
- 1MapReduce集群的安装与部署_mapreduce安装部署
- 2R语言上机例题_单位招聘2500人,按考试成绩从高到低依次录用,共有10000人报名,假设报名者的成绩
- 3Linux-解压缩文件命令(gzip、zip、unzip、tar、jar)_jar文件解压与压缩
- 4基于springboot生鲜交易商城微信小程序源码和论文
- 5【Hive---06】数据导入 与 数据导出_hive导出数据到本地
- 62024年网络安全最新网络安全学习笔记
- 7Django+uwsgi+nginx服务器部署后无法访问除首页外的其它页面_nginx django 打不开
- 8CSDN上该如何查看自己有多少积分?_csdn查看积分
- 9快速体验 Llama3 的 4 种方式,本地部署,800 tokens/s 的推理速度真的太快了!_llama 3 token就可以下各种软件输入你的token来操作了
- 10python linux运行环境,Linux平台Python运行环境配置
Hive表---内部表、外部表、数据导入和导出_hive的内外部表
赞
踩
一. 内部表
1. 内部表基本操作
创建内部表: create table [if not exists] 内部表名(字段名 字段类型 , 字段名 字段类型 , … )[row format delimited fields terminated by ‘字段分隔符’] ;
复制内部表: 方式1: like方式复制表结构 方式2: as 方式复制表结构和数据
删除内部表: drop table 内部表名;
注意: 删除内部表效果是mysql中表相关元数据被删除,同时存储在hdfs中的业务数据本身也被删除
查看表格式化信息: desc formatted 表名; – 内部表类型: MANAGED_TABLE
注意: 还可以使用truncate清空内部表数据 格式: truncate table 内部表名;
2. 示例
-- 操作表的前提:先有库并使用它 create database hive2; use hive2; -- 一.内部表的创建和删除 -- 1.演示创建内部表 -- 建表方式1 create table inner_stu1( id int, name string ); -- 插入数据 insert into inner_stu1 values(1,'张三'); -- 建表方式2: 复制表结构 create table inner_stu2 like inner_stu1; -- 插入数据 insert into inner_stu2 values(1,'张三'); -- 建表方式3: 复制表结构和数据 create table inner_stu3 as select * from inner_stu1; -- 2.演示查看内部表结构详细信息 -- 内部表类型: MANAGED_TABLE desc formatted inner_stu1; desc formatted inner_stu2; desc formatted inner_stu3; -- 3.演示内部表的删除 -- 删除内部表 drop table inner_stu3;-- 元数据和业务数据均被删除 -- 清空内部数据 truncate table inner_stu2; -- 注意: delete和update不能使用 delete from inner_stu1;-- 报错 update inner_stu1 set name = '李四'; -- 报错

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
二. 外部表基本操作
1. 外部表基本操作
创建外部表: create external table [if not exists] 外部表名(字段名 字段类型 , 字段名 字段类型 , … )[row format delimited fields terminated by ‘字段分隔符’] ;
复制表: 方式1: like方式复制表结构 注意: as方式不可以使用
删除外部表: drop table 外部表名;
注意: 删除外部表效果是mysql中元数据被删除,但是存储在hdfs中的业务数据本身被保留
查看表格式化信息: desc formatted 表名; – 外部表类型: EXTERNAL_TABLE
注意: 外部表不能使用truncate清空数据本身
2. 示例
-- 二.外部表的创建和删除 -- 1.外部的表创建 -- 建表方式1 create external table outer_stu1( id int, name string ); -- 插入数据 insert into outer_stu1 values(1,'张三'); -- 建表方式2 create external table outer_stu2 like outer_stu1; -- 插入数据 insert into outer_stu2 values(1,'张三'); -- 注意: 外部表不能使用create ... as 方式复制表 create external table outer_stu3 as select * from outer_stu1; -- 报错 -- 2.演示查看外部表结构详细信息 -- 外部表类型: EXTERNAL_TABLE desc formatted outer_stu1; desc formatted outer_stu2; -- 3.演示外部表的删除 -- 删除表 drop table outer_stu2; -- 注意: 外部表不能使用truncate关键字清空数据 truncate table outer_stu1; -- 报错 -- 注意: delete和update不能使用 delete from outer_stu1; -- 报错 update outer_stu1 set name = '李四'; -- 报错
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
三. 查看/修改表
知识点
查看所有表: show tables;
查看建表语句: show create table 表名;
查看表信息: desc 表名;
查看表结构信息: desc 表名;
查看表格式化信息: desc formatted 表名; 注意: formatted能够展示详细信息
修改表名: alter table 旧表名 rename to 新表名
字段的添加: alter table 表名 add columns (字段名 字段类型);
字段的替换: alter table 表名 replace columns (字段名 字段类型 , …);
字段名和字段类型同时修改: alter table 表名 change 旧字段名 新字段名 新字段类型;
注意: 字符串类型不能直接改数值类型
修改表路径: alter table 表名 set location ‘hdfs中存储路径’; 注意: 建议使用默认路径
location: 建表的时候不写有默认路径/user/hive/warehouse/库名.db/表名,当然建表的时候也可以直接指定路径
修改表属性: alter table 表名 set tblproperties (‘属性名’=‘属性值’); 注意: 经常用于内外部表切换
内外部表类型切换: 外部表属性: ‘EXTERNAL’=‘TRUE’ 内部表属性: ‘EXTERNAL’=‘FALSE’
示例
-- 三.表的查看/修改操作 -- 验证之前的内外部表是否存在以及是否有数据,如果没有自己创建,如果有直接使用 select * from inner_stu1 limit 1; select * from outer_stu1 limit 1; -- 1.表的查看操作 -- 查看所有的表 show tables; -- 查看建表语句 show create table inner_stu1; show create table outer_stu1; -- 查看表基本机构 desc inner_stu1; desc outer_stu1; -- 查看表格式化详细信息 desc formatted inner_stu1; desc formatted outer_stu1; -- 2.表的修改操作 -- 修改表名 -- 注意: 外部表只会修改元数据表名,hdfs中表目录名不会改变 alter table inner_stu1 rename to inner_stu; alter table outer_stu1 rename to outer_stu; -- 修改表中字段 -- 添加字段 alter table inner_stu add columns(age int); alter table outer_stu add columns(age int); -- 替换字段 alter table inner_stu replace columns(id int,name string); alter table outer_stu replace columns(id int,name string); -- 修改字段 alter table inner_stu change name sname varchar(100); alter table outer_stu change name sname varchar(100); -- 修改表路径(实际不建议修改) -- 注意: 修改完路径后,如果该路径不存在,不会立刻创建,以后插入数据的时候自动生成目录 alter table inner_stu set location '/inner_stu'; alter table outer_stu set location '/outer_stu'; -- 修改表属性 -- 先查看类型 desc formatted inner_stu; -- MANAGED_TABLE desc formatted outer_stu; -- EXTERNAL_TABLE -- 内部表改为外部表 alter table inner_stu set tblproperties ('EXTERNAL'='TRUE'); -- 外部表改为内部表 alter table outer_stu set tblproperties ('EXTERNAL'='FALSE'); -- 最后再查看类型 desc formatted inner_stu; -- EXTERNAL_TABLE desc formatted outer_stu; -- MANAGED_TABLE
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
四. 默认分隔符
创建表的时候,如果不指定分隔符,以后表只能识别默认的分隔符,键盘不好打印,展示形式一般为:\0001,SOH,^A,□
-- 默认分隔符: 创建表的时候不指定就代表使用默认分隔符
-- 1.创建表
create table stu(
id int,
name string
);
-- insert方式插入数据,会自动使用默认分隔符把数据连接起来
-- 2.插入数据
insert into stu values(1,'zhangsan');
-- 3.验证数据
select * from stu limit 1;
-- 当然也可以通过在hdfs中查看,默认分隔符是\0001,其他工具中也会展示为SOH,^A,口
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
五. 快速映射表
创建表的时候指定分隔符:
create [external] table 表名(字段名 字段类型) row format delimited fields terminated by “分隔符”;
加载数据:
如果加上local则是在linux上加载数据
load data [local] inpath ‘结构化数据文件’ into table 表名;
-- 创建表
create table products(
id int,
name string,
price double,
cid string
)row format delimited
fields terminated by ',';
-- 加载数据
-- 注意: 如果从hdfs中加载文件,本质就是移动文件到对应表路径下
load data inpath '/source/products.txt' into table products;
-- 验证数据
select * from products limit 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
六. 数据导入和导出
1. 文件数据加载导入
6.1.1 直接上传文件
window页面上传
需求: 已知emp1.txt文件在windows/mac系统,要求使用hdfs保存此文件
并且使用hivesql建表关联数据
-- 1.先在hive上根据数据建表,然后在window/mac上传文件到hdfs表路径中
create table emp1(
id int,
name string,
sal double,
dept string
)row format delimited
fields terminated by ',';
-- windows使用hdfs页面上传文件
-- node1:9870访问页面把emp1.txt上传到/user/hive/warehouse/hive02.db/emp1路径下
-- 查询数据
select * from emp1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
linux本地put上传
需求: 已知emp2.txt文件在linux系统,要求使用hdfs保存此文件
并且使用hivesql建表关联数据
-- 2.先在hive上根据数据建表,然后在linux上传文件到hdfs表路径中
create table emp2(
id int,
name string,
sal double,
dept string
)row format delimited
fields terminated by ',';
-- linux使用hdfs命令上传文件
-- [root@node1 ~]# hdfs dfs -put emp2.txt /user/hive/warehouse/hive02.db/emp2
-- 查看数据
select * from emp2;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
6.1.2 load加载文件
从hdfs路径把文件移动到表对应存储路径中: load data inpath ‘HDFS文件路径’ [overwrite] into table 表名;
从linux本地把文件上传到表对应存储路径中: load data local inpath ‘Linux文件路径’ [overwrite] into table 表名;
load移动HDFS文件
-- 数据导入
-- 需求1: load加载hdfs中文件到表路径中
-- 1.根据斌哥资料中search_log.txt数据创建表
create table search_log(
dt string,
uid string,
name string,
url string
)row format delimited fields terminated by '\t';
-- 2.把windows中search_log.txt文件上传hdfs其他路径,例如:/src中
-- 3.使用load把hdfs的/src中的文件移动到search_log对应hdfs表存储路径中
load data inpath '/src/search_log.txt' into table search_log;
-- 4.查询数据
select * from search_log;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
load上传Linux文件
-- 需求2: 直接把linux中最新的search_log.txt文件上传到search表对应hdfs路径中
-- 先把资料中search_log.txt文件传到linux中,例如:/root
-- load命令上传文件
load data local inpath '/root/search_log.txt' overwrite into table search_log;
-- 查看最终数据
select * from search_log;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
6.1.3 insert插入数据
从其他表查询数据’追加’插入到当前表中: insert into [table] 表名 select 语句;
从其他表查询数据’覆盖’插入到当前表中: insert overwrite table 表名 select 语句;
insert追加数据
-- 需求1:创建一个search_log_copy表,然后从search_log查询数据插入到新表中
create table search_log_copy(
dt string,
uid string,
word string,
url string
)row format delimited
fields terminated by '\t';
-- 从search_log表中查所有数据,直接插入到search_log_copy表
insert into table search_log_copy select * from search_log;
-- 查看数据
select * from search_log_copy;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
insert覆盖数据
-- 需求2: 假设search_log表中数据改变了,要求把最新的数据更新到search_log_copy表中
insert overwrite table search_log_copy select * from search_log;
-- 查看数据
select * from search_log_copy;
- 1
- 2
- 3
- 4
2. 文件数据导出
6.2.1 直接下载文件
web页面下载
需求: 已知search_log.txt文件在HFDS的/user/hive/warehouse/hive02.db/search_log路径下,要下载到window系统
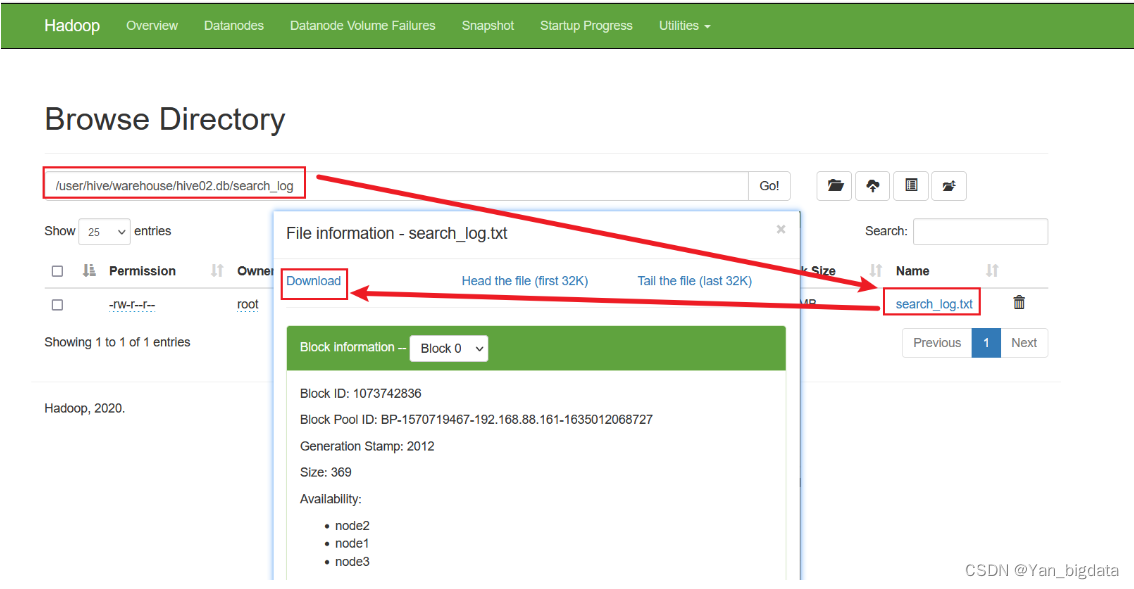
get命令下载文件
需求: 已知search_log.txt文件在HFDS的/user/hive/warehouse/hive02.db/search_log路径下,要下载到linux系统
[root@node1 binzi]# hdfs dfs -get /user/hive/warehouse/hive02.db/search_log/search_log.txt /binzi
- 1
6.2.2 insert 导出数据
查询数据导出到hdfs其他路径: insert overwrite directory ‘hfds存储该数据路径’ select语句;
查询数据导出到linux本地中: insert overwrite local directory ‘linux存储该数据路径’ select语句;
注意: overwrite默认是覆盖重写,所以在指定存储该数据路径的时候尽量指定一个空的目录
注意: 导出数据的时候不指定分隔符采用默认分隔符SOH,0001,?..
导出数据指定分隔符添加: row format delimited fields terminated by ‘分隔符’
insert导出到hdfs
-- 演示insert overwrite导出数据到文件
-- 语法: insert overwrite [local] directory 文件存储路径 [指定分隔符] select语句;
-- 导出数据到hfds
-- 注意: 如果是根目录/,会自动创建-ext-10000目录存储生成的000000_0文件
-- 但是其他目录,会自动清空所有内容,再生成一个000000_0文件,所以注意导出目录尽量是一个新的空目录
-- 默认分隔符
insert overwrite directory '/source' select * from search_log1;
-- 指定分隔符
insert overwrite directory '/output'
row format delimited fields terminated by ','
select * from search_log1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
insert导出到linux
-- 2.2导出到linux
-- [root@node1 ~]# mkdir /output
-- 导出到linux的/output目录下,自动生成000000_0文件存储查询结果
-- 默认分隔符
insert overwrite local directory '/output' select * from search_log1;
-- 指定分隔符
insert overwrite local directory '/output'
row format delimited fields terminated by ','
select * from search_log1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6.2.3 hive_shell命令
hive命令执行sql语句: hive -e “sql语句” > 存储该结果数据的文件路径
hive命令执行sql脚本: hive -f sql脚本文件 > 存储该结果数据的文件路径
hql语句导出
# 以下命令都是在linux的shell命令行执行
# 3.1使用hive -e sql语句方式导出数据
[root@node1 ~]# hive -e 'select * from hive02.search_log;' > /home/hs1.txt
[root@node1 ~]# cat hs1.txt
- 1
- 2
- 3
- 4
hql脚本导出
# 3.2使用hive -f 脚本文件方式导出数据
[root@node1 ~]# echo 'select * from hive02.search_log;' > /home/export.sql
[root@node1 ~]# hive -f export.sql > /home/hs2.txt
[root@node1 ~]# cat hs2.txt
- 1
- 2
- 3
- 4


