
- 1【精】18款在线网页SVG编辑器_svg在线编辑器
- 2开源免费AI引擎:智能合同审查技术的应用与优势_合同风险ai审核
- 3DBeaver使用-Hive-Phoenix链接hbase-Doris_dbeaver连接doris
- 4Hive的安装部署_hive客户端部署
- 5前端 Code Review 指北
- 6【雷达原理】雷达信号级建模与仿真_lfmcw信号是什么
- 7如何在Python中使用ChatGPT API处理实时数据_github上python chatgpt
- 8历史记录_csdn的历史纪录在那里
- 9pytorch embedding层报错IndexError: index out of range in self
- 10R 安装 GitHub上的包_github上的boostedhp包
大数据毕业设计PyFlink+Hadoop+Hive民宿数据分析可视化大屏 民宿推荐系统 民宿爬虫 民宿大数据 知识图谱 机器学习 计算机毕业设计 深度学习 人工智能 Spark 预测算法_基于hive的民宿价格分析系统可视化
赞
踩
广东科技学院毕业设计(论文)开题报告
| 设计(论文)名称 | 民宿数据可视化分析系统的设计与实现 | |||||||||||||||||||||||||
| 设计(论文)类型 | C | 指导教师 | 朱富裕 | |||||||||||||||||||||||
| 学 院 | 专 业 | 数据科学与大数据技术 | ||||||||||||||||||||||||
| 姓 名 | 庄贵远 | 学 号 | 2020135232 | 班 级 | 20大数据本科2班 | |||||||||||||||||||||
(一)研究背景及意义 民宿起源于欧美乡村,而民宿在中国出现最早的是在台湾垦丁,并在台湾不断的发展兴盛,随着中国大陆经济以及旅游业的蓬勃发展,民宿的发展迅速[1]。随着民宿数量不断增加有些问题也随之而出,首先民宿行业准入机制不明确,导致一些不符合条件的机构或个人也进入民宿行业,他们往往缺乏专业的管理和运营能力,服务质量低下,用户体验差[2]。其次,民宿的监管机制不健全,导致一些民宿存在安全隐患、卫生问题、消防问题等,这些问题可能会对客人的生命财产安全造成威胁。此外,民宿的竞争激烈,一些民宿为了吸引客人,采用低价策略,导致整个行业的利润水平下降,这也会影响民宿的服务质量和用户体验[3]。 随着旅游业的快速发展和人们对于旅行体验的不断追求,民宿作为一种新的住宿选择方式,得到了越来越多人的喜爱。然而,随之而来的问题是如何更好地管理和分析民宿数据,提供相关的决策支持和可视化分析,以促进民宿行业的可持续发展,大数据技术的应用为民宿行业提供了更多的机会和挑战[4]。本研究旨在基于大数据技术设计并实现一个民宿数据可视化分析系统,以提供全面的数据分析和决策支持,让民宿的各个维度的数据指标更加全面生动的展示出来,帮助民宿经营者和旅游相关决策者更好地理解和分析民宿市场,提高民宿的运营效率和用户满意度。帮助消费者提前了解民宿的市场环境,对民宿的选择提供参考作用[5]。 (二)国内外研究现状 1、国外研究现状 国外民宿行业相较于中国起步较早,很早就进行民宿行业的研究。Jianzhuang等学者研究发现,民宿周围环境、经营者管理的情况和经营管理者与消费者之间的关系会影响消费者对民宿的选择倾向[6]。Dinesh等人用实验的方法探究房主特征对消费者信任的影响,发现房主的头像和声誉得分对消费者的选择倾向有显著影响,即会影响消费者是否选择体验其服务[7]。Adamia等人采用随机抽样的研究方法调查约翰内斯堡都市,以探究服务质量感知与客户期望之间的联系,其研究结果表明,为了提升服务质量,民宿经营者需在设施和环境管理上注重舒适性,并改变服务方式,这些举措不仅能够满足客户的期望,还能够提高客户对服务质量的感知[8]。 2、国内研究现状 在知网数据库中检索关键词“民宿”后利用知网的总体趋势分析功能得到自2014年后关于民宿的相关研究正在逐年线性递增。王春英和陈宏民将是否拥有厨房作为虚拟变量引入模型,得到厨房正向显著影响共享民宿的价格的结论,还提出地理位置因素影响房源定价[9]。张延宇通过文本分析和情感分析等技术探讨Airbnb网站评论信息中消费者的情感倾向,并利用多重线性回归的方法,分析了用户评论及房源的相关特征对共享民宿预订的影响[10]。王佳慧通过对大学生的旅游动机、旅游目的地的感知、旅游决策的分析,构建大学生旅游消费行为影响因素模型,最后得出月生活费是大学生旅游决策最大的影响因素[11]。 (三)参考文献 [1] 莫彩云. 阳朔民宿旅游发展调查研究[D].广西师范大学,2023.DOI:10.27036/d.XXXXXX.2023.001684. [2] 赵采云.北京市共享民宿销量的影响因素及空间格局差异性分析[D].东北财经大学,2023.DOl:10.27006/d.cnki.gdbcu.2022.000986. [3] 穆敏杰.SD民宿社交媒体营销策略研究[D]云南财经大学,2023.DOl:10.27455/d.cnki.gycm c.2023.001050. [4] 马妍.共享经济发展背景下民宿业发展对策研究[J].商业文化,2022(07):114-115. [5] 文君.基于大数据分析的高端民宿消费行为研究[D],郑州大学,2022.DOl:10.27466/d.cnki.g zzdu.2021.003666. [6] Jianzhuang Zheng,Lingyan Huang.Characterizing the Spatiotemporal Patterns and Key Determinantsof Homestay Industry Agglomeration in Rural China Using Multi Geospatial Datasets[J].Sustainability.2022,72(42). [7] Dinesh VALLABH.Profiling Tourists in the Bed and Breakfast Establishments in Port Alfred, Eastern Cape[J].Journal of Tourism Intelligence and Smartness,2019,1(1). [8] Adamiak,C.,2018,“Mapping Airbnb Supply in European Cities”,Annals of Tourism Research,Vol.71,PP67-71. [9] 王春英,陈宏民.共享短租平台住宿价格及其影响因素研究一基于小猪短租网站相关数据的分析[J].价格理论与实践,2018,(6):14-17. [10] 张延宇.共享经济背景下在线民宿预订评价影响因素分析[D].哈尔滨工业大学,2017. [11] 王佳慧.大学生旅游消费行为现状分析[D].河北经贸大学,2018. [12]张艳丽,吴淮北.Hive数据仓库在Hadoop大数据环境下数据的导入与应用[J].电脑编程技巧与维护,2022(12):97-99.DOI:10.16184/j.cnki.comprg.2022.12.006. [13] 赵海国.Ajax技术支持下的ECharts动态数据实时刷新技术的实现[J].电子技术,2018,47(03):25-27+57. | ||||||||||||||||||||||||||
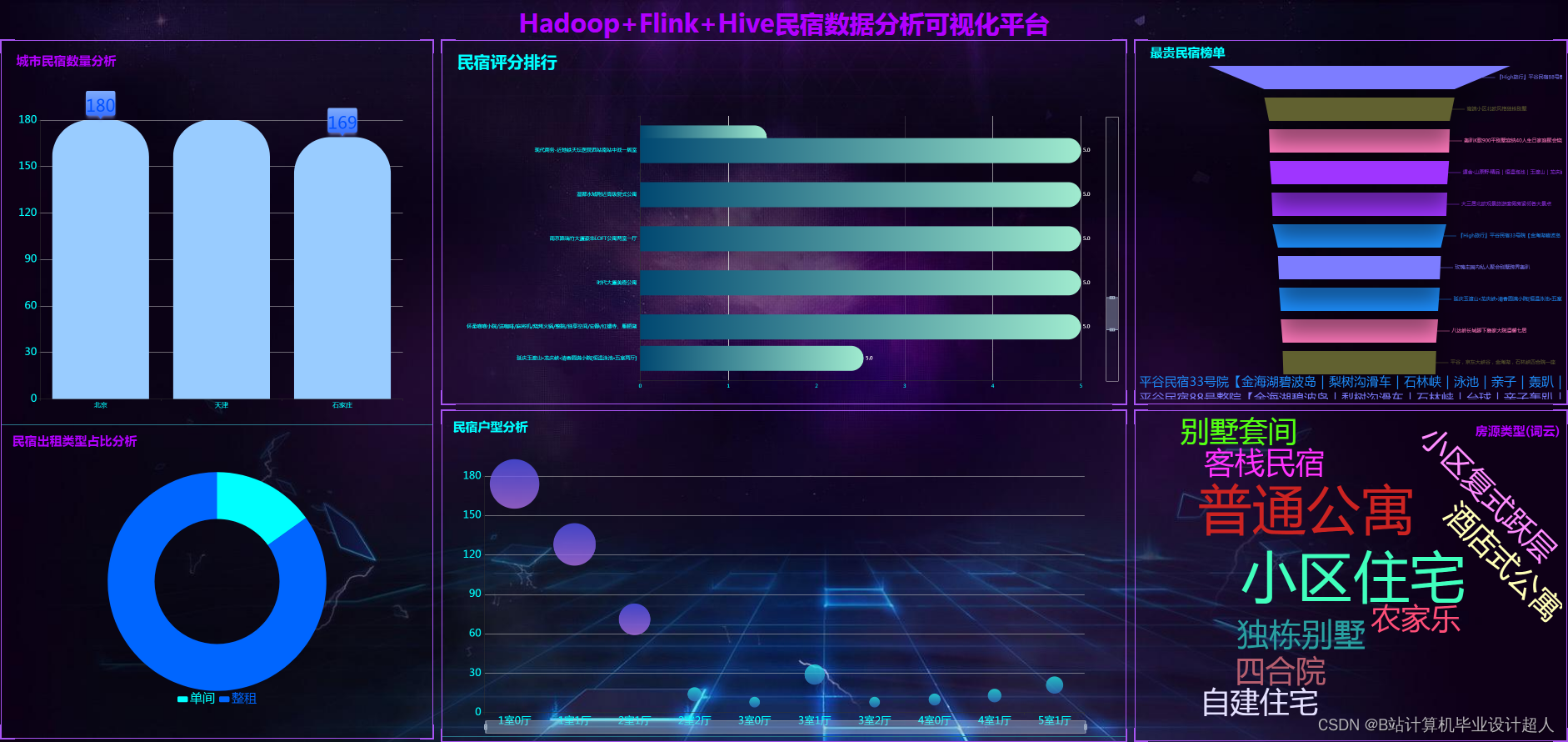
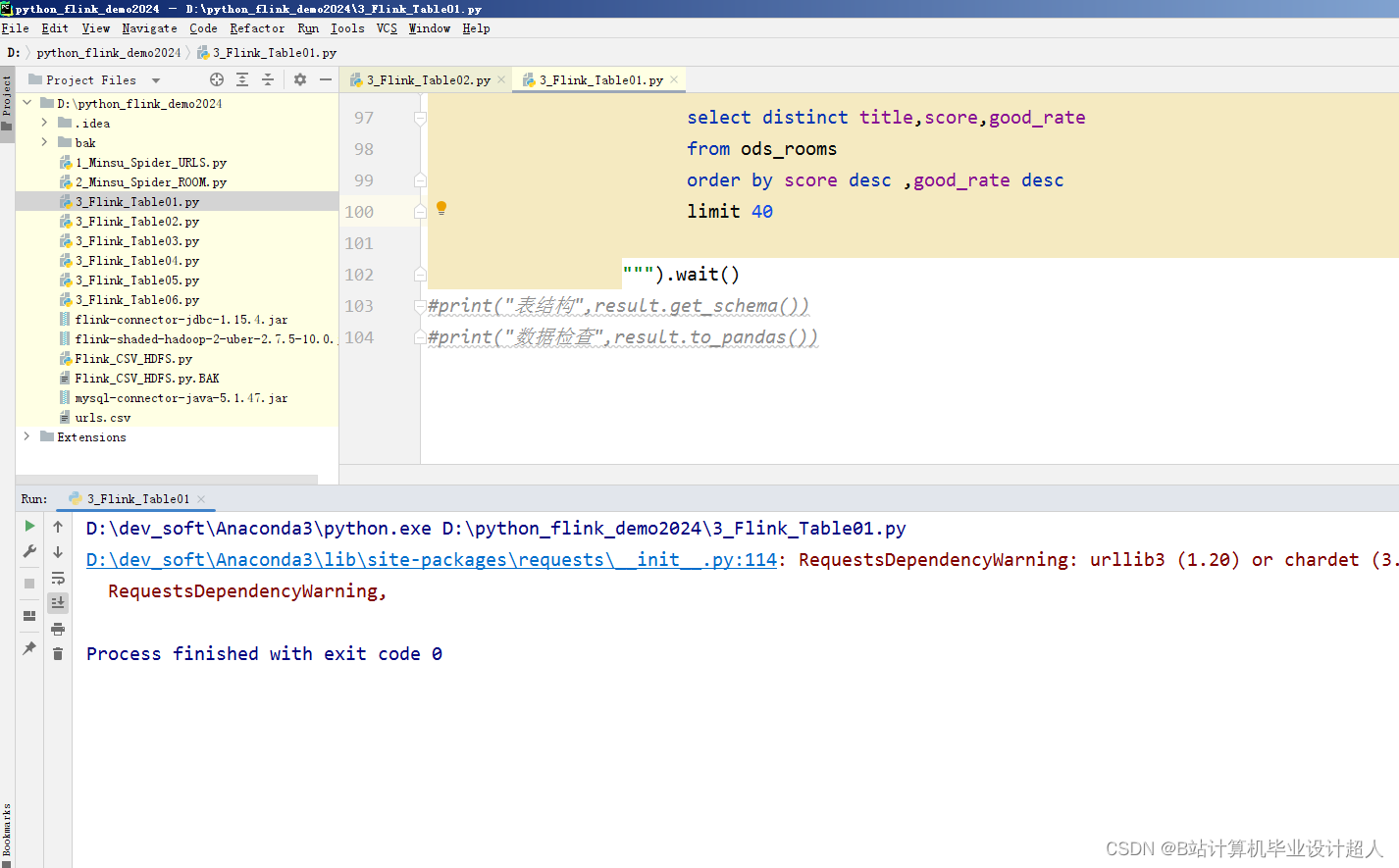
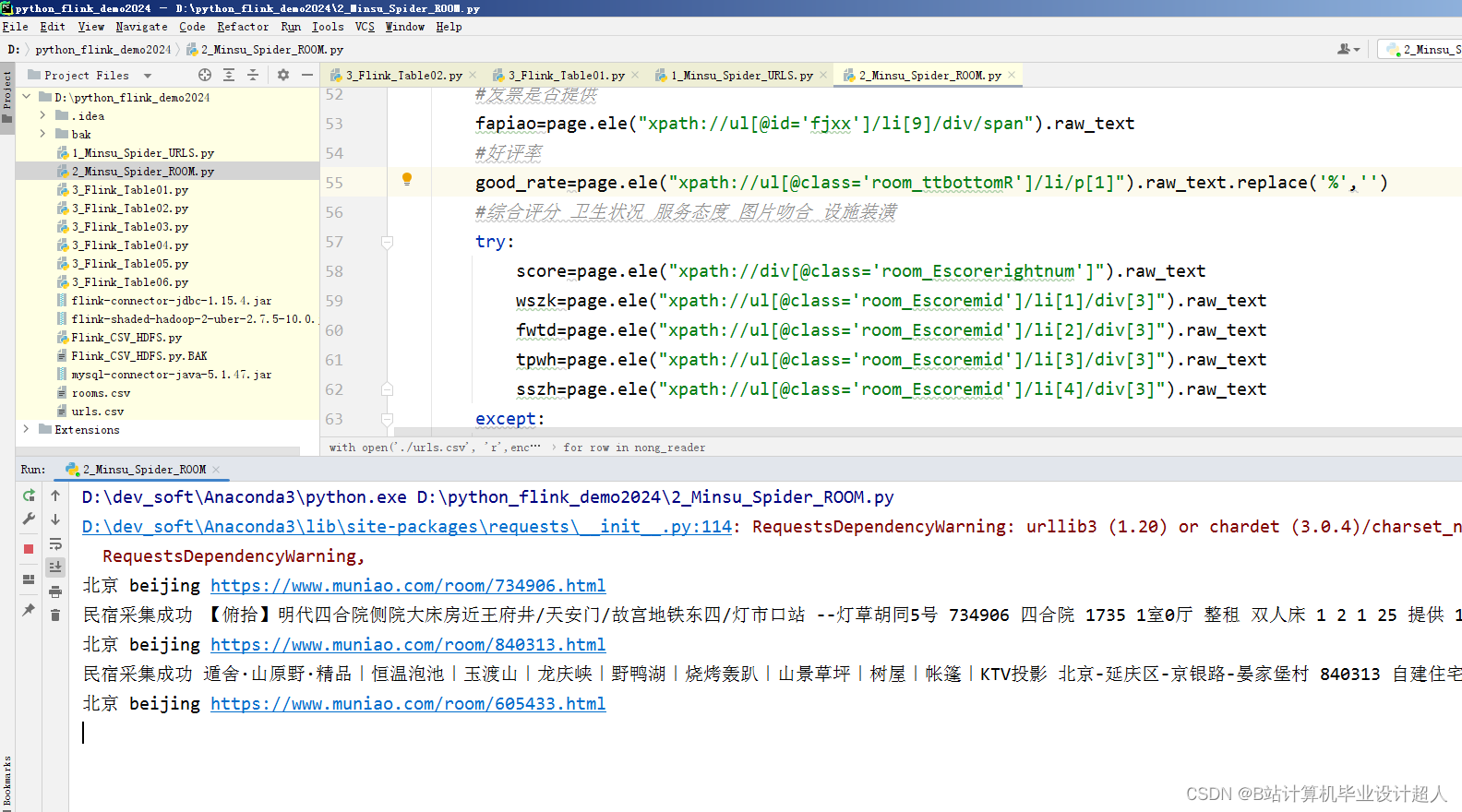
(一)研究内容 数据的分析展示使用ECharts图表库,根据需求设计各类图表,并提供交互式操作,使用户能够灵活地进行数据分析和展示[13]。首先利用Python编程语言,结合第三方爬虫Scrapy框架,编写爬虫程序,实现对民宿的民宿描述、位置、价格、面积、户数、类型、床数、宜住人数、评分、点评数等数据的定向抓取。获取数据后接下来进行数据的预处理操作,在Linux虚拟机上开启已经搭建好Hadoop集群的服务器并启动Hadoop集群,将爬取的数据以文件的形式上传至HDFS中,并编写MapReduce程序对爬取的数据实现数据清洗操作。接下来将已清洗的数据加载至Hive数据仓库中并使用Hive自带的类SQL语言对数据进行数据分析,例如描述性统计、区域对应民宿均价、区域对应民宿评分均值、区域对应民宿平均户数、用户评价关键词等词频统计等。最后引入ECharts图表库,使用HTML、CSS和JavaScript等前端技术,设计各类图表。该系统具有数据获取及时准确、存储高效、分析结果直观等特点,可为民宿行业决策者提供更准确的数据支持和分析结果。
实现用户登录功能模块的设计,用户需要使用正确的账户密码才能登录到系统中,主要功能为用户的注册、登录、修改密码。
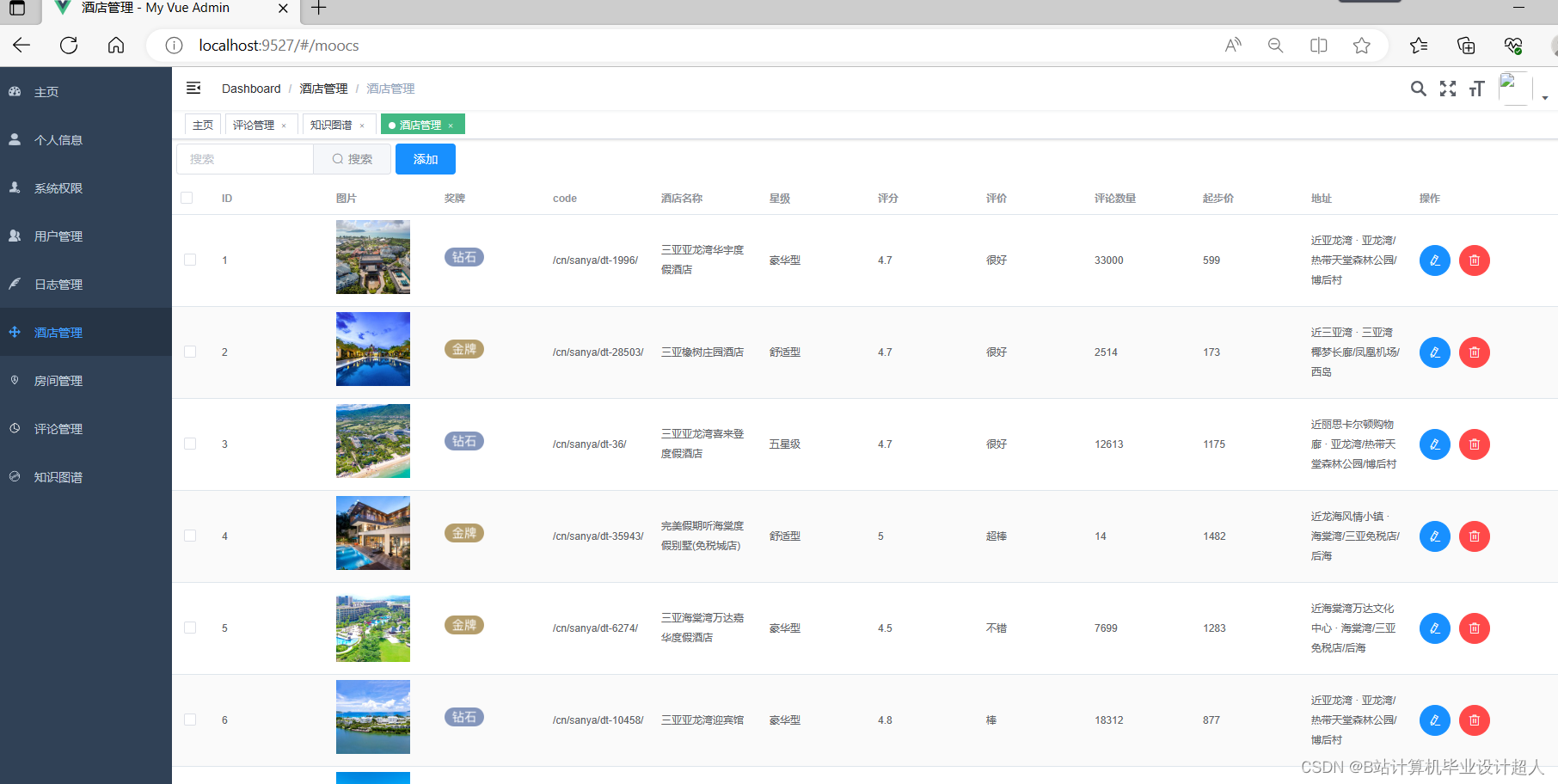
对某城市的民宿情况进行具体的分析、例如对民宿的价格、点评数、床位数、区域平均价格、区域平均评分、区域民宿数量等民宿的基本数据。
对用户在民宿网站上的评价进行分析,对评价进行分析可以了解用户的需求和期望,从而改进服务质量和水平,提高用户满意度。其他用户可以通过评价了解民宿的设施、环境、服务、卫生等方面的具体情况,从而做出更明智的预订决策。
为了提高房源的知名度和曝光率、吸引用户消费,房东在房源网页上都会标注特征描述,对标注的数据进行提取分析,例如民宿的基本设施和特点、民宿的特色和个性化服务、民宿的质量和用户口碑。针对房东用什么服务、准备何种特殊设施、特殊地理位置等来吸引消费者进行分析。
民宿的选址往往取决于经济、交通、景点几个方面,对房源网页上爬取的交通、景点、餐饮、商超等位置信息进行分析,得出哪个位置的民宿密度较高,以及该区域的民宿分布特点.
把分析获得的数据利用可视化工具进行可视化操作结合前端页面实现展示效果。 (二)预期目标 提升客户体验:通过对民宿数据的分析可视化,可以了解客户评价、投诉情况等信息,从而及时发现问题并采取措施改进。此外,可以根据客户喜好和需求,提供个性化的服务和增值服务,提升客户体验。 提供决策参考:通过对民宿数据的分析可视化,可以为管理层提供决策依据。例如,可以根据数据分析结果,判断是否需要扩大或调整民宿的规模,选择合适的营销渠道,或者进行资源的合理配置。 (三)拟解决的关键问题 1、网站为了预防恶意爬虫都会布置反爬虫技术,这要求在使用爬虫技术时应该遵从法律规定,做到友好访问,不破坏、不妨碍网站的正常运行。 2、数据质量问题,民宿数据的准确性和完整性可能存在问题。解决方案是获得数据后对特殊的数据通过数据清洗和预处理提高数据质量。 3、系统性能问题,大数据量和复杂的计算可能导致系统性能下降。解决方案是通过系统优化和资源调度解决性能问题。 | ||||||||||||||||||||||||||
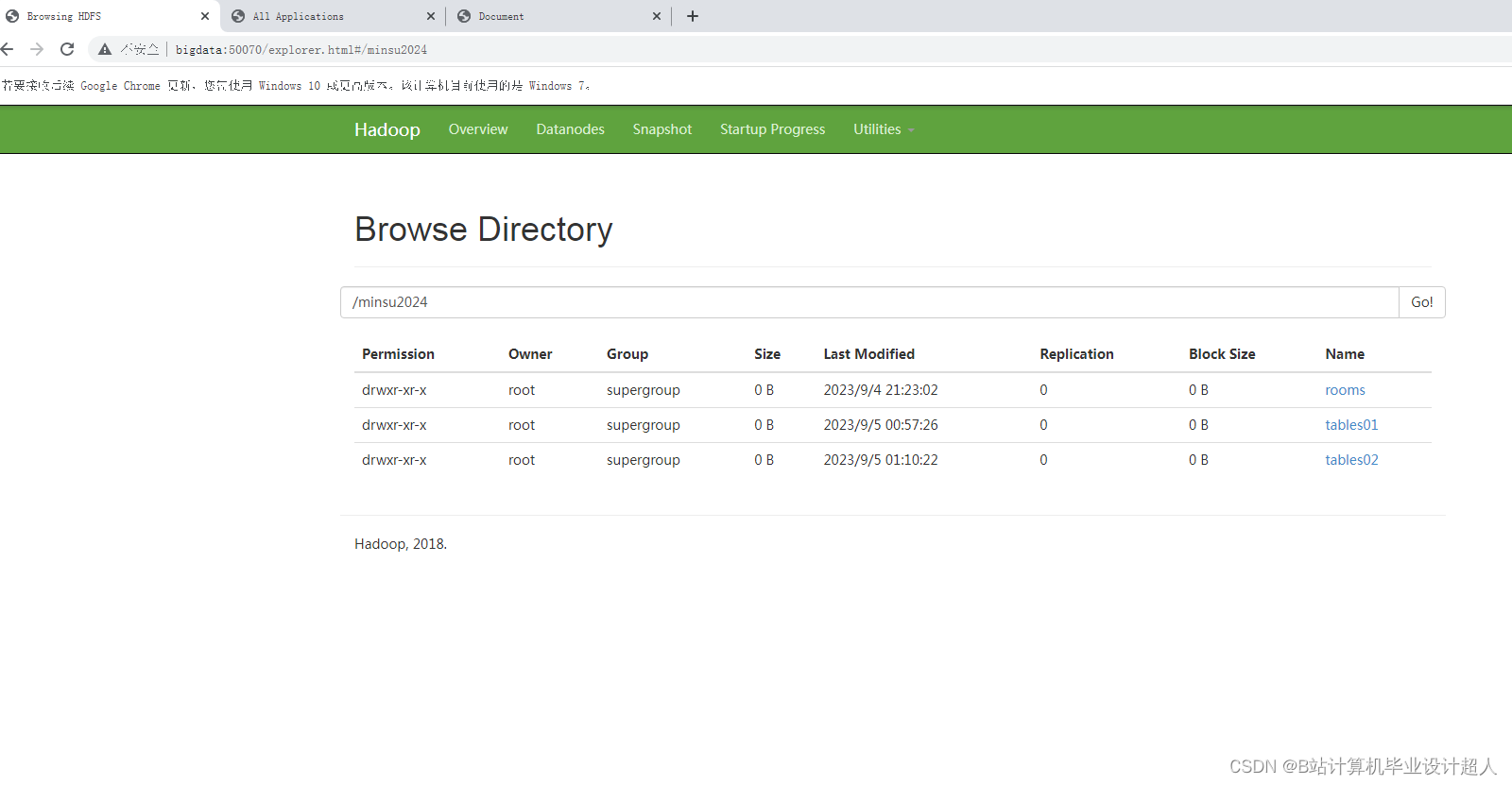
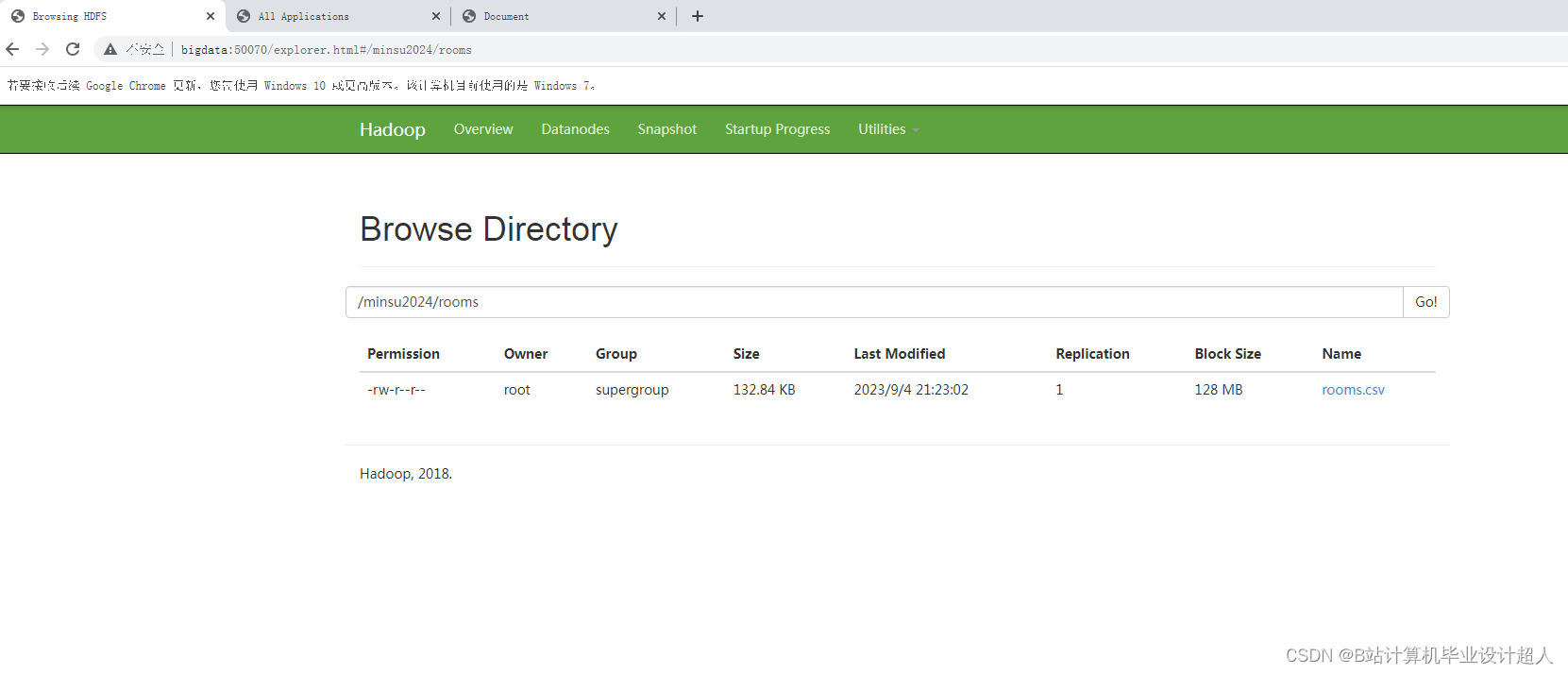
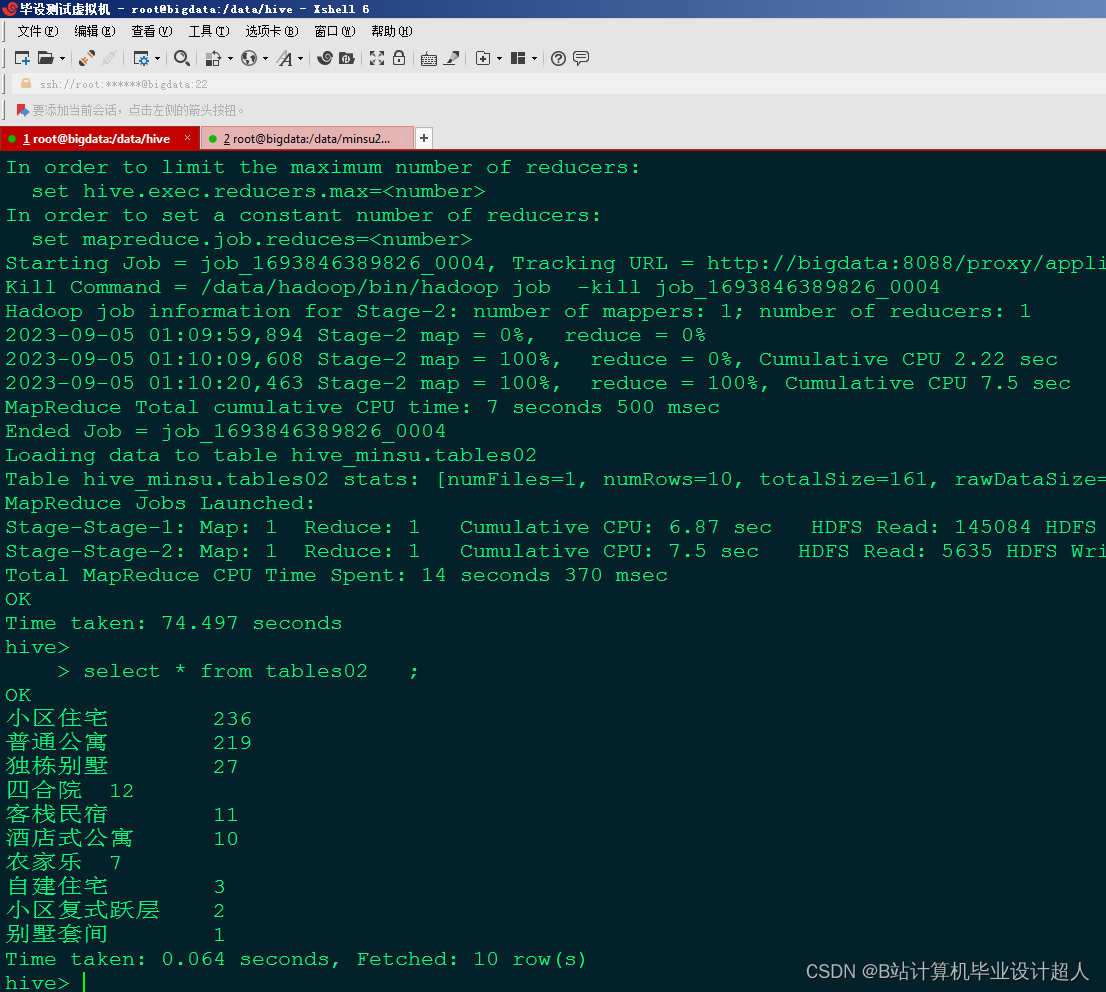
| 三、研究方案(包括有关方法、技术路线、实验手段、关键技术等)。 (一)有关方法 1、信息研究方法 信息研究方法是利用信息来研究系统功能的一种科学研究方法。信息方法就是根据信息论、系统论、控制论的原理,通过对信息的收集、传递、加工和整理获得知识,并应用于实践,以实现新的目标。在本研究中利用从民宿网站上获取的数据进行去重、清洗、分析,最后再利用可视化工具展示出来。 2、文献研究法 本研究通过查阅中国知网数据库,对民宿与大数据技术等主题相关的文献进行遴选、整理、归纳和总结,为科学系统地认知和理解民宿的发展和营销以及大数据技术奠定基础。 (二)技术路线 (三)实验手段 1、 数据获取模块:利用Python编程语言,结合第三方爬虫框架,编写爬虫程序,实现对民宿数据字段的定向抓取。 2、数据存储模块:利用Hadoop自带的HDFS,将爬取的数据以文件形式上传至HDFS,利用Hadoop的MapReduce对数据进行数据清洗,最后将清洗后的数据以json文件形式再次上传至HDFS中,进行存储。 3、数据清洗模块:利用Hadoop自带的的MapReduce编程模型,编写MapReduce程序对上传到HDFS中数据进行数据清洗操作。 4、数据分析模块:利用Hadoop自带的Hive数据仓库,编写Hive类SQL编程,对以清洗的数据进行数据分析。 5、 数据可视化模块:引入ECharts图表库,使用HTML、CSS和JavaScript等前端技术,设计各类图表。 (四)、关键技术 1、数据的爬取用到Python的Scrapy框架、Selenium、Xpath解析库等相关技术。 2、数据的存储用到Hadoop集群的HDFS,该数据库免费开源易于使用、且性能出色、方便后期存储大量数据和进行数据的提取处理。 3、数据的清洗用到了Hadoop集群中的MapReduce编程模型,利用MapReduce进行数据清洗可以大大提高数据的质量和准确性,为后续的数据分析和应用提供可靠的基础。 4、数据分析用到Hadoop集群的Hive数据仓库,操作接口采用类SQL语法,提供快速开发的能力。 5、数据的可视化利用HTML、CSS和JavaScript等前端技术,引入ECharts图表库设计各类图表。 | ||||||||||||||||||||||||||
| 四、设计或研究计划进度
| ||||||||||||||||||||||||||
| 五、设计(论文)的预期成果与特色或创新之处 (一)预期成果 1、数据获取 通过使用爬虫技术,从民宿平台获取相关数据,包括民宿信息、评论数据、价格、地理位置、面积等。 2、数据存储 选择MySQL数据库作为数据存储的解决方案,通过合理的数据表设计和索引优化,实现对大量民宿数据的高效存储和查询。 3、数据清洗 对采集到的数据进行清洗和预处理,包括去重、缺失值处理、异常值处理等,以确保数据的质量和准确性。 4、数据可视化 使用ECharts图表库,将清洗后的数据进行可视化展示,包括柱状图、折线图、散点图等,以直观地展现民宿数据的趋势和关联性。 (二)特色之处 1、数据全面性 通过数据采集和清洗,获取到具有较高质量和全面性的民宿数据,提供给用户更准确的数据分析结果。 2、决策支持 通过数据分析和挖掘,提供给用户相关的决策支持,如市场趋势分析、民宿评价等,帮助用户做出更明智的决策。 3、可视化界面 设计并实现一个直观、易用的数据可视化界面,使用户能够通过图表、地图等方式直观地理解和分析数据。 | ||||||||||||||||||||||||||












当采集民宿数据时,您可以使用 Python 中的第三方库(例如 BeautifulSoup 和 Requests)来获取网页内容并解析 HTML。以下是一个示例代码,演示如何采集民宿数据:
- import requests
- from bs4 import BeautifulSoup
-
- def scrape_homestay_data(url):
- # 发送 HTTP GET 请求获取网页内容
- response = requests.get(url)
-
- # 检查响应状态码
- if response.status_code == 200:
- # 使用 BeautifulSoup 解析 HTML 内容
- soup = BeautifulSoup(response.text, 'html.parser')
-
- # 在此处编写具体的数据提取逻辑
- # 使用 soup.select() 或 soup.find() 方法来选择和提取相应的数据
-
- # 示例:提取民宿名称
- homestay_name = soup.select_one('.homestay-name').text.strip()
- print("民宿名称:", homestay_name)
-
- # 示例:提取民宿价格
- homestay_price = soup.select_one('.homestay-price').text.strip()
- print("民宿价格:", homestay_price)
-
- # 示例:提取民宿评分
- homestay_rating = soup.select_one('.homestay-rating').text.strip()
- print("民宿评分:", homestay_rating)
-
- # 其他数据提取逻辑类似
-
- else:
- print("请求失败,状态码:", response.status_code)
-
- # 示例 URL
- url = "XXXXXXXXXXXXXXXXXXXX"
-
- # 调用函数进行数据采集
- scrape_homestay_data(url)

在这个示例中,我们定义了一个函数 scrape_homestay_data(),该函数接收一个 URL 作为参数,并使用 requests 库发送 HTTP GET 请求来获取网页内容。然后,使用 BeautifulSoup 库将 HTML 内容解析为一个 BeautifulSoup 对象。您可以使用 soup.select() 或 soup.find() 方法选择和提取相应的数据。
在示例代码中,我们提取了民宿名称、价格和评分作为示例。您可以根据实际情况编写适合的数据提取逻辑,并使用相应的 CSS 选择器选择和提取数据。
请注意,这只是一个简单的示例,实际的数据采集过程可能更复杂,需要根据具体网页结构和数据的位置进行定制。您可能还需要处理异常情况、分页、反爬虫措施等问题。
希望这个示例对您有帮助。如果您有任何其他问题或需要进一步的解释,请随时告诉我。我随时为您提供帮助。

