on Unsplash.
李世石的失败标志着人工智能发展历程上的又一个重要里程碑:它表明,在曾被认为太复杂而不可能被计算机处理的游戏中,机器甚至可以击败最熟练的人类选手。AlphaGo使用深度强化学习(deep reinforcement learning) [11]和蒙特卡罗树搜索(Monte Carlo tree search) [12]的组合,分析以前游戏中的数百万个位置,并评估了可能的最佳落子位置——此策略在这种情况下远远超越了人类的决策能力。
05 2017年:Transformer架构和语言模型
可以说,2017年是为我们今天所见到的生成式人工智能取得突破性进展奠定基础的最关键的一年。
在2017年12月,Vaswani及其同事发布了名为《Attention is all you need》的基础论文[13],介绍了使用自注意力(self-attention) [14]概念来处理顺序输入数据的Transformer架构。这使得long-range dependencies的处理更加高效,而此前传统的循环神经网络结构对此仍是一个挑战。

Photo by Jeffery Ho on Unsplash.
Transformer由两个重要组件组成:编码器和解码器。编码器负责对输入数据进行编码,可以是一个单词序列。然后,它接受输入序列并应用多层自注意力(self-attention)和前馈神经网络(feed-forward neural nets)来捕捉句子内存在的关系和特征,并学习有意义的表达。
从本质上讲,自注意力使模型能够理解句子中不同单词之间的关系。与传统模型不同,传统模型会按固定顺序处理单词,而transformer实际上同时考虑所有单词。根据单词与句子中其他单词的相关性,它们为每个单词分配一种称为attention scores的指标。
另一方面,解码器将编码器的编码后的表达作为输入,并生成输出序列。在机器翻译或文本生成等任务中,解码器根据从编码器接收到的输入生成翻译序列。与编码器类似,解码器也包括多层自注意力和前馈神经网络。但是,它还包括一个额外的注意力机制,使其能够集中关注编码器的输出。这样,解码器就可以在生成输出时考虑到来自输入序列的相关信息。
自从Transformer架构问世以来,其已成为LLM开发的关键组件,并在NLP领域,如机器翻译、语言建模和问题回答等方面取得了突破性的进展。
06 2018年:GPT-1、BERT和图神经网络
在Vaswani等人发表他们的论文几个月后,OpenAI于2018年6月推出了生成预训练Transformer(即GPT-1)[15],它利用Transformer架构有效地捕捉文本中的long-range dependencies。GPT-1是首批进行无监督预训练后,展示针对特定NLP任务进行微调相关效果的模型之一。
此外,谷歌也利用当时还很新颖的Transformer架构,在2018年底发布并开源了他们自己的预训练方法,称为Bidirectional Encoder Representations from Transformers,即BERT[16]。与以前以单向方式处理文本的模型(包括GPT-1)不同,BERT同时考虑了每个词在两个方向的上下文。 为了说明这一点,作者提供了一个非常直观的例子:
……在“我访问银行账户”这个句子中,单向上下文模型(unidirectional contextual model)将基于“我访问”而非“账户”来表示“银行”。然而,BERT使用其前后上下文——“我访问……账户”——表示“银行”。从深度神经网络的最底层开始,使其实现了深层次双向(deeply bidirectional)。
双向性(bidirectionality)非常强大,使BERT在各种基准任务上优于当时的NLP系统。
除了GPT-1和BERT之外,图神经网络(graph neural networks, GNN) [17]在那一年也引起了一些轰动。它们属于一类专门设计用于图形数据的神经网络。GNN利用一种消息传递算法在图的节点和边上传播信息。这使得网络可以以更直观的方式学习数据的结构和关系。
这项工作使得研究人员能够从数据中提取更深入的信息,从而扩大了深度学习可应用的范围。有了GNN,AI在社交网络分析、推荐系统和药物研究等领域取得重大进展。
07 2019年:GPT-2和改进的生成模型
2019年,生成模型拥有了一些重要进展,特别是GPT-2[18]的推出。该模型在许多NLP任务中拥有最先进的性能,真正让同类模型相形见绌,并且还能够生成高度逼真的文本内容。现在看来,这为我们预告了即将在这个领域发生的“大爆炸”。
当年,该领域中的其他进展包括DeepMind的BigGAN[19],它生成的高质量图像与真实图像几乎没有区别,以及NVIDIA的StyleGAN[20],可以更好地控制这些生成图像的外观。
总的来说,这些现在被称为生成式AI的进展将人工智能领域的界限推得更远,而且…
08 2020年:GPT-3和自监督学习
……不久之后,另一个模型问世,一个即使在技术领域之外也家喻户晓的名字:GPT-3[21]。这个模型代表了LLMs规模和能力的极大提升。GPT-1只有117万个参数,而GPT-2则增加到了15亿个,GPT-3则达到了1750亿个。
如此巨大的参数使得GPT-3能够在各种Prompt和任务中生成非常连贯的文本,在文本补全、问答甚至是创意写作等NLP任务的完成上也展现了万众瞩目的性能和卓越表现。
此外,GPT-3再次突显了使用自监督学习(self-supervised learning) 的潜力,这种方式使得模型可以在大量未标记的数据上进行训练。自监督学习的好处是,模型可以获得对语言的普遍理解,而不需要进行大范围的特定任务训练,这使得其更加经济实惠。
Yann LeCun在推特上发表了一篇关于自监督学习的纽约时报文章
09 2021年:AlphaFold 2、DALL-E和GitHub Copilot
从蛋白质折叠到图像生成,再到自动化编码助手,得益于AlphaFold 2、DALL·E和GitHub Copilot的发布,2021年是充满惊喜的一年。
AlphaFold 2[22]是一种用于解决数十年未被解决的蛋白质折叠问题的解决方案。DeepMind的研究人员扩展了Transformer架构,创建了evoformer(这是一种借助进化策略进行模型优化的结构)来构建一个能够根据一维氨基酸序列预测蛋白质三维结构的模型。这一突破具有巨大的潜力,可以彻底改变药物研发、生物工程以及我们对生物系统的理解等方面。
OpenAI在这一年也再次成为新闻的焦点,他们发布了DALL·E[23]。从本质上讲,这个模型将GPT-style的语言模型和图像生成的概念结合起来,使得可以通过文本描述创建高质量的图像。
为了证明这个模型的强大功能,请看下面这张图片,它是根据Prompt “Oil painting of a futuristic world with flying cars“生成的。

Image produced by DALL·E.
最后,GitHub发布了Copilot[24]。这是Github与OpenAI合作实现的,OpenAI提供了底层语言模型Codex,该模型使用大量公开可用的代码进行训练,并学会了理解和生成各种编程语言的代码。开发者可以通过简单地提供一段代码注释,并说明他们正在尝试解决的问题,模型就会编写代码来实现解决方案。还有其他功能,包括用自然语言描述输入的代码以及在各种编程语言之间转换代码。
10 2022年:ChatGPT 和 Stable Diffusion
过去十年间,人工智能的快速发展在一项突破性的进展中达到了顶峰:OpenAI在2022年11月发布了ChatGPT[25]。该工具被认为代表自然语言处理领域的顶级成就,针对各种查询和Prompt能够生成连贯且符合上下文的回答。此外,它可以进行对话、提供问题解释、提供创意建议、协助解决问题、编写和解释代码,甚至可以模拟不同的人物个性或写作风格。

Image by the Author.
人们可以在简单而直观的界面与机器人进行互动也刺激了可用性(usability)的急剧上升。以前,主要是技术界会琢磨最新的基于人工智能的新技术。然而现在,AI工具已经渗透到几乎所有专业领域,从软件工程师到作家、音乐家和广告商。许多公司也在使用这种模型来实现服务自动化(automate services),如客户支持、语言翻译或回答常见问题。事实上,我们现在正看到的自动化浪潮(the wave of automation) 已经重新引起了一些担忧,并引发了对自动化有关风险的讨论。
虽然2022年ChatGPT获得了很多关注,但图像生成方面也有了重大的进展。Stability AI发布了Stable diffusion[26],一种潜在的文转图扩散模型,能够通过文本描述生成逼真的照片。
Stable diffusion是传统扩散模型的延伸,它迭代地向图像添加噪声,然后逆转过程来恢复数据。它被设计成不直接在输入图像上操作,而是在它们的低维表示或隐空间(latent space)上操作,从而加速这一过程。 此外,扩散过程是通过向网络添加来自用户的transformer-embedded text prompt来修改的,从而使其在每次迭代中引导图像生成过程。
总的来说,2022年发布的ChatGPT和Stable diffusion突显了多模态、生成式AI的潜力,并引发了对该领域进一步发展和投资的推动。
11 2023年:LLMs和Bots
今年无疑是LLMs和chatbots大展身手的一年。越来越多的大模型正以迅猛的速度问世和迭代。
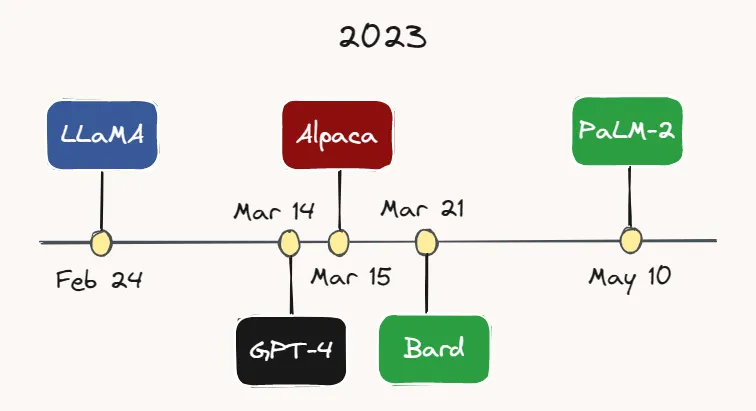
Image by the Author.
例如,Meta AI在2月24日发布了LLaMA[27]——一个性能比GPT-3更好的LLM,而且参数数量要少得多。不到一个月后,在3月14日,OpenAI发布了GPT-4[28]——GPT-3的一个更大、能力更强和多模态的版本。虽然GPT-4的确切参数数量不详,但据推测可能达到数万亿。
3月15日,斯坦福大学的研究人员发布了Alpaca[29],这是一种轻量级的语言模型,基于LLaMA通过指令跟随演示(译者注:这是一种通过让模型观察人类执行某项任务的过程,来进行模型微调的方法)进行了微调。几天后,在3月21日,谷歌推出了其ChatGPT竞品:Bard[30]。谷歌也刚刚在本月初的5月10日发布了其最新的LLM——PaLM-2[31]。根据这个发展速度,很有可能到您阅读本文的时候,又会涌现出另一个新的模型。
我们也看到越来越多的公司将这些模型整合到他们的产品中。例如,Duolingo宣布推出基于GPT-4的Duolingo Max[32],这是一个新的订阅服务,旨在针对每个个体提供量身定制的语言课程。Slack也推出了一个名为Slack GPT[33]的人工智能助手,可以完成诸如起草回复和总结会话等任务。此外,Shopify还在其商店应用程序中引入了ChatGPT-powered助手,可以通过各种Prompt帮助客户识别所需的产品。
Shopify在Twitter上宣布其ChatGPT-powered AI助手
有趣的是,如今人工智能聊天机器人(AI chatbots)甚至被视为人类心理治疗师(human therapists)的替代品。例如,美国chatbot应用程序Replika[34]为用户提供一个“关心你的AI伴侣,始终倾听和与你交谈,始终在你身边”。其创始人Eugenia Kuyda表示,该应用程序的客户范围非常之广,从寻求“与人交往之前热身”的自闭症儿童到仅需要一个朋友的孤独成年人都有。
最后,我想强调一下上一个十年中AI发展的高潮:人们使用Bing!今年早些时候,微软推出了基于GPT-4的“copilot for the web”[35],它是为搜索而定制的,这么长时间以来,它首次成为谷歌在搜索业务上需要认真对待的竞争对手。
12 回顾过去&展望未来
当我们回顾过去十年的AI发展历程时,很明显,我们一直在见证一场变革,对我们的工作方式、商业运作模型和人际互动行为产生了深远的影响。最近生成式模型(generative models)方面取得了重大进展,特别是LLMs。生成式模型的发展似乎在坚持一个共同的信念,即“越大越好”,当然这里指的是模型内部包含的可调整参数的总数(the parameter space of the models)。 这在GPT系列中尤为明显,该系列从117万个参数(GPT-1)开始,接下来每个版本的模型增加约一个数量级,最终达到了可能拥有数万亿个参数的GPT-4。
然而,在最近一次采访中[36],OpenAI首席执行官Sam Altman认为我们已经到达了参数“越大越好”时代的尽头。展望未来,他仍然认为参数数量会呈上升趋势,但未来模型改进的主要重点将放在增加模型的功能、效用和安全性上。
最后一点尤为重要。这些强大的AI工具现在已经掌握在大众手中,不再局限于研究实验室的受控环境中,我们现在比以往任何时候都更需要谨慎行事,确保这些工具是安全的,符合人类的最佳利益。希望我们能看到AI安全方面像其他领域一样得到同样的发展和投资。
END
参考资料
1.https://venturebeat.com/ai/10-years-on-ai-pioneers-hinton-lecun-li-say-deep-learning-revolution-will-continue/
2.https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
3.https://machinelearning.wtf/terms/top-5-error-rate/
4.https://www.cs.toronto.edu/~fritz/absps/reluICML.pdf
5.https://arxiv.org/abs/1312.6114
6.https://proceedings.neurips.cc/paper_files/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
7.https://arxiv.org/abs/1512.03385
8.https://en.wikipedia.org/wiki/Vanishing_gradient_problem
9.https://en.wikipedia.org/wiki/Recurrent_neural_network
10.https://pubmed.ncbi.nlm.nih.gov/9377276/
11.https://en.wikipedia.org/wiki/Deep_reinforcement_learning
12.https://en.wikipedia.org/wiki/Monte_Carlo_tree_search
13.https://arxiv.org/abs/1706.03762
14.https://en.wikipedia.org/wiki/Attention_(machine_learning)
15.https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
16.https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
17.https://en.wikipedia.org/wiki/Graph_neural_network
18.https://openai.com/research/gpt-2-1-5b-release
19.https://www.deepmind.com/open-source/big-gan
20.https://github.com/NVlabs/stylegan
21.https://arxiv.org/abs/2005.14165
22.https://www.nature.com/articles/s41586-021-03819-2
23.https://openai.com/dall-e-2/
24.https://github.com/features/copilot
25.https://openai.com/blog/chatgpt
26.https://stability.ai/blog/stable-diffusion-public-release
27.https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
28.https://openai.com/product/gpt-4
29.https://crfm.stanford.edu/2023/03/13/alpaca.html
30.https://blog.google/technology/ai/bard-google-ai-search-updates/
31.https://ai.google/discover/palm2
32.https://blog.duolingo.com/duolingo-max/
33.https://slack.com/blog/news/introducing-slack-gpt
34.https://replika.com/
35.https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/
36.https://techcrunch.com/2023/04/14/sam-altman-size-of-llms-wont-matter-as-much-moving-forward/?guccounter=1&guce_referrer=aHR0cHM6Ly93d3cuZ29vZ2xlLmNvbS8&guce_referrer_sig=AQAAAANxF1G0qEgpUn-9mD7CxuZrc77IDr8t-QvyX3Do6Koa10eGy5DYiq3lzXDAJRakptl0Jy49OkuxXU8zD-3-8l-h3YJxFgKRwk5HqIHdhG2BIXavq5Tfn1HHz6IKk8-y86xZbyHXZJwE_Q_OFXr4nrHygrl48-WxX7vdgTft_lhw
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://towardsdatascience.com/ten-years-of-ai-in-review-85decdb2a540

