
热门标签
热门文章
- 1Nacos、EureKa、Consul、CoreDNS、Zookeeper注册中心对比_nacos eureka等注册中心的比较
- 2OceanBase v4.3 特性解析:列存储引擎,优化查询性能的新利器
- 3Postman基本使用、测试环境(Environment)配置_postman environment
- 4linux安装JDK
- 5【专题介绍】圆桌论坛——AI与音视频技术的融合之路
- 6差分隐私(一)概念&熵_瑞丽差分隐私
- 7基础算法之前缀和于差分_前缀和套差分
- 8如何查看端口号是否被占用_查看端口占用情况
- 9机器学习之Spark MLlib介绍_spark mllin
- 10一、python入门、python环境安装--附代码案例_代码安装python
当前位置: article > 正文
flink1.17.1安装记录_available task slots显示为0
作者:小丑西瓜9 | 2024-05-07 10:47:37
赞
踩
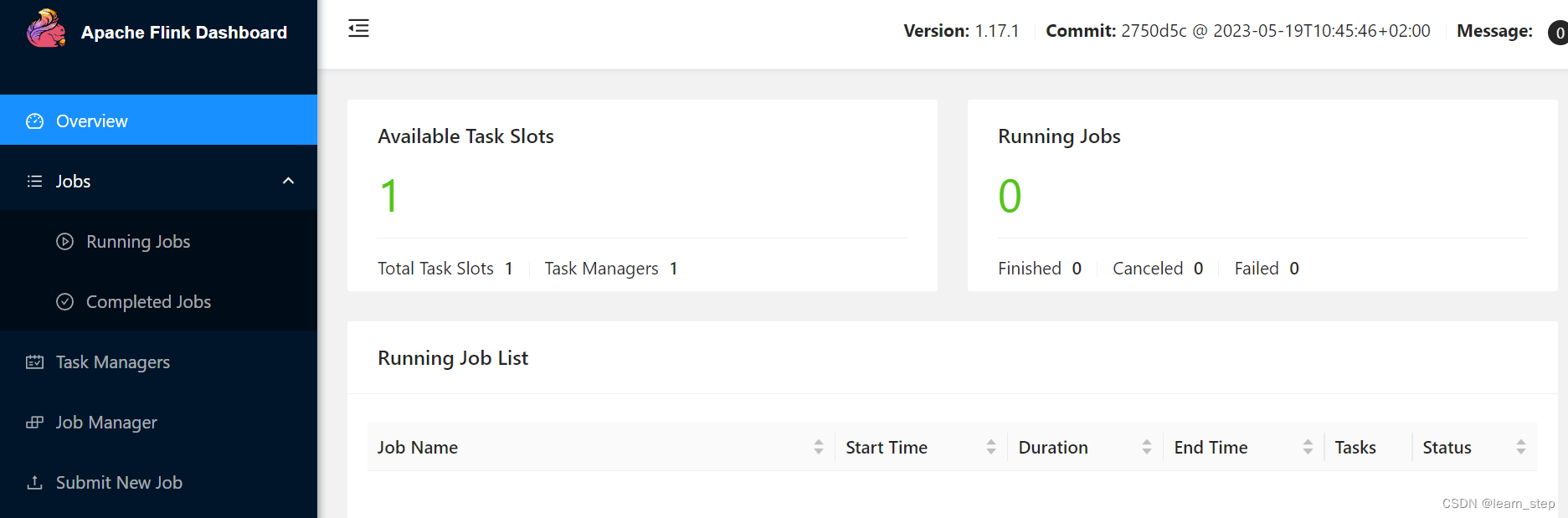
available task slots显示为0
1、下载并上传至虚拟机hadoop100
虚拟机有两台:hadoop100(主),hadoop101(从)
2、解压到安装目录,并修改主文件夹为flink
- tar zxvf /tempupload/flink-1.17.1-bin-scala_2.12.tgz -C /opt/module
- mv flink-1.17.1 flink
3、修改conf下的配置文件
flink-conf.yaml文件:
- jobmanager.rpc.address: localhost
-
- 改成自己的主机名
-
- jobmanager.rpc.address: hadoop100
(说明:jobmanager节点地址,也是master节点地址)
masters文件:
- localhost:8081
-
- 改成
-
- hadoop100:8081
works文件
- localhost
- 改成
- hadoop101
4、将hadoop100上的flink分发到节点hadoop101
scp -r flink hadoop101:/opt/module5、配置环境变量,修改/etc/profile
- #flink
- export FLINK_HOME=/opt/module/flink
- export PATH=$PATH:$FLINK_HOME/bin
- //使配置文件生效
- source /etc/profile
6、启动集群
start-cluster.sh7、本机浏览器访问
碰到的问题:
1、浏览器访问提示拒绝访问
处理:flink-conf.yaml修改rest.bind-address: 0.0.0.0。
参考:【linux 安装flink 防火墙关闭但无法访问web网页(8081)】-CSDN博客
2、Available Task Slots为0
处理:flink-conf.yaml修改jobmanager.bind-host: 0.0.0.0
参考:flink-standalone模式启动后Available Task Slots都显示0_@假装的博客-CSDN博客
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/548776
推荐阅读
相关标签

