- 1vue实现录音并转文字功能,包括PC端web,手机端web
- 2如何在IDEA中使用Git_idea git status
- 3用Flutter构建漂亮的UI界面 - 基础组件篇_flutter ui
- 4RabbitMq 基础篇_mqp$
- 5android 11.0 wifi密码保存的位置_一加手机wifi密码保存的位置2024
- 6Baidu comate智能编程助手评测
- 7【学习排序】 Learning to Rank中Pointwise关于PRank算法源码实现_pranking with ranking
- 8项目日记 | 基于Linux系统的2048小游戏_linux小游戏源码包分享
- 9C语言—自定义类型(详解)_c语言怎么声明一个自定义的类型
- 10【实践篇】4.1 Redis管道pipeline使用详解_redis pipeline使用方法
Java笔记——数据库03_编程题:用java连接数据库,编程实现往表中插入自己和张三的名字和学号,再查询表中
赞
踩
目录
编辑 注释:原成绩中为 90 的加上10就为 100了,这在decimal(3,1)放不下的
查询结果的展示往往,不美观,意义不明确,所以可以给查询结果起别名~
select 列名 as 新名词 from tb_name;编辑
select 属性名称 from tb_name limit n offset s; //查询结果按照前n行输出,从第s行开始,第s行不算,s相当于是索引
知识回顾
-
-
- mysql -u root -p; /* 登录mysql */
-
- mysql -h 127.0.0.1 -P 3306 -u root -p /* 完整的登录命令 */
-
-
-
- show databases; /* 查看当前有多少个数据库 */
-
- show create database 数据库名称; /* 查看数据库的创建信息 */
-
- select database(); /* 查看当前是在哪个数据库里面 */
-
- show warnings; /* 查看警告 */
-
-
- create database 数据库名称; /* 创建数据库 */
-
- create database if not exists 数据库名称; /* 如果已经存在数据库就不再创建 */
-
- use 数据库名称 /* 切换数据库 */
-
- drop database 数据库名称; /* 删除数据库 */
-
-
- alter database 数据库名称 character set 编码名称; /* 修改数据库编码 */
-
-
- -----------------关于 数据表 的操作
-
- show tables; /* 查看当前数据库有多少个表 */
-
- select @@datadir; /* 查看当前文件存在位置 */
-
- desc 表名; /* 查看某个具体表的结构 */
-
- show create table 表名称; /* 查看表的信息 */
-
-
- create table 表名称; /* 创建表 */
-
- /* 在创建表的同时也可以结合其他命令一起操作*/
-
- create table if not exists 表名称 (属性名称, 属性类型) character set 编码;
-
- comment '' /* 添加注释 写在末尾 */
-
- drop table 表名称; /* 删除表 */
-
-
- -------------修改表结构 alter 关键字
-
- alter table 表名称 add 新属性名称 新属性类型; /* 在表中添加一个属性 */
-
- alter table 表名称 drop 属性名称; /* 删除某一列 */
-
- insert into test values(1,'张三',98.6,'男'); /* 在表中插入一行数据 */
-
- select * from test; /* 打印插入的数据 */
-
- alter table 表名称 change 原属性名称 新属性名称 类型; /* 修改某一行*/
-
- alter table 旧名称 rename 新名称; /* 修改表名称 */
-
- alter table 表名称 convert to character set 新编码; /* 修改表的编码 */
-
-
-
- ----------------数值类型----字符串类型---日期类型
-
- int /* 整形 */
-
- decimal(M,D) /* 双精度浮点数 M指定长, D指保留小数位数 */
-
- varchar(size) /* 可变长度字符串 */
-
- char(size) /* 定长字符串 */
-
- bigint /* 长整形 */
-
- select now(); /* 查看当前时间 */

MySQL表的增删改查(基础)
CRUD
CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写。
1. 对于表中数据的增删改查在每一行上进行操作~
2. MySQL中表,数据库,属性名称
统一使用全小写+下划线分隔。不要使用驼峰名称
1. 新增(Create)
insert into tb_name(属性名称...) values(属性值...)
1.1 单行插入
insert into tb_name(属性名称...) values(属性值...)
选择某些属性进入数据插入
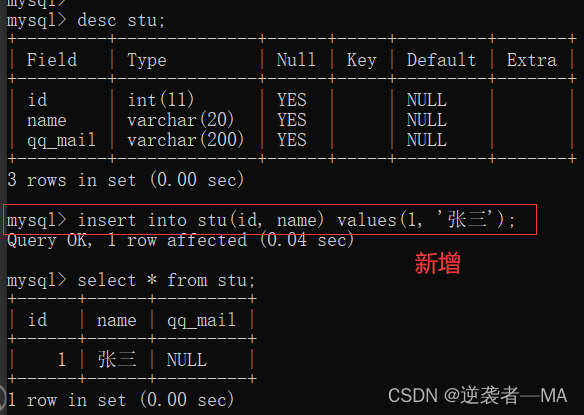
括号中就是本次要插入数据的列名,若有的属性没有插入,就会使用NULL值代替
1.2单行全列插入。
在插入时表名之后没有指定列名,默认为需要单列全列插入
insert into tb_name values(属性值...)
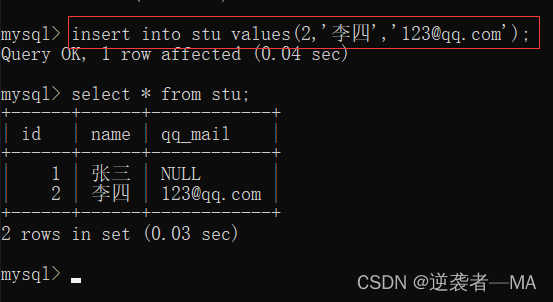
全列插入数据个数必须严格等于列的个数,否则报错,不会使用null占位
注释:不想给某些变量赋值的可以用null代替。
1.3 多行某几列插入
insert into tb_name(属性名称1 .....) values(数据1) , (数据2)..... ;
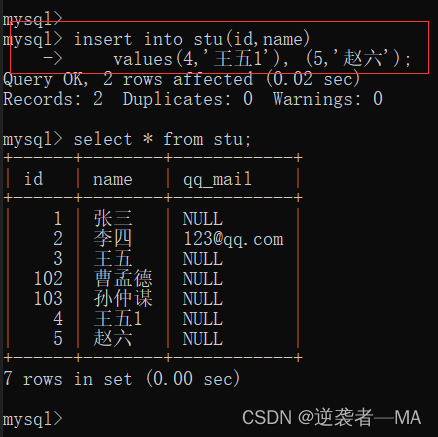
注释:values 后面多个数据用逗号分隔
1.4 多行全列插入
insert into tb_name values(数据1....) , (数据2...)...;
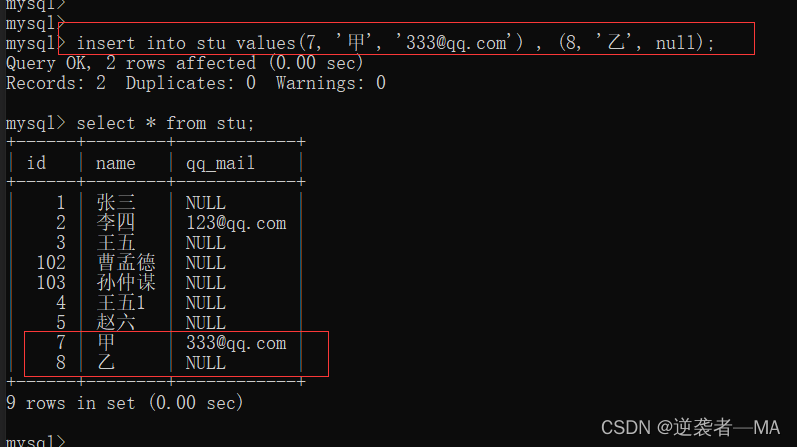
2. 查询(Retrieve)
语法:
- SELECT
- [DISTINCT] {* | {column [, column] ...}
- [FROM table_name]
- [WHERE ...]
- [ORDER BY column [ASC | DESC], ...]
- LIMIT ...
注释: select 关键字 得到的数据都是从数据库里面查询出来 临时的数据
select得到的数据相当于—张临时表
2.1 全行全列的查找
select * from 表名称;
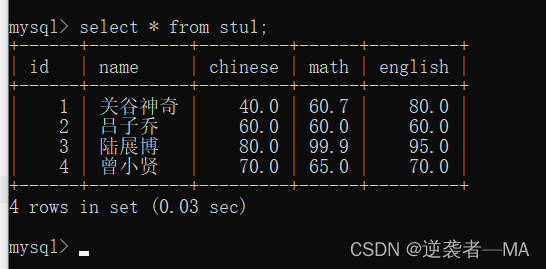
注释:一般不会这样查找,效率太低
注释:以二维表格的形式展示数据,这个表格是一张临时表,不会存储到具体的硬盘中。
2.2 查找指定列
select 列名称.... from tb_name;
注释:想一起查找多个列名称,用逗号分割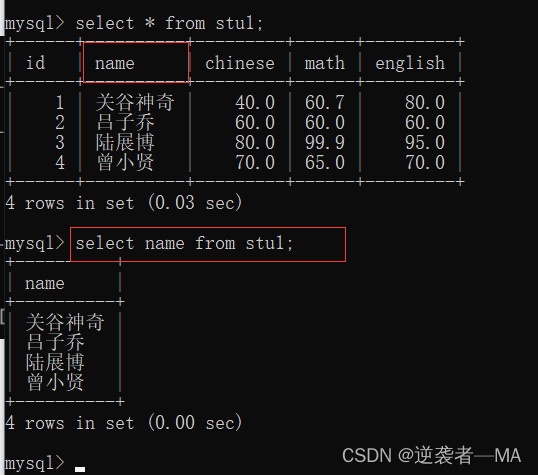
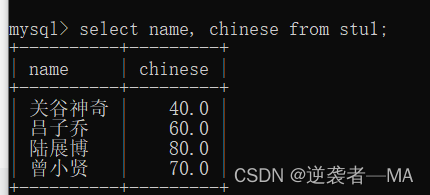
2.3 查询字段为表达式

注释:exam_result 是一个表的名称
比如:查询所有学生姓名,语文成绩+10的结果
注释:不会真的给数据+10,仅当前展示有效。
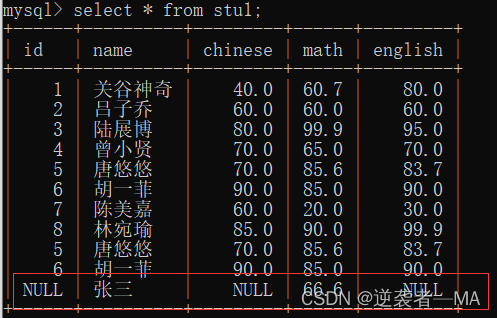
select name , chinese + 10 from stu1;
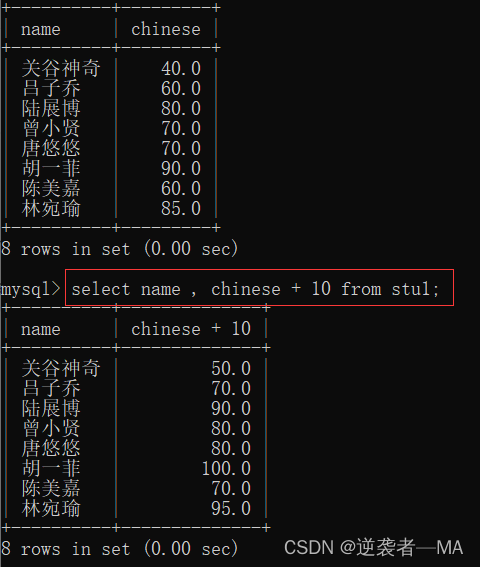
注释:原成绩中为 90 的加上10就为 100了,这在decimal(3,1)放不下的
这里的数据只是临时数据,给我们看看的。
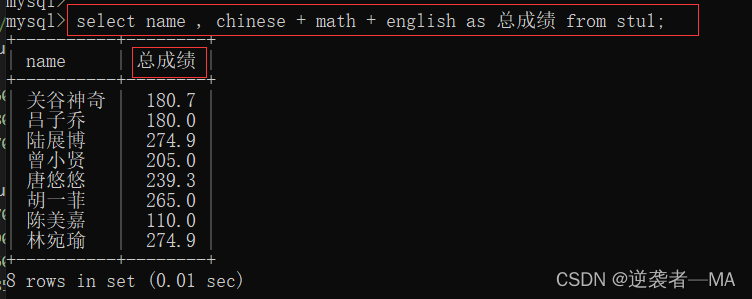
2.4 给查询结果起别名 as
查询结果的展示往往,不美观,意义不明确,所以可以给查询结果起别名~
select 列名 as 新名词 from tb_name;
2.5 去重查询
得到去重处理后的结果 distinct 关键字
select distinct 列名称 from tb_name
比如查询不重复的语文成绩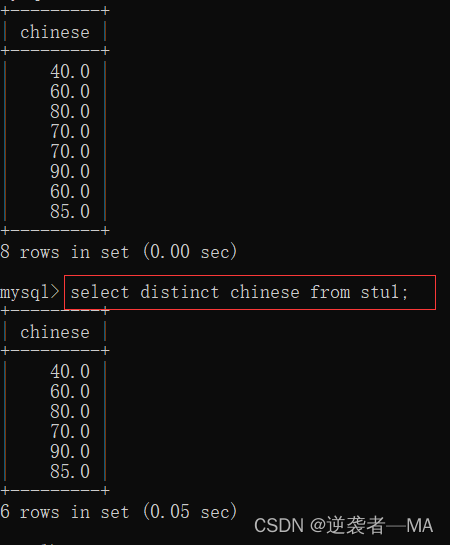
select distinct 列名称1,列名称2...组合属性去重
如果 distinct 后面有多个列名称,那么就是 组合去重
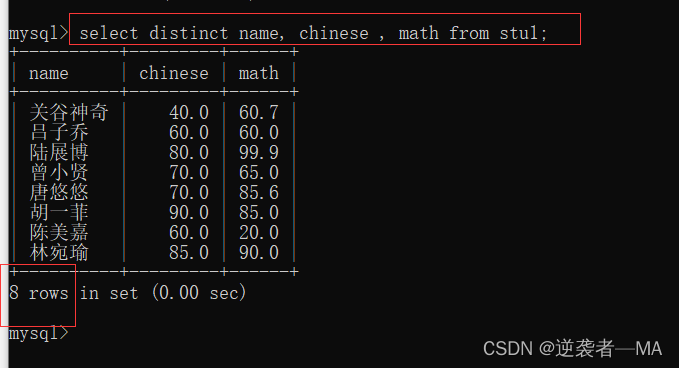
比如: select distinct name, chinese , math from stu1;
这个语句的意思就是 名字和语文 一模一样的数据才认为是同一个数据,进行去重。如果是出现了两个相同的name,但成绩不同的数据,那么认为是不同的,不会进行去重。
举例:添加了两个一模一样的数据
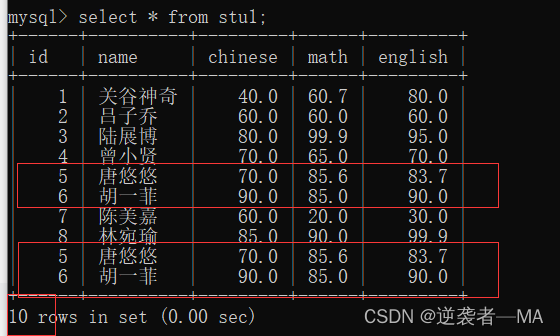
完成了去重 ,组合属性去重
注释:只能组合上不重复,因为如果你想数学和语文都不重复。如果语文不重复有四行,数学不重复只有三行,行数不一致,这样怎么办?所以只能组合不重复。
2.6 按照结果集排序 order by 关键字
select 列名称 from tb_name
order by 列名称 [asc|desc];
注释:默认为升序排序,asc不写的话默认升序,desc表示降序
注释:可以使用别名
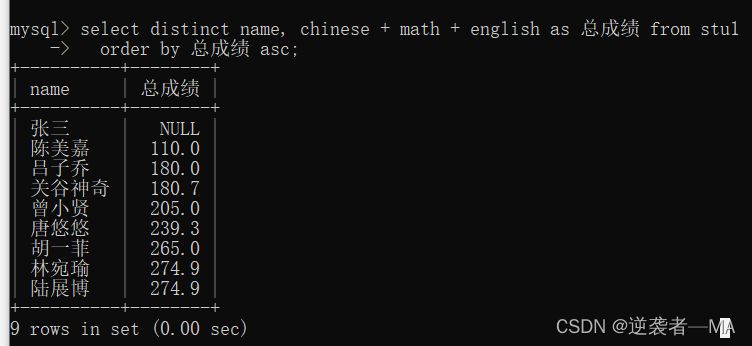
举例:查询所有学生的姓名和他们的总成绩,按照总成绩升序排序
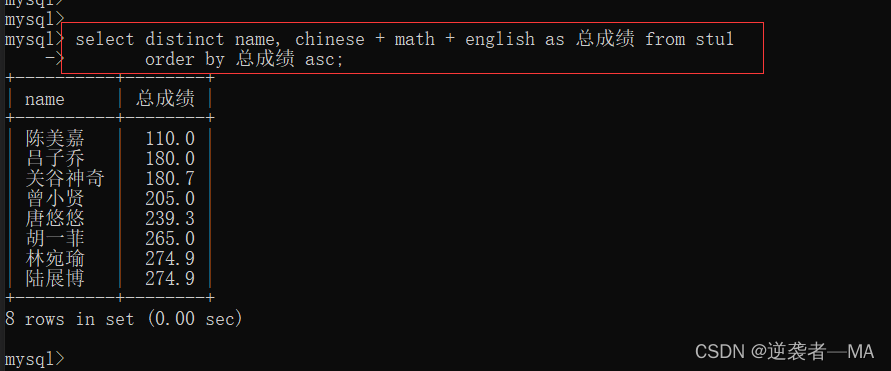
这是不去重,不排序的样子
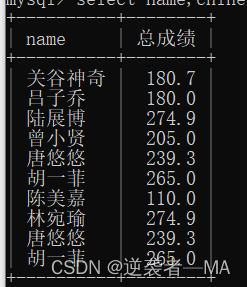
注释:这里有一种特殊情况,当学生的成绩为 null 或者 存在一门科目为 null 时,将不会参与排序运算, 升序在最开头, 降序在最末尾。 因为 null 表示不存在, 所以就没有比较的意义。
若此时结果集中包含null值,这个值null认为是最小值 (其实null 是为空,并不是某个特定的值)
只要一个学生的数据存在 null,不管有几个 null ,都算作无意义。
如果发现有两个及以上的学生存在 null 成绩, 那么它们null之间的排序顺序为当时书写插入的顺序。

要求2:查询所有学生的姓名,语文成绩,数学成绩其中按照语文成绩升序,数学成绩降序排序
select distinct name, chinese , math from stu1
order by chinese asc , math desc;

发现:数学并没有按照降序进行。
原因:我们上面写的代码语义:
优先按照语文成绩升序排序,只有两个语文成绩相同的数据才按照数学降序排序
总结:当多个数据进行排序时, 按照书写顺序优先级排序
注释:像 values 一样, order by 只用在开头写一次就可以了
2.7 分页查询 limit 关键字
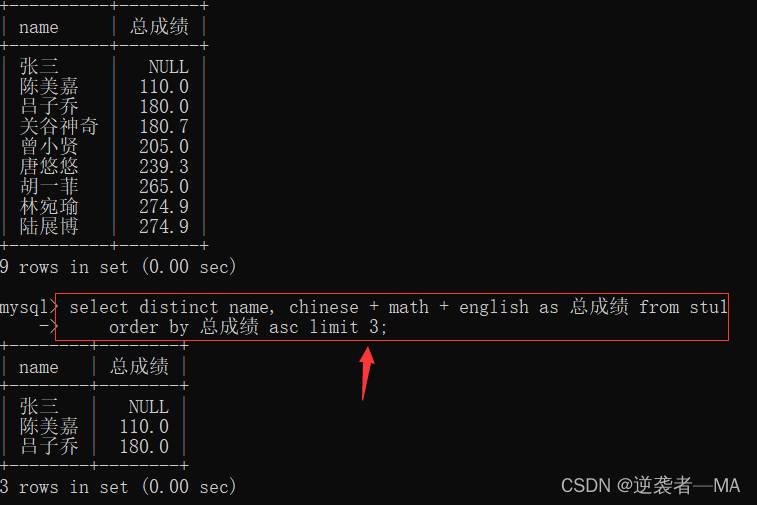
select 属性名称 from tb_name limit n ; //查询结果按照前n行输出
select 属性名称 from tb_name limit n offset s; //查询结果按照前n行输出,从第s行开始,第s行不算,s相当于是索引
举例:查询总成绩前三名同学也们的姓名以及总成绩多少
查询总成绩在3-5名的同学姓名和他们的总成绩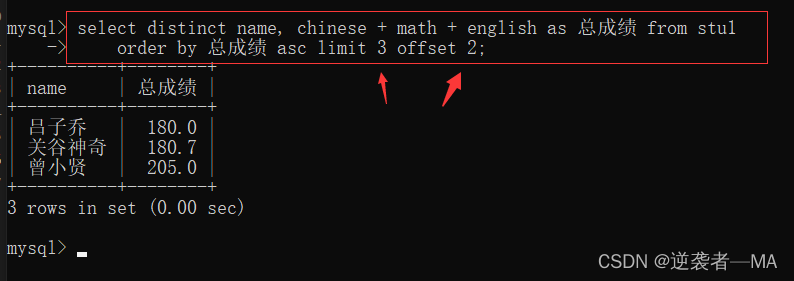
注释:如果你想输出的 n 行大于 总行数,就会全部输出, 如果想从第s行开始输出的s过大,就会显示 找不到,不会报错。
2.8 条件查询:WHERE
where条件中不支持别名
比较运算符:
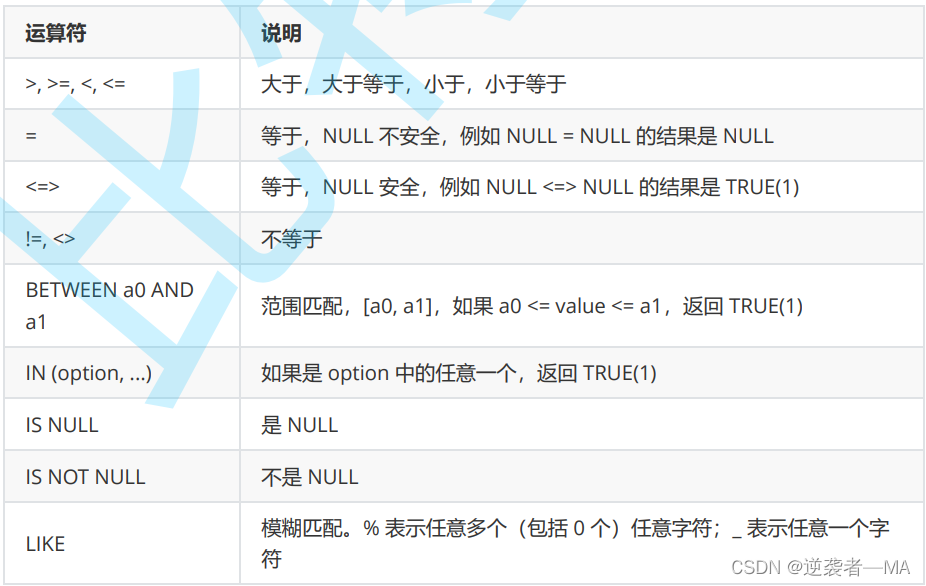
注释: 不要用 = 比较null, 用专门的 is null 和 is not null
2.8.1 查询所有总成绩 >200 的司学姓名和他们的总成绩
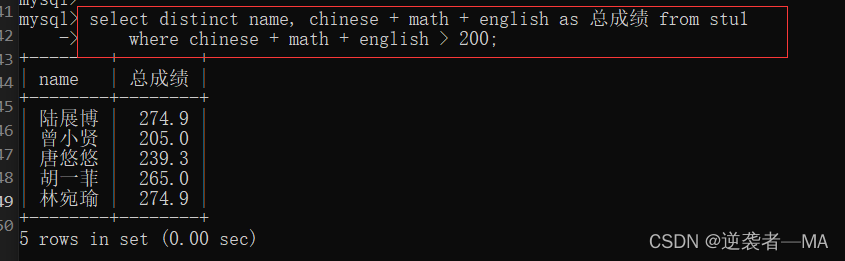
2.8.2 where分支中不支持别名

为啥order by支持别名,而where不支持。
原因:
order by的执行顺序是在已经把结果查出来了,只是给查出来的结果排序。
(select查询出来的结果对于order by已经可见了) 也就是说再执行 order by 的时候,查询的表已经完成任务了。
where执行顺序是在查询之前,条件过滤,select先要满足where分支的条件基础上的查询!
select的别名这个时候还没执行呢~~~所以对于where来说,不可见。
就是,where是先把 大于 200的人筛选出来,然后才对符合要求的数据进行去重,排序等操作。
而order by 没有条件选择,所有元素都满足,这时执行了as,所以才对后面的程序可见。
mysql不会做无用功,比如先把大量数据进行排序,再去删除其中不符合条件的部分。
它只会先去筛选符合条件的数据再进行操作!
注释:执行顺序和你书写顺序无关
2.8.3 MySQL的null不包含在 <<=的条件中
null = null也不支持

where条件 并不会把 null 值包括进来,会过滤掉。 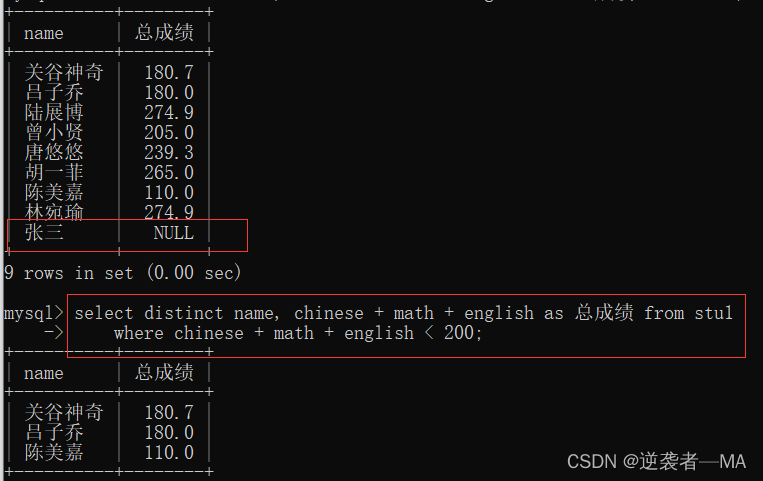
如果想在所有同学总成绩的时候,过滤条件仅为,过滤掉 null 用 in not null
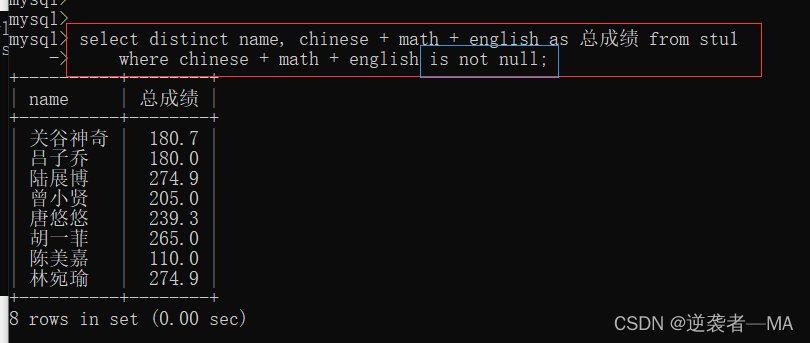
过滤为 null 的同学
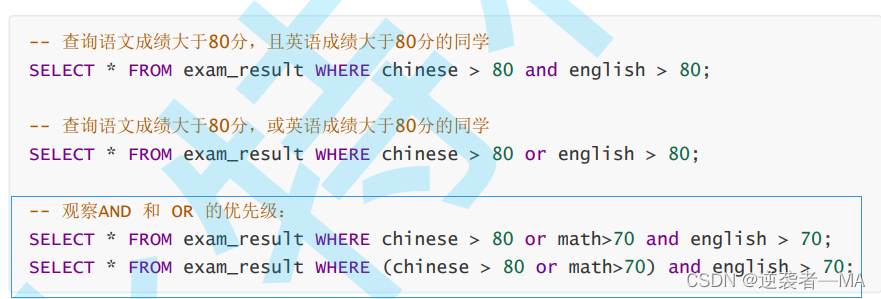
/*.查询语文成绩优于英语成绩的同学姓名及成绩*/
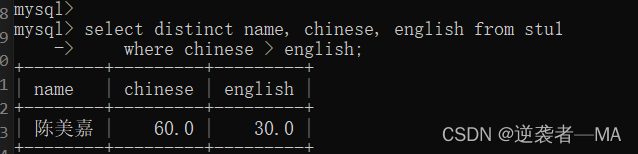
2.8.4)区间查询: between ..and..
比如:查询语文成绩在 [70..80]之间的同学姓名和他们的语文成绩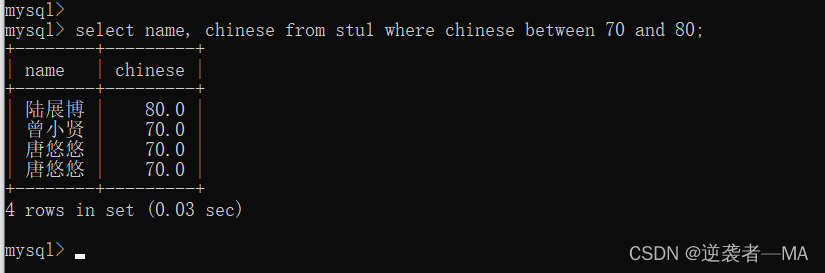
其实可以直接使用 and(且)
select name, chinese from stu1 where chinese >= 70 and chinese <= 80;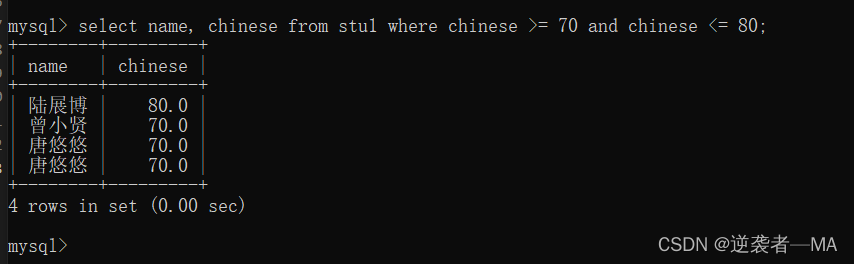
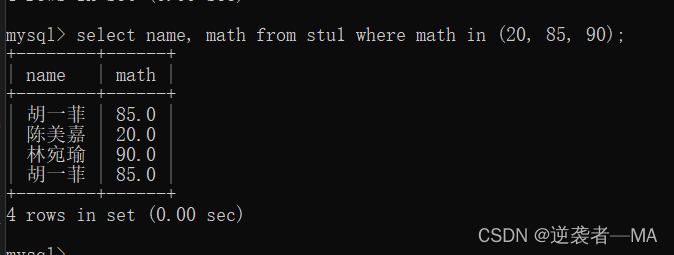
2.8.5 包含查询in(或)
select name, math from stu1 where math in (20, 85, 90);
2.8.6 模糊查询 like
-- % 匹配任意多个(包括 0 个)字符
SELECT name FROM exam_result WHERE name LIKE '孙%'; -- 匹配到孙悟空、孙权
-- _ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_'; -- 匹配到孙权
举例:% 元素[0....n] 模糊查询
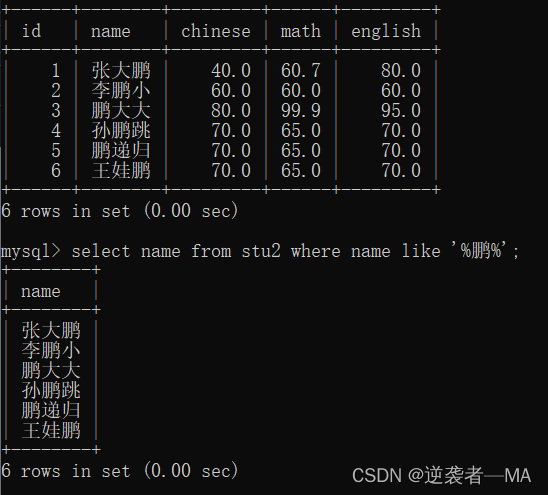
select name from stu2 where name like '%鹏%';
这句话的意思是 stu2表中,名字只要带鹏的都查询出来
举例:_ 匹配严格的一个任意字符
查询在三位字符的情况下,鹏出现在末尾,中间,和开头的情况。一个_ 表示一个字符位置