
- 1hMailServer安装配置_hmailserver宝塔
- 2升级多款教育行业解决方案 星辰天合推动高校高质量发展
- 351单片机+ESP8266+Android APP实现局域网内控制LED灯_esp8266手机端app开发
- 4二叉树C语言基本定义+操作代码+注释详解(二叉树的递归/非递归遍历方法)_二叉树与递归c语言基础
- 5PHP EOF(heredoc) 使用说明
- 6五、汇总Linux系统中的权限管理_linux查看权限
- 7SQL的索引_sql索引
- 8使用Python Seaborn绘制热力图(heatmap)的时候怎么改变配色_python热力图颜色设置
- 9【OpenCv 4 Python 3.7】图像金字塔_prydown opencv
- 10微信小程序开屏_小程序投屏功能 csdn
spark概述和scala的安装部署_scala 集群安装
赞
踩
一:spark的特点
1.快速,逻辑回归算法一般需要多次迭代
2.易用,spark支持使用Scala,python,Java,R等语言快速写应用
3.通用,spark可以与SQL语句,实时计算以及其他的分析计算进行良好的结合
4.随处运行。
5.代码简洁,支持Scala,python等语言
二:spark生态圈重要组件简要介绍。
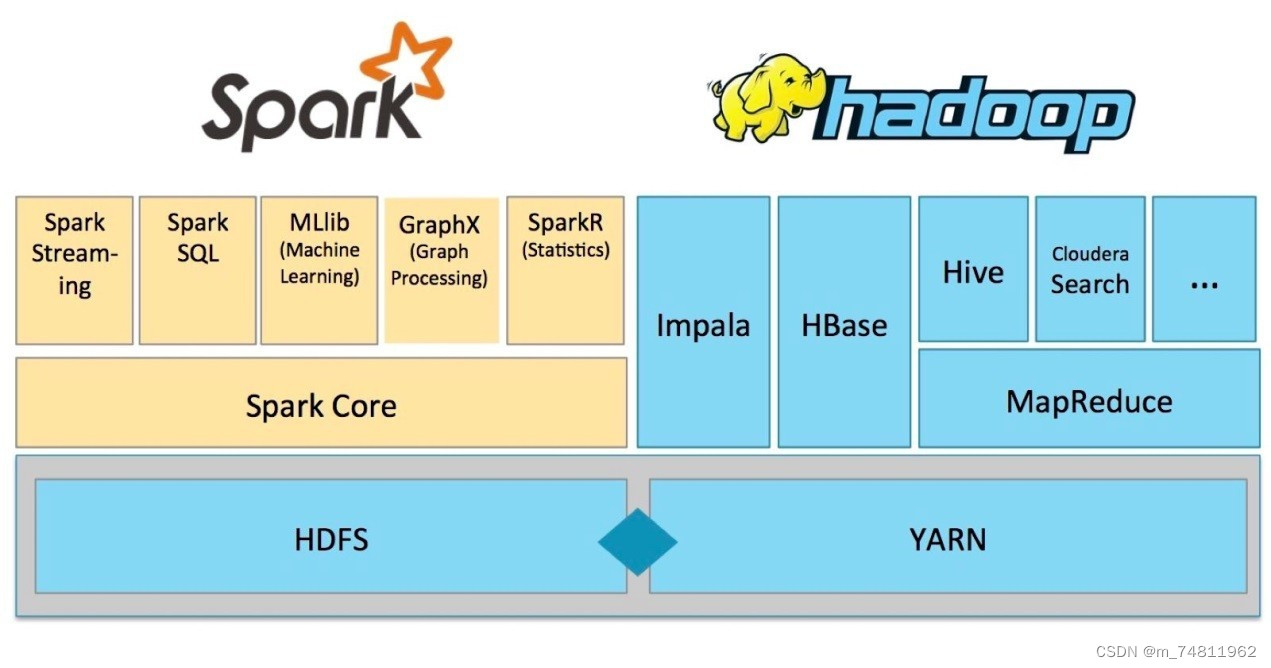
1,SparkCore:Spark的核心,提供底层框架及核心支持
2,BlinkDB:一个用于在海量数据进行交互式SQL查询的大规模并进行查询引擎,允许用户通过权衡利弊数据精度缩短查询响应时间,数据的精度将被控制在允许的误差范围内。
3,Spark SQL :可以执行SQL查询,支持基本的SQL语法和HIveQL语法,可读取的数据包括HIve,HDFS,关系型数据库
4,Spark Steaming:可以进行实时数据流式计算
5,MLBase:MLBase是spark生态圈的一部分,专注于机器学习,学习门槛较低。
6,GrapHx:图计算的应用在很多情况下处理的数据量都是很庞大的。
7,SparckR:SparckR是AMPLab发布的一个R语言开发包,使得R语言编写的程序不只是在单机上面运行,也可以作为Spark的作业运行在集群上,极大地提升了R语言的数据出来能力。
三:Spark的运行架构
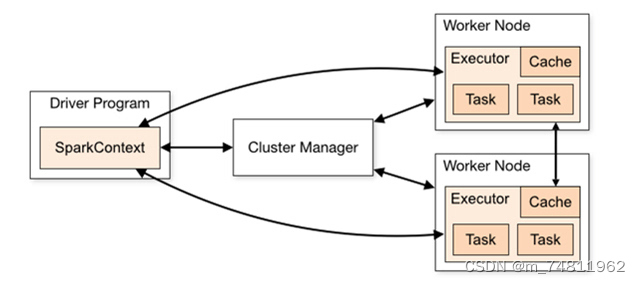
1,客户端:用户提交作业的客户端
2,Diver:负责运行应用程序的main函数并创建Spark Context,应用程序包含Diver功能的代码和发布在集群中多个节点上的Executor代码
3,SparkContext:应用上下文,控制整个生命周期。
4,Cluster Manager:资源管理器,在集群上面获取资源的外部服务,目前主要有Stand alone和YARN
5,SparkWorker:集群中可以运行应用程序的节点,运行一个或者多个Executor
6,Executor:运行在SparkWorker上的任务执行器,Executor启动线程池运行Task,并负责将数据存在内存或者磁盘上,每个应用程序都会申请各自的Executor以处理任务
7,Task:被发送到某个Executor的具体任务
四:安装好Scala
scala官网:The Scala Programming Language
五:安装好spark步骤
首先搜索spark官网:The Scala Programming Language

spark简介官网 Apache Spark™ - Unified Engine for large-scale data analytics
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
MapReduce和Spark的对比
1,内存计算
2,执行速度
3,API和编程模型
4,扩展性
5,容错性
注:Spark处理数据与MapReduce处理数据相比,有如下两个不同点:Spark处理数据时,可以将中间处理结果数据存储到内存中
Spark Job调度以DAG方式,并且每个任务Task执行以线程方式,并不是像MapReduce以进程方式执行。mapreduce里面的shuffle,是指对Map输出结果进行分区、排序、合并等处理并交给Reduce的过程
未完待续......


