
- 1mac虚拟机crossover 23.6破解版带来全新功能_crossover crack
- 2贝叶斯网络_贝叶斯网络因果方向
- 3《大数据系统与编程》常用的HBase操作实验报告_hbase数据库:hbase表设计和操作实验报告
- 4CrossOver (Mac安装Windows应用) v23.7中文激活版2024最新图文安装教程_crossover23.7安装包
- 5module ‘numpy‘ has no attribute_module 'numpy' has no attribute 'typedict
- 6动态规划算法_)动态规划(dynamic programming)算法的核心思想是:将大问题划分为小问题进行
- 7Redis数据类型及常用命令_了解redis存储的基本类型和使用命令
- 8rebasing状态、找回commit时候的代码
- 9PGD_Towards deep learning models resistant to adversarial attacks_CSDN
- 10MacBook(m1)配置Python注意事项(自用,持续更新)_m1安装sklearn
总结:机器学习之DBSCAN
赞
踩
一、基本思想
DBSCAN是一种基于密度的聚类算法,这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间的紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。
通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。
二、DBSCAN密度定义
在上一节我们定性描述了密度聚类的基本思想,本节我们就看看DBSCAN是如何描述密度聚类的。DBSCAN是基于一组邻域来描述样本集的紧密程度的,参数(ϵ, MinPts)用来描述邻域的样本分布紧密程度。
其中,ϵ描述了某一样本的邻域距离阈值,MinPts描述了某一样本的距离为ϵ的邻域中样本个数的阈值。
假设我的样本集是D=(x1,x2,...,xm),则DBSCAN具体的密度描述定义如下:
1)ϵ-邻域:表示的是D样本集中,距离xj的距离小于∈的区域,称为ϵ-邻域。在这个区域内的点的个数记为|Nϵ(xj)|。
注意:1、在代码实践的时候,距离需要业务自己定义。2、ϵ-邻域数量要不低于2,否则就无法将密度相连的那些点合并到一个簇了,也就失去了DBSCAN原有的意义。
2) 核心对象:对于任一样本xj∈D,如果其ϵ-邻域对应的Nϵ(xj)至少包含MinPts个样本,即如果|Nϵ(xj)|≥MinPts,则xj是核心对象。 大白话就是,称为核心对象的前提是这个点周边有比较多的离得近的点。
3)密度直达( 或直接密度可达 ):如果xi位于xj的ϵ-邻域中,且xj是核心对象,则称xi由xj密度直达。注意反之不一定成立,即此时不能说xj由xi密度直达, 除非且xi也是核心对象。
4)密度可达:从核心对象O1到对象On(这里同样不要求On是核心对象)是密度可达的,如果存在一组对象链{O1,O2,…,On},其中Oi到Oi+1都是关于(ϵ,MinPts)直接密度可达的。实际上,从这个定义我们不难看出,{O1,O2,…,On−1}都必须是核心对象。
5)密度相连:两个对象O1,O2(注意,这里不要求是核心对象)是密度相连的,如果存在一个对象p,使得p到O1,pp到O2都是密度可达的。这个定义是对称的,即O1与O2是密度相连的,则O2与O1也是密度相连的。
从下图可以很容易看出理解上述定义,图中MinPts=5,红色的点都是核心对象,因为其ϵ-邻域至少有5个样本。黑色的样本是非核心对象。
所有核心对象密度直达的样本在以红色核心对象为中心的超球体内,如果不在超球体内,则不能密度直达。
图中用绿色箭头连起来的核心对象组成了密度可达的样本序列。在这些密度可达的样本序列的ϵϵ-邻域内所有的样本相互都是密度相连的。
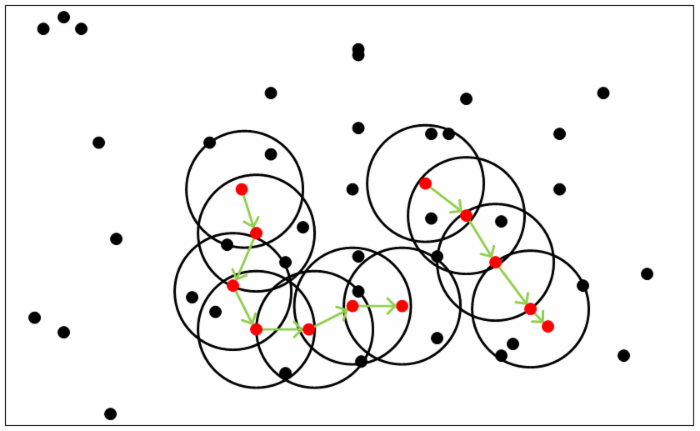
有了上述定义,DBSCAN的聚类定义就简单了。
三、DBSCAN密度聚类思想
DBSCAN的聚类定义很简单:由密度可达关系导出的最大密度相连的样本集合,即为我们最终聚类的一个类别,或者说一个簇。
这个DBSCAN的簇里面可以有一个或者多个核心对象。如果只有一个核心对象,则簇里其他的非核心对象样本都在这个核心对象的ϵϵ-邻域里;如果有多个核心对象,则簇里的任意一个核心对象的ϵϵ-邻域中一定有一个其他的核心对象,否则这两个核心对象无法密度可达。这些核心对象的ϵϵ-邻域里所有的样本的集合组成的一个DBSCAN聚类簇。
那么怎么才能找到这样的簇样本集合呢?DBSCAN使用的方法很简单,它任意选择一个没有类别的核心对象作为种子,然后找到所有这个核心对象能够密度可达的样本集合,即为一个聚类簇。接着继续选择另一个没有类别的核心对象去寻找密度可达的样本集合,这样就得到另一个聚类簇。一直运行到所有核心对象都有类别为止。
基本上这就是DBSCAN算法的主要内容了,是不是很简单?但是我们还是有三个问题没有考虑。
第一个是一些异常样本点或者说少量游离于簇外的样本点,这些点不在任何一个核心对象在周围,在DBSCAN中,我们一般将这些样本点标记为噪音点。
第二个是距离的度量问题,即如何计算某样本和核心对象样本的距离。在DBSCAN中,一般采用最近邻思想,采用某一种距离度量来衡量样本距离,比如欧式距离。这和KNN分类算法的最近邻思想完全相同。对应少量的样本,寻找最近邻可以直接去计算所有样本的距离,如果样本量较大,则一般采用KD树或者球树来快速的搜索最近邻。如果大家对于最近邻的思想,距离度量,KD树和球树不熟悉,建议参考之前写的另一篇文章K近邻法(KNN)原理小结。
第三种问题比较特殊,某些样本可能到两个核心对象的距离都小于ϵϵ,但是这两个核心对象由于不是密度直达,又不属于同一个聚类簇,那么如果界定这个样本的类别呢?一般来说,此时DBSCAN采用先来后到,先进行聚类的类别簇会标记这个样本为它的类别。也就是说DBSCAN的算法不是完全稳定的算法。
四、DBSCAN小结
和传统的K-Means算法相比,DBSCAN最大的不同就是不需要输入类别数k,当然它最大的优势是可以发现任意形状的聚类簇,而不是像K-Means,一般仅仅使用于凸的样本集聚类。同时它在聚类的同时还可以找出异常点,这点和BIRCH算法类似。
那么我们什么时候需要用DBSCAN来聚类呢?一般来说,如果数据集是稠密的,并且数据集不是凸的,那么用DBSCAN会比K-Means聚类效果好很多。如果数据集不是稠密的,则不推荐用DBSCAN来聚类。
下面对DBSCAN算法的优缺点做一个总结。
DBSCAN的主要优点有:
1) 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
2) 可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3) 聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
DBSCAN的主要缺点有:
1)如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
2) 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
3) 调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值ϵϵ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
参考:

