
- 1GPU:使用阿里云服务器,免费部署一个开源大模型_免费gpu服务器
- 2十分钟搞定时间复杂度(算法的时间复杂度)_渐进时间复杂度怎么算
- 3大数据学习week3_ctas和cte
- 4CommandInvokationFailure: Failed to update Android SDK package list. 报错的解决方法
- 5mysql sqlalchemy 索引_SQLAlchemy中指定想要使用的索引
- 6opencv 编译安装时出现报错 modules/videoio/src/cap_ffmpeg_impl.hpp:585:34: error: ‘AVStream {aka struct AVStre_error: no member named 'codec' in 'avstream
- 7【Java面试系列】ElasticSearch面试题_elastucsearch 面试题
- 8MyBatis-Plus CURD查询入门_mybatis plus cursor
- 93 分钟部署 SeaTunnel Zeta 单节点 Standalone 模式环境
- 10C++版OpenCV里的机器学习
截图识别对比:CnOCR与PaddleOCR_cnocr cpu占用
赞
踩
1、需求
想使用PyAutoGUI做界面自动化,需要一个ocr库识别压测软件的文字,然后获取定位。现在找到了CnOCR与PaddleOCR,都安装来试试看,哪一个更适合我的需求,这里对这俩库进行对比。
本机环境:
win11+python3.9
- 1

2、安装
两个库都有详细的安装步骤,有报错就去百度,安装对应的库就好了。
特别提醒安装Polygon3报错:Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools”: Microsoft C++ Build Tools - Visual Studio。
不要去安Visual Studio,去https://www.lfd.uci.edu/~gohlke/pythonlibs/下载一个Polygon3-3.0.9.1-cp39-cp39-win_amd64.whl包,手动安就好了。
CnOCR:
CnOCR 是 Python 3 下的文字识别(Optical Character Recognition,简称OCR)工具包,支持简体中文、繁体中文(部分模型)、英文和数字的常见字符识别,支持竖排文字的识别。自带了20+个训练好的识别模型,适用于不同应用场景,安装后即可直接使用。同时,CnOCR也提供简单的训练命令供使用者训练自己的模型。
开源地址:https://gitee.com/cyahua/cnocr/
安装使用国内源快一点
pip install cnocr[ort-cpu] -i https://mirrors.aliyun.com/pypi/simple
- 1
PaddleOCR(飞桨)
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。支持多种OCR相关前沿算法,在此基础上打造产业级特色模型PP-OCR和PP-Structure,并打通数据生产、模型训练、压缩、预测部署全流程。
开源地址:https://gitee.com/paddlepaddle/PaddleOCR
安装命令:
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
- 1
3、使用对比
待识别原图:
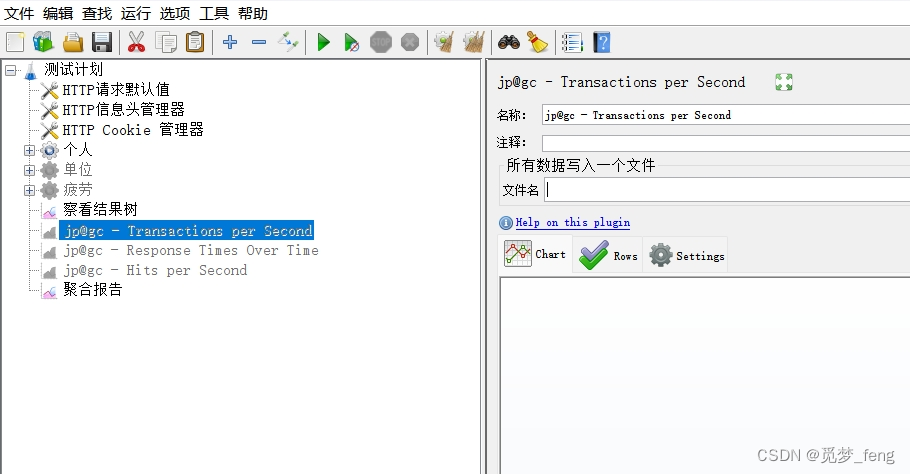
CnOCR:
使用还是挺方便,有几个模型选用,我主要是识别软件截图,就使用了doc-densenet_lite_136-gru的文档图片模型,试了几个图片,比通用模型要好一点点。
import time
from cnocr import CnOcr
time1=time.time()
img_fp = 'Temporary picture/jm.png'
#ocr = CnOcr() # 所有参数都使用默认值
ocr = CnOcr(rec_model_name='doc-densenet_lite_136-gru') # 文档图片模型
result = ocr.ocr(img_fp)
time2=time.time()
print('本次图片识别总共耗时%s s' % (time2 - time1))
for line in result:
print('text:'+line['text']+'\t\t\t\tscore:'+str(line['score']))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
识别出的文字:
其中score是:识别结果的得分(置信度),取值范围为 [0, 1];得分越高表示越可信
从结果对比原图,有较多的图标被识别成文字,我需要点击的【jp@gc - Transactions per Second】等标题,置信度不高。
本次图片识别总共耗时0.36582493782043457 s 文件 编辑 查找 运行 选项 工具 帮助 score:0.5050349831581116 T score:0.16470065712928772 昌日4自自 score:0.1683034747838974 45 score:0.22396154701709747 a score:0.17519843578338623 汇:? score:0.3250223994255066 -”A score:0.2549944818019867 测试计划 score:0.9605422019958496 NHTTP请求默认值 score:0.26849085092544556 jp@gc - Transactions per Second score:0.6434031128883362 3 score:0.1756362020969391 火HTTP信息头管理器 score:0.237385094165802 名称: score:0.8146508932113647 jp@gc - Transactions per Second score:0.6060640811920166 XHTTP Cookie管理器 score:0.5214072465896606 中安个人 score:0.3283456563949585 注释: score:0.8776631951332092 电豪单位 score:0.3201594650745392 所有数据写入一个文件 score:0.8833575248718262 中换疲劳 score:0.36431533098220825 文件名 score:0.6730592250823975 laC score:0.27173328399658203 察看结果树 score:0.9904499650001526 jp@gc - Transactiorns per Second score:0.5057143568992615 OHelp on this plugin score:0.5024359822273254 jp@gc - Response Times Over Time score:0.5534773468971252 Cha score:0.33296921849250793 RoFS score:0.1565089076757431 Settings score:0.9603992104530334 d jp@gc - Hits per Second score:0.5598205327987671 聚合报告 score:0.2708910405635834

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
PaddleOCR(飞桨)
就是默认设置,示例代码
import time from paddleocr import PaddleOCR, draw_ocr time1=time.time() img_fp = 'Temporary picture/jm.png' ocr = PaddleOCR(use_angle_cls=True, use_gpu=False) result = ocr.ocr(img_fp, cls=True) time2=time.time() print('本次图片识别总共耗时%s s' % (time2 - time1)) for idx in range(len(result)): res = result[idx] for line in res: print(line[1]) # 显示结果图片 from PIL import Image result = result[0] image = Image.open(img_fp).convert('RGB') boxes = [line[0] for line in result] txts = [line[1][0] for line in result] scores = [line[1][1] for line in result] im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf') im_show = Image.fromarray(im_show) im_show.save('result.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
识别出的文字:
速度慢点,但是内容明细精准许多。
[2024/03/28 16:17:26] ppocr DEBUG: dt_boxes num : 30, elapsed : 0.47530055046081543 [2024/03/28 16:17:26] ppocr DEBUG: cls num : 30, elapsed : 0.25675177574157715 [2024/03/28 16:17:31] ppocr DEBUG: rec_res num : 30, elapsed : 5.016136646270752 本次图片识别总共耗时9.896943092346191 s ('文件编辑查找运行选项工具帮助', 0.9968308210372925) ('测试计划', 0.9999251365661621) ('jp@gc -Transactions per Second', 0.973632276058197) ('HTTP请求默认值', 0.9975183010101318) ('HTTP信息头管理器', 0.9982931017875671) ('名称:', 0.9997771382331848) ('jp@gc - Transactions per Second', 0.9546123743057251) ('HTTPCookie管理器', 0.9962799549102783) ('个人', 0.9977327585220337) ('注释:', 0.9986750483512878) ('单位', 0.999846339225769) ('所有数据写入一个文件', 0.999435544013977) ('疲劳', 0.930761456489563) ('文件名|', 0.8699598908424377) ('C', 0.5080356001853943) ('察看结果树', 0.9994238615036011) ('jp@gc-', 0.9731400609016418) ('Transactions per Second', 0.9741607904434204) ('Help on this plugin', 0.9478721618652344) ('jp@gc - Response Times Over Time', 0.9619945883750916) ('Chart', 0.9883855581283569) ('Rows', 0.9848779439926147) ('Settings', 0.916187584400177) ('jp@gc- Hits per Second', 0.9670764803886414) ('聚合报告', 0.9991028308868408)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
有个飞桨的可视化图

4、总结
我需要对jmeter与loadrunner软件截图进行识别,获取定位,再使用PyAutoGUI做自动化操作。从上面的识别结果来看,PaddleOCR(飞桨)的识别率符合要求,就是慢一点。

