
- 1处理多维度变化——桥接模式(四)_在某系统的报表处理模块中
- 2Docker安全防护与配置_定期检查每个宿主机的容器清单,及时清理不必要的容器
- 3解决MYSQL into outfile Error13 的问题_into outfile 无法写入文件
- 4有趣的十个Python实战项目,让你瞬间爱上Python!
- 5大语言模型应用指南:以ChatGPT为起点,从入门到精通的AI实践教程_大语言模型应用指南 epub
- 6Angular Material 每个版本的发布时间_angular版本及发布时间
- 7多数据库学习之GBase8s查询数据库表元信息常用SQL_gbase8s查询所有库
- 8蓝桥杯第十四届电子类单片机组决赛程序设计_蓝桥杯单片机14届国赛
- 9HDFS 基本 shell 操作_hdfs上传文件命令
- 10STM32深入系列02——BootLoader分析与实现_stm32 bootloader
ECCV 2022 | 上交&华为提出SdAE:自蒸馏掩码自编码器
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:鹦鹉丛中笑 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/485061820
 SdAE: Self-distillated Masked Autoencoder
SdAE: Self-distillated Masked Autoencoder论文:https://arxiv.org/abs/2208.00449
代码:https://github.com/AbrahamYabo/SdAE
1. 论文动机
介绍了BEIT和PECO的弊端,是需要一个预先训练好的dVAE来提供最后的预测目标。这种tokenizer需要pretrain。
介绍了MAE和splitmask的弊端,就是重建目标和语义理解可能有较大的鸿沟。
文章基于这两个点提出了改进:
a.引入根据EMA更新权重的教师模型,来产生预测目标。
b.其次是通过分析学生分支和教师分支之间的information bottleneck,从而提出一个新的重建的策略。
2. 具体做法
2-1.整体结构
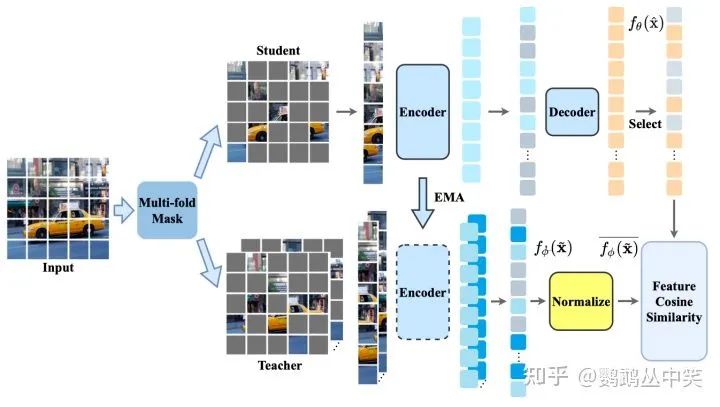
相比于还原像素等low-level的特征,论文采用了教师分支输出特征的方法。并且对教师分支的特征进行Patch内部的归一化。
这部分预测目标的修改,在最近的工作其实比较多,不展开。
2-2. 教师模型的输入
文章通过分析学生分支和教师分支的输入之间的互信息,得出了三个结论。
a. 学生分支和教师分支的输入要尽量减少共享的信息,即输入的token避免重叠。
b. 学生分支和教师分支的输入的互信息量应该相等,因此文章设计了新的策略使得两个分支输入的patch数量接近。
c. 为了保留更多信息,要利用上更多的被遮掩的图像块。
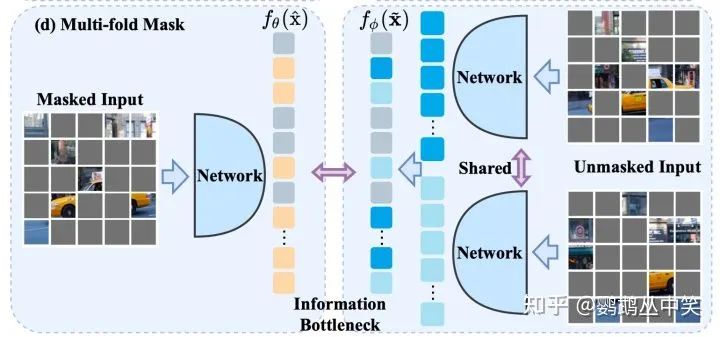
因此文章提出了新的策略——先将被遮掩的块进行分组,保证每一组的图像块的数量和学生分支输入的数量接近,然后每一组图像块分别通过共享的教师分支的模型,得到相应的特征,作为被预测的对象。
这种新的策略相比于全图输入和被遮掩的块一次性输入,计算速度能有些许提升。

3. 实验结果
3-1.分类下游任务
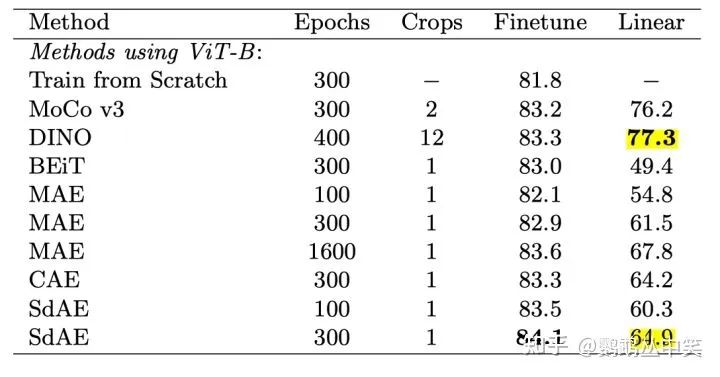
finetune效果可以,在较少的epoch能有领先。但是线性的结果比较一般。
这里MAE应该是low-level feature的重建,任务目标跟SDAE(用了EMA更新的teacher)不一致。
3-2. 消融实验
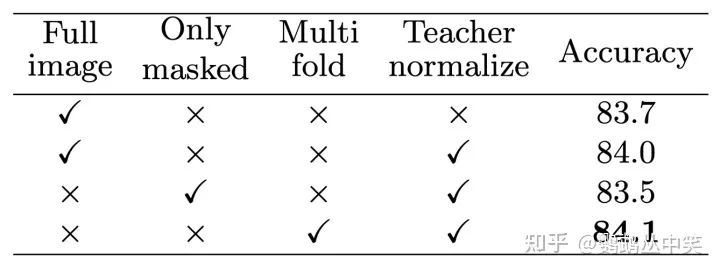
从全图输入到只输入被遮掩的块,有0.5的掉点。
再加入新的策略,能够提升0.6%。
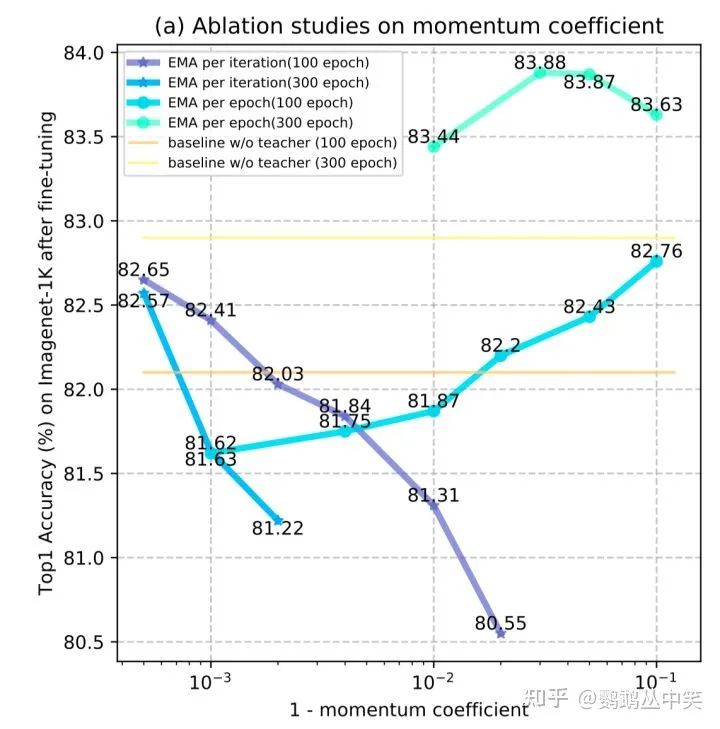
每一个epoch更新一次教师分支的权重效果更好。
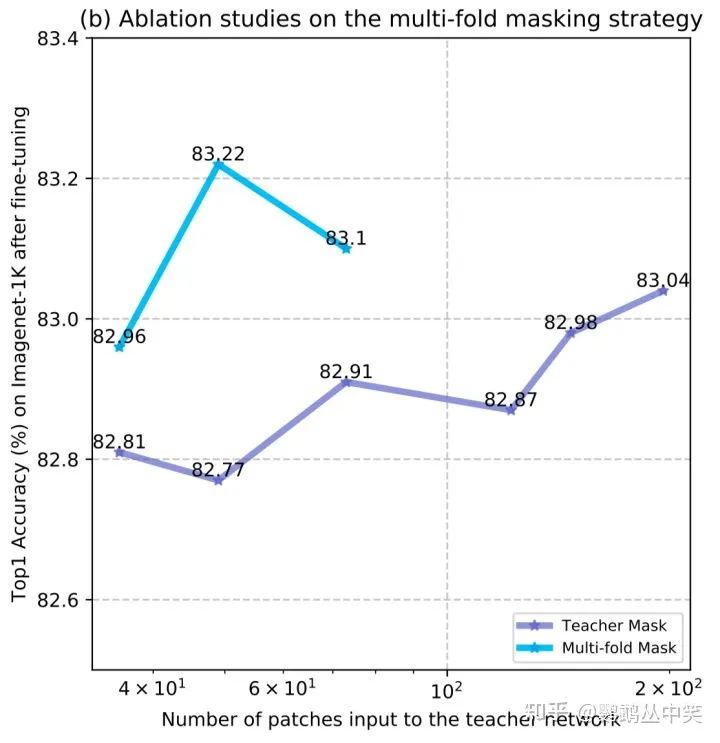
teacher mask:用过多的被遮掩的块,整体会有提升趋势。
multi-fold mask(文章最后的方案):教师分支和学生分支输入接近时,下游准确率更高。
3-3. 附录的实验
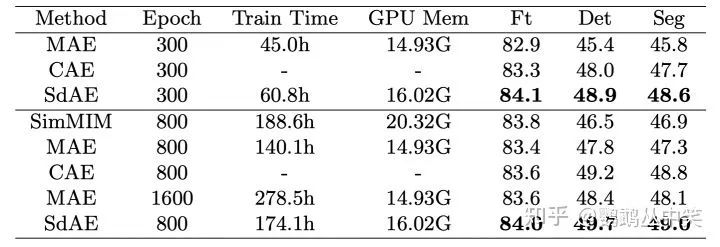
随着训练轮次的提升,分类任务上没有什么提升。可能代表了这个方式训练的高效性。此外作者在这里也说可能达到了这个backbone在分类任务的瓶颈。
4. 结论
这个教师分支的输入的分析还是比较有意思的。
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
- 目标检测和Transformer交流群成立
- 扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
-
- ▲扫码或加微信: CVer6666,进交流群
- CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
-
- ▲扫码进群
- ▲点击上方卡片,关注CVer公众号
- 整理不易,请点赞和在看

