
- 1电商后台管理系统的项目优化_电商后台商品管理功能怎么优化
- 2当使用git时提醒Your branch and ‘origin/master‘ have diverged
- 3笔记:C51单片机——音乐播放,模拟钢琴键。_c51音乐
- 4【Linux】目录结构详解_linux目录结构
- 5用Rust重写数万行C代码,有必要吗?
- 6Ubuntu搭建Android源码编译环境_ubuntu搭建android编译环境
- 7mysql多表查询的分类_navicat for mysql 多表查询的分类
- 8ChatGPT 达人迷
- 9远程桌面键盘无法输入
- 10MySQL获取数据库元数据相关命令:DESC、SHOW、INFORMATION_SCHEMA、mysqlshow、mysqldump_show full status columns
LSTM(长短期记忆)网络的算法介绍及数学推导_lstm算法
赞
踩
前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容不乏不准确的地方,希望批评指正,共同进步。
本文旨在说明LSTM正向传播及反向传播的算法及数学推导过程,其他内容CSDN上文章很多,不再赘述。因此在看本文前必须掌握以下两点基础知识:
①RNN的架构及算法:RNN作为LSTM的基础,是必须要先掌握的。
夹带私货,推荐自己的文章:基于Numpy构建RNN模块并进行实例应用(附代码)
②LSTM的架构:基于RNN引入上一时刻隐层输出的思想,LSTM又增加了细胞状态 C t C_t Ct的概念。 t t t时刻的输出除了要参考 t − 1 t-1 t−1时刻隐层的输出 h t − 1 h_{t-1} ht−1之外,还要参考 t − 1 t-1 t−1时刻的细胞状态 C t − 1 C_{t-1} Ct−1。为了计算细胞状态,引入忘记门、输出门、新记忆门、输出门几个路径。
推荐文章:如何从RNN起步,一步一步通俗理解LSTM 以及此篇文章中引用的文章,都值得好好看下。
基于colah的博客的LSTM结构图,稍微加工下得到下面的原理图:
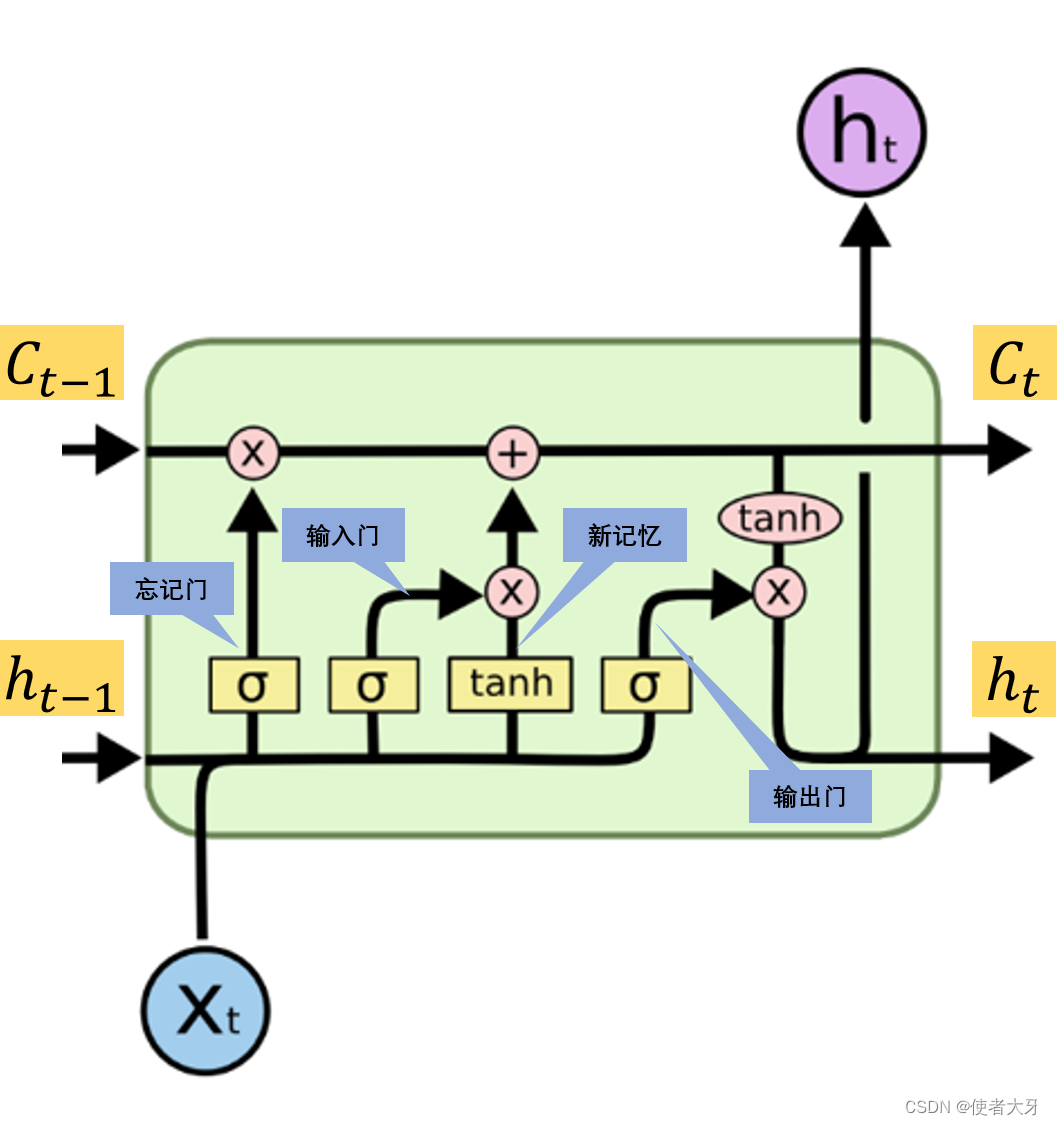
一、LSTM正向传播算法
这块比较容易,只要严格按照上面原理图,正向传播的算法都容易得出。
1.隐藏层正向传播算法
t t t时刻各个门为:
- 忘记门: f t = σ ( w f ⋅ x t + v f ⋅ h t − 1 + b f ) f_t = \sigma(w_f·x_t+v_f·h_{t-1}+b_f) ft=σ(wf⋅xt+vf⋅ht−1+bf)
- 输入门: i t = σ ( w i ⋅ x t + v i ⋅ h t − 1 + b i ) i_t = \sigma(w_i·x_t+v_i·h_{t-1}+b_i) it=σ(wi⋅xt+vi⋅ht−1+bi)
- 新记忆门: g t = t a n h ( w g ⋅ x t + v g ⋅ h t − 1 + b g ) g_t = tanh(w_g·x_t+v_g·h_{t-1}+b_g) gt=tanh(wg⋅xt+vg⋅ht−1+bg)
- 输出门: o t = σ ( w o ⋅ x t + v o ⋅ h t − 1 + b o ) o_t = \sigma(w_o·x_t+v_o·h_{t-1}+b_o) ot=σ(wo⋅xt+vo⋅ht−1+bo)
t t t时刻的细胞状态 C t C_t Ct为:
C t = f t ⨀ C t − 1 + i t ⨀ g t C_t = f_t \bigodot C_{t-1} + i_t \bigodot g_t Ct=ft⨀Ct−1+it⨀gt
t t t时刻的隐层输出 h t h_t ht为:
h t = o t ⨀ t a n h ( C t ) h_t = o_t \bigodot tanh(C_t) ht=ot⨀tanh(Ct)
σ \sigma σ为Sigmoid函数,⨀为矩阵的哈达马积。
2.输出层正向传播算法
t t t时刻的最终输出为:
y t = s o f t m a x ( w h ⋅ h t + b h ) y_t = softmax(w_h·h_t + b_h) yt=softmax(wh⋅ht+bh)
二、LSTM的反向传播算法
重点,也是LTSM算法的难点来了。
※关于反向传播,始终要牢记其目的是:求解损失函数E关于各个权重的偏导。※
既然有了正向传播的算法公式,那么反向传播就变成了一个求偏导的纯粹数学问题。下面以对忘记门的权重
w
f
w_f
wf求偏导为例,讲解这个过程。
损失函数E对权重
w
f
w_f
wf的偏导为:

这里的E根据损失函数的选择而不同,例如交叉熵损失函数,即为:
E = − Σ y t r u e ⋅ l n ( y t ) E=-\Sigma y_{true} ·ln(y_t) E=−Σytrue⋅ln(yt)
可见这个偏导由3个部分组成:
1. 损失函数E对细胞状态 C t C_t Ct的偏导
首先我们要明白损失函数E是一个关于 h 0 , h 1 , h 2 . . . h n h_0, h_1, h_2...h_n h0,h1,h2...hn的函数,即:
E = L ( h 0 , h 1 , h 2 . . . h n ) E=L(h_0, h_1, h_2...h_n) E=L(h0,h1,h2...hn)
根据正向传播公式, h t h_t ht是 C t C_t Ct的函数, C t C_t Ct是 C t − 1 C_{t-1} Ct−1的函数,即:
h
t
=
H
(
C
t
)
h_t = H(C_t)
ht=H(Ct)
C
t
=
F
(
C
t
−
1
)
C_t = F(C_{t-1})
Ct=F(Ct−1)
这样,求损失函数E对细胞状态 C t C_t Ct的偏导就成了高等数学中对复合函数求偏导的问题了。
首先计算
t
=
n
t=n
t=n时刻细胞状态的偏导,即E对
C
n
C_n
Cn的偏导:

反向传播,再求E对
C
n
−
1
C_{n-1}
Cn−1的偏导:
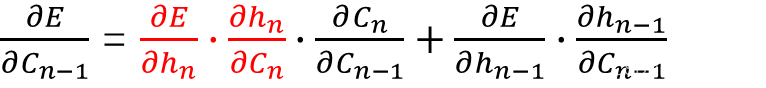
反向传播,再求E对
C
n
−
2
C_{n-2}
Cn−2的偏导:

以此类推,容易得出
t
t
t时刻E对
C
t
C_t
Ct的偏导:

根据正向传播公式,可以得出:

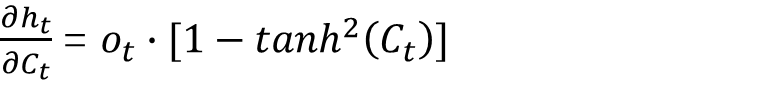
代入上式,最终得出:
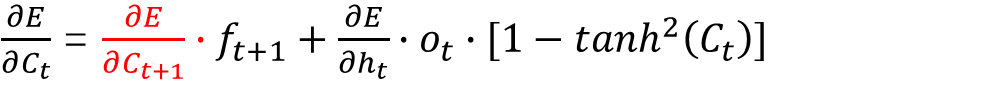
实际上,上式的乘法“ · ”对于矩阵而言,都是哈达马积“⨀”。为了方便理解,均以单个变量而非矩阵的形式为例说明求偏导的过程,下面也是如此,不再特殊说明。
2. 细胞状态 C t C_t Ct对忘记门 f t f_t ft的偏导
根据正向传播公式容易得出:

3. 忘记门 f t f_t ft对权重 w f w_f wf的偏导
根据正向传播公式容易得出:
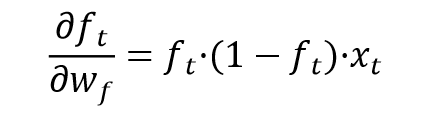
对于Sigmoid函数及上面tanh函数的求导过程略,如果不会CSDN上也能找到具体过程。
最终得出:
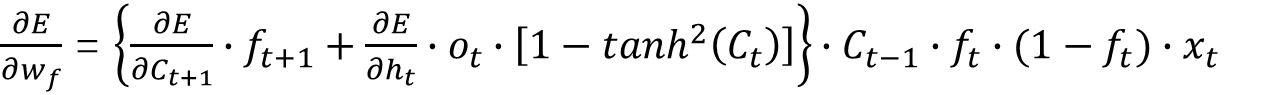
至此,LSTM的正向传播及反向传播的过程推导结束。
后面预告下用Python实现它。
----2023.5.1更新----
填坑了,Python实现LSTM的链接:基于NumPy构建LSTM模块并进行实例应用(附代码)

