
- 1推荐一款YYDS的低代码开源项目:1小时创建企业专属ERP_电商erp零代码搭建
- 2Python资源汇总
- 3基于ssm+vue+Mysql的企业公寓后勤管理系统
- 4Ubuntu下PostgreSQL的安装与使用_ubuntu安装postgresql
- 5win11安装docker-desktop_win11安装docker desktop
- 6Linux 基础命令知识1_lunix 命令count
- 7java web 找回密码_java web实现 忘记密码(找回密码)功能及代码
- 8数据结构与算法——二叉树、堆、优先队列_结点的直接前驱
- 9python判断质数_python i%j==0
- 10黑屏定屏那些事 - 系统机制,分析套路和实战(系统篇)_android黑屏问题分析
2、24 个常见的 Docker 疑难杂症处理技巧(二)_docker 吐核什么意思
赞
踩
7Docker 容器中文异常
容器存在问题话,记得优先在官网查询
[问题起因] 今天登陆之前部署的 MySQL 数据库查询,发现使用 SQL 语句无法查询中文字段,即使直接输入中文都没有办法显示。
# 查看容器支持的字符集
root@b18f56aa1e15:# locale -a
C
C.UTF-8
POSIX
- 1
- 2
- 3
- 4
- 5
[解决方法] Docker 部署的 MySQL 系统使用的是 POSIX 字符集。然而 POSIX 字符集是不支持中文的,而 C.UTF-8 是支持中文的只要把系统中的环境 LANG 改为 “C.UTF-8” 格式即可解决问题。同理,在 K8S 进入 pod 不能输入中文也可用此方法解决。
# 临时解决
docker exec -it some-mysql env LANG=C.UTF-8 /bin/bash
# 永久解决
docker run --name some-mysql \
-e MYSQL_ROOT_PASSWORD=my-secret-pw \
-d mysql:tag --character-set-server=utf8mb4 \
--collation-server=utf8mb4_unicode_ci
- 1
- 2
- 3
- 4
- 5
- 6
- 7
8Docker 容器网络互通
了解 Docker 的四种网络模型
[问题起因] 在本机部署 Nginx 容器想代理本机启动的 Python 后端服务程序,但是对代码服务如下的配置,结果访问的时候一直提示 502 错误。
# 启动Nginx服务
$ docker run -d -p 80:80 $PWD:/etc/nginx nginx
server {
...
location /api {
proxy_pass http://localhost:8080
}
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
[解决方法] 后面发现是因为 nginx.conf 配置文件中的 localhost 配置的有问题,由于 Nginx 是在容器中运行,所以 localhost 为容器中的 localhost,而非本机的 localhost,所以导致无法访问。
可以将 nginx.conf 中的 localhost 改为宿主机的 IP 地址,就可以解决 502 的错误。
# 查询宿主机IP地址 => 172.17.0.1
$ ip addr show docker0
docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:d5:4c:f2:1e brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:d5ff:fe4c:f21e/64 scope link
valid_lft forever preferred_lft forever
server {
...
location /api {
proxy_pass http://172.17.0.1:8080
}
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
当容器使用 host 网络时,容器与宿主共用网络,这样就能在容器中访问宿主机网络,那么容器的 localhost 就是宿主机的 localhost 了。
# 服务的启动方式有所改变(没有映射出来端口)
# 因为本身与宿主机共用了网络,宿主机暴露端口等同于容器中暴露端口
$ docker run -d -p 80:80 --network=host $PWD:/etc/nginx nginxx
- 1
- 2
- 3
9Docker 容器总线错误
总线错误看到的时候还是挺吓人了
[问题起因] 在 docker 容器中运行程序的时候,提示 bus error 错误。
# 总线报错
$ inv app.user_op --name=zhangsan
Bus error (core dumped)
- 1
- 2
- 3
[解决方法] 原因是在 docker 运行的时候,shm 分区设置太小导致 share memory 不够。不设置 --shm-size 参数时,docker 给容器默认分配的 shm 大小为 64M,导致程序启动时不足。具体原因还是因为安装 pytorch 包导致了,多进程跑任务的时候,docker 容器分配的共享内存太小,导致 torch 要在 tmpfs 上面放模型数据用于子线程的 共享不足,就出现报错了。
# 问题原因
root@18...35:/opt/app# df -TH
Filesystem Type Size Used Avail Use% Mounted on
overlay overlay 2.0T 221G 1.4T 3% /
tmpfs tmpfs 68M 0 68M 0% /dev
shm tmpfs 68M 41k 68M 1% /dev/shm
# 启动docker的时候加上--shm-size参数(单位为b,k,m或g)
$ docker run -it --rm --shm-size=200m pytorch/pytorch:latest
# 在docker-compose添加对应配置
$ shm_size: '2gb'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
[解决方法] 还有一种情况就是容器内的磁盘空间不足,也会导致 bus error 这样的报错,所以如果出现了,清除多余文件和目录或者分配一个大的磁盘空间,就可以解决了。
# 磁盘空间不足
$ df -Th
Filesystem Type Size Used Avail Use% Mounted on
overlay overlay 1T 1T 0G 100% /
shm tmpfs 64M 24K 64M 1% /dev/shm
- 1
- 2
- 3
- 4
- 5
10Docker NFS 挂载报错
NFS 挂载之后容器程序使用异常为内核版本太低导致的
[问题起因] 我们将服务部署到 openshift 集群中,启动服务调用资源文件的时候,报错信息如下所示。从报错信息中,得知是在 Python3 程序执行 read_file() 读取文件的内容,给文件加锁的时候报错了。但是奇怪的是,本地调试的时候发现服务都是可以正常运行的,文件加锁也是没问题的。后来发现,在 openshift 集群中使用的是 NFS 挂载的共享磁盘。
# 报错信息
Traceback (most recent call last):
......
File "xxx/utils/storage.py", line 34, in xxx.utils.storage.LocalStorage.read_file
OSError: [Errno 9] Bad file descriptor
# 文件加锁代码
...
with open(self.mount(path), 'rb') as fileobj:
fcntl.flock(fileobj, fcntl.LOCK_EX)
data = fileobj.read()
return data
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
[解决方法] 从下面的信息得知,要在 Linux 中使用 flock() 的话,就需要升级内核版本到 2.6.11+ 才行。后来才发现,这实际上是由 RedHat 內核中的一个错误引起的,并在 kernel-3.10.0-693.18.1.el7 版本中得到修复。所以对于 NFSv3 和 NFSv4 服务而已,就需要升级 Linux 内核版本才能够解决这个问题。
# https://t.codebug.vip/questions-930901.htm
$ In Linux kernels up to 2.6.11, flock() does not lock files over NFS (i.e.,
the scope of locks was limited to the local system). [...] Since Linux 2.6.12,
NFS clients support flock() locks by emulating them as byte-range locks on the entire file.
- 1
- 2
- 3
- 4
11Docker 使用默认网段
启动的容器网络无法相互通信,很是奇怪!
[问题起因] 我们在使用 Docker 启动服务的时候,发现有时候服务之前可以相互连通,而有时启动的多个服务之前却出现了无法访问的情况。究其原因,发现原来是因为使用的内部私有地址网段不一致导致的。有的服务启动到了 172.17 - 172.31 的网段,有的服务跑到了 192.169.0 - 192.168.224 的网段,这样导致服务启动之后出现无法访问的情况(默认情况下,有下面这个两个网段可供其使用)。
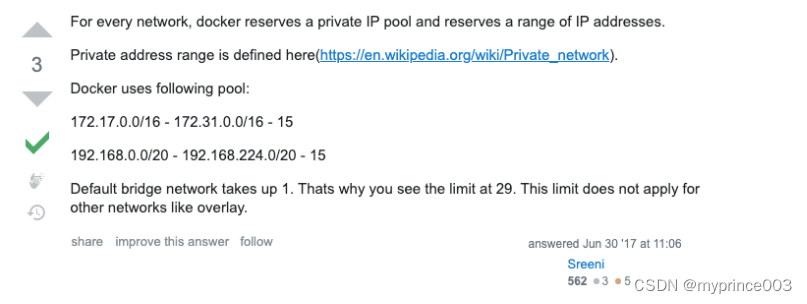
[解决方法] 上述问题的处理方式,就是手动指定 Docker 服务的启动网段,二选一就可以了。
# 查看docker容器配置
$ cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://vec0xydj.mirror.aliyuncs.com"],
"default-address-pools":[{"base":"172.17.0.0/12", "size":24}],
"experimental": true,
"default-runtime": "nvidia",
"live-restore": true,
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
12Docker 服务启动串台
使用 docker-compose 命令各自启动两组服务,发现服务会串台!
[问题起因] 在两个不同名称的目录目录下面,使用 docker-compose 来启动服务,发现当 A 组服务启动完毕之后,再启动 B 组服务的时候,发现 A 组当中对应的一部分服务又重新启动了一次,这就非常奇怪了!因为这个问题的存在会导致,A 组服务和 B 组服务无法同时启动。之前还以为是工具的 Bug,后来请教了 “上峰”,才知道了原因,恍然大悟。
# 服务目录结构如下所示
A: /data1/app/docker-compose.yml
B: /data2/app/docker-compose.yml
- 1
- 2
- 3
[解决方法] 发现 A 和 B 两组服务会串台的原因,原来是 docker-compose 会给启动的容器加 label 标签,然后根据这些 label 标签来识别和判断对应的容器服务是由谁启动的、谁来管理的,等等。而这里,我们需要关注的 label 变量是 com.docker.compose.project,其对应的值是使用启动配置文件的目录的最底层子目录名称,即上面的 app 就是对应的值。我们可以发现, A 和 B 两组服务对应的值都是 app,所以启动的时候被认为是同一个,这就出现了上述的问题。如果需要深入了解的话,可以去看对应源代码。
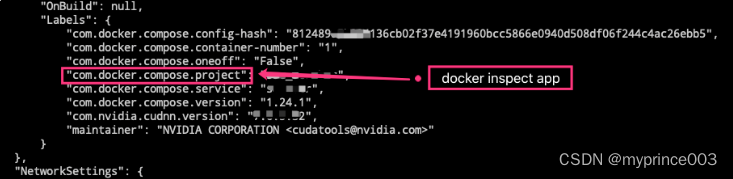
Docker服务启动串台
# 可以将目录结构调整为如下所示
A: /data/app1/docker-compose.yml
B: /data/app2/docker-compose.yml
A: /data1/app-old/docker-compose.yml
B: /data2/app-new/docker-compose.yml
或者使用 docker-compose 命令提供的参数 -p 手动指定标签,来规避该问题的发生。
# 指定项目项目名称
$ docker-compose -f ./docker-compose.yml -p app1 up -d
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
13Docker 命令调用报错
在编写脚本的时候常常会执行 docker 相关的命令,但是需要注意使用细节!
[问题起因] CI 更新环境执行了一个脚本,但是脚本执行过程中报错了,如下所示。通过对应的输出信息,可以看到提示说正在执行的设备不是一个 tty。

随即,查看了脚本发现报错地方是执行了一个 exec 的 docker 命令,大致如下所示。很奇怪的是,手动执行或直接调脚本的时候,怎么都是没有问题的,但是等到 CI 调用的时候怎么都是有问题。后来好好看下,下面这个命令,注意到 -it 这个参数了。
# 脚本调用docker命令
docker exec -it <container_name> psql -Upostgres ......
- 1
- 2
我们可以一起看下 exec 命令的这两个参数,自然就差不多理解了。

[解决方法] docker exec 的参数 -t 是指 Allocate a pseudo-TTY 的意思,而 CI 在执行 job 的时候并不是在 TTY 终端中执行,所以 -t 这个参数会报错。同时在 『stackoverflow』也有人给出原因,可以自行查看。

14Docker 定时任务异常
在 Crontab 定时任务中也存在 Docker 命令执行异常的情况!
[问题起因] 今天发现了一个问题,就是在备份 Mysql 数据库的时候,使用 docker 容器进行备份,然后使用 Crontab 定时任务来触发备份。但是发现备份的 MySQL 数据库居然是空的,但是手动执行对应命令切是好的,很奇怪。
# Crontab定时任务
0 */6 * * * \
docker exec -it <container_name> sh -c \
'exec mysqldump --all-databases -uroot -ppassword ......'
- 1
- 2
- 3
- 4
[解决方法] 后来发现是因为执行的 docker 命令多个 -i 导致的。因为 Crontab 命令执行的时候,并不是交互式的,所以需要把这个去掉才可以。总结就是,如果你需要回显的话则需要 -t 选项,如果需要交互式会话则需要 -i 选项。

15Docker 变量使用引号
compose 里边环境变量带不带引号的问题!
[问题起因] 使用过 compose 的朋友可能都遇到过,在编写启服务启动配置文件的时候,添加环境变量时到底是使用单引号、双引号还是不使用引号的问题?时间长了,我们可能会将三者混用,认为其效果是一样的。但是后来,发现的坑越来越多,才发现其越来越隐晦。
反正我是遇到过很多问题,都是因为添加引号导致的服务启动异常的,后来得出的结论就是一律不使引号。裸奔,体验前所未有的爽快!直到现在看到了 Github 中对应的 issus 之后,才终于破案了。
# 在Compose中进行引用TEST_VAR变量,无法找到
TEST_VAR="test"
# 在Compose中进行引用TEST_VAR变量,可以找到
TEST_VAR=test
# 后来发现docker本身其实已经正确地处理了引号的使用
docker run -it --rm -e TEST_VAR="test" test:latest
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[解决方法] 得到的结论就是,因为 Compose 解析 yaml 配置文件,发现引号也进行了解释包装。这就导致原本的 TEST_VAR=“test” 被解析成了 ‘TEST_VAR=“test”’,所以我们在引用的时候就无法获取到对应的值。现在解决方法就是,不管是我们直接在配置文件添加环境变量或者使用 env_file 配置文件,能不使用引号就不适用引号。
需要注意的是环境变量配置的是日志格式的话(2022-01-01),如果使用的是 Python 的 yaml.load 模块的话,会被当做是 date 类型的,这是如果希望保持原样信息的话,可以使用 '/" 引起来将其变成字符串格式的。
16Docker 删除镜像报错
无法删除镜像,归根到底还是有地方用到了!
[问题起因] 清理服器磁盘空间的时候,删除某个镜像的时候提示如下信息。提示需要强制删除,但是发现及时执行了强制删除依旧没有效果。
# 删除镜像
$ docker rmi 3ccxxxx2e862
Error response from daemon: conflict: unable to delete 3ccxxxx2e862 (cannot be forced) - image has dependent child images
# 强制删除
$ dcoker rmi -f 3ccxxxx2e862
Error response from daemon: conflict: unable to delete 3ccxxxx2e862 (cannot be forced) - image has dependent child images
[解决方法] 后来才发现,出现这个原因主要是因为 TAG,即存在其他镜像引用了这个镜像。这里我们可以使用如下命令查看对应镜像文件的依赖关系,然后根据对应 TAG 来删除镜像。
# 查询依赖 - image_id表示镜像名称
$ docker image inspect --format='{{.RepoTags}} {{.Id}} {{.Parent}}' $(docker image ls -q --filter since=<image_id>)
# 根据TAG删除镜像
$ docker rmi -f c565xxxxc87f
# 删除悬空镜像
$ docker rmi $(docker images --filter "dangling=true" -q --no-trunc)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
17Docker 普通用户切换
切换 Docker 启动用户的话,还是需要注意下权限问题的!
[问题起因] 我们知道在 Docker 容器里面使用 root 用户的话,是不安全的,很容易出现越权的安全问题,所以一般情况下,我们都会使用普通用户来代替 root 进行服务的启动和管理的。今天给一个服务切换用户的时候,发现 Nginx 服务一直无法启动,提示如下权限问题。因为对应的配置文件也没有配置 var 相关的目录,无奈 声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

